4860
Harmonizing Multicenter Datasets: Enhancing Consistency and Longitudinal Alignment using NLP and Realignment Algorithms1Subtle Medical, Menlo Park, CA, United States, 2Radiology, Stanford University, Palo Alto, CA, United States
Synopsis
Keywords: AI/ML Software, Machine Learning/Artificial Intelligence, Natural Language Processing
Motivation: Cohesive multicenter imaging datasets are critical for research, yet variability across institutions poses a significant challenge, especially when aggregating retrospective data for longitudinal disease monitoring.
Goal(s): Here, we present a method for harmonizing multicenter data that produces consistent series descriptions and enhances brain alignment between longitudinal time points.
Approach: We employed an NLP pipeline to standardize series descriptions and an automated algorithm to realign images. We applied these tools to ADNI imaging collected across multiple sites, scanners, and time points.
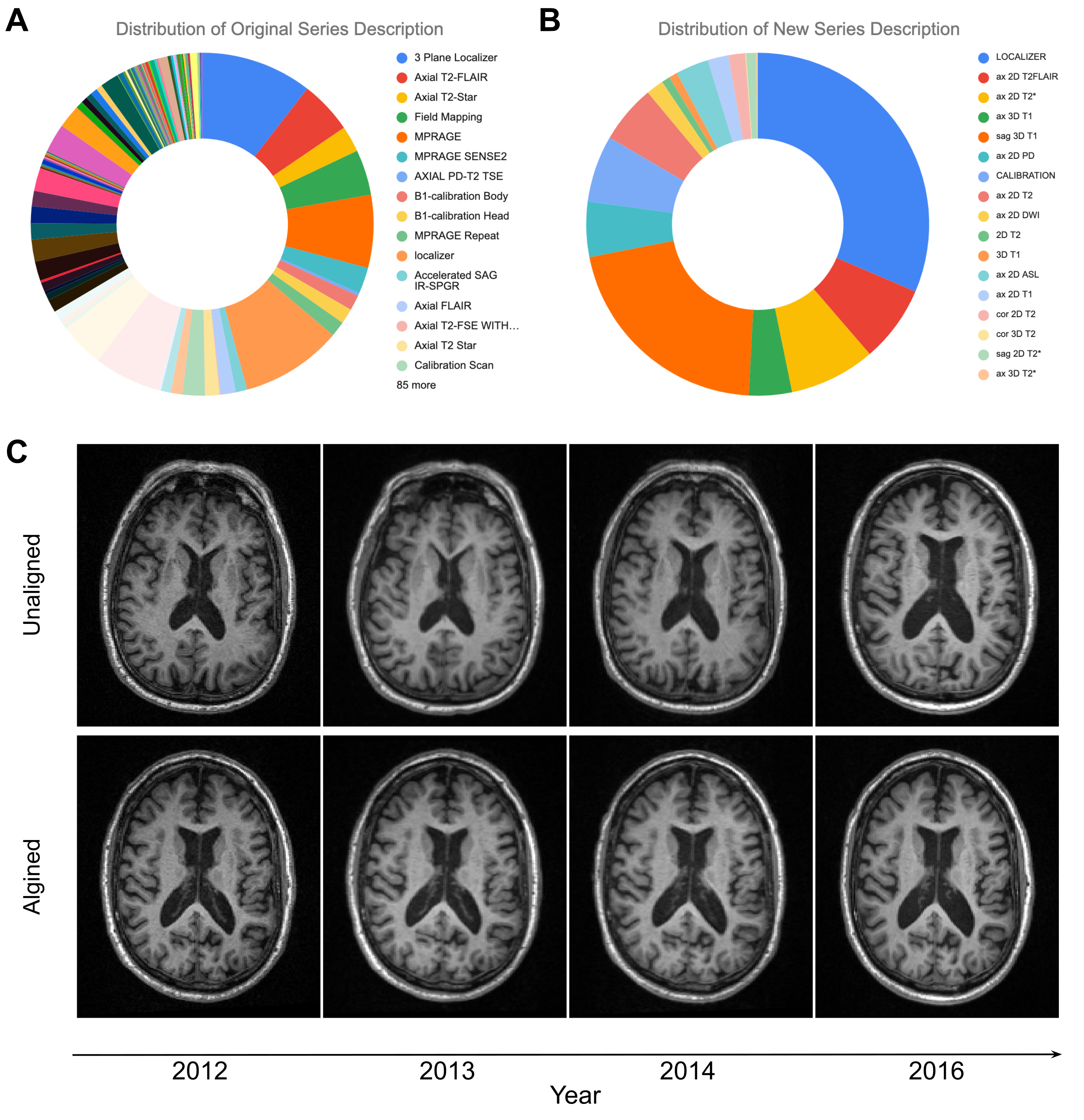
Results: The pipeline consolidated 101 unique series descriptions into 17 standardized descriptions. The alignment algorithm reduced orientation error and improved longitudinal image consistency.
