4501
NLCG-Net: A Model-Based Zero-Shot Learning Framework for Undersampled Quantitative MRI Reconstruction1School of Information Science and Technology, Fudan University, Shanghai, China, 2Department of Radiology, Harvard Medical School, Boston, MA, United States, 3Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Charlestown, MA, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: Typical quantitative MRI (qMRI) methods estimate parameter maps after image reconstructing, which is prone to biases and error propagation.
Goal(s): To propose an end-to-end method to directly estimate qMRI maps from undersampled k-space data using model-based reconstruction and zero-shot network regularization.
Approach: We propose a Nonlinear Conjugate Gradient (NLCG) optimizer for model-based T2/T1 estimation, which incorporates U-Net regularization trained in a scan-specific manner.
Results: T2 and T1 mapping results demonstrate the ability of the proposed NLCG-Net to improve estimation quality compared to subspace reconstruction at high accelerations.
Impact: We propose a model-based qMRI technique, NLCG-Net, that incorporates mono-exponential signal modeling with zero-shot scan-specific neural network regularization to enable high fidelity T1 and T2 mapping.
Introduction
Standard quantitative MRI (qMRI) techniques rely on a two-step process whereby undersampled k-space data are reconstructed first, and then used in model fitting to estimate parameters of interest. Model based approaches [1,2] have been developed to incorporate mono-exponential signal models into the reconstruction, so that parameter maps can be directly estimated from undersampled data.In this work, we propose a Non-linear Conjugate Gradient (NLCG) optimization to solve the arising optimization problem and use a scan-specific Neural Network as regularizer. Experiments show the ability of the proposed NLCG-Net to improve T1 and T2 mapping relative to subspace modeling at high accelerations, while obviating the need for an external training dataset.
