5003
Quality assessment of MR images: Does deep learning outperform machine learning with handcrafted features on new sites?1Centre for Medical Image Computing and Department of Computer Science, University College London, London, United Kingdom, 2Neuroradiological Academic Unit, UCL Queen Square Institute of Neurology, University College London, London, United Kingdom, 3Queen Square Centre for Neuromuscular Diseases, Department of Neuromuscular Diseases, UCL Queen Square Institute of Neurology, London, London, United Kingdom, 4Radiology & Nuclear Medicine, VU University Medical Center, Amsterdam, Netherlands, 5Queen Square Centre for Neuromuscular Diseases, Department of Neuromuscular Diseases, UCL Queen Square Institute of Neurology, London, United Kingdom, 6Centre for Microscopy, Characterisation, and Analysis, The University of Western Australia, Nedlands, Australia
Synopsis
Keywords: Artifacts, Brain, Quality, Deep learning, Quality Assessment
Motivation: Deep learning (DL) outperforms conventional machine learning (ML) that relies on handcrafted feature-based in many vision tasks, but its superiority in assessing brain MRI image quality for new sites/scanners is unclear.
Goal(s): Compare DL and conventional ML for quality assessment of brain MRI images from new sites/scanners.
Approach: One popular and widely accepted DL and one conventional ML method are evaluated on a multi-site dataset using leave-one-site-out approach using a binary quality label (good/bad).
Results: Averaged balanced accuracy (BA) for the DL and conventional ML approaches are comparably poor (0.60+-0.12 and 0.54+-0.12, respectively) and does not exceed 0.76, suggesting room for improvement.
Impact: Widespread adoption of automated quality assessment of brain MRI images is limited by a lack of generalizability. By comparing popular DL and conventional ML approaches, we find comparable but limited generalizability. This underscores the need for future algorithm development.
Introduction
Automated analysis of brain MRI scans (e.g., segmentation) requires high-quality inputs, necessitating automated quality assessment (AQA) methods [2-4]. Traditional AQA uses conventional machine learning (ML) methods that rely on handcrafted features (e.g., MRIQC) and is computationally expensive [1,5]. Deep learning (DL) methods (e.g., CNNQC) offer faster alternatives that do not require ad hoc feature engineering [2-4]. A recent comparison of the two types of methods has shown the equivalence of DL and conventional ML in terms of AQA performance [3]. Critically, this work did not evaluate the classification of images from unseen sites/scanners outside the training dataset. This gap is pivotal, as it does not inform whether such methods have the necessary generalizability to be deployed at new sites/scanners . This study aims to bridge this gap by conducting a comparative analysis of these two approaches with leave-one-site-out evaluation.Materials and Methods
We have opted for MRIQC [1] as the chosen conventional ML method because it represents the state-of-the-art in this category and is publicly available. It computes handcrafted features after computationally-intensive image pre-processing and segmentation. For the DL class of methods, we have chosen the 2D CNN architecture of CNNQC [2], as it has significantly less memory requirement compared to 3D CNN architectures used in other AQA works [3].Dataset: To evaluate generalizability for unseen sites/scanners, we need a multi-site dataset with manually labelled image quality. The ABIDE dataset [6] meets these requirements, with 1098 images from 17 sites (Fig. 1) and image quality labelled as bad if one or more rater has labelled it bad. A total of 756 images were labeled good, and 342 were labelled bad.
Experiments: Both models were trained using data from all sites except one, and then their performance assessed on the excluded site during the testing phase. This process was repeated for each of the sites in the ABIDE dataset, one site at a time. We assess each method's performance using accuracy, sensitivity, and balanced accuracy (BA, accounting for class imbalance). Comparison involves relative evaluation (|difference| < 0.1 = equivalent) and absolute assessment of accuracy (>0.55 accurate, <=0.45 less accurate, 0.45 < accuracy ≤ 0.55 uncertain) and sensitivity (<=0.5 sensitive, >0.5 less sensitive).