Impact: Our methodology can impact clinical workflows by streamlining multicenter data analysis and enhancing longitudinal disease monitoring. These techniques improve image consistency between time points, which can facilitate disease monitoring and allow radiologists to assess changes in chronic disorders.
Introduction
Integrating multi-center MRI data into a cohesive dataset, especially in a retrospective context, presents substantial challenges in MRI research. Variability in MRI data arises from differences in imaging protocols, naming conventions, and data visualization practices among different institutions. This study introduces an approach that utilizes natural language processing (NLP) and a brain alignment algorithm to enhance dataset uniformity and improve longitudinal disease monitoring.Methods
An NLP pipeline was developed to extract key information from DICOM metadata, including sequence types (e.g., T1, T2, etc.), scan orientations (axial, sagittal, coronal), and acquisition types (2D, 3D). These elements were combined to generate standardized series descriptions (e.g., axial 3D T1). The NLP pipeline and automated brain alignment algorithm were trained and validated using large internal MRI datasets spanning multiple imaging centers. The alignment algorithm employs self-similarity and Scale Invariant Feature Transform (SIFT).1 For evaluation, multicenter longitudinal scans were sampled from the ADNI dataset.2,3 Images were obtained from 42 patients, representing 30 clinical sites and 19 different scanner models. Only subjects with at least two imaging time points were included in the study. Manual labeling of four anatomical structures (anterior and posterior commissures, left and right eye centroids) was performed on 3D T1 images using ITK-SNAP.4 These landmarks were used to determine pitch, roll, and yaw of images relative to the AC-PC line. We compared the alignment of each patient’s initial T1 scan to all follow-up T1 exams. Similarly, peak signal-to-noise ratio (PSNR) was calculated between initial and follow-up T1 exams. PSNR values for unaligned and realigned images were compared using a paired t-test.Results
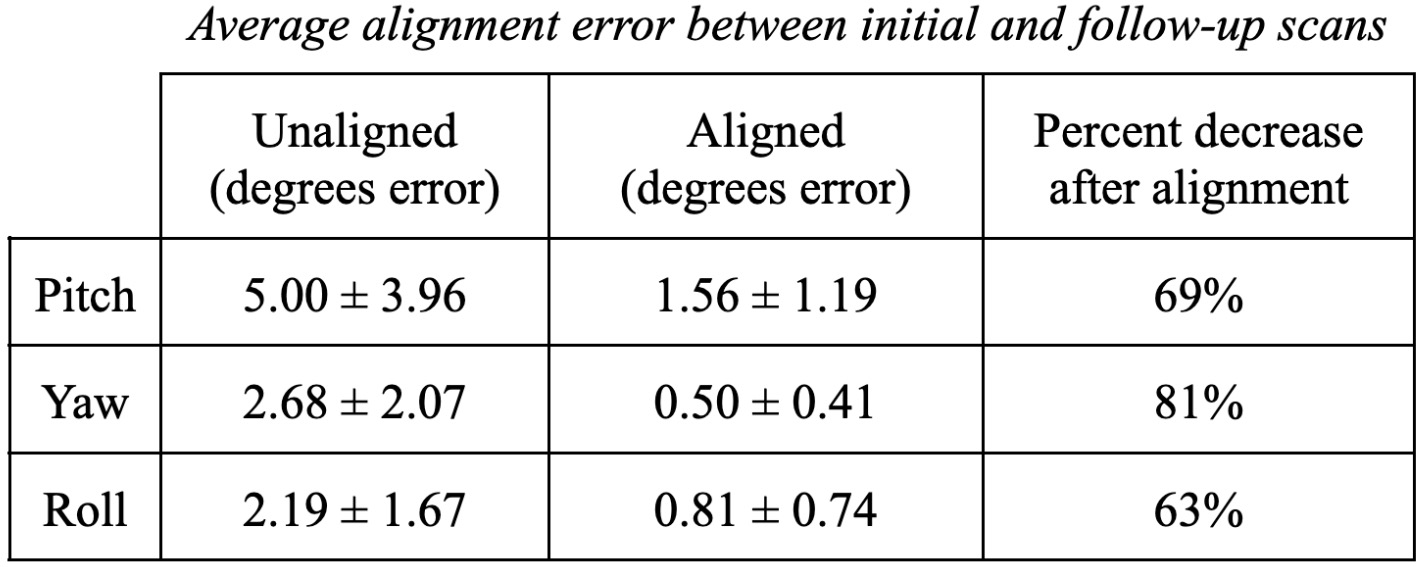