Methods
·Problem FormulationWe formulate qMRI reconstruction as an optimization problem by solving the following objective function:
$$\mathop{\arg\min}\limits_{\boldsymbol{x}} \left\| \mathbf{PFCM}(\boldsymbol{x}) - \boldsymbol{y} \right\|^2 + \lambda \left\| \boldsymbol{x} - \boldsymbol{z}\right\|^2\text{(1)}$$
where
$$\boldsymbol{x} = \begin{bmatrix} \boldsymbol{M_x} \\ \boldsymbol{M_y} \\ \boldsymbol{R} \end{bmatrix}= \begin{bmatrix} \boldsymbol{M_x} \\ \boldsymbol{M_y} \\ \boldsymbol{\frac{1}{T}} \end{bmatrix}$$
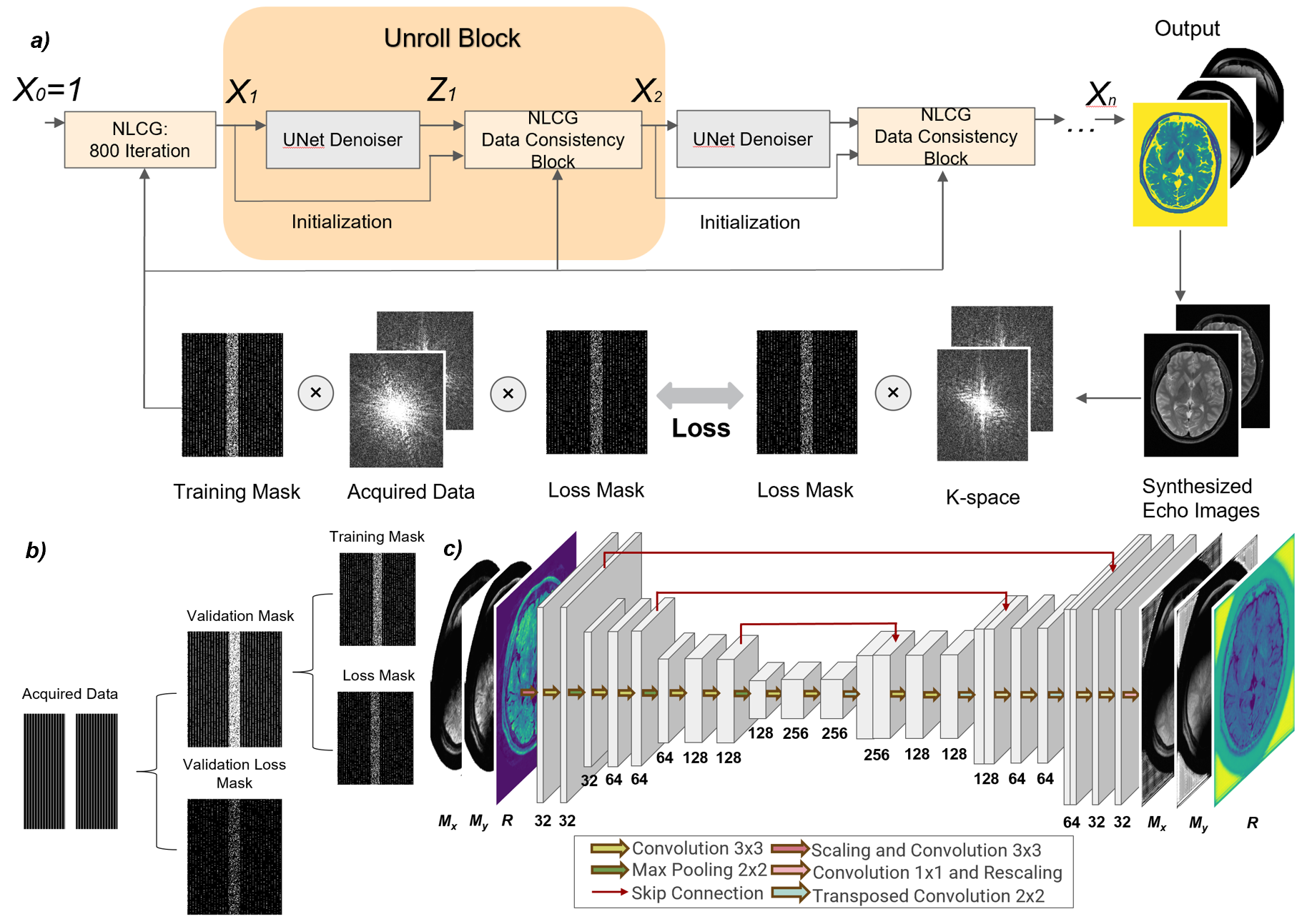
Here Mx, My real and imaging components of transverse magnetization, R refers to R1 or R2 representing parameter values. y denotes acquired kspace data, z refers to regularized x and λ is regularization coefficient. PFCM are forward operators illustrated in Fig.1. M denotes the mono-exponential signal model, which has different expressions for T1 and T2 mapping; C denotes coil sensitivity maps, F denotes Fast Fourier transform, and P denotes k-space sampling mask.
To solve this, we can unroll the target function and solve it separately and iteratively. Specifically[3],
$$\boldsymbol{z_n} = \boldsymbol{R}(\boldsymbol{x_n}) (2)$$
$$\boldsymbol{x_{n+1}} = \mathop{\arg\min}\limits_{\boldsymbol{x}} \left\| \text{PFCM}(\boldsymbol{x}) - \boldsymbol{y} \right\|^2+ \lambda \left\| \boldsymbol{x} - \boldsymbol{z_n}\right\|^2 (3)$$
Where R( ) refers to regularization operation by Neural Network.
·Proposed Model
We propose NLCG-Net to solve the iterative optimization problem. The detailed architecture of NLCG-Net is presented in Fig.2. NLCG-Net directly takes k-space data as input, and unrolls the optimization into several unroll blocks. Each block has one regularization layer and one data consistency (DC), which correspond to (2) and (3). For the regularizer, we deploy a light U-Net model with only three downsample and upsample layers to restrict the parameter number and facilitate the training. In the data consistency layer, we deploy NLCG to solve (3).
