4854
A multi-scale pyramid residual weight network for medical image fusion1Center for Biomedical Imaging Research, Department of Biomedical Engineering, Tsinghua University, BeiJing, China, 2Department of Biomedical Engineering, Tsinghua University, BeiJing, China, 3Beijing Tsinghua Changgung Hospital, BeiJing, China
Synopsis
Keywords: Diagnosis/Prediction, PET/MR, Artificial Intelligence,Brain
Motivation: At present, the multi-modal fusion image has the problems of weak functional information performance and much noise.
Goal(s): Based on the existing technology, this research increases the retention of functional information and improves the display quality of the fused image.
Approach: In this study, a multi-scale pyramid convolutional neural network model based on residual structure is constructed, which can extract deeper semantic information while retaining shallow context information.
Results: By constructing a new convolutional neural network, the loss of functional information in the fused image is reduced, the noise of the fused image is reduced, and the image quality is improved.
Impact: The multimodal image fusion technology proposed in this paper preserves the texture information of MRI and CT, and the functional information of PET/SPECT at the same time, which makes more dimensions available for clinical diagnosis in the future.
Introduction
Obtaining medical images that contain both functional metabolic information and structural organization details is a challenging task due to the limitations of imaging sensors. Multimodal image fusion has become an important technology to assist clinical diagnosis and surgical navigation by effectively fusing complementary information from different modalities. However, the commonly used fusion methods based on deep learning often have the defect of directly fusing high-frequency detail information and low-frequency context information, which may lead to the former being destroyed by the latter. To solve this problem, a new convolutional neural network, a multi-scale pyramid residual weight network, is proposed, which can fuse high-frequency and low-frequency information simultaneously. This paper proposes an image fusion algorithm based on feature distillation, which can effectively extract and fuse appropriate features to enhance the interaction between context cues and reduce the noise of the fused image. In addition, the proposed method significantly reduces the difference between the fused image and the original image.Methods
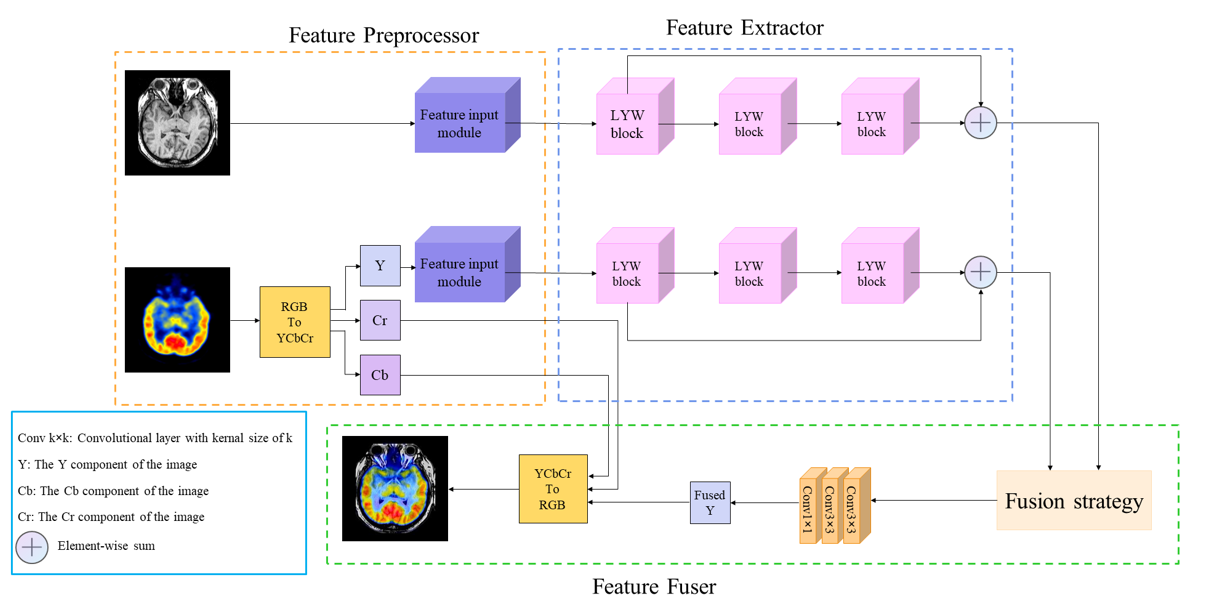
Li et al. proposed a multi-scale dual-branch Residual Attention (MSDRA) network1, which included a feature extraction module, a feature fusion module, and an image reconstruction module. In Li’s approach, the MSDRA block has two branches that extract more features.For PET/SPECT images, preserving functional information is of paramount importance. Chromaticity information, distinct from PET/SPECT, plays a vital role and is translated into the YCbCr color space. This transformation allocates chromaticity details into Y, Cb, and Cr channels. During the fusion process, the Y (intensity) channel is amalgamated with the MRI image, ensuring that the resulting fused image upholds the information distribution strength in the Y channel. In CT images, critical information resides in the dense texture structure of high pixel intensity. Conversely, MRI images require meticulous preservation of intricate texture details. Therefore, the primary features in these distinct image modalities are rooted in chromaticity and texture information. Throughout the fusion process, our goal is twofold: to maintain high-quality data