4663
Transferable Variational Feedback Network for Accelerated MRI Reconstruction1School of Computing and Augmented Intelligence, Arizona State University, Tempe, AZ, United States, 2Department of Radiology, Mayo Clinic, Phoenix, AZ, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence, Transfer learning, Generalization
Motivation: Long MR procedure times often result in a shortage of patient data for specific cases, affecting the performance of data-dependent deep networks. Transfer learning offers a remedy, enabling pretrained models to adapt to new domains with limited data availability.
Goal(s): Our goal is to create a network capable of producing clinically acceptable reconstructions with limited data.
Approach: We leverage representation learning to refine low-resolution data and enhance final reconstructions in data-limited scenarios.
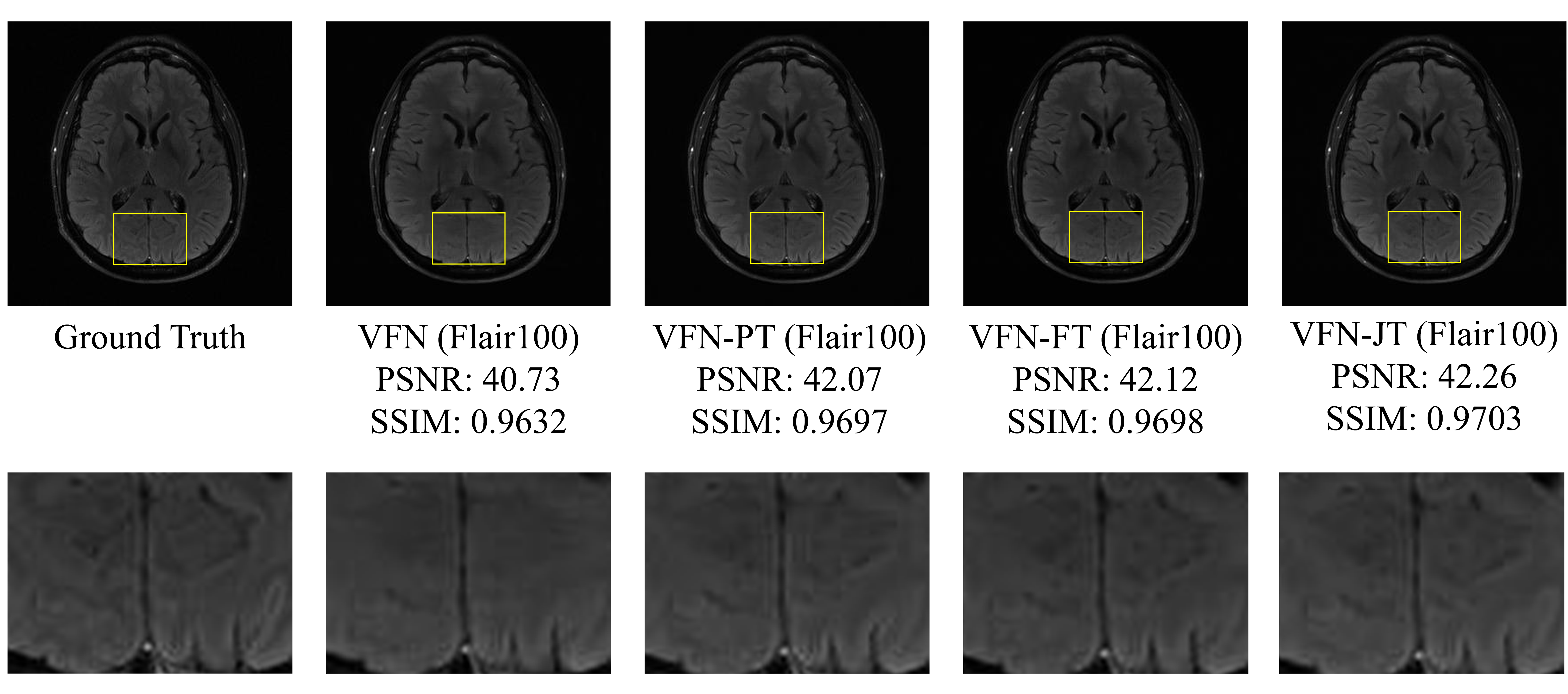
Results: Successful transfers with 100 and 40 training sample sets were achieved. Both networks achieve comparable results to the large dataset (240 samples) trained network.
