Open Source in Lab Management
Julien Cohen-Adad1
1Polytechnique Montreal, Montreal, QC, Canada
1Polytechnique Montreal, Montreal, QC, Canada
Synopsis
Keywords: Transferable skills: Data management, Transferable skills: Reproducible research, Transferable skills: Software engineering
This document explores the advantages of integrating open source software and practices in managing a scientific lab, emphasizing reproducibility and the avoidance of pitfalls. It details practical applications from website management using GitHub Pages to organizing datasets in compliance with BIDS standards, highlights the importance of continuous testing for data integrity, IT management through Ansible for efficient system configuration, open source software development. The broader goal is to promote transparent, reproducible science by adopting open source tools. This approach not only saves time but exposes students to best practices, enhancing the transparency and reproducibility of scientific research.Introduction
This document describes how managing a scientific lab can benefit from open source software and practices. It is not exhaustive, and very much biased towards particular software, some which have been chosen for historical reasons. One motivation for open source practices in science is to promote reproducibility and avoid situations like the one illustrated on Figure 1, that ultimately slows down scientific progress.Website
Every lab should have a website that describes the research performed in the lab, the team, publications, available positions, etc. Also useful is an intranet, which contains information useful for lab members, such as: onboarding procedures, relevant university courses, poster templates, procedure for conference reimbursement, etc. At NeuroPoly we have a lab website: www.neuro.polymtl.ca and an intranet https://intranet.neuro.polymtl.ca/. They are both hosted on GitHub pages. The source of the websites is on public GitHub repositories, is written in markdown format, and is readable directly from GitHub. Compilation of the website is done every time there is a change on the source (ie: someone ‘git commit/push’ a change) to generate the prettier, more public-facing version. The website can also be built locally to check if changes are OK before pushing. For important changes, we use pull requests. Everyone with a GitHub account can update the website (for example, to fix stale information, fix wrong links). In addition to being open and flexible to manage, this approach is also an opportunity for new students in the lab to get familiar with git/GitHub.Managing publications: An important aspect of a lab’s website is the management of publications. Manually maintaining the list of publications is prone to error and requires time. With the website hosted on GitHub and automatically compiled, an attractive solution is to leverage code that fetches the list of publications from a centralized source organized by the PI (eg: could be a google sheet), formats the publication list as a markdown page, and update that page on the lab’s website source every time someone commits something on the website via a Github’s Action workflow. As an example, NeuroPoly’s website publication list is automatically updated via a github action (https://github.com/neuropoly/neuro.polymtl.ca/blob/master/.github/workflows/publish.yml) and the bibeasy software developed by NeuroPoly [1]. What’s interesting is the possibility to tweak the page (with javascript code) by adding e.g. filters to the publication based on keywords.
Organizing datasets
Standardizing file structure with BIDS: We organize our public and private datasets according to the BIDS standard [2]. Procedure to BIDSify our datasets are on our intranet (https://intranet.neuro.polymtl.ca/data/dataset-curation.html). BIDS also allows tracking data and label provenance using JSON sidecars containing information on which tool (eg: deep learning model) was used to generate the label and whether the label was manually corrected or not.Continuous testing of data compliance: How can you ensure your data are and stay BIDS compliant? Use PyBIDS [3] combined with cron jobs such as Github Action (for cloud hosting), that runs every time new data is pushed to the repository. Can tests for missing file, acquisition parameters, etc. See this footnote for an example of github action for continuous BIDS compliance testing.
Hosting data: Data hosting utilizes OpenNeuro and Amazon S3 for public datasets, and university servers for private ones, with backup routines in place. We employ git-annex for versioning, avoiding direct storage of large files by tracking their SHA256 pointers, offering a more scalable solution. This method ensures dataset consistency, allowing users to access specific data versions, keeping work synchronized among multiple researchers, and simplifying the addition of new data while maintaining a clear record of data provenance. Git-annex, preferred for its direct command control, supports reproducible analyses by enabling precise version tracking in research scripts. The adoption of git-annex and Datalad aligns with the YODA principles for transparent and reproducible research, emphasizing the importance of familiarizing students with these advanced tools for future scientific endeavors.
