4499
Cyclic-Consistency for Improved Self-Supervised Learning of Highly Accelerated MRI Reconstruction1Department of Electrical and Computer Engineering, University of Minnesota, Minneapolis, MN, United States, 2Center for Magnetic Resonance Research, University of Minnesota, Minneapolis, MN, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence, Self-supervised, Reconstruction
Motivation: To improve self-supervised deep learning (DL) reconstruction for highly-accelerated acquisition regimes.
Goal(s): To introduce the concept of cyclic-consistency to improve self-supervised DL reconstruction for highly-accelerated MRI.
Approach: Cyclic-consistency data is formed by simulating new undersampled acquisitions from the neural network output, with a similar undersampling pattern distribution as the true one. Then reconstruction on these simulated data is trained to match acquired data at the true sampling locations, building cyclic consistency for network training. This is supplemented with a conventional self-supervised masking strategy.
Results: The proposed method significantly reduces artifacts at rate 6 and 8 fastMRI reconstruction, and 20-fold fMRI.
Impact: Substantial reduction in aliasing artifacts is achieved at high acceleration rates using the proposed cyclic-consistent self-supervised learning method compared to existing self-supervised learning methods.
Introduction
Physics-driven deep learning (PD-DL)1-5 has become a powerful tool for accelerated MRI. In early works1-3, PD-DL networks were trained via supervised learning, necessitating fully-sampled data. Unsupervised techniques were subsequently developed, including self-supervised learning4 and generative models5,6, without the need for fully sampled reference datasets. In the former, a common approach is to mask part of k-space data and learn to predict it from the remainder4; while in the latter, underlying image priors are learned via a generative model, which are used along with a log-likelihood term at inference. In this work, we aim to improve self-supervised learning strategies by proposing to use cyclic-consistency (CC) with respect to acquired data. The main goal in CC is to simulate new measurements based on the reconstruction model, and to ensure reconstruction on these simulated measurements are consistent with acquired data. Variations on CC has been used in parallel imaging7, generative computer vision8, and more recently by the DL MRI reconstruction community9-12. In this study, we take an alternate approach to utilize CC for further enhancing self-supervised learning via data undersampling (SSDU)4 for improved PD-DL reconstruction. Results on fastMRI knee datasets13 and HCP-style fMRI14 show the proposed CC-based SSDU substantially improves image quality for highly-accelerated MRI.Methods
Cyclic-Consistency-based SSDU (CC-SSDU): Let $$$\bf{y_{\Omega}}$$$ be the acquired k-space measurements with forward operator $$$\bf{E_{\Omega}}$$$, which by k-space sampling locations $$$\bf\Omega$$$ of sub-sampling rate R. Reconstruction $$$\bf\hat{x}_{\Omega}$$$ is given by a PD-DL network:$$\bf\hat{x}_{\Omega}={\it{f}}(y_{\Omega},E_{\Omega};\theta)$$
where $$$\bf\theta$$$ denotes the learnable parameters. Let $$$\{\bf\Delta_{\it{n}}\}$$$ be undersampling patterns drawn from a similar distribution as $$$\bf\Omega$$$, in terms of acceleration rate, number of ACS lines and underlying distributions e.g. shifted equispaced or variable-density random with the same underlying distribution. New rate R measurements from $$$\bf\hat{x}_{\Omega}$$$ can be simulated using $$$\{\bf\Delta_{\it{n}}\}$$$ as:
$$\bf\hat{y}_{\Delta_{\it{n}}}=E_{\Delta_{\it{n}}}\hat{x}_{\Omega}$$
where $$$\bf{E_{\Delta_{\it{n}}}}$$$ shares the same coil sensitivities with $$$\bf{E_{\Omega}}$$$. Since a trained PD-DL network should generalize well to sampling patterns drawn from similar distributions, reconstruction using simulated measurements should be possible and yield a similar output:
$$\bf\hat{x}_{\Delta_{\it{n}}}={\it{f}}(\hat{y}_{\Delta_{\it{n}}},E_{\Delta_{\it{n}}};\theta)$$
This suggests that if $$$\bf{E_{\Omega}}$$$ is applied on $$$\bf\hat{x}_{\Delta_{\it{n}}}$$$ it should reliably map to $$${\bf{y}_{\Omega}}$$$. To this end, we proposed the following loss function:
$$\min_{{\bf{\theta}}}\mathbb{E}\left[\frac{1}{M}\sum_{m=1}^{M}\mathcal{L}\left({\bf{y_{\Lambda_{\it{m}}}}},{\bf{E_{\Lambda_{{\it{m}}}}}}\left({\it{f}}\left({\bf{y_{\Theta_{\it{m}}}}},{\bf{E_{\Lambda_{\it{m}}}}};{\bf\theta}\right)\right)\right)+\frac{1}{N}\sum_{n=1}^{N}\mathcal{L}\left({\bf{y_{\Omega}}},{\bf{E_{\Omega}}}{\it{f}}\left({\bf{E_{\Delta_{\it{n}}}}}\left({\it{f}\left({\bf{y_{\Omega}}},{\bf{E_{\Omega}}};{\bf{\theta}}\right)}\right),{\bf{E_{\Delta_{\it{n}}}}};{\bf{\theta}}\right)\right)\right]$$
where $$$\mathcal{L}$$$ denotes a loss function, e.g. MSE or $$$\mathcal{l}_1-\mathcal{l}_2$$$ loss4. The first term is the multi-mask(MM) SSDU loss15 with disjoint pairs of $$$\{\bf{\Lambda_{\it{m}},\Theta_{\it{m}}}\}$$$, and the proposed second term ensures that cyclic consistency is ensured by using $$$\bf\Omega$$$ (Fig. 1), We denote this consistency by $$$\bf\Omega\rightarrow\Delta_{\it{n}}\rightarrow\Omega$$$.