Impact: Our approach has broader clinical uses beyond acquisition protocols, extending to vendor differences and scenarios with limited access to disease scans due to privacy concerns. It presents an opportunity to tackle limited data generalization challenges without adding architectural complexity.
Introduction
Deep neural networks offer significant promise in fast MRI reconstruction[1-11], particularly for high acceleration factors. However, they demand extensive data, often from the same scanner protocol as the test set, which is frequently scarce[12, 13]. To address this, we introduce a Transferable Variational Feedback Network that leverages pretrained models to extract meaningful features and enhance low-resolution data. Our study demonstrates that this approach can produce high-quality reconstructions even with limited training data, making it a valuable tool for accelerating MRI reconstruction.Methods
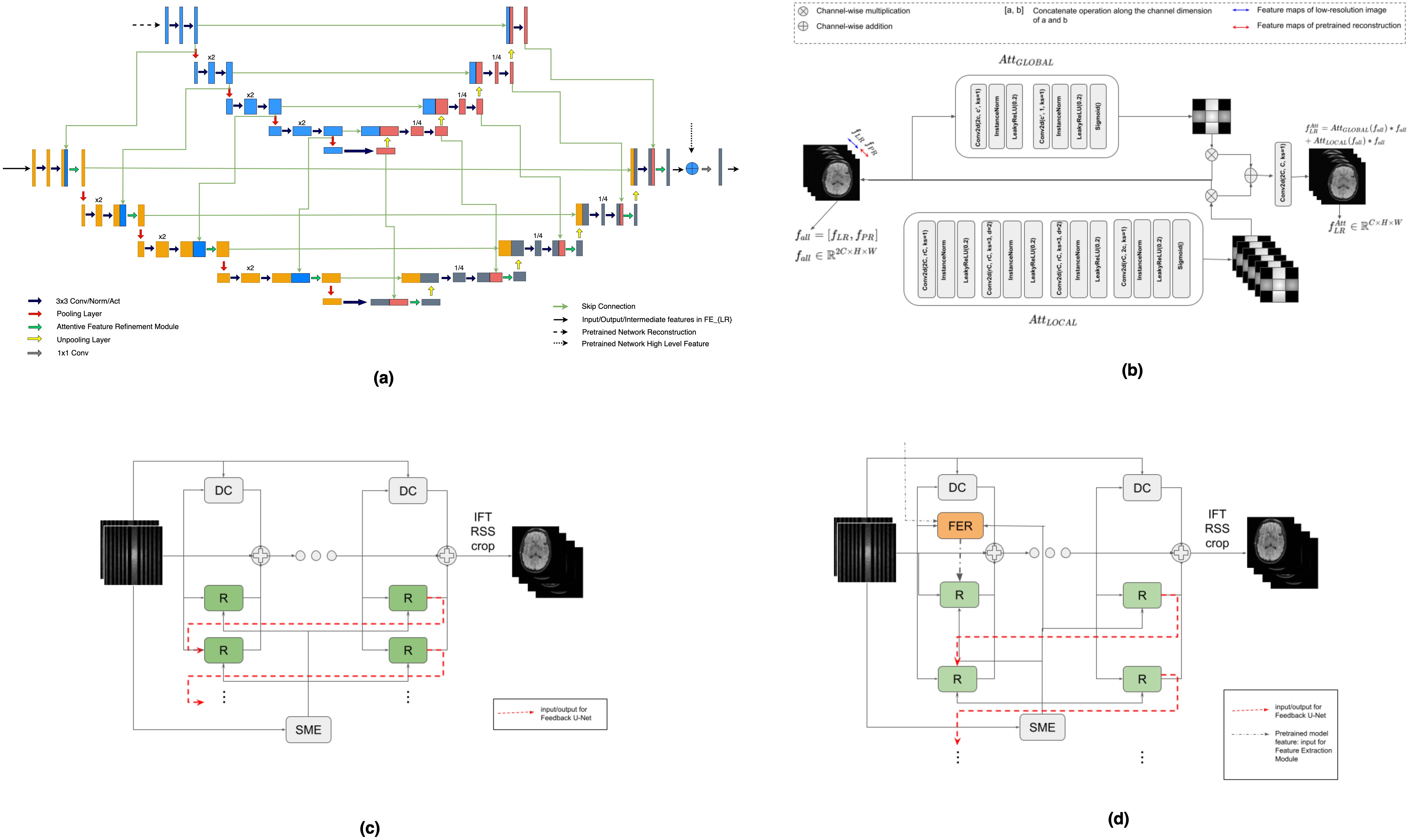
In this study, we employ a Variational Feedback Network[4] with a feature-transfer module to create a transferable version. The feature extraction module denoted as $$$FER(.)$$$, uses both conventional U-Net and multilevel attentive U-Net networks for feature extraction from pretrained reconstructions and refining zero-filled reconstructions. High-frequency features from pretrained reconstructions are acquired by a traditional U-Net network ($$$FE_{PR}$$$), while a modified multilevel