4516
ResoNet: MRI Super-Resolution via Multi-Path GAN with Adaptive Convolutional Kernels1The Hong Kong Polytechnic University, HongKong, China, 2Affiliated Hospital of Yangzhou University, Yangzhou, China, 3GE Healthcare, MR Research China, Beijing, China, 4Shenzhen Wrmherd biotech Ltd. co., Shenzhen, China
Synopsis
Keywords: Diagnosis/Prediction, Vessels, Image super-resolution , Generative Adversarial Network (GAN) , Multi- path generator model , Medical imaging
Motivation: The project aims to improve MRI image resolution, addressing the limitations of current super-resolution methods that hinder accurate medical diagnosis and treatment planning.
Goal(s): Enhancing MRI image clarity through ResoNet, an innovative approach featuring a multi-path generator, self-adaptive kernel sizing, and a comprehensive loss function.
Approach: Multi-path generator enhances resolution with different kernel sizes, preserving details. Self-adaptive component optimizes kernel size for efficiency. Comprehensive loss function combines GAN-based discriminator, VGG16, and WGAN-GP for sTab. training and quality samples.
Results: ResoNet significantly enhances SSIM and PSNR scores, promising substantial impact in medical imaging for more precise diagnoses and treatment planning by healthcare professionals.
Impact: This work improves MRI diagnostics by enhancing image resolution, enabling clearer visuals for accurate medical assessments. It optimizes performance and resources, accelerates scanning time, and potentially transforms emergency medical practices, making it an improvement in medical imaging.
INTRODUCTION
Image super-resolution is crucial in healthcare for precise diagnosis and treatment planning [1]. MRI, despite detailed anatomical information, suffers from lower resolution due to hardware constraints, affecting medical interpretation. Methods like interpolation, statistical models, and CNNs (e.g., SRCNN [2], VDSR [3], SRGAN [4]) have enhanced super-resolution, generating higher fidelity images.Our GAN-based MRI super-resolution method aims to improve image clarity for better medical assessments and treatment strategies.Our approach introduces three key innovations:
1. Multi-Path Generator Model: Simultaneously captures small details and a wide visual field using different kernel sizes for effective resolution enhancement while retaining vital image features.
2. Self-Adaptive Kernel Sizing: Determines large convolutional kernel size based on input images, optimizing performance and resources.
3. Comprehensive Loss Function: Merges GAN-based discriminator, VGG16 network, and WGAN-GP structure for sTab. training and high-quality samples.
METHODS
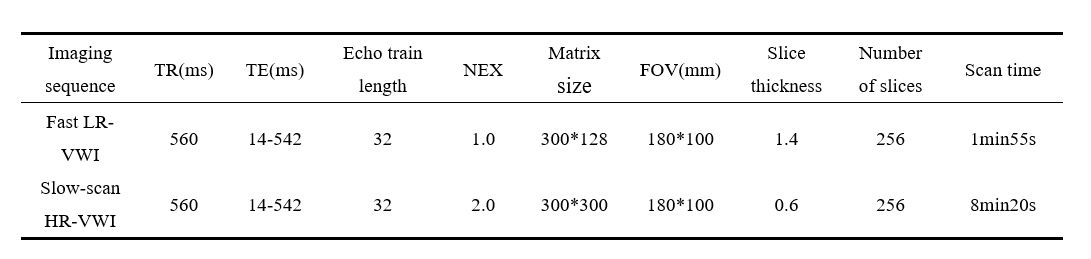
DatasetsIn partnership with Yangzhou University School of Medicine, we compiled a unique brain MRI dataset. The "One-to-one fast-scan and slow-scan dataset" presents the greatest challenge, involving both scans on each patient, establishing a direct correspondence. 30 patients contributed 200 sets of corresponding images each, offering valuable insights into brain function and detailed structural information. Magnetic resonance imaging (MRI) was performed for all participants on GE 750W 3.0 Tesla MRI scanner. The scan parameters were shown in Tab.1.
