4504
Feature-Image Variational Network for Accelerated MRI Reconstructions1Bernard and Irene Schwartz Center for Biomedical Imaging, Department of Radiology, NYU Grossman School of Medicine, New York, NY, United States, 2Center for Advanced Imaging Innovation and Research (CAI2R), Department of Radiology, NYU Grossman School of Medicine, New York, NY, United States, 3Vilcek Institute of Graduate Biomedical Sciences, NYU Grossman School of Medicine, New York, NY, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence, Compressed Sensing, Parallel Imaging
Motivation: To improve learning-based MRI reconstructions to achieve higher clinical accuracy and detail retention.
Goal(s): To introduce modifications in the end-to-end (E2E) variational network (VarNet) to enhance its performance for undersampled MRI reconstructions.
Approach: We performed training in feature-space instead of image-space and included an attention layer that leverages the spatial locations of the Cartesian undersampling artifacts. We combined the new network with the E2E VarNet into Feature-Image VarNet to facilitate cross-domain learning.
Results: Reconstructions were evaluated using standard metrics and clinical scoring. Feature-Image VarNet outperformed all open-source models in the fastMRI leaderboard and preserved small anatomical details that were blurred with E2E VarNet.
Impact: We propose the Feature-Image (FI) variational network (VarNet), which performs cross-domain learning between feature and image spaces. FI VarNet significantly enhances the reconstruction quality of undersampled MRI and could enable clinically acceptable reconstructions at higher acceleration factors than currently possible.
INTRODUCTION
Compressed sensing (CS) has revolutionized MRI by enhancing its cost-efficiency and broadening its applications. Recently, deep learning (DL) models1,2 have been integrated to CS where the regularization parameters are now learned directly from the data instead of being set empirically. In particular, the end-to-end variational network3 (E2E VarNet) employs a UNET at every gradient descent iteration (cascade), outperforming conventional CS techniques. Since DL methodologies are embedded in most commercial scanners, it is important to continue to advance learning-based MRI reconstruction to ensure even greater clinical precision and detail retention. In previous research, we introduced the Feature VarNet4, which preserves high-level features typically lost in the final convolutional layers of the E2E VarNet cascades. Here, we build upon both the E2E VarNet and the Feature VarNet and propose the incorporation of transformers and cross-domain learning to mitigate the limitations of these networks and further boosts image reconstruction performance.METHODS
We added a self-attention layer5 in front of each UNET of the Feature VarNet. In particular, we leveraged the information that Cartesian undersampling artifacts are shifted replicas of the original image along the phase-encoding direction, with the extent of displacement dictated by the degree of undersampling. We passed this information as a block-based representation of the feature tensors to the attention layer to detect the location of aliasing artifacts and mitigate them. We combined the modified Feature VarNet with the E2E VarNet into a single Feature-Image (FI) VarNet to facilitate cross-domain learning and improve performance.We used the fastMRI dataset6 to train our models on either brain or knee volumes. We trained on 5847 brain volumes and tested on 558, while for the knee, we used 973 and 199 volumes for training and testing, respectively. We sampled either 8% or 7% of the central k-space and uniformly undersampled the remaining k-space, aiming for either 4x or 5x acceleration factor, respectively. We used the AdamW optimizer for 210k iterations, cosine annealing after 140k iterations, and trained over the structural similarity index (SSIM). E2E and Feature VarNet had 12 cascades (since more cascades did not improve performance). FI VarNet had either 6+6 or 12+12 feature and image cascades.