·Implementation Details
NLCG-Net contains 3 Unroll blocks. A DC layer performs 20 iterations with NLCG and takes x from the last layer as iteration initialization. In the beginning, input x is acquired by performing NLCG without regularization to k-space input for 800 iterations, which can be done within 1 minute. To achieve zero-shot training, we use different sampling masks to divide data into training and validation sets, and the splitting strategy is the same as [4]. Before feeding into the network, Mx, My, and R are scaled[5] by 3 trainable parameters due to their different dynamic ranges[6]. Overall training process was performed on an NVIDIA 4090 GPU, and 300 epochs were finished within 5 hours.
·Experiments
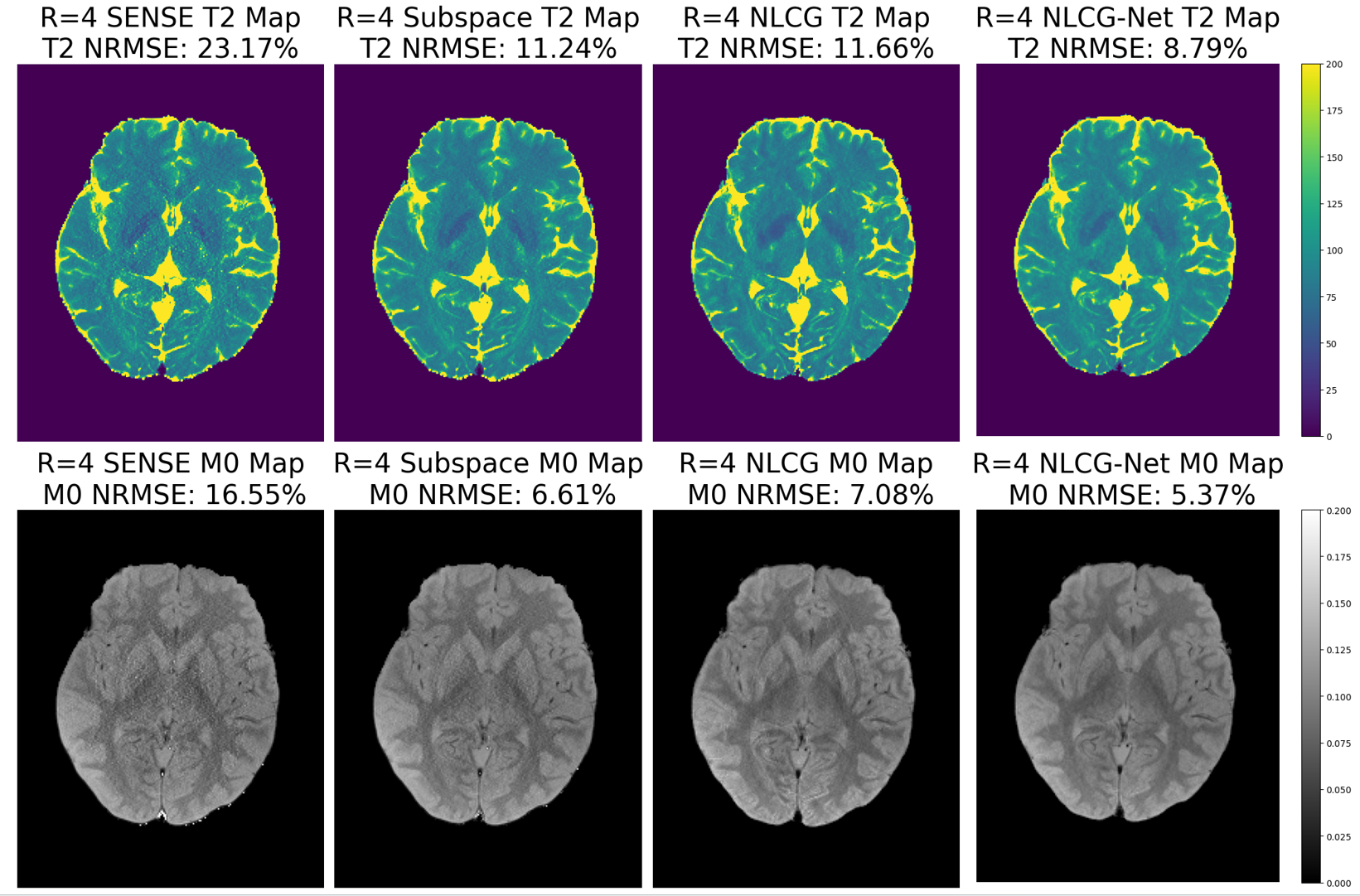
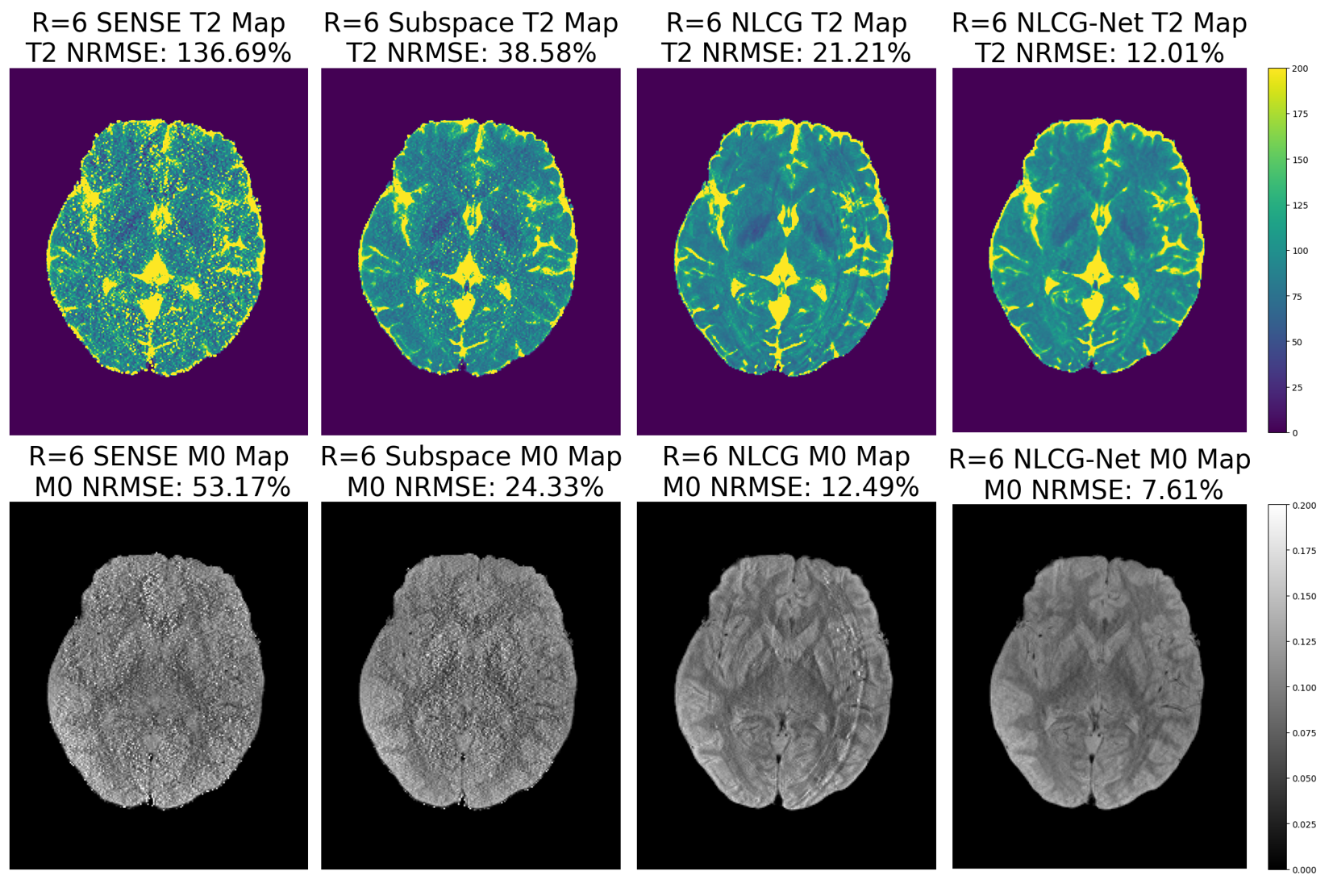
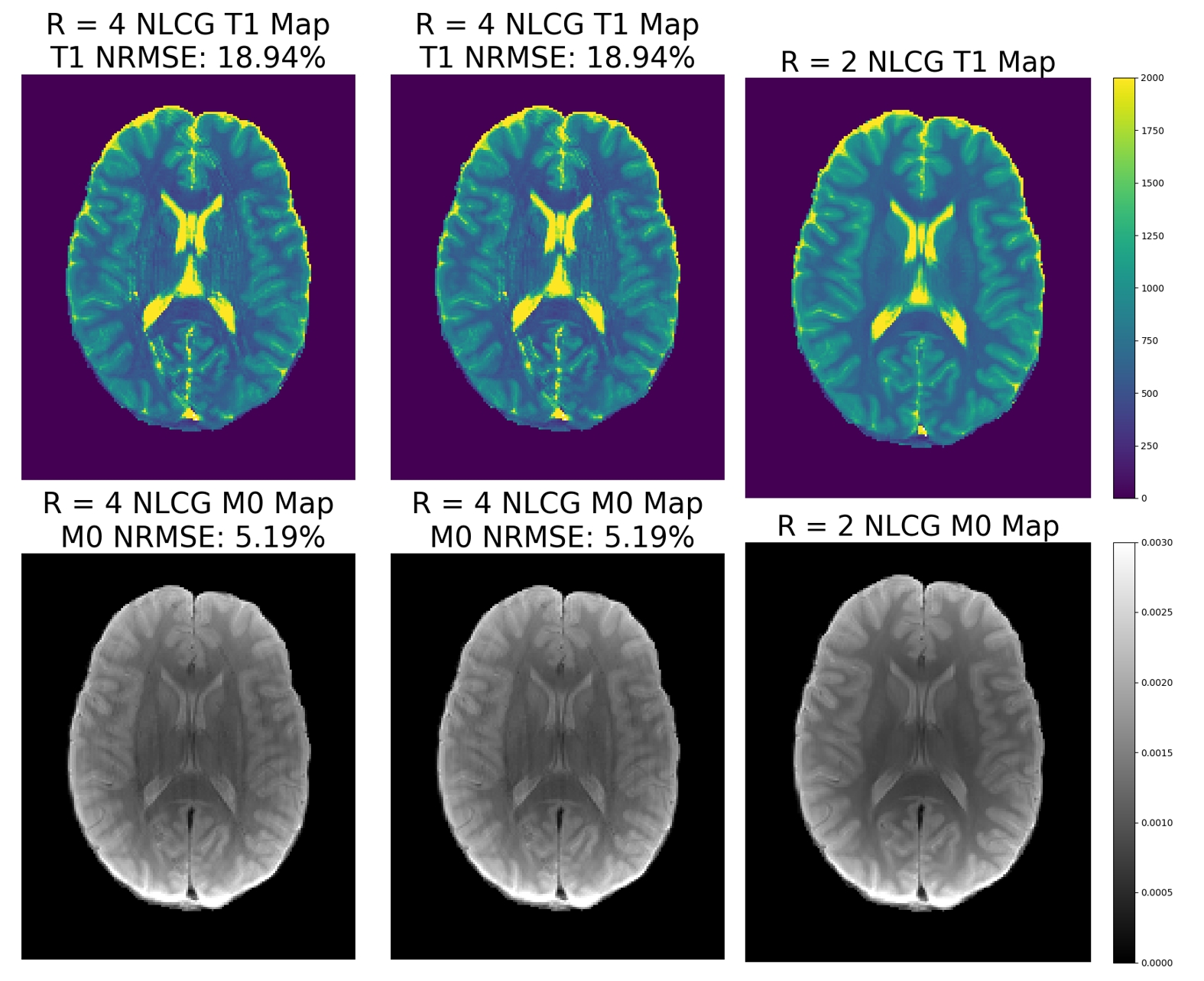
