4847
Fully Automatic Vertebrae and Spinal Cord Segmentation Using a Hybrid Approach Combining nnU-Net and Iterative Algorithm1Multiple Sclerosis Center, Sheba Medical Center, Ramat-Gan, Israel, 2Arrow Program for Medical Research Education, Sheba Medical Center, Ramat-Gan, Israel, 3Adelson School of Medicine, Ariel University, Ariel, Israel, 4NeuroPoly Lab, Institute of Biomedical Engineering, Polytechnique Montreal, Montreal, QC, Canada, 5Mila - Quebec AI Institute, Montreal, QC, Canada, 6Faculty of Medicine, Tel-Aviv University, Tel-Aviv, Israel, 7Queen Square Multiple Sclerosis Centre, Department of Neuroinflammation, University College London, London, United Kingdom, 8Queen Square Institute of Neurology, Faculty of Brain Sciences, University College London, London, United Kingdom, 9Centre for Medical Image Computing (CMIC), Department of Computer Science, Faculty of Engineering Sciences, University College London, London, United Kingdom, 10Functional Neuroimaging Unit, CRIUGM, Université de Montréal, Montreal, QC, Canada, 11Centre de recherche du CHU Sainte-Justine, Université de Montréal, Montreal, QC, Canada
Synopsis
Keywords: AI/ML Software, Segmentation
Motivation: 3D visualisation of the spinal cord and vertebrae anatomy is critical for treatment planning and assessment of cord atrophy in neurodegenerative and traumatic diseases.
Goal(s): Develop a fully automatic segmentation of the whole spinal cord, vertebrae and discs.
Approach: The hybrid method combines a nnU-Net with an iterative processing algorithm with Spinal Cord Toolbox to conveniently generate ground truth labels. We used 3D T1w and T2w scans from three different databases.
Results: A validation Dice score of 0.928 was obtained (averaged across contrasts, classes and datasets), suggesting promising segmentation accuracy and capabilities for generalisation given the use of multi-site/multi-vendor datasets.
Impact: The fully automatic segmentation of the spine and spinal cord will pinpoint pathologies at specific vertebrae level, offering visualization for surgery preparation. This could also refine segmentation of substructures like multiple sclerosis lesions and tumors, inspiring solutions for related issues.
Background
Recent advancements have been made in employing deep learning models for medical image segmentation. Yet, a gap exists in the automatic segmentation and labelling of all vertebrae and intervertebral discs (IVDs) in MRI scans: either the tools are not publicly available or they fail to generalise to multiple contrasts and resolutions. We propose a novel hybrid approach integrating nnU-Net1 with an iterative algorithm for segmenting vertebrae, IVDs, spinal cord, and spinal canal. The method is open-source and will soon be part of Spinal Cord Toolbox2. This new segmentation tool has the potential to aid clinicians in visualising the complete spine anatomy for diagnosis and treatment planning. Moreover, this segmentation model could be used to refine the segmentation of pathological sub-structure as a way to mitigate class imbalance (e.g., multiple sclerosis lesions, tumours).Material and Methods
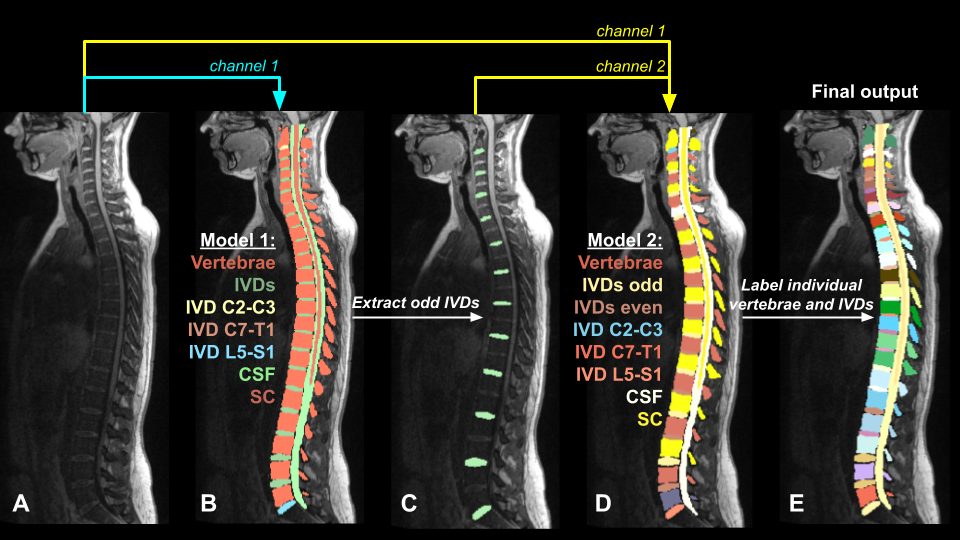
Multi-site and multi-contrast MRI were used for this project: T1w (n=61) and T2w (n=60) stitched images (2-3 slabs) from a private database, covering the cervical, thoracic and lumbar areas; T1w (n=285) and T2w (n=286) data from the spine-generic project3; T1w (n=196) and T2w (n=251) data from the SPIDER project4. First, to obtain the complex labels for each structure (vertebrae, IVDs, spinal cord, CSF), images were registered to the PAM50 template5 using the Spinal Cord Toolbox (SCT)2,6. The inverse warping field was then used to warp PAM50’s atlas—manually modified using 3D Slicer (https://www.slicer.org/)— to the subjects’ native space. For model training, we used the nnU-Net v2 framework to train a 3D model with 5-fold cross-validation. To tackle the challenge of having many classes and class imbalance, we developed a two-step training process. A first model (model 1) was trained (single input channel: image) to identify 4 classes (IVDs, vertebrae, spinal cord and spinal canal) as well as specific IVDs (C2-C3, C7-T1 and L5-S1) representing key anatomical landmarks along the spine, so 7 classes in total (Figure 1A). The output segmentation was processed using an algorithm that distinguished odd and even IVDs based on the C2-C3, C7-T1 and L5-S1 IVD labels output by the model (Figure 1B). Then, a second nnU-Net model (model 2) was trained (two input channels: 1=image, 2=odd IVDs), to output 12 classes (Figure 1C). Finally, the output of model 2 was processed in order to assign an individual label value to each vertebrae and IVD in the final segmentation mask (Figure 1D).Results
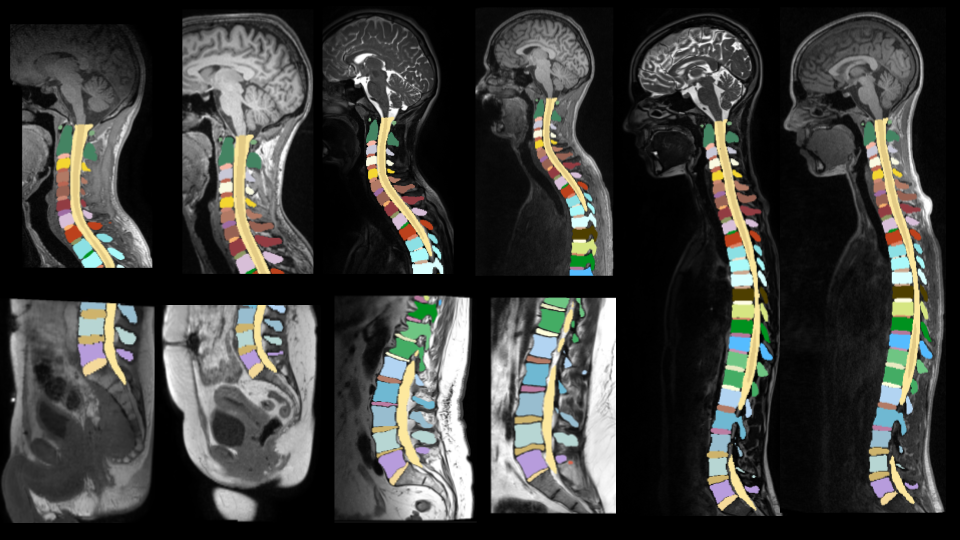
The first model used for segmentation of vertebrae, IVDs, spinal cord, and spinal canal obtained an average validation Dice score of 0.873. The second model, which used an additional input (odd IVDs) yielded an average validation Dice score of 0.928.While using a single model for individual label value to each vertebrae and IVD performed very well on cervical and upper thoracic levels, it achieved lower performances in the lower thoracic region, assumed to be caused by fewer images for this region (only 121 images). However, the results show that our multi-step approach allows for improved performance (Figure 2) by considering even and odd IVDs separately.
Conclusions
A total of 1139 MRI volumes (542 T1w, 597 T2w) were used to train two sequential nnU-Net models with 5-fold cross-validation. The number of scans is similar to the TotalSegmentator CT model (n=1204)7. The proposed hybrid methodology for generating complex ground truth labels and training a deep learning segmentation model has the potential to improve the segmentation and labelling accuracy of vertebrae and associated structures in MRI scans, ultimately improving clinical workflows and surgical planning. The next step is to make the model available within SCT.Acknowledgements
Funded by the Canada Research Chair in Quantitative Magnetic Resonance Imaging [CRC-2020-00179], the Canadian Institute of Health Research [PJT-190258], the Canada Foundation for Innovation [32454, 34824], the Fonds de Recherche du Québec - Santé [322736, 324636], the Natural Sciences and Engineering Research Council of Canada [RGPIN-2019-07244], the Canada First Research Excellence Fund (IVADO and TransMedTech), the Courtois NeuroMod project, the Quebec BioImaging Network [5886, 35450], INSPIRED (Spinal Research, UK; Wings for Life, Austria; Craig H. Neilsen Foundation, USA), Mila - Tech Transfer Funding Program.References
1. Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J. & Maier-Hein, K. H. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211 (2020).
2. SCT: Spinal Cord Toolbox, an open-source software for processing spinal cord MRI data. Neuroimage 145, 24–43 (2017).
3. Cohen-Adad, J. et al. Open-access quantitative MRI data of the spinal cord and reproducibility across participants, sites and manufacturers. Scientific Data 8, 1–17 (2021).
4. SPIDER - Lumbar spine segmentation in MR images: a dataset and a public benchmark. doi:10.5281/zenodo.8009680.
5. PAM50: Unbiased multimodal template of the brainstem and spinal cord aligned with the ICBM152 space. Neuroimage 165, 170–179 (2018).
6. Automatic segmentation of the spinal cord and intramedullary multiple sclerosis lesions with convolutional neural networks. Neuroimage 184, 901–915 (2019).
7. Wasserthal, J. et al. TotalSegmentator: Robust Segmentation of 104 Anatomic Structures in CT Images. Radiol Artif Intell 5, e230024 (2023).
Figures