Structure of the proposed model
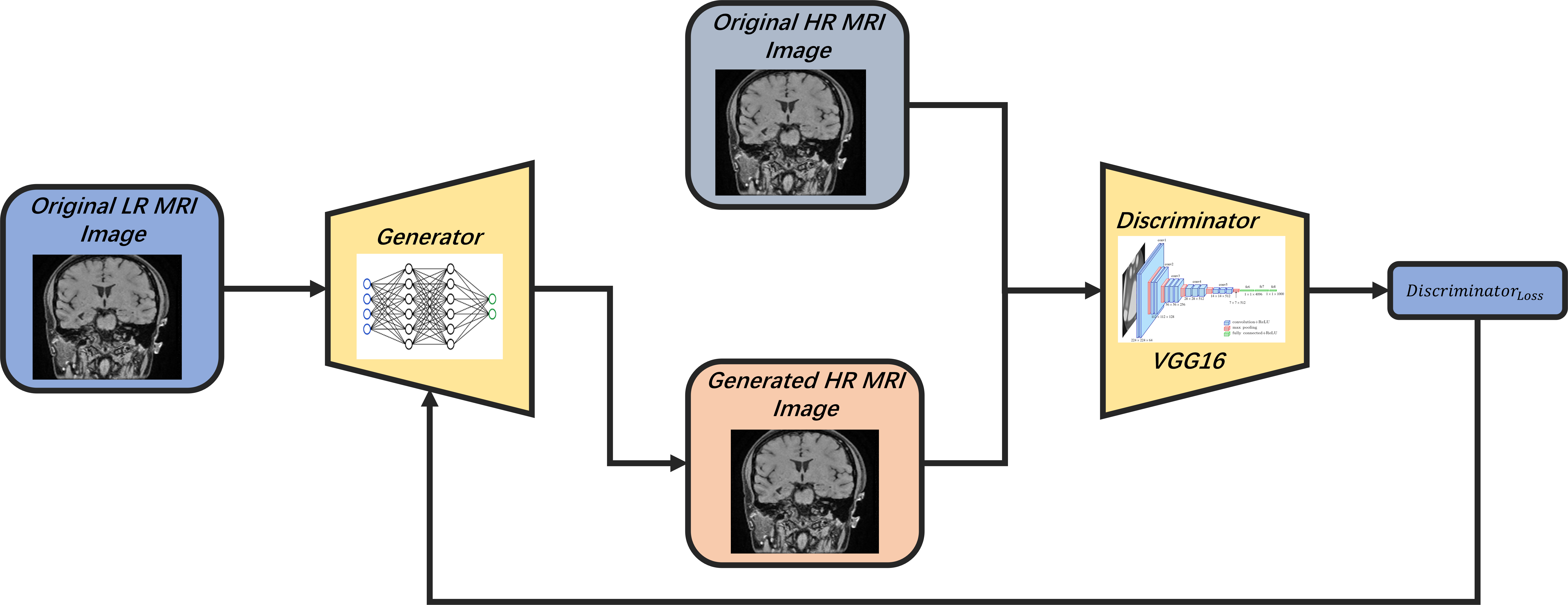
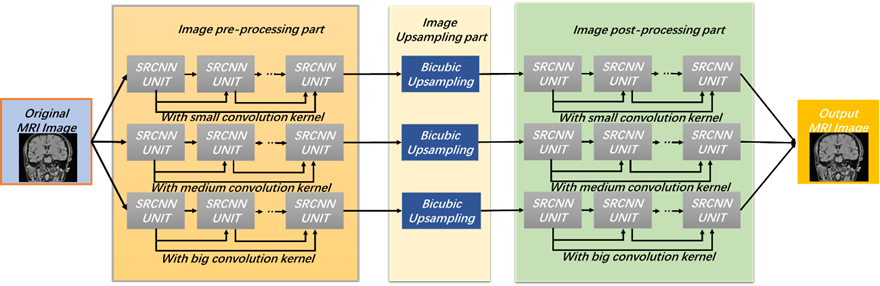
Our MRI image super-resolution method utilizes a GAN structure (Fig.1). The generator model (Fig.2) consists of four modules: Image Pre-processing, Image Upsampling, Image Post-processing, and Final Processing. Enhancing performance and versatility, we adopt a multi-path structure employing convolutional kernels of various sizes (small, medium, and large). Large convolutional kernels balance performance and resource efficiency, further bolstered by a self-adaptive component within the model.
Based on Ref. [5], larger convolutional kernels balance computation and match Transformer model performance. Self-adaptive elements notably enhance model abilities. Experiments confirm appropriately sized convolutional kernels improve results in our method. For optimal performance, our findings suggest the large kernel size should not exceed 1/4 of the input vector (Equation 1).
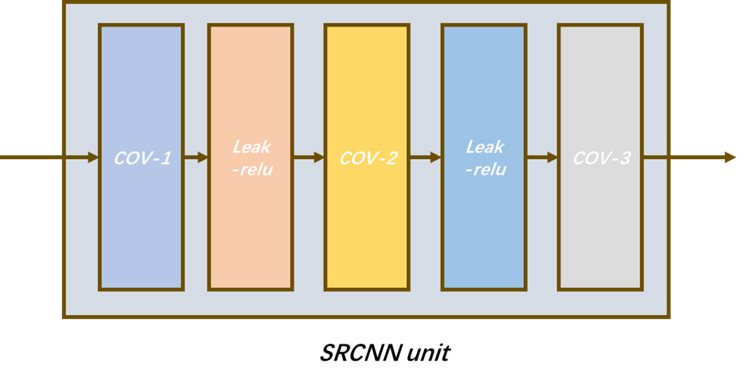
$$S_{k-\max} \leq \frac{S_p}{4}+1 \tag{1}$$ Here, $$$S_{k-\max} $$$represents the maximum size of the convolutional kernel, while denotes the smaller value between the length and width of the input image vectors. This equation guides us in selecting the optimal kernel size for superior performance. SRCNN (Super-Resolution Convolutional Neural Network) units, Fig. 3, form the basis of our model. These units have three convolutional layers and two activation function layers, effectively transforming LR features into HR features. Both the image pre-processing and post-processing modules encompass an equal number of SRCNN units, calculated using Equation (2).
