4639
Performance Study and Optimization of an MRI Motion-Compensated Reconstruction Program1IADI, INSERM U1254, Université de Lorraine, Nancy, France, 2CIC-IT, INSERM 1433, Université de Lorraine and CHRU Nancy, Nancy, France
Synopsis
Keywords: Motion Correction, Breast, MRI Hardware, CPU-GPU
Motivation: MRI motion-compensated reconstruction programs rely on several computationally intensive algorithms. For clinical use, they need to use efficiently the computational resources of compute nodes to achieve a good performance.
Goal(s): Evaluate the performance of a program across architectures and optimize its execution without any code modification.
Approach: We investigate the different parallelization paradigms. We use the roofline model, and the performance profiling tools to derive the architectural efficiency on CPU. A Matlab GPU implementation of the reconstruction kernel is used to draw comparisons.
Results: The optimal parallel mapping reduces considerably the reconstruction time. Moreover, GPUs don’t outperform CPUs in every reconstruction problem.
Impact: We demonstrate the importance of micro-architectural study in the overall behavior of MRI motion-compensated reconstruction codes. This study provides insights about how to select the most suitable architecture to a given code, depending on its hardware limitations.
Introduction
Recent advances in MRI motion-compensated programs lead to numerous implementation challenges to reduce the reconstruction time [1]. To overcome the volume of acquisition data, and the computational complexity of such algorithms, High Performance Computing systems are required. As the power of HPC systems is increasing over the years, scenarios of non-optimal use of the processor’s micro-architecture happen frequently [2]. Runtime is a major problem in MRI, as a short time-to-image is required in clinical practice. Usually, implementation details and runtime variations are neglected. In this work, we use the roofline model [3] to investigate the performance of the Generalized Reconstruction by Inversion of Coupled Systems (GRICS) [4] software, in terms of Floating-Point-Operations per second (FLOP/s) and elapsed time. Then we optimize its execution on a CPU workstation. Finally, a GPU-Matlab implementation of the reconstruction kernel is considered to compare the CPU/GPU performances.Methods
GRICS is a C/C++ software. Its most computationally intensive part is the conjugate gradient linear solvers; The application of the operator EHE comprises an outer loop on motion states and an inner loop on coil receivers [4]. $$ E^{H}E = \sum\limits_{\substack{t=1}}^{N_{t}}T_{t}^{H}\left(\sum\limits_{\substack{c=1}}^{N_{c}} C_{c}^{H}F^{H}S_{t}^{H}S_{t}FC_{c}\right)T_{t}.$$Two parallel implementations of GRICS are studied: OpenMP implementation where the Nc coils are distributed over OpenMP threads, and hybrid implementation where the Nc coils are distributed over OpenMP threads, and the Nt motion states are distributed using MPI. The tests are done on two CPU architectures, Intel-Xeon-Gold-6140 and AMD-EPYC-75F3. The reconstruction was tested on patient taken from data of publication[5].