RESULTS
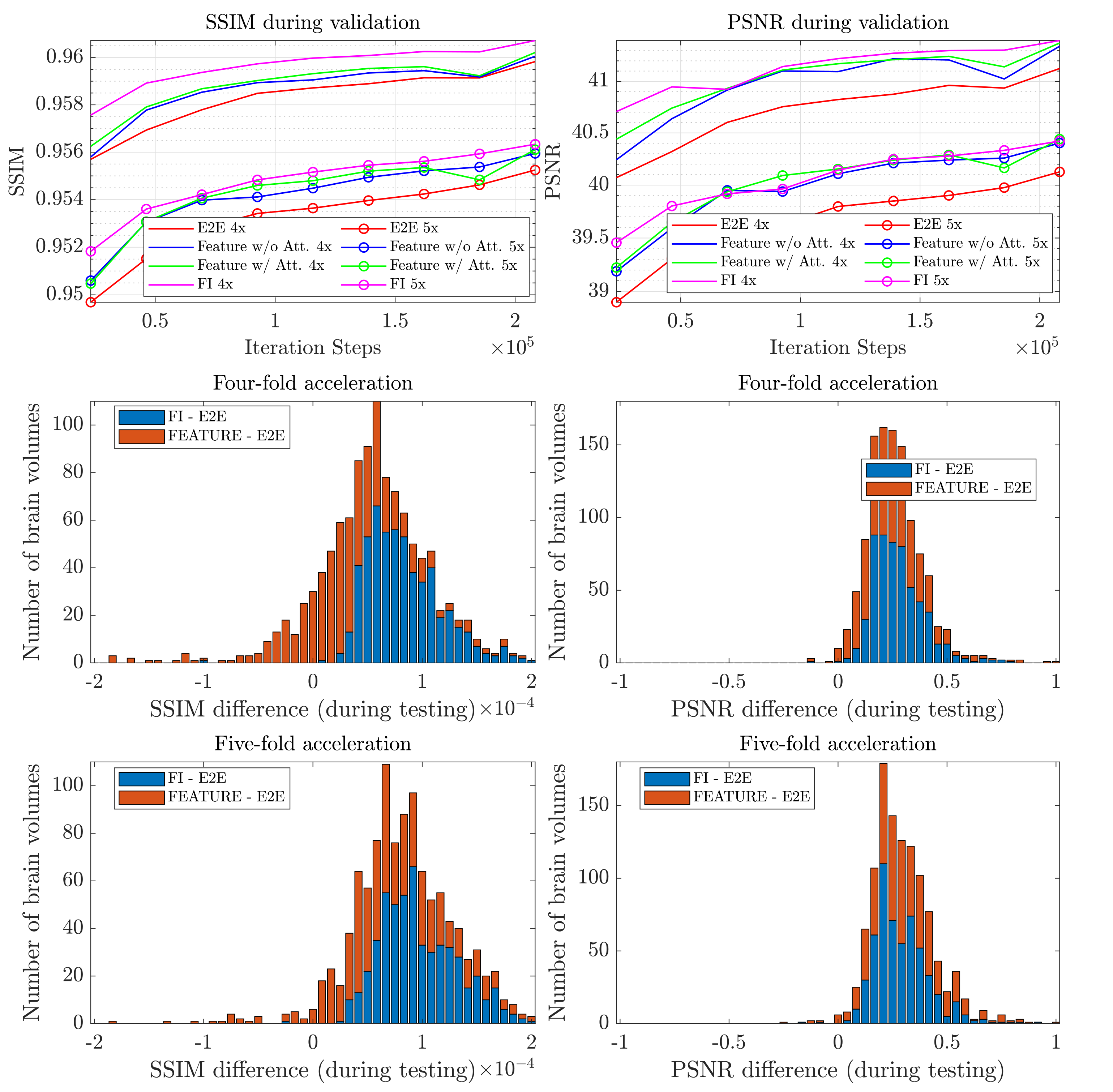
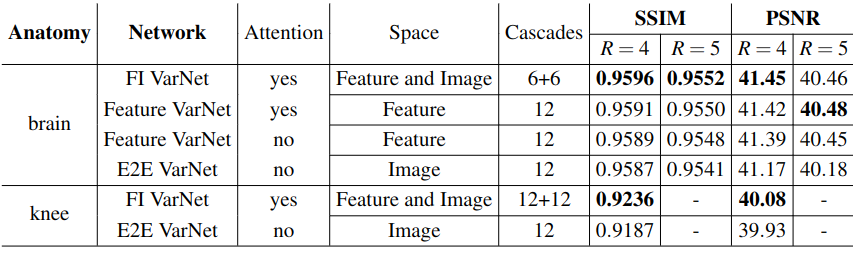
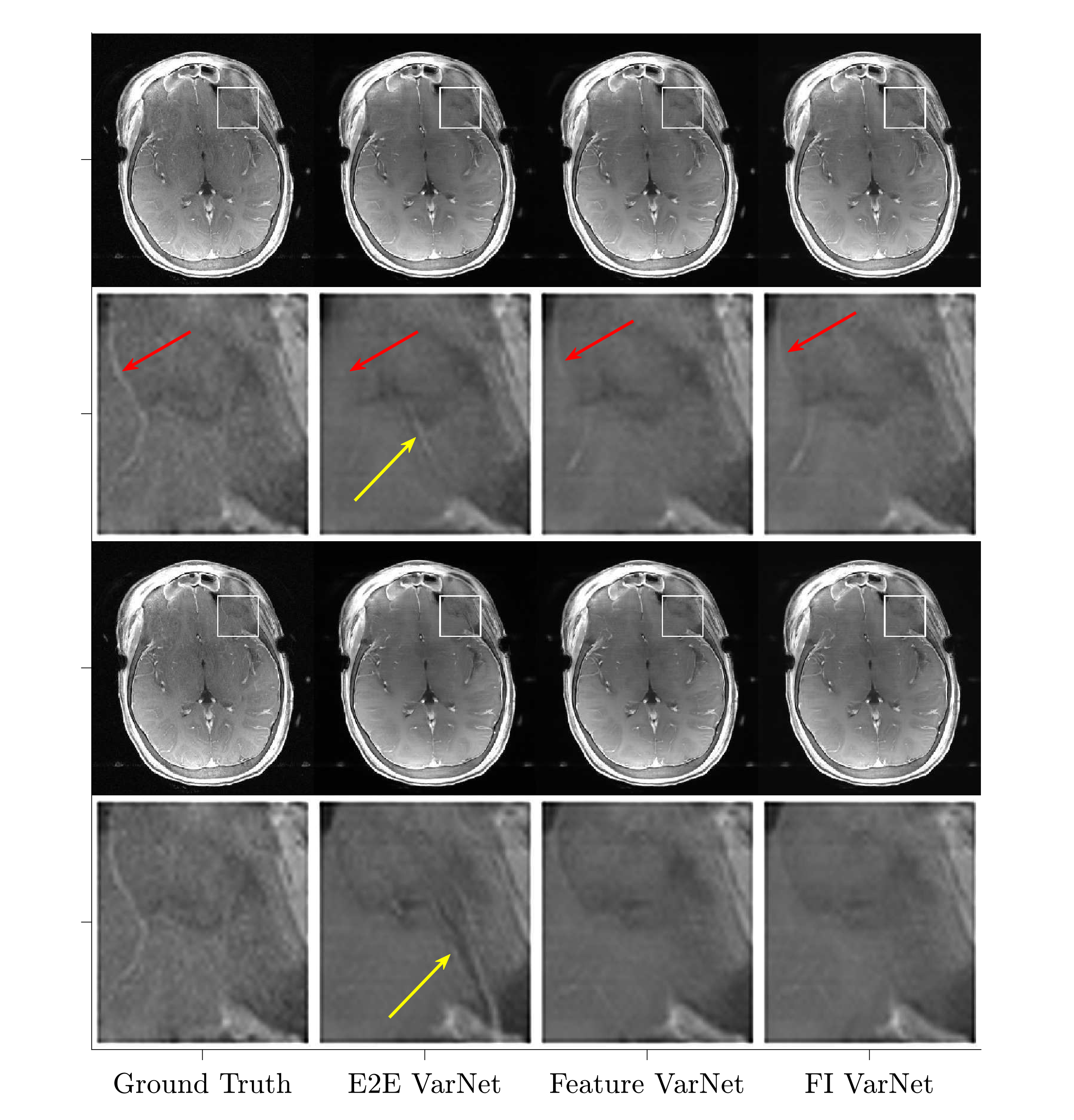
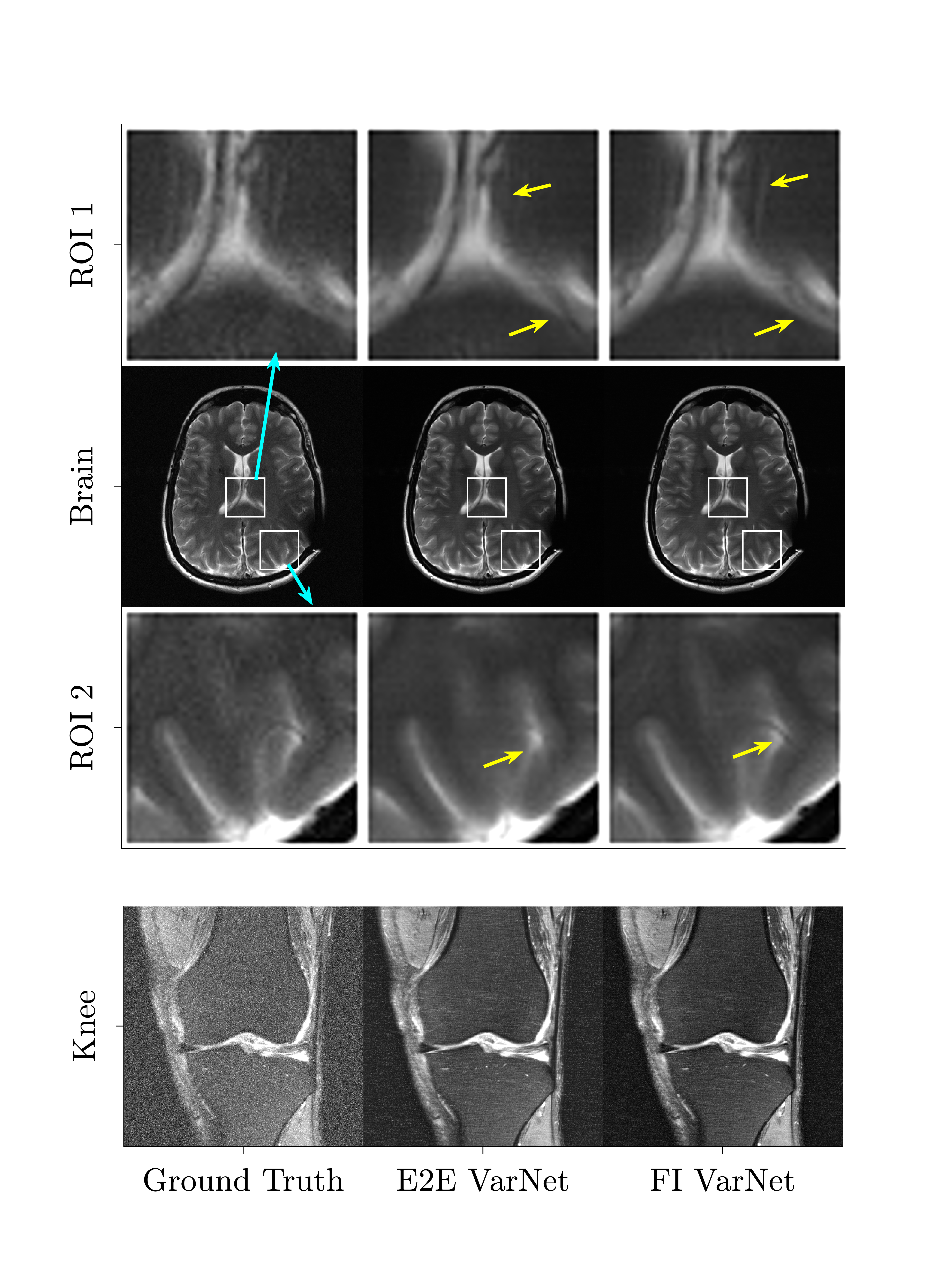
Figure 1 (top), presents the validation error convergence for SSIM and peak signal-to-noise ratio (PSNR) for 4x and 5x acceleration for all networks during training on brains. It also compares the SSIM and PSNR score differences of the FI and Feature (w/ attention) VarNet with respect to E2E VarNet for the brain test dataset for 4x (middle) and 5x (bottom) undersampling. Figure 2 compares average SSIM and PSNR for brain and knee reconstructions and the E2E, Feature (w/ and w/o attention), and FI VarNets.Figure 3 shows a reconstruction in which the E2E VarNet had an artifact and blurred a blood vessel. Feature (w/ attention) and FI VarNet (6+6 cascades) did not exhibit this artifact for both accelerations and retained the vessel at 4x acceleration only. Figure 4 (top) compares another brain image at 4x acceleration, reconstructed using the FI (12+12 cascades) and the E2E VarNets. E2E VarNet exhibits a blurred representation of the thalamus, an artifact in the choroid plexus, and also fails to capture a blood vessel, while FI VarNet successfully preserves them. In Figure 4 (bottom), FI VarNet leads to lower noise in the reconstruction than the E2E VarNet.