We used a set of fully sampled spin echo multi-coil data with FOV 256 × 208 for T2 mapping. 8 echo data are deployed from TE = 23ms to 184ms, with an echo spacing of 23ms. We simulate Acceleration by creating sampling masks, with acceleration factor R = 4 and 6. Central ACS region was used with width = 24. We also validated T1 mapping on in vivo data, which has been prospectively accelerated by R = 2. 5 sets of inversion recovery TSE data with TI from 35ms to 3000ms were acquired. We furthermore simulated the R = 4 condition without utilizing ACS region data for reconstruction. For metric consideration, we used normalized root mean squared error (NRMSE).
Results
We present T2, T1, and corresponding M0 map reconstruction results in Figs. 3-5. For comparison, we also presented T2 estimation using SENSE and Subspace. We observe that for T2 mapping, unregularized NLCG can readily achieve a good fit when considering NRMSE. However, as R increases, aliasing artifacts emerge, which were better mitigated using NLCG-Net. The proposed model could still retain the lowest NRMSE and address artifacts. For T1 mapping, it is observed that NLCG-Net has a similar performance.Discussion and Conclusion
We proposed a model-based zero-shot self-supervised learning framework, NLCG-Net for qMRI reconstruction, which is able to reach high acceleration factors with high fidelity. Its nonlinear estimation is flexible enough for both T2 and T1 mapping, and iterative optimization problem formulation allows neural network regularization while obviating the need for an external training datasets.Acknowledgements
No acknowledgement found.References
[1] Sumpf, T.J., Uecker, M., Boretius, S. and Frahm, J., 2011. Model‐based nonlinear inverse reconstruction for T2 mapping using highly undersampled spin‐echo MRI. Journal of Magnetic Resonance Imaging, 34(2), pp.420-428.
[2] Wang, X., Roeloffs, V., Klosowski, J., Tan, Z., Voit, D., Uecker, M. and Frahm, J., 2018. Model‐based T 1 mapping with sparsity constraints using single‐shot inversion‐recovery radial FLASH. Magnetic resonance in medicine, 79(2), pp.730-740.
[3]Aggarwal, Hemant K et al. “MoDL: Model-Based Deep Learning Architecture for Inverse Problems.” IEEE Transactions on medical imaging vol. 38,2 (2019): 394-405. doi:10.1109/TMI.2018.2865356
[4]Yaman, Burhaneddin, Seyed Amir Hossein Hosseini, and Mehmet Akçakaya. "Zero-shot self-supervised learning for MRI reconstruction." arXiv preprint arXiv:2102.07737 (2021).
[5]Blumenthal, Moritz et al. “NLINV-Net: Self-Supervised End-2-End Learning for Reconstructing Undersampled Radial Cardiac Real-Time Data.” ISMRM Annual Meeting: n. pag.