Results
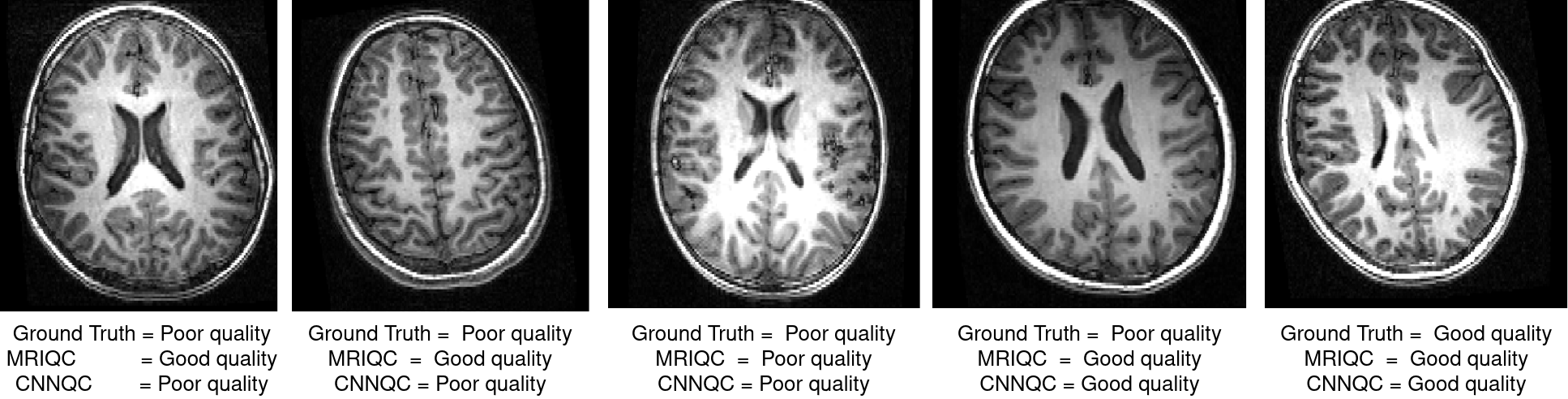
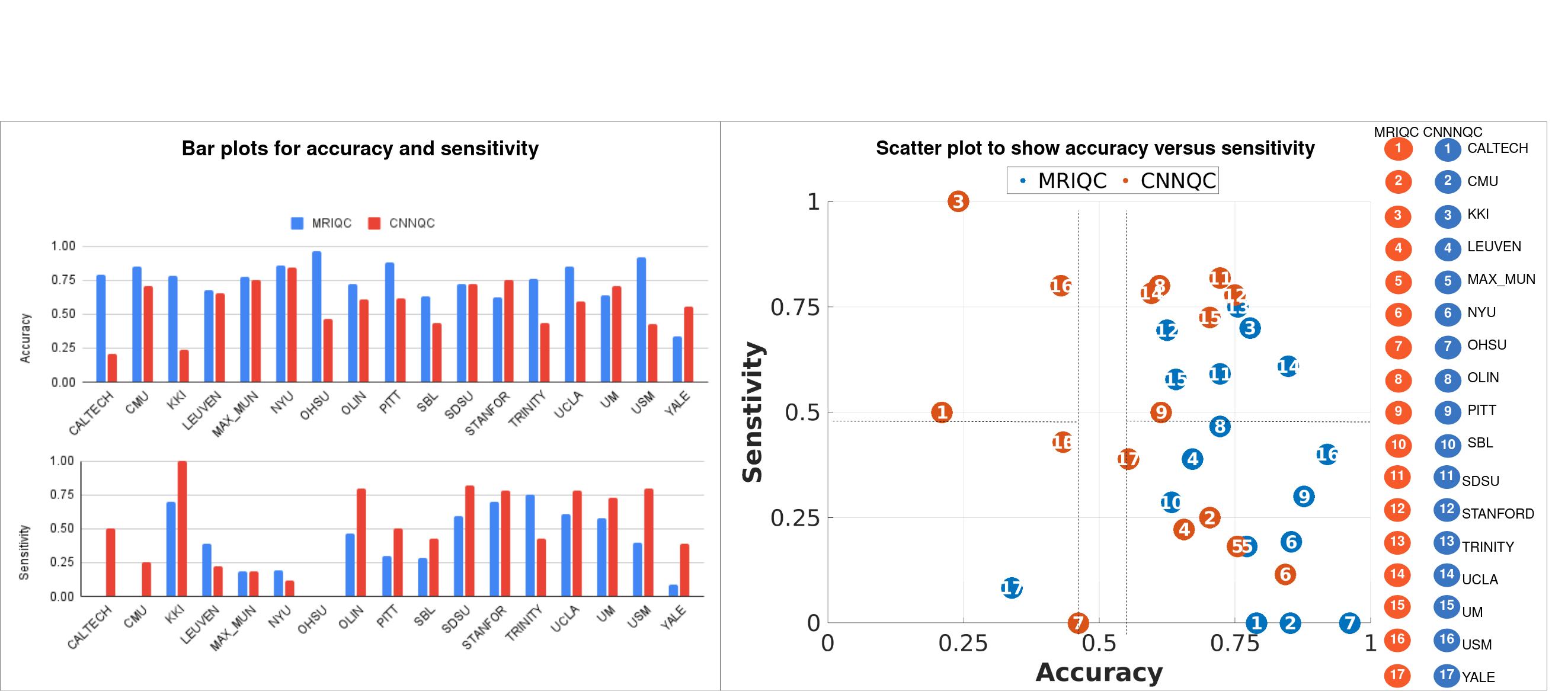
Example good and bad quality images are shown in Fig.2, demonstrating cases where the automated methods agree and disagree on.Fig.3 shows the comparison between two methods based on accuracy and sensitivity, along with scatter plot relating accuracy and sensitivity.