attentive U-Net structure ($$$FR_{LR}$$$) refines low-resolution features for high-frequency details selection. $$$FE_{PR}$$$ includes an encoder-decoder architecture with specific layers and depth settings. The encoder uses "Conv-Conv-Pool" combinations with normalization[15] and leaky ReLU[16] layers, while the decoder consists of "Unpool-Conv-Conv" modules with skip connections from the encoder at the chosen depth, which is set to $$$D=4$$$ in our approach. $$$FR_{LR}$$$ shares a similar architecture with $$$FE_{PR}$$$, but with some slight modifications. It's a multi-level attentive Unet, with each level following a pattern of Conv-Conv-Skip-Att-Pool. This process is applied at various encoder and decoder depths, combining low-frequency and high-frequency features to optimize using high-frequency features from pretrained reconstructions. Figures of the proposed $$$FER(.)$$$ and the attention module $$$Att(.)$$$ are illustrated in Figure 1 (a, b). Figure 1 (c) and (d) represent the original and proposed transferable VFN architecture.Results
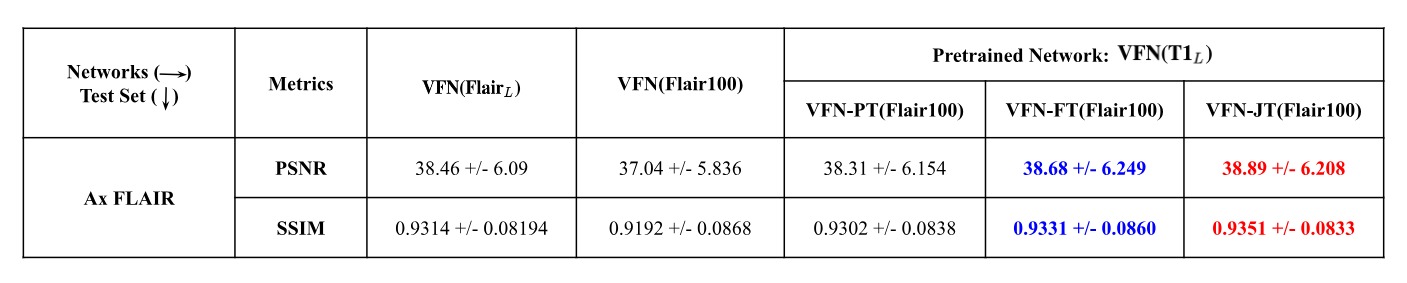
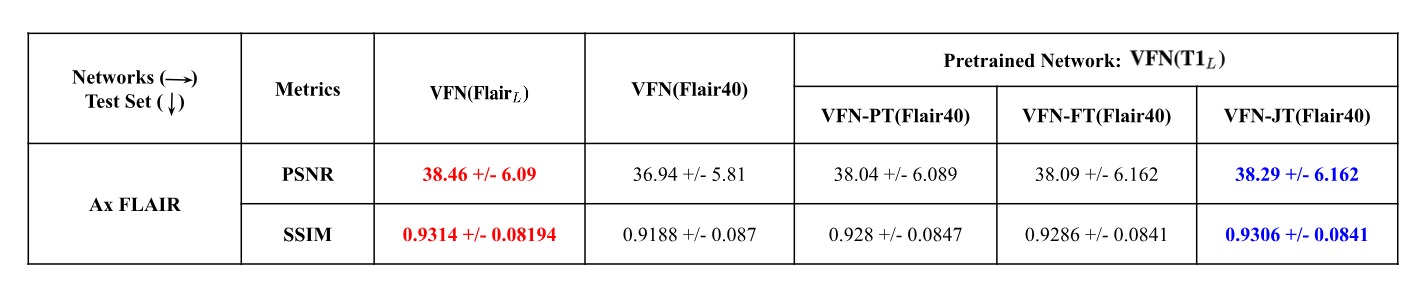
This study examines the transferability of the T1 sequence to FLAIR scans using the Facebook-NYU dataset[17]. We create large brain anatomy training datasets ($$$\text{T1}_{L}$$$ and $$$\text{Flair}_{L}$$$) with 240 samples. The validation (50 samples) and testing (40 samples) sets are created from the validation