[6]Jun, Y, Cho, J, Wang, X, et al. SSL-QALAS: Self-Supervised Learning for rapid multiparameter estimation in quantitative MRI using 3D-QALAS. Magn Reson Med. 2023; 90(5): 2019-2032. doi: 10.1002/mrm.29786
Figures
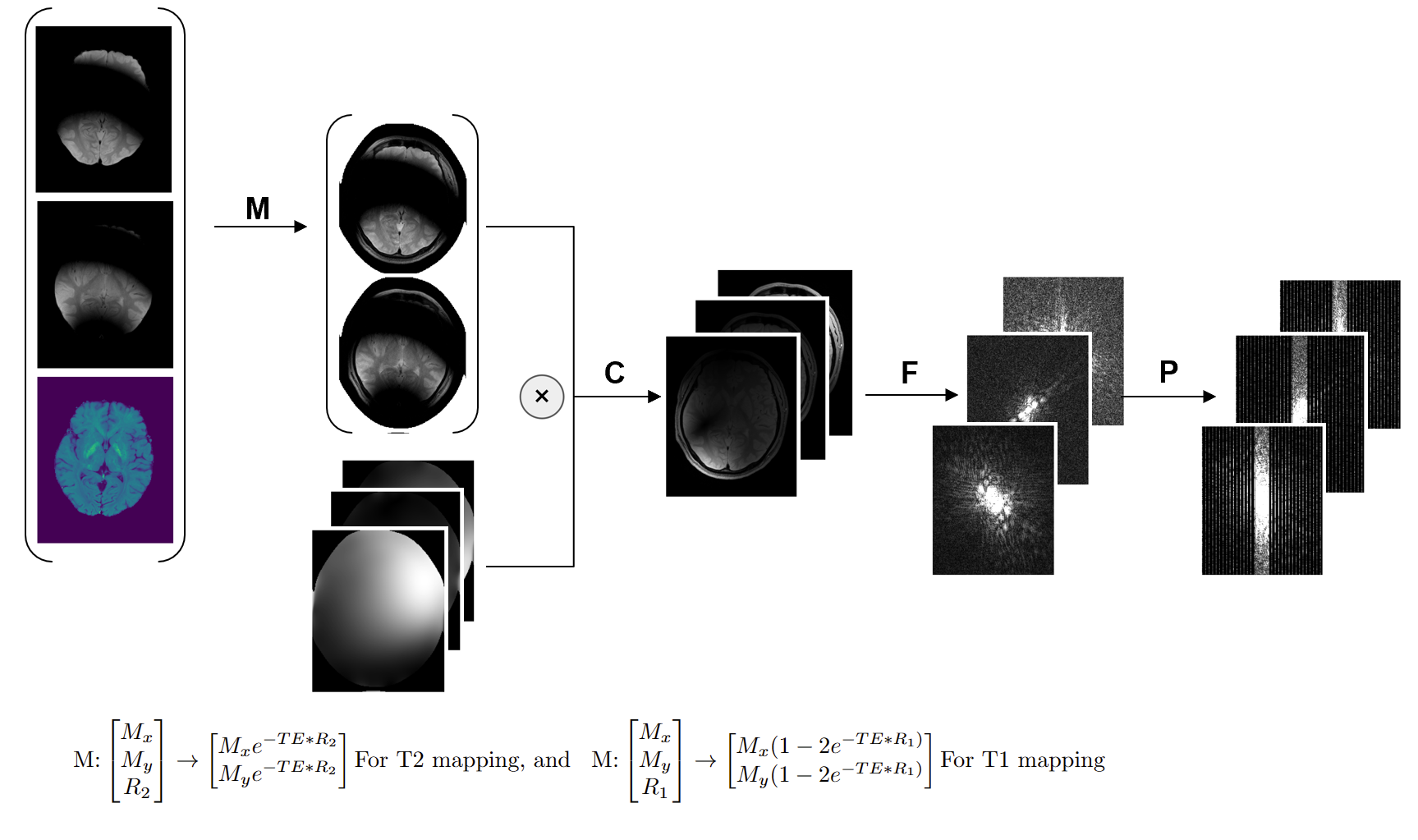
Fig.1: PFCM forward operators. To derive the k-space expression, x is firstly converted to signal intensity following T2/T1 quality, then multiplied with coil sensitivity maps to form each coil image. After that, Fast Fourier Transform F is performed to transform data into k-space, then finally applying mask P to reproduce downsample process.