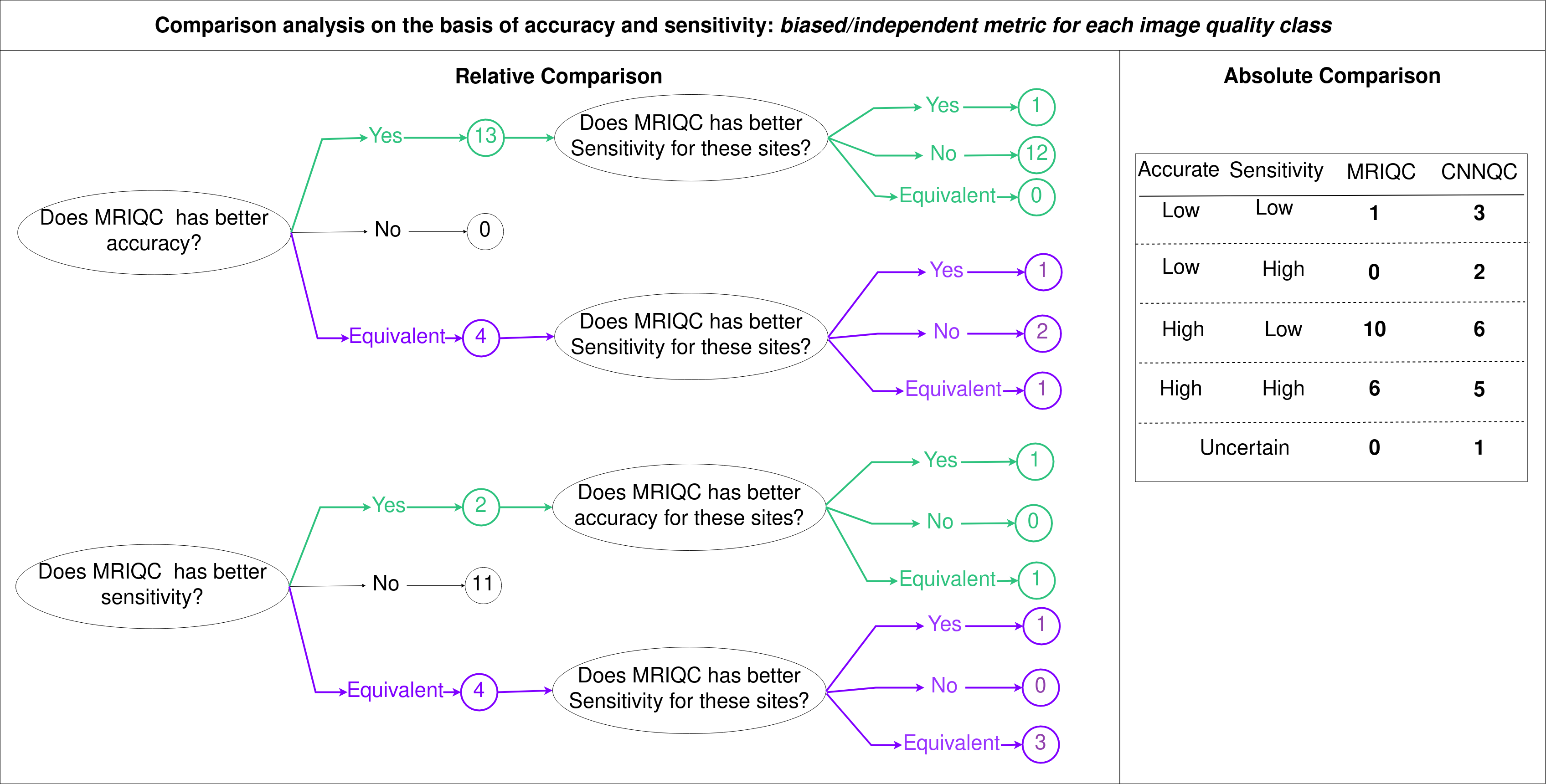
Fig.4 shows the comparison analysis in relative and absolute manner.In relative comparison MRIQC has higher accuracy for 13 sites, while 4 sites show similar accuracy (difference<0.1). Among these 13 sites, CNNQC outperforms MRIQC in sensitivity for 12 of them. Out of the 4 sites with equivalent accuracy, CNNQC has higher MRIQC in sensitivity for 2 sites. This suggests that, although MRIQC is relatively more accurate, CNNQC tends to be more sensitive as compared to each other.Absolute comparison shows that MRIQC has accuracy>0.55 for 16 sites whereas CNNQC achieves similar accuracy for 11 sites. MRIQC has sensitivity >0.5 for 6 sites and CNNQC provides similar sensitivity for 7 sites.