IT management
Management of lab computers is a necessary pain. A very ‘hands off’ approach is to give students a laptop and have them install whatever they need. This approach works relatively well, until the laptop is returned and reused and needs to be reconfigured for the next student, or until there is a need to deploy shared resources (eg: CPU/GPU clusters, data server, shared printer, etc.), or proprietary software with network licenses (eg: Matlab, CST, Ansys HFSS). Configuration management software like Ansible offers an efficient solution, enabling automated deployment of software and settings across lab systems. This setup simplifies adding new servers and ensures consistent environments for reproducible scientific research. Regularly wiping and reinstalling systems, along with scheduled software updates, further enhance reproducibility and system reliability.To manage the different tasks related to IT management, IT documentation should be kept in a digital notebook; again, we use GitHub here, keeping the IT notes in a section of our intranet. We also keep a separate section of sensitive information is present (eg: IP addresses, sensitive messages) in a the repository can be made private for the lab; this does not build to a public website, but it does use the same markdown format that our public websites do, and those notes render cleanly and legibly directly on GitHub.
Project management
Every project has a shared GDoc associated with it. It follows the same organization as for student’s lab notes. Agenda and minutes are organized per meeting, with the file name starting with the date (Figure 2 illustrates the ONLY way to write a date). At the top of the GDoc, there is a link to the GitHub repository of the project, calendar to the meetings with a Zoom link for the meetings. To make it easier to have external collaborators participate in our lab meetings, those lab meeting agenda are usually public.In all projects, whether this is a software dev project, or an MR physics project, we try to have a GitHub repository associated with it. Then, students use GitHub issues as a way to ask questions about the project, document their experiments. GitHub issues is a fantastic way to keep track of discussions, eg: we can cross-reference the code that was used to generate some results, we can add images, we can format text and code with markdown. To ensure transparency and reproducibility, when presenting results of an experiment, always specify the version of the code that was used (SHA), and the version of the data (SHA from git-annex/Datalad). Ideally, the analysis script should produce log files that include these versioning information (also see YODA framework)
Issues are also a great way to initiate project ideas, and assign labels to it (eg: ‘good internship project’, or ‘good first issue’)-- then, once a student is assigned to the project, GitHub has a tag ‘assigned to XX’. Issues can also be referenced in a Kanban project managing board. The best resource to get started with leveraging the power of github’s issues to manage code and project is this link: https://docs.github.com/en/issues.
Open source coding
Adopting open source coding practices through platforms like GitHub and GitLab significantly benefits both development processes and student education. It enhances code quality through peer reviews and continuous integration (CI) tools, which enforce coding standards and perform automated testing. This approach promotes collaborative learning and the development of industry-valued coding skills. The open-source model encourages a transparent and inclusive environment, boosting innovation and knowledge sharing. It also improves research reproducibility and credibility by facilitating easier validation and building upon previous work. Engaging with the open-source community further enriches research tools through diverse feedback. Overall, open source practices in research labs not only elevate software quality and research outcomes but also equip students with essential skills for their future careers.Writing articles
Collaborative writing: Exception to open source: we use GDoc and Paperpile. Some students use Latex-based Overleaf (mostly ML students). These technologies enable researchers to collaborate simultaneously on the same version of the manuscript, add comments, see who wrote the comments (if they are logged in with their google account), and tag people on comments. I find this makes article writing very efficient. Example of large article-writing collaboration using that approach: [5] (92 co-authors), [6] (57 co-authors). The wrong way to do it (in my humble opinion) is for one author to write the manuscript on a local file (eg: Microsoft Word), and then send the article to all co-authors via email. Working on multiple 'unsynchronized' versions of a document, as opposed to a unified, cloud-based document with version control, causes several issues. It can lead to confusion, inefficiency, and redundant work due to uncertainty about the most current version. This method often involves excessive email exchanges with large attachments that can burden email storage and may not reach all co-authors due to size limits or spam filters, exacerbating data duplication and environmental concerns. The merging of changes is error-prone and usually done by one person, reducing transparency and increasing the risk of miscommunication. Additionally, it results in disorganized file naming, complicating the identification of the latest document version.Advancing reproducible science: It is vital for papers to be self-contained, allowing data and code to reproduce the published results and figures. To avoid issues like those depicted in Figure 1, it's recommended to include the code with the paper submission, ideally enabling figures to regenerate dynamically. NeuroLibre (https://neurolibre.org/) offers a platform for such reproducible preprints, supporting both publication and ongoing project needs. Additionally, when code associated with a publication is hosted on GitHub, linking directly to the specific release version ensures the code matches the published work, maintaining the integrity of the research by distinguishing between the static published version and the evolving main branch.