A total of 1381 sequences from 152 scan sessions were evaluated. The NLP pipeline successfully consolidated 101 unique series descriptions (Figure 1A) into 17 standardized descriptions (Figure 1b), covering 9 sequence types. The brain alignment algorithm significantly reduced errors in all three axes: pitch (pre-alignment: 11.9°, post-alignment: 2.1°), roll (pre-alignment: 2.2°, post-alignment: 1.1°), yaw (pre-alignment: 1.9°, post-alignment: 0.7°). Realignment increased the percentage of cases with less than 5° of absolute error from 24.4% to 90% and reduced the maximum error from 33° to less than 8°. When comparing initial and follow-up scans, the algorithm significantly reduced average alignment error in all three axes (Table 1: pitch 69%, yaw 81%, roll 63%). The PSNR between imaging time points increased from 22.7 ± 3.1 dB to 24.3 ± 2.7 dB (paired t-test, p<0.0001) after alignment. Figure 1C illustrates an example of improved alignment between two time points in a subject.Discussion
Heterogeneity in longitudinal data complicates multicenter research studies and can disrupt clinical workflows. The utilization of NLP and realignment algorithms can enhance data consistency and significantly improve alignment between time points, thereby facilitating disease monitoring in MRI research.Conclusion
Using NLP and realignment algorithms to standardized imaging protocols can improve data consistency across multicenter studies and improve clinical workflows, which can lead to improved diagnostic accuracy, better patient outcomes, and more cohesive multicenter clinical research.Acknowledgements
Data used in the preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu). Data collection and sharing for this project was funded in part by the Alzheimer's Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012).References
1. Prabhu, Pooja, et al. "Content-Based Estimation of Brain MRI Tilt in Three Orthogonal Directions." Journal of Digital Imaging 34 (2021): 760-771.
2. Petersen, Ronald Carl, et al. "Alzheimer's disease neuroimaging initiative (ADNI): clinical characterization." Neurology 74.3 (2010): 201-209.
3. Jack Jr, Clifford R., et al. "The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods." Journal of Magnetic Resonance Imaging: An Official Journal of the International Society for Magnetic Resonance in Medicine 27.4 (2008): 685-691.
4. Yushkevich, Paul A., Yang Gao, and Guido Gerig. "ITK-SNAP: An interactive tool for semi-automatic segmentation of multi-modality biomedical images." 2016 38th annual international conference of the IEEE engineering in medicine and biology society (EMBC). IEEE, 2016.
Figures