Reconstruction Experiments: For fastMRI knee datasets, comparisons were made to supervised training, and other self-supervised training methods, including MM-SSDU, Equalvariant Imaging (EI)9, and Unsupervised Learning from Incomplete Measurements (ULIM)10. EI enforces equivariance to image transformations, e.g. rotations. ULIM is the closest to our approach, but its first term uses consistency to all acquired (non-masked) data, a term that typically goes to noise level with PD-DL reconstructions, while the second term enforces consistency among simulated reconstruction outputs and not to $$$\bf{y_{\Omega}}$$$. In these datasets, equispaced Cartesian sub-sampling was performed at R=6,8 (24 ACS). $$$\{{\bf\Delta}_1,{\bf\Delta}_2...{\bf\Delta}_{\it{R}-1}\}$$$ were designed to select every Rth lines in k-space starting from the 1st, 2nd … (R-1)th line after the first sampled line in $$$\bf\Omega$$$, respectively.
For fMRI experiments, comparisons were made to split-slice GRAPPA(SPSG)16 and MM-SSDU. The datasets were acquired with SMS=5 and in-plane R=2 at HCP resolutions (1.6mm,7T). Further sub-sampling was performed to in-plane R=417.
Results
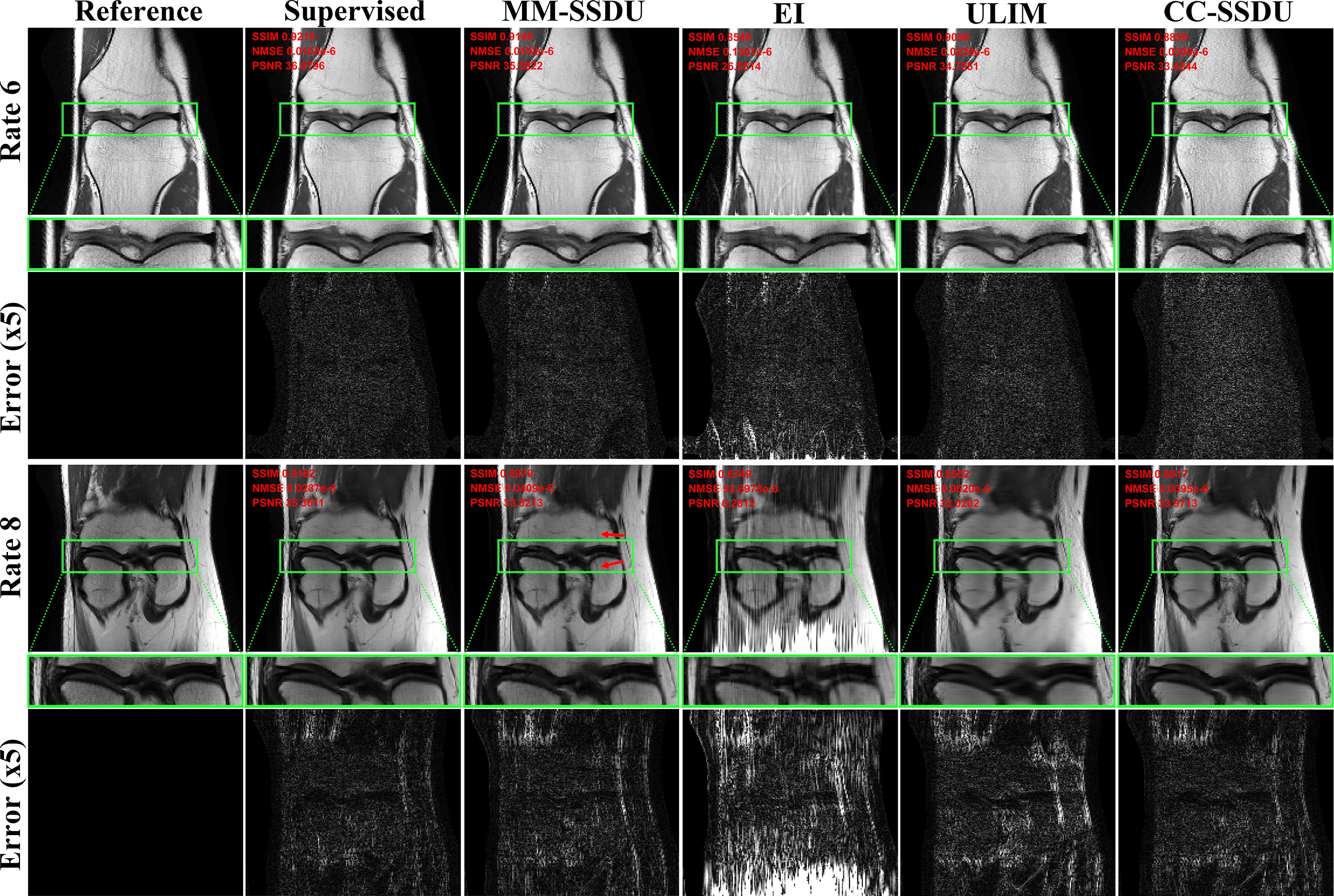
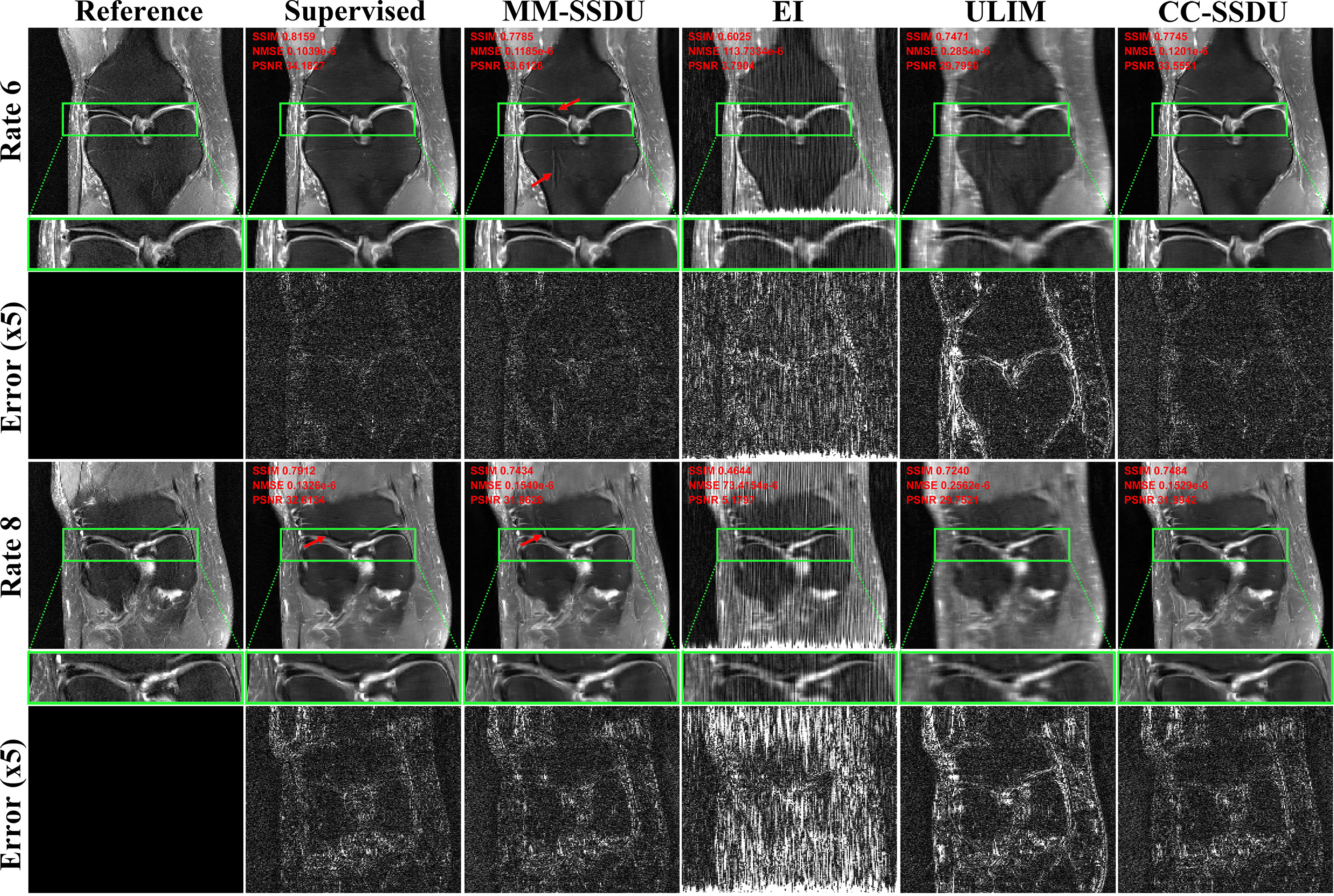