Communication
Exception to open source: we use Slack. We tried mattermost. It was too cumbersome to deploy and to maintain the server locally. But the biggest hurdle was adoption: lab members and collaborators already had Slack installed and used it. It was too much to ask to use another app in their daily routine. We ended up with a hybrid mode, with some people using Slack, and a minority using mattermost. It was a disaster. We stopped it and went back to full Slack with a paid license.Conclusion
The use of open source software in lab management aims to promote its development and inspire other labs through practical examples. This approach supports the broader goal of making science transparent and reproducible, extending beyond publication to encompass all research phases, aligned with the FAIR principles of making data findable, accessible, interoperable, and reusable. While beneficial, these tools often require significant IT skills, such as knowledge of Ansible or git-annex, presenting a balance between the initial learning investment and long-term efficiency gains (see Figure 4). Ultimately, adopting these technologies not only saves time but also introduces students to valuable practices that enhance the transparency and reproducibility of scientific research.Acknowledgements
I would like to thank Sandrine Bédard, Naga Karthik Enamundram, Jan Valošek, Armand Collin, Mathieu Guay-Paquet and Nick Guenther for contributing to this document.References
- Cohen-Adad J. bibeasy: Managing references made easy [Internet]. Zenodo; 2024. Available from: https://zenodo.org/doi/10.5281/zenodo.10650997
- Gorgolewski KJ, Auer T, Calhoun VD, Craddock RC, Das S, Duff EP, Flandin G, Ghosh SS, Glatard T, Halchenko YO, Handwerker DA, Hanke M, Keator D, Li X, Michael Z, Maumet C, Nichols BN, Nichols TE, Pellman J, Poline JB, Rokem A, Schaefer G, Sochat V, Triplett W, Turner JA, Varoquaux G, Poldrack RA. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Sci Data. 2016 Jun 21;3:160044