transmission with low noise, to achieve an optimal reflection of functional data, and to maintain rich textures to retain necessary soft tissue information. We proposed that the network structure is meticulously designed to safeguard high-quality chromaticity and texture information.We present the network architecture for medical image fusion. The network framework is shown in Figure 1. The network includes three modules: feature preprocessor, extractor, and fuser. Firstly, the image features were extracted through the feature input module. To extract more levels of semantic information, as shown in Figure 2, a three-branch feature extractor is used to extract features., and the output is fused. We then use three modules in series to extract the input features. To make the output image contain low-dimensional and high-dimensional information, a jump connection is used between the low-level features and the deep features. Finally, the fusion strategy in the image fusion module was used to fuse the 64-dimensional features of the input image, and the output was reconstructed by two 3*3 convolution kernels and one 1*1 convolution kernel to obtain the fused image. Each detail of our algorithm is presented in the following subsections. In the experiments, all the images are from the Whole Brain Atlas created by Harvard Medical School. The size of the MRI, SPECT, PET, and CT images is 256 × 256 pixels, and the images are coregistered. The Net is implemented by PyTorch with an NVIDIA RTX 3090 GPU. For quantitative comparison, we use six metrics to evaluate the fusion performance, including SSIM2, Peak signal-to-noise ratio, Mutual information(MI)3, Fowlkes-Mallows Index(FMI)4, Adjusted rand index, Correlation coefficient(CC)5.Results
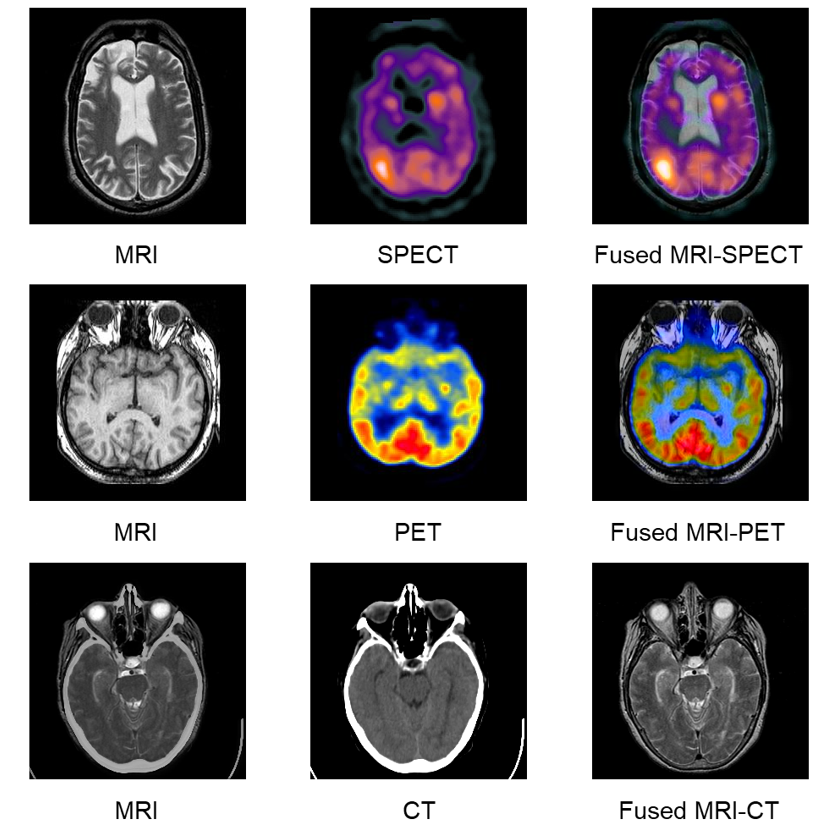
In the experiment, we prepared 329 pairs of SPECT-MRI, 318 pairs of PET-MRI, 184 pairs of CT-MRI images for training, and 30 pairs of SPECT-MRI, PET-MRI, and CT-MRI images for testing. Figure 2 shows the fusion results of MRI-SPECT, MRI-PET, and MRI-CT. It can be seen that more texture information and functional information are retained in the fusion results of MRI and PET/SPECT, and more dense texture information is retained in the fusion results of MRI and CT. Figure 3 quantitatively shows the effect of fusion, and it can be seen that the fused image has a better performance in image quality.Conclusion
The quantitative and qualitative effects of the three-branch network on image fusion are initially explored. Preliminary experimental results show that the three-branch network has good image fusion performance. The fused image preserves more functional information about PET/SPECT on top of preserving the details of MRI. At the same time, the texture information in the CT image is preserved and the image quality is improved.Acknowledgements
No acknowledgement found.References
[1] Li, W., Peng, X., Fu, J., Wang, G., Huang, Y., & Chao, F. (2022). A multiscale double-branch residual attention network for anatomical–functional medical image fusion. Computers in Biology and Medicine, 141, 105005.
[2] Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P. (2004). Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4), 600-612.
[3] Qu, G., Zhang, D., & Yan, P. (2002). Information measure for performance of image fusion. Electronics letters, 38(7), 1.
[4] Fowlkes, E. B., & Mallows, C. L. (1983). A method for comparing two hierarchical clusterings. Journal of the American statistical association, 78(383), 553-569.
[5] Deshmukh, M., & Bhosale, U. (2010). Image fusion and image quality assessment of fused images. International Journal of Image Processing (IJIP), 4(5), 484.
Figures