Fig. 2 depicts proton-density (PD)-weighted knee data. Supervised PD-DL removes artifacts, MM-SSDU has visible aliasing at R=8. CC-SSDU removes these artifacts. EI has visible aliasing at R=6, while ULIM suffers from blurring at R=8.Fig. 3 depicts fat suppressed PD (PDFS) knee data. CC-SSDU is the only methods that can suppress aliasing at both rates, while EI and ULIM show major artifacts.
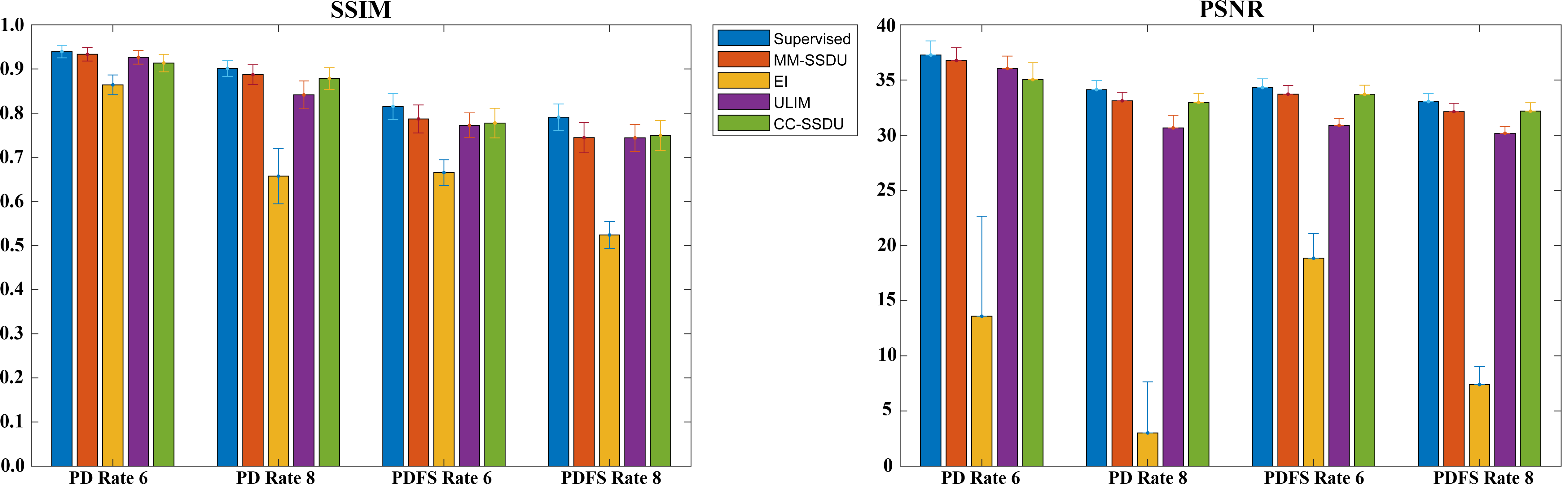
Fig. 4 SSIM and PSNR metrics for all testing slices. Supervised learning has the highest SSIM and PSNR in all cases. MM-SSDU and CC-SSDU show non-significant differences, while significantly improving (P<0.05) on EI and ULIM.