- Yarkoni T, Markiewicz CJ, de la Vega A, Gorgolewski KJ, Salo T, Halchenko YO, McNamara Q, DeStasio K, Poline JB, Petrov D, Hayot-Sasson V, Nielson DM, Carlin J, Kiar G, Whitaker K, DuPre E, Wagner A, Tirrell LS, Jas M, Hanke M, Poldrack RA, Esteban O, Appelhoff S, Holdgraf C, Staden I, Thirion B, Kleinschmidt DF, Lee JA, Visconti di Oleggio Castello M, Notter MP, Blair R. PyBIDS: Python tools for BIDS datasets. J Open Source Softw [Internet]. 2019 Aug 12;4(40). Available from: http://dx.doi.org/10.21105/joss.01294
- Halchenko Y, Meyer K, Poldrack B, Solanky D, Wagner A, Gors J, MacFarlane D, Pustina D, Sochat V, Ghosh S, Mönch C, Markiewicz C, Waite L, Shlyakhter I, de la Vega A, Hayashi S, Häusler C, Poline JB, Kadelka T, Skytén K, Jarecka D, Kennedy D, Strauss T, Cieslak M, Vavra P, Ioanas HI, Schneider R, Pflüger M, Haxby J, Eickhoff S, Hanke M. DataLad: distributed system for joint management of code, data, and their relationship. J Open Source Softw. 2021 Jul 1;6(63):3262
- Cohen-Adad J, Alonso-Ortiz E, Abramovic M, Arneitz C, Atcheson N, Barlow L, Barry RL, Barth M, Battiston M, Büchel C, Budde M, Callot V, Combes AJE, De Leener B, Descoteaux M, de Sousa PL, Dostál M, Doyon J, Dvorak A, Eippert F, Epperson KR, Epperson KS, Freund P, Finsterbusch J, Foias A, Fratini M, Fukunaga I, Wheeler-Kingshott CAMG, Germani G, Gilbert G, Giove F, Gros C, Grussu F, Hagiwara A, Henry PG, Horák T, Hori M, Joers J, Kamiya K, Karbasforoushan H, Keřkovský M, Khatibi A, Kim JW, Kinany N, Kitzler H, Kolind S, Kong Y, Kudlička P, Kuntke P, Kurniawan ND, Kusmia S, Labounek R, Laganà MM, Laule C, Law CS, Lenglet C, Leutritz T, Liu Y, Llufriu S, Mackey S, Martinez-Heras E, Mattera L, Nestrasil I, O’Grady KP, Papinutto N, Papp D, Pareto D, Parrish TB, Pichiecchio A, Prados F, Rovira À, Ruitenberg MJ, Samson RS, Savini G, Seif M, Seifert AC, Smith AK, Smith SA, Smith ZA, Solana E, Suzuki Y, Tackley G, Tinnermann A, Valošek J, Van De Ville D, Yiannakas MC, Weber KA 2nd, Weiskopf N, Wise RG, Wyss PO, Xu J. Generic acquisition protocol for quantitative MRI of the spinal cord. Nat Protoc. 2021 Oct;16(10):4611–32