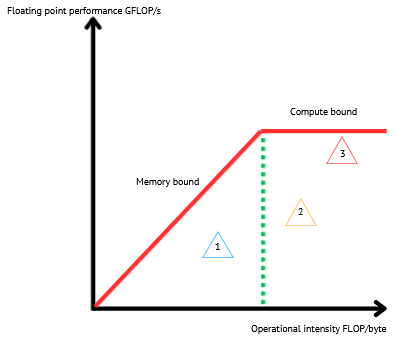
The roofline model is a powerful tool to visualize the performance P of a code running on a micro-architecture. It relies on three concepts: The peak performance Pm in GFLOP/s. The memories bandwidth Bs in GB/s and the code’s operational intensity I in Flop/Byte [3]. P verifies: $$ P \leq \min{(P_{m},I\times B_{s})}.$$
To generate the roofline model of the workstations, we use the Empirical Roofline Toolkit ERT-1.1.0 [6]. It generates the bandwidth of memories and estimates the peak performance of the machine empirically. Without accurate estimation of FLOPs and data traffic, the roofline analysis fails. To collect this data, we use Intel-SDE [7] and Intel-Vtune [8]. The code’s performance verifies $$ P = \frac{SDE\hspace{1mm}Flops}{Runtime}$$ and the arithmetic intensity I on architecture i: $$ I_{i} = \frac{SDE\hspace{1mm}Flops\hspace{1mm}on\hspace{1mm}i}{Vtune\hspace{1mm}Memory\hspace{1mm}accesses\hspace{1mm}on\hspace{1mm}i}.$$
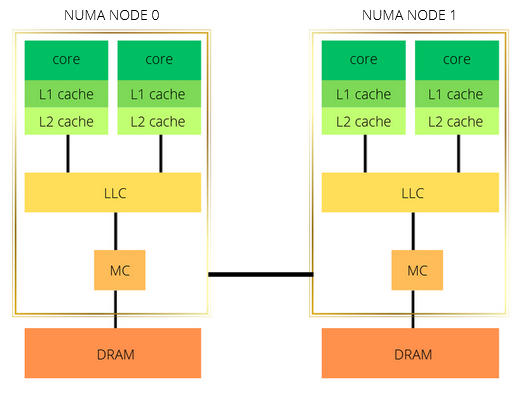
For the optimization techniques, we pinpoint the importance of the compilation flags; they help to exploit the hardware capabilities to create an optimal binary [9]. Moreover, thread binding is employed to prevent the OS from moving threads around from their initial positions during the execution [10]; Close and Spread options are investigated. Both CPUs are NUMA-systems, another optimization is to make the application NUMA-aware by preventing remote DRAM access. For GRICS’s hybrid implementation, we determine the suitable combination of MPI processes and OpenMP threads, to distribute optimally the workflow among resources.
Results and Discussion
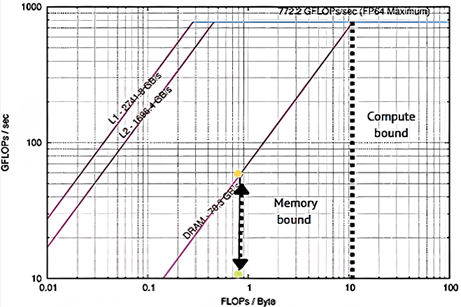
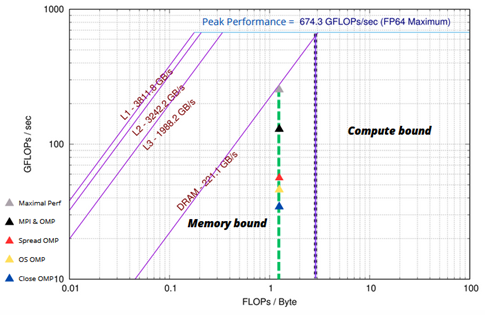
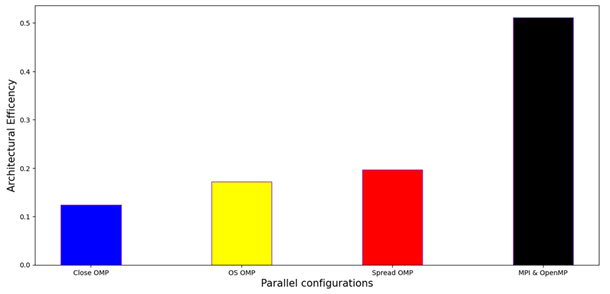
Figures 3&4: GRICS is memory bound in both architectures. Considering only OpenMP, PXeon=8GFLOP/s, while PAMD=47GFLOP/s. GRICS is based on iterative resolutions; on repetitive calls to the FFT algorithm. The code requires a huge number of DRAM/caches requests. Consequently, GRICS performs better in the architecture that offers a higher memory bandwidth, in our case AMD-EPYC: Bs,AMD=221GB/s, Bs,Xeon=70GB/s. We decided to optimize the code on this platform.Figure 4: With OpenMP, Close option (blue) degrades performance (34GFLOP/s) compared to OS (Yellow) binding (47GFLOP/s). Spread option (red) improves performance (54GFLOP/s); it ameliorates FP units and memory bandwidth.
For optimal resources sharing in hybrid case, the number of MPI processes m and OpenMP threads n should divide respectively Nt=12 and Nc=20. Empirically, we obtain the best performance (140GFLOP/s) when m=Nt and n=Nc /2 (black).