Together, relative and absolute comparison shows that as compared to each other MRIQC might seem more accurate and CNNQC be more sensitive but analyzing the absolute accuracy and sensitivity values suggests both methods are poor.
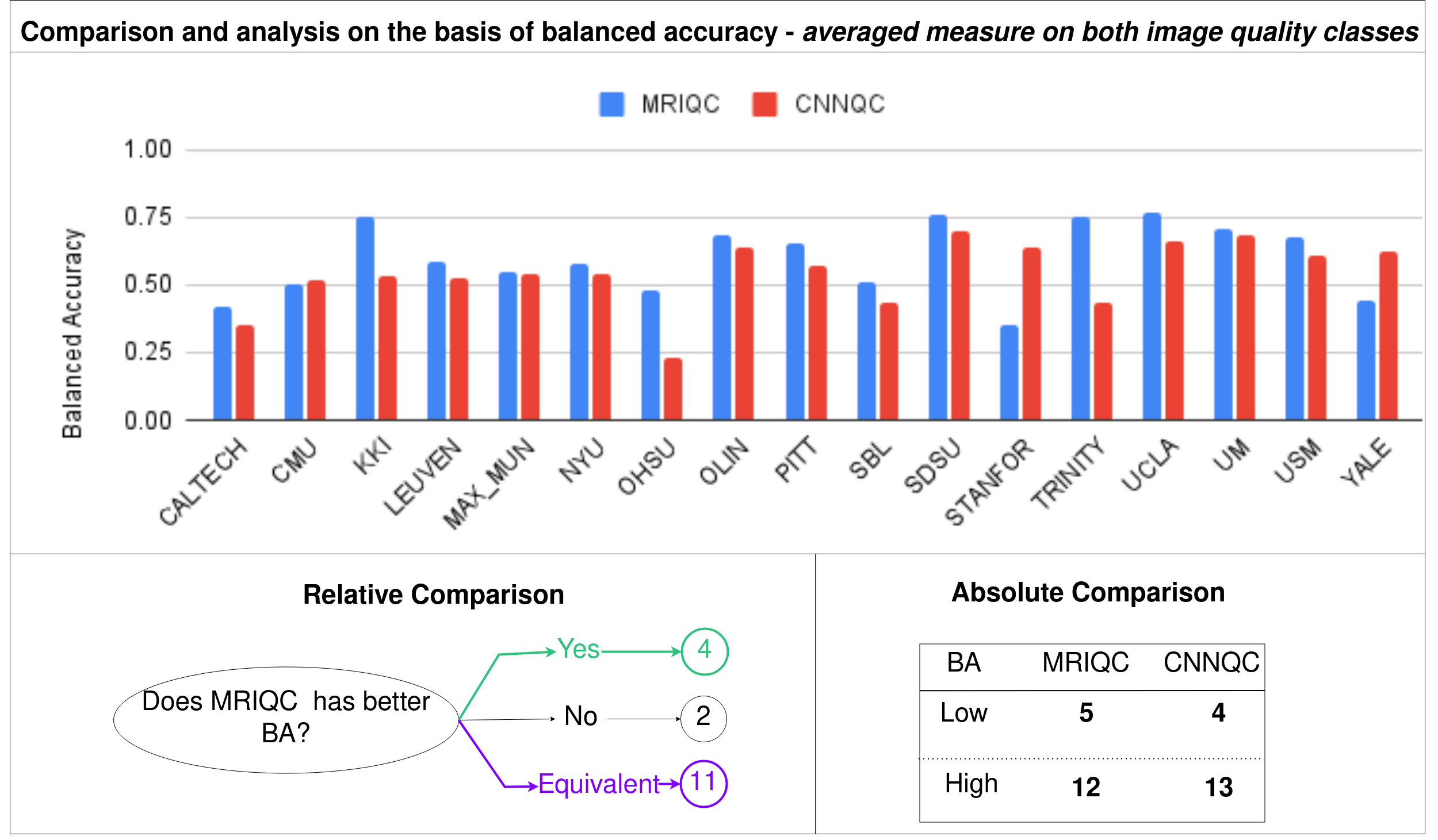
Fig.5 shows the comparison and analysis of MRIQC and CNNQC with respect to BA. When compared with each other, both methods show equivalence with difference in BA less than 0.1. For the 4 sites that have the fewest number of bad images, MRIQC is better than CNNQC, while for the 2 sites that have the highest number of bad images CNNQC provides better BA. In absolute manner, both methods provide BA>0.5 for almost 12 sites but the highest BA does not exceed 0.76 indicating need for improvement.