$$ N_{\max } \leq \frac{S_p}{20}+1 \tag{2}$$ Here, $$$N_{\max } $$$represents the maximum number of SRCNN units in each part of the path, and $$${S_p}$$$indicates the smaller value between the length and width of the input image vectors. In our model development, we've optimized for computational efficiency and effectiveness by selecting a fraction—1/20 of the image size—as the appropriate number of SRCNN units. This approach enables efficient image processing while retaining crucial details. Bicubic interpolation is utilized for up-sampling, ensuring smooth and visually pleasing results. Outputs from multiple paths combine to create a comprehensive super-resolved output, capturing diverse image features. The GAN improves image realism, balancing global shape and local texture for visually appealing outcomes.
Loss Function
Our model uses GAN with a VGG16-based discriminator and WGAN-GP for stability. The discriminator loss guides training, distinguishing between real and generated images. The generator loss consists of GAN loss, style loss, structure loss, and content loss, ensuring the generation of high-quality images resembling the target. The comprehensive loss function guides the generator to produce images retaining the desired style, structure, and content, showcasing the efficacy of our proposed method.
RESULTS
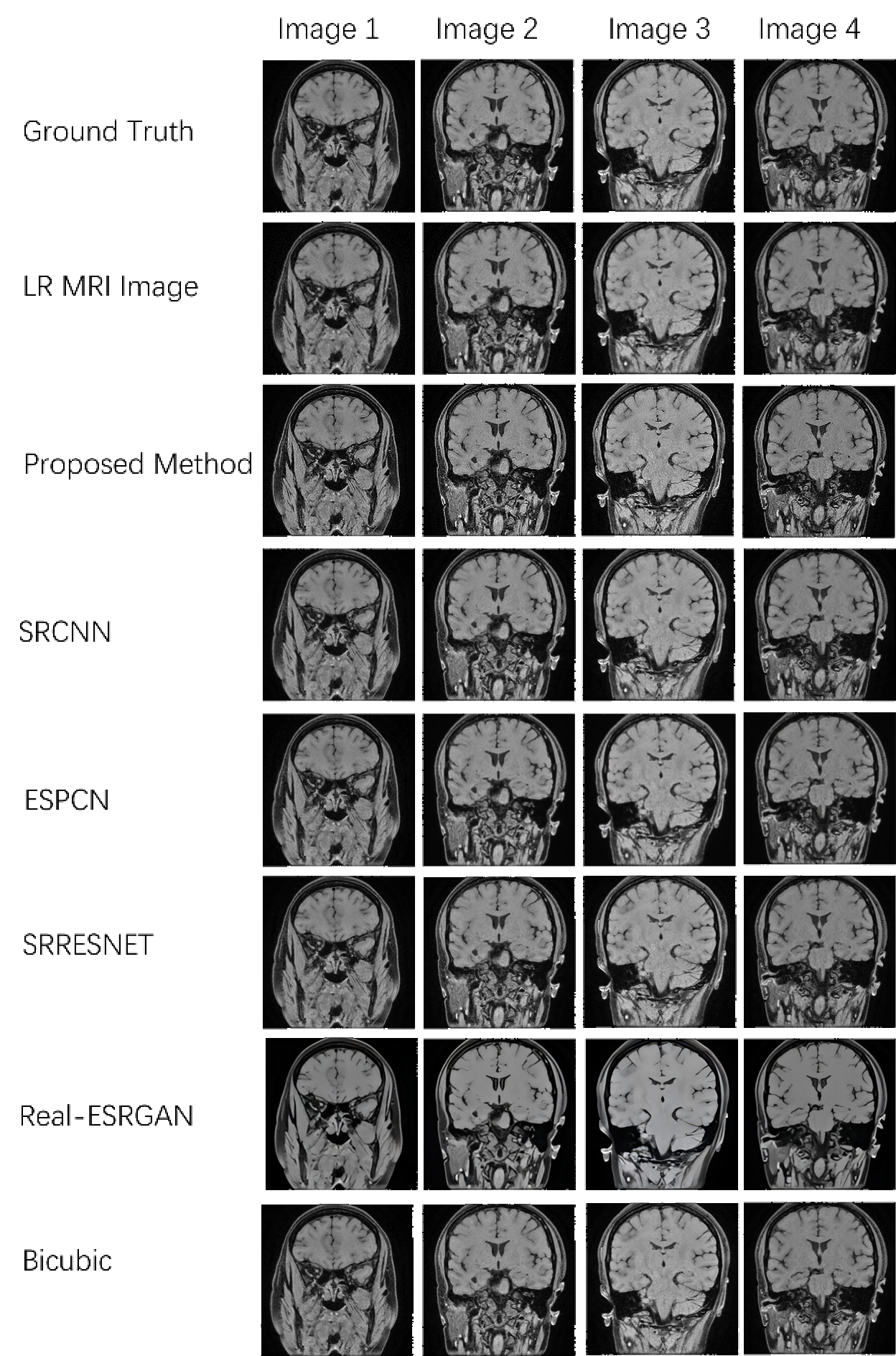
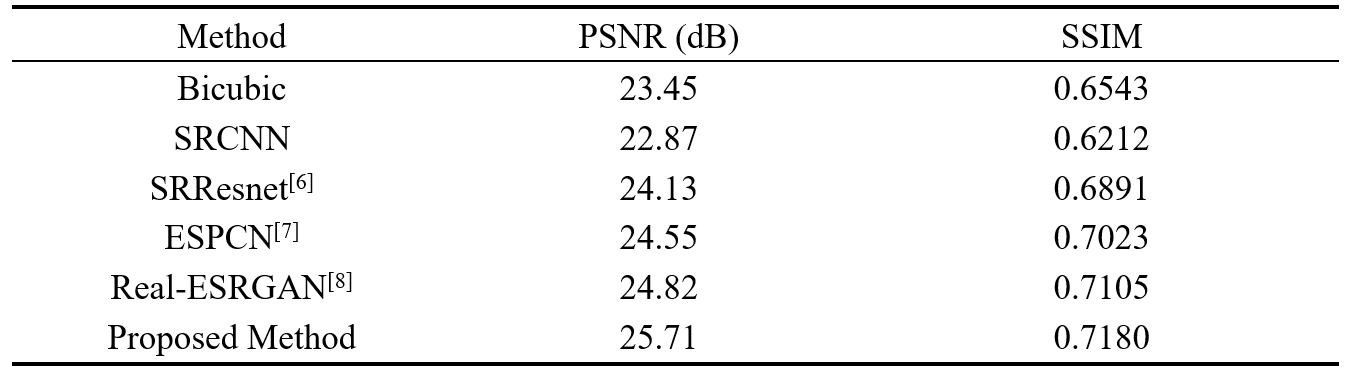
In the experiment(Tab.2), our method outperforms existing approaches in PSNR and SSIM, improving image quality and similarity to slow-scan images. It surpasses Bicubic and SRCNN, competes well with SRResnet and ESPCN, closely rivals Real-ESRGAN but with higher PSNR and SSIM. Visual comparisons in Fig.4 show our model excelling in preserving crucial structural details, reducing noise in fast-scan images, and approximating slow-scan image quality. This clarity aids medical observations, reducing the need for further processing. The use of large convolutional kernels signifies promising advancements in MRI image super-resolution for accurate medical diagnoses.CONCLUSIONS