- Jelescu IO, Grussu F, Ianus A, Hansen B, Barrett RLC, Aggarwal M, Michielse S, Nasrallah F, Syeda W, Wang N, Veraart J, Roebroeck A, Bagdasarian AF, Eichner C, Sepehrband F, Zimmermann J, Soustelle L, Bowman C, Tendler BC, Hertanu A, Jeurissen B, Verhoye M, Frydman L, van de Looij Y, Hike D, Dunn JF, Miller K, Landman BA, Shemesh N, Anderson A, McKinnon E, Farquharson S, Acqua FD, Pierpaoli C, Drobnjak I, Leemans A, Harkins KD, Descoteaux M, Xu D, Huang H, Santin MD, Grant SC, Obenaus A, Kim GS, Wu D, Le Bihan D, Blackband SJ, Ciobanu L, Fieremans E, Bai R, Leergaard T, Zhang J, Dyrby TB, Allan Johnson G, Cohen-Adad J, Budde MD, Schilling KG. Recommendations and guidelines from the ISMRM Diffusion Study Group for preclinical diffusion MRI: Part 1 -- In vivo small-animal imaging [Internet]. arXiv [physics.med-ph]. 2022. Available from: http://arxiv.org/abs/2209.12994
Figures
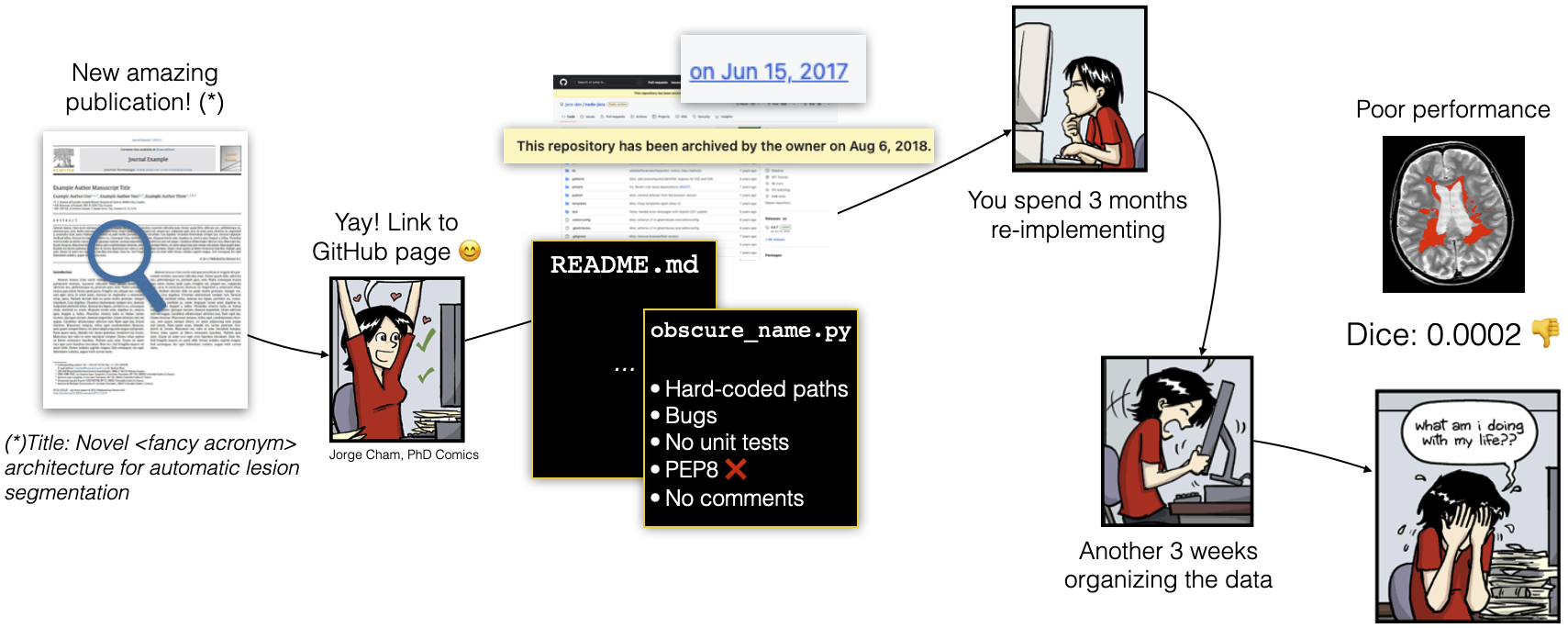
Figure 1. A student finds a promising algorithm for medical image analysis on GitHub but discovers it's poorly documented, buggy, and no longer maintained. The original author is unreachable, having left academia. Despite efforts to reimplement the method and organize data, the approach fails upon testing. This scenario, highlighting the cycle of un-reproducible science, suggests the challenges of relying on archived code and the continuous effort required to adapt or choose among numerous new methods annually.

Figure 2. How to properly format dates? Especially when naming electronic files. Source: https://xkcd.com/1179/

Figure 3. Why is it a bad idea to work on multiple ‘unsynced’ versions of a document, versus a single document on the cloud one that has version control? Source: https://phdcomics.com/
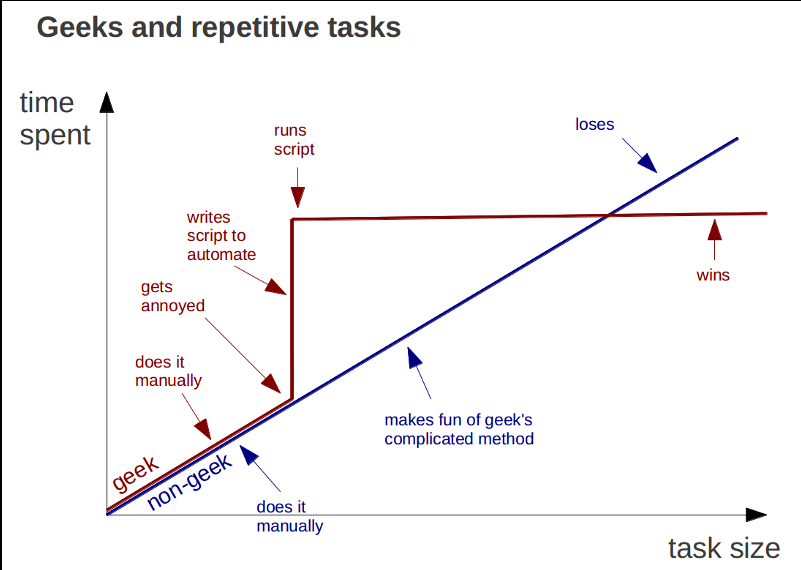
Figure 4. Is it worth spending time developing automated procedures? This chart can answer that. Source: https://i.imgur.com/Q8kV8.png