dataset to access the ground truth for quantitative evaluation. To evaluate the performance of the transfer learning algorithm with limited data, we create the following configurations of training data for Flair:- $$$\text{Flair}_{100}$$$ → Training samples: 100, Validation: 30
- $$$\text{Flair}_{40}$$$ → Training samples: 40, Validation:10
For performance evaluation, we compare the reconstructions from the following networks:
- $$$\text{VFN}(\text{Flair}_{N})$$$ → VFN network trained from scratch on $$$\text{Flair}_N$$$, where $$$N \in {100, 40}$$$
- $$$\text{VFN-PT}(\text{Flair}_{N})$$$ → Assuming we have access to a large pretrained network, such as $$$\text{VFN}(\text{T1}_{L})$$$, we finetune the weights of the pretrained network with $$$\text{Flair}_N$$$.
- $$$\text{VFN-FT}(\text{Flair}_{N})$$$ → The “feature transfer” mode of our proposed algorithm where $$$\text{VFN}(\text{T1}_{L})$$$ is used as a reconstruction retrieval system, and the FER module is used to refine the LR reconstruction. Parameters are initialized randomly, and the network is trained on $$$\text{Flair}_N$$$.
- $$$\text{VFN-JT}(\text{Flair}_{N})$$$ → The “joint transfer” mode of our proposed algorithm where $$$\text{VFN}(\text{T1}_{L})$$$ is used as a reconstruction retrieval system, and the FER module is used to refine the LR reconstruction. Parameters are initialized with $$$\text{VFN}(\text{T1}_{L})$$$, and the network is trained on $$$\text{Flair}_N$$$.