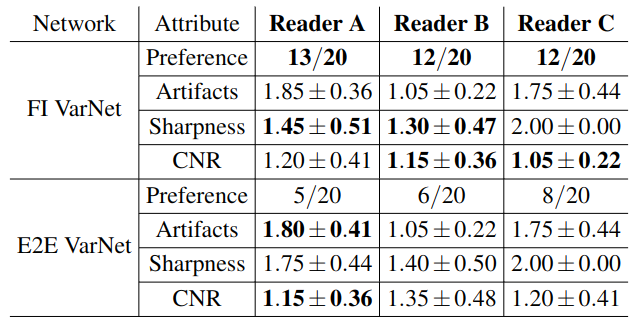
Figure 5 presents clinical scoring regarding overall preference of the image, reconstruction artifacts, image sharpness and contrast-to-noise ratio, by three expert neuroradiologists for 20 cases with abnormalities.
DISCUSSION
We modified the E2E VarNet for MRI reconstructions. The novel VarNet outperformed the E2E architecture in SSIM and PSNR for 4x and 5x undersampling for almost the entire testing dataset. Feature-space facilitates the incorporation of attention in the Feature VarNet, which mitigates artifacts in the reconstruction through training. Cross-domain learning in FI VarNet utilizes the advantages of both feature and image-space networks, thus, improving the reconstruction performance. This is demonstrated by FI VarNet's robustness to acceleration artifacts and detail retention, in contrast to the E2E VarNet. FI VarNet also outperformed the E2E VarNet on clinical scoring. On average, the readers preferred the FI VarNet in 62% of the 20 cases and noted higher sharpness in the reconstruction. Notably, FI VarNet secured second place in the public fastMRI leaderboard with SSIM=0.9607 (third place model: 0.9601)7.CONCLUSION
The incorporation of feature space training, block-wise attention layers and, cross-domain learning demonstrate improved reconstruction performance in comparison to the baseline model. Ultimately these modifications could enable clinically acceptable reconstructions at higher acceleration factors than currently possible.Acknowledgements
This work was supported in part by NIH R01 EB024536 and NIH R01 AR070297 and was performed under the rubric of the Center for Advanced Imaging Innovation and Research (CAI2R, www.cai2r.net), an NIBIB National Center for Biomedical Imaging and Bioengineering (NIH P41 EB017183).References
- Hammernik, K. et al. Learning a variational network for reconstruction of accelerated MRI data. Magn. resonancemedicine 79, 3055–3071 (2018).
- Sriram, A. et al. End-to-end variational networks for accelerated MRI reconstruction. In Medical Image Computingand Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020,Proceedings, Part II 23, 64–73 (Springer, 2020).
- Arvinte, M., Vishwanath, S., Tewfik, A. H. & Tamir, J. I. Deep J-Sense: Accelerated MRI reconstruction via unrolled alter-nating optimization. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th InternationalConference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part VI 24, 350–360 (Springer, 2021).
- Giannakopoulos, I. I., Johnson, P., Lattanzi, R. & Muckley, M. J. Improving variational network based 2D MRI reconstruction via feature-space data consistency. In Proc. ISMRM, 3321 (2023).
- Vaswani, A. et al. Attention is all you need. Adv. neural information processing systems 30 (2017).
- Zbontar, J. et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:1811.08839 (2018).
- Muckley, M. J. et al. State-of-the-art machine learning MRI reconstruction in 2020: Results of the second fastMRIchallenge. arXiv preprint arXiv:2012.06318 2, 7 (2020).
Figures