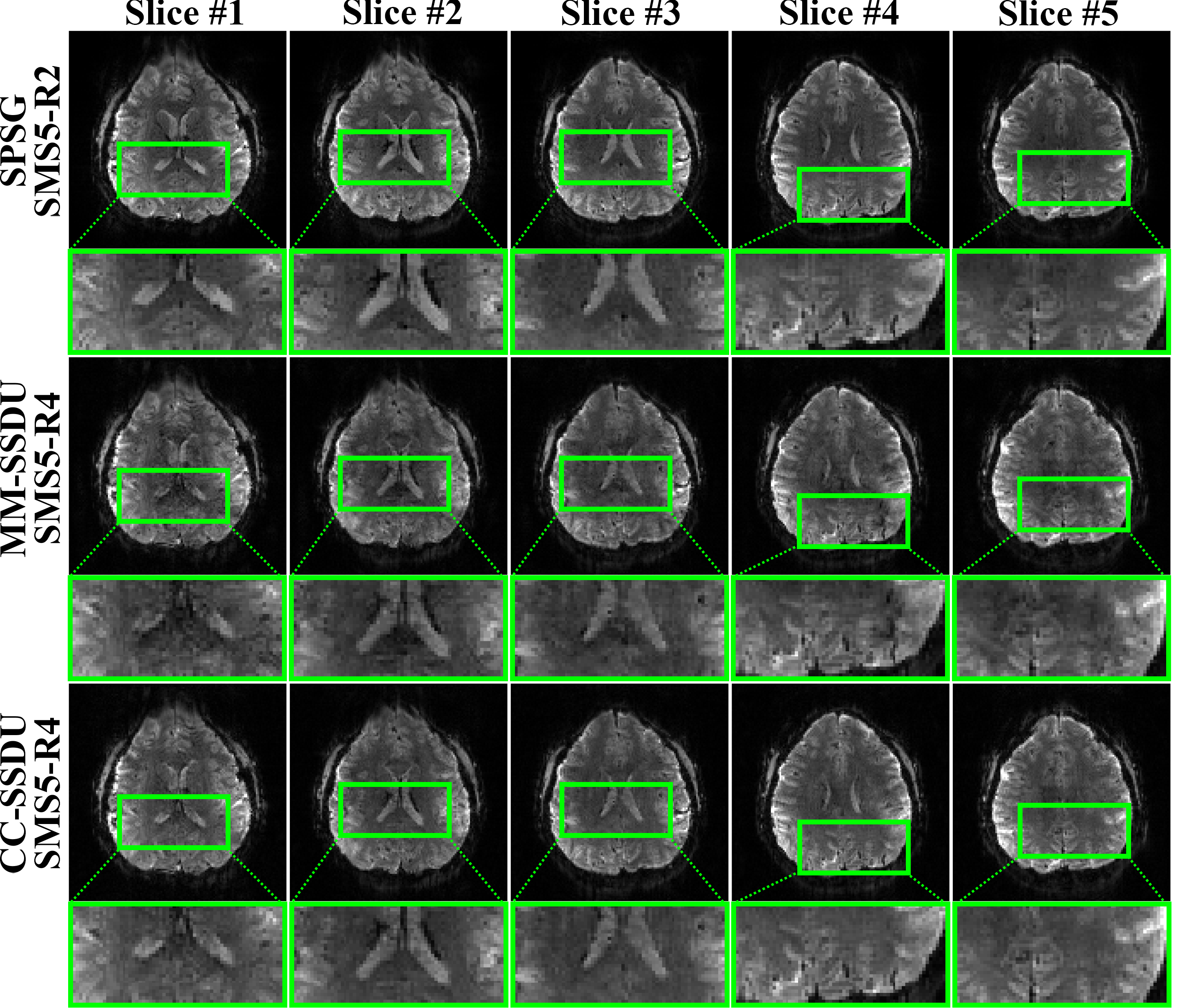
Fig. 5 shows a representative from HCP-style fMRI data, using SPSG, MM-SSDU and CC-SSDU. Due to lack of fully sampled ground truth, SPSG reconstruction at SMS5×R2 is provided as a baseline. SPSG suffers from artifacts at SMS5×R417. CC-SSDU shows the most homogeneous brain structures with less noise and aliasing compared to MM-SSDU.
Discussion and Conclusion
In this study, we propose a cyclic-consistency term for SSDU-type training of PD-DL. This method allows for reduction of aliasing at very high acceleration rates, outperforming existing self-supervised methods, including MM-SSDU, EI and ULIM. Note further cyclic consistencies are possible, e.g. $$$\bf\Omega\rightarrow\Delta_{\it{n}}\rightarrow\Delta_{\it{k}}\rightarrow\Omega$$$ for $$$k\neq{n}$$$, the benefit of which will be investigated in subsequent studies.Acknowledgements
This work was partially supported by NIH R01HL153146, NIH R01EB032830, NIH P41EB027061References
[1] Hammernik K, Klatzer, T, et al., Learning a variational network for reconstruction of accelerated MRI data, Magn Reson Med, vol. 79