Figure5: Architectural efficiency of an application a solving a problem p is given by
$$e_{i}(a,p) = \frac{P_{i}(a,p)}{\min(P_{m},I_{i}(a,p).B_{s})}.$$
| Device | Pm(GFLOP/s) | Bs(GB/s) | Reconstruction-time(s) |
| AMD-EPYC | 674 | 221 | 56 |
| Nvidia-Quadro-RTX-5000-GPU | 5600 | 400 | 145 |
| Nvidia-A100-GPU | 9700 | 1555 | 33 |
The GPU-MATLAB implementation is suggested to question the statement “GPU is always better”. Only the last image reconstruction problem was evaluated (at the last iteration of the multi-resolution algorithm).With our optimizations, EPYC is 2.5 times faster than RTX-5000, and 1.7 times slower than A100 (the C++/Matlab-implementations give approximately the same image; NRMSE=10-5). GPUs may require implementation-level modifications to make profits from all its capabilities.
Conclusion
We evaluated the performance of motion-compensated reconstruction algorithms using the GRICS code as an example. Optimal processor architecture is algorithm-dependent. Using the roofline model, we have shown that memory bandwidth is the limitation for this class of algorithms. Threads binding allows a gain of 22%. The optimal MPI-OpenMP combination yields to a gain of 67% and an architectural efficiency of 51%.Acknowledgements
The authors would like to thank Mr. Vadim Karpusenko, from IonQ company, for his valuable advices and suggestions. Funding: MOSAR project, (ANR-21-CE19-0028), CPER IT2MP, FEDER (European Regional Development Fund).References
[1] S. Schaetz, D. Voit, J. Frahm, et M. Uecker, « Accelerated Computing in Magnetic Resonance Imaging: Real-Time Imaging Using Nonlinear Inverse Reconstruction », Comput. Math. Methods Med., vol. 2017, p. 3527269, 2017, doi: 10.1155/2017/3527269.
[2] V. C. Cabezas et M. Puschel, « Extending the roofline model: Bottleneck analysis with microarchitectural constraints », in 2014 IEEE International Symposium on Workload Characterization (IISWC), Raleigh, NC, USA: IEEE, oct. 2014, p. 222‑231. doi: 10.1109/IISWC.2014.6983061.
[3] S. Williams, A. Waterman, et D. Patterson, « Roofline: an insightful visual performance model for multicore architectures », Commun. ACM, vol. 52, no 4, p. 65‑76, avr. 2009, doi: 10.1145/1498765.1498785.
[4] F. Odille, P.-A. Vuissoz, P.-Y. Marie, et J. Felblinger, « Generalized Reconstruction by Inversion of Coupled Systems (GRICS) applied to free-breathing MRI », Magn. Reson. Med., vol. 60, no 1, p. 146‑157, 2008, doi: 10.1002/mrm.21623.
[5] K. Isaieva et al., « Feasibility of online non-rigid motion correction for high-resolution supine breast MRI », Magn. Reson. Med., vol. 90, no 5, p. 2130‑2143, nov. 2023, doi: 10.1002/mrm.29768.
[6] « berkeleylab / cs-roofline-toolkit — Bitbucket ». https://bitbucket.org/berkeleylab/cs-roofline-toolkit/src/master/
[7] « Intel® Software Development Emulator ». https://www.intel.com/content/www/us/en/developer/articles/tool/software-development-emulator.html
[8] « Fix Performance Bottlenecks with Intel® VTuneTM Profiler ». https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html
[9] K. Halbiniak, R. Wyrzykowski, L. Szustak, A. Kulawik, N. Meyer, et P. Gepner, « Performance exploration of various C/C++ compilers for AMD EPYC processors in numerical modeling of solidification », Adv. Eng. Softw., vol. 166, p. 103078, avr. 2022, doi: 10.1016/j.advengsoft.2021.103078.
[10] N. Denoyelle, B. Goglin, E. Jeannot, et T. Ropars, « Data and Thread Placement in NUMA Architectures: A Statistical Learning Approach », in Proceedings of the 48th International Conference on Parallel Processing, in ICPP ’19. New York, NY, USA: Association for Computing Machinery, août 2019, p. 1‑10. doi: 10.1145/3337821.3337893.
Figures