Our method enhances super-resolution, accelerates model performance, potentially reducing scanning time. It holds promise for quicker, accurate diagnoses, potentially improving emergency medical practices.Acknowledgements
No acknowledgement found.References
[1] C.-H. Pham, A. Ducournau, R. Fablet, and F. Rousseau, "Brain MRI super-resolution using deep 3D convolutional networks," in Biomedical Imaging (ISBI 2017), 2017 IEEE 14th International Symposium on. IEEE, 2017, pp. 197-200.
[2] J. Shi, Q. Liu, C. Wang, Q. Zhang, S. Ying, and H. Xu, "Super-resolution reconstruction of MR image with a novel residual learning network algorithm," Phys Med Biol, vol. 63, 2018, article 085011.
[3] J. Kim, J. Lee, and K. M. Lee, "Accurate Image Super-Resolution Using Very Deep Convolutional Networks," in Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1646-1654, 2016.
[4] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, et al., "Photo-realistic single image super-resolution using a generative adversarial network," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4681-4690.
[5] X. Ding, X. Zhang, J. Han, and G. Ding, "Scaling up your kernels to 31x31: Revisiting large kernel design in CNNs," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11963-11975.
[6] Y. Huang, N. Zhang, and Q. Hao, "Real-time noise reduction based on ground truth free deep learning for optical coherence tomography," Biomedical Optics Express, vol. 12, no. 4, pp. 2027-2040, 2021.
[7] W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, et al., "Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1874-1883.
[8] X. Wang, L. Xie, C. Dong, and Y. Shan, "Real-esrgan: Training real-world blind super-resolution with pure synthetic data," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1905-1914.
Figures