Discussion
Strong site-to-site variability in sensitivity, accuracy, and balanced accuracy across the 17 sites in the ABIDE dataset indicates the challenges of generalizing automated image quality assessments. Methodologically, MRIQC has a feature normalisation step aiming to reduce this site-wise variability, which may explain fewer low accuracy sites compared to the CNNQC method where this is not explicitly done (although it may be captured in the learnt features). Both methods tend to have biases for either image quality class that is observed in terms of accuracy and sensitivity, and seems equivalent once averaged for both image quality classes. Still, maximum BA=0.76 for both methods indicates significant room and need for improvement, and development of methods that can generalize well on new sites/scanners images.Acknowledgements
We are thankful to Rosetrees Trust (grant UCL-IHE-2020\101) and University College London Hospitals Biomedical Research Centre for the financial support.References
1. Esteban O, Birman D, Schaer M, Koyejo OO, Poldrack RA, Gorgolewski KJ; MRIQC: Advancing the Automatic Prediction of Image Quality in MRI from Unseen Sites; PLOS ONE 12(9):e0184661; doi:10.1371/journal.
2. Sujit SJ, Coronado I, Kamali A, Narayana PA, Gabr RE. Automated image quality evaluation of structural brain MRI using an ensemble of deep learning networks. J Magn Reson Imaging. 2019 Oct;50(4):1260-1267. doi: 10.1002/jmri.26693. Epub 2019 Feb 27. PMID: 30811739; PMCID: PMC6711839.
3. Pál Vakli, Béla Weiss, János Szalma, Péter Barsi, István Gyuricza, Péter Kemenczky, Eszter Somogyi, Ádám Nárai, Viktor Gál, Petra Hermann, Zoltán Vidnyánszky, Automatic brain MRI motion artifact detection based on end-to-end deep learning is similarly effective as traditional machine learning trained on image quality metrics, Medical Image Analysis, Volume 88, 2023.
4. Simona Bottani, Ninon Burgos, Aurélien Maire, Adam Wild, Sebastian Ströer, Didier Dormont, Olivier Colliot, Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse, Medical Image Analysis, Volume 75, 2022.
5. Woodard JP, Carley-Spencer MP. No-Reference image quality metrics for structural MRI. Neuroinformatics. 2006;4(3):243–262. pmid:16943630
Figures
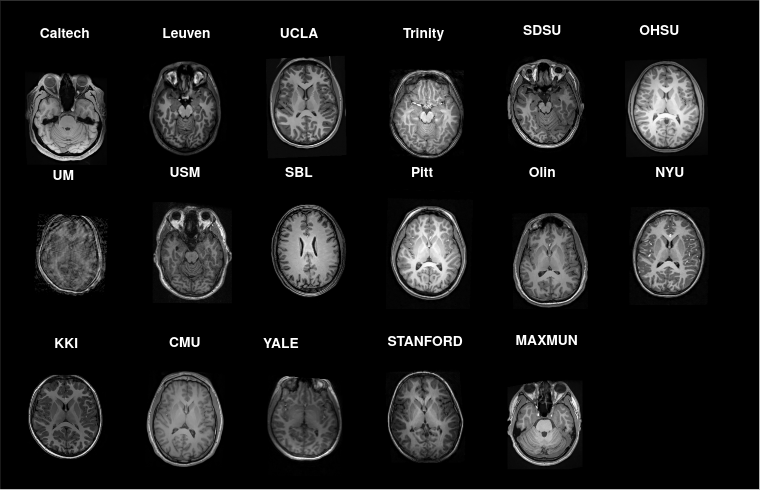
Fig.1: Example axial slice from all 17 sites in the ABIDE dataset showing significant image contrast differences across sites.