Discussion
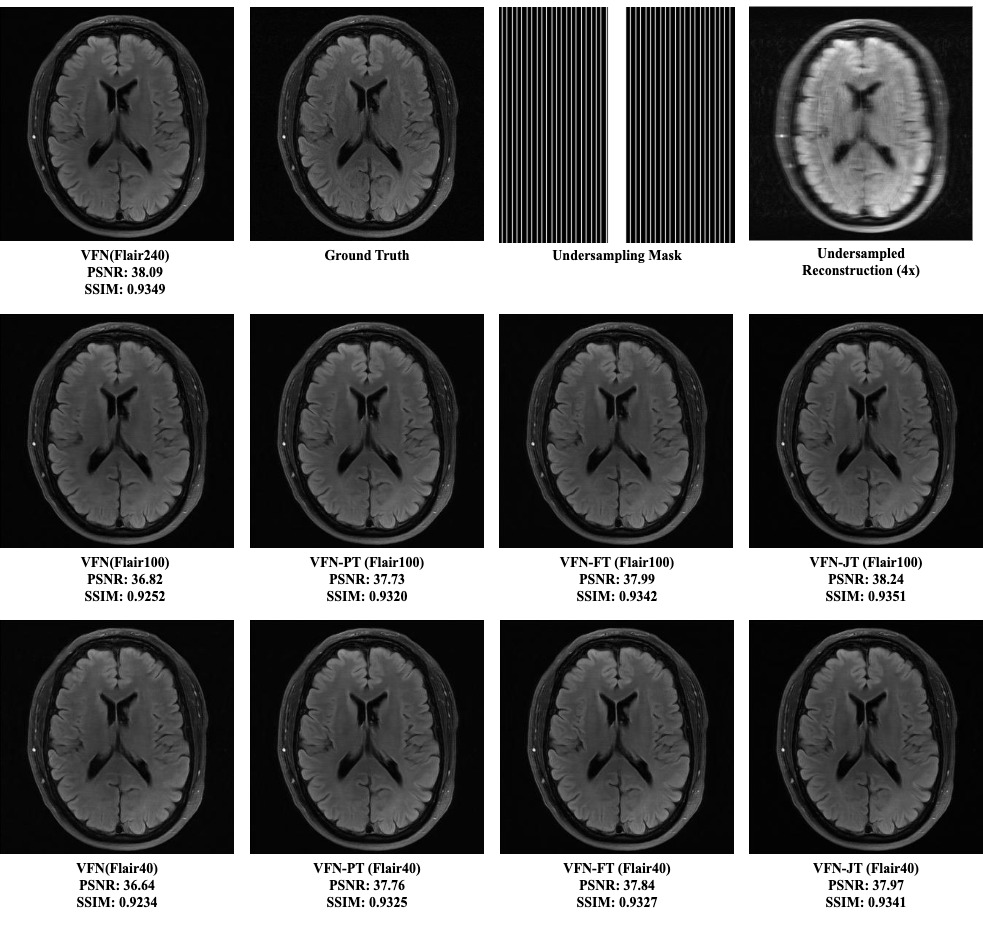
We analyze the results in Tables 1 and 2, leading to the following conclusions:- Transferring knowledge from the T1-trained network to Flair data (with limited samples) leads to a positive representation transfer and, consequently, a performance boost. For $$$\text{Flair}_{100}$$$ and $$$\text{Flair}_{40}$$$, we observe a boost of (1.7 dB, 2.7%) and (1.35dB, 1.2%) in PSNR and SSIM compared to their base models trained only on limited data, respectively. Our proposed algorithm performs marginally better than parameter finetuning due to the explicit feature transfer and refinement.
- In addition to the performance boost of $$$\text{Flair}_{100(/40)}$$$ in the transfer models, it also performs comparably to $$$\text{VFN}(\text{Flair}_{L}$$$), which showcases the effectiveness of our method in limited data scenarios.
Conclusion
This study introduces a transferable variational feedback network inspired by representation learning and subsequent refinement. Our proposed algorithm successfully transfers information from T1 to Flair, and we assess its effectiveness on the VFN architecture through experiments on different data configurations. Future directions for this work include 1) examining the connection between source pretraining and finetuning datasets and 2) evaluating the architecture's performance in diverse scenarios like vendor transfer and healthy-to-tumor data transfer.Acknowledgements
No acknowledgement found.References
- Ding, P. L. K., Li, B., & Chang, K. (2017, September). Convex dictionary learning for single image super-resolution. In 2017 IEEE International Conference on Image Processing (ICIP) (pp. 4058-4062). IEEE.
- Yang, J., Wang, Z., Lin, Z., Cohen, S., & Huang, T. (2012). Coupled dictionary training for image super-resolution. IEEE transactions on image processing, 21(8), 3467-3478.
- Hammernik, K., Klatzer, T., Kobler, E., Recht, M. P., Sodickson, D. K., Pock, T., & Knoll, F. (2018). Learning a variational network for reconstruction of accelerated MRI data. Magnetic resonance in medicine, 79(6), 3055-3071.
- P. L. K. Ding, R. Paul, A. Patel, Y. Zhou, and B. Li. Variational feedback network for accelerated mri reconstruction. ISMRM SMRT Annual Meeting Exhibition 2021. Available: https://doi.org/10.13140/RG.2.2.26769.10087
- Liang, D., Cheng, J., Ke, Z., & Ying, L. Deep MRI Reconstruction: Unrolled optimization algorithms meet neural networks. arXiv 2019. arXiv preprint arXiv:1907.11711.
- Putzky, P., & Welling, M. (2019). Invert to learn to invert. Advances in neural information processing systems, 32.
- Putzky, P., Karkalousos, D., Teuwen, J., Miriakov, N., Bakker, B., Caan, M., & Welling, M. (2019). i-RIM applied to the fastMRI challenge. arXiv preprint arXiv:1910.08952.
- Schlemper, J., Caballero, J., Hajnal, J. V., Price, A., & Rueckert, D. (2017). A deep cascade of convolutional neural networks for MR image reconstruction. In Information Processing in Medical Imaging: 25th International Conference, IPMI 2017, Boone, NC, USA, June 25-30, 2017, Proceedings 25 (pp. 647-658). Springer International Publishing.
- Wang, S., Su, Z., Ying, L., Peng, X., Zhu, S., Liang, F., ... & Liang, D. (2016, April). Accelerating magnetic resonance imaging via deep learning. In 2016 IEEE 13th international symposium on biomedical imaging (ISBI) (pp. 514-517). IEEE.
- Kwon, K., Kim, D., & Park, H. (2017). A parallel MR imaging method using multilayer perceptron. Medical physics, 44(12), 6209-6224.
- Sriram, A., Zbontar, J., Murrell, T., Defazio, A., Zitnick, C. L., Yakubova, N., ... & Johnson, P. (2020). End-to-end variational networks for accelerated MRI reconstruction. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part II 23 (pp. 64-73). Springer International Publishing.
- Muckley, M. J., Riemenschneider, B., Radmanesh, A., Kim, S., Jeong, G., Ko, J., ... & Knoll, F. (2021). Results of the 2020 fastMRI challenge for machine learning MR image reconstruction. IEEE transactions on medical imaging, 40(9), 2306-2317.
- Raghu, M., Zhang, C., Kleinberg, J., & Bengio, S. (2019). Transfusion: Understanding transfer learning for medical imaging. Advances in neural information processing systems, 32.
- Wang, Z., Simoncelli, E. P., & Bovik, A. C. (2003, November). Multiscale structural similarity for image quality assessment. In The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003 (Vol. 2, pp. 1398-1402). Ieee.
- Ulyanov, D., Vedaldi, A., & Lempitsky, V. (2016). Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022.
- Maas, A. L., Hannun, A. Y., & Ng, A. Y. (2013, June). Rectifier nonlinearities improve neural network acoustic models. In Proc. icml (Vol. 30, No. 1, p. 3).
- Zbontar, J., Knoll, F., Sriram, A., Murrell, T., Huang, Z., Muckley, M. J., ... & Lui, Y. W. (2018). fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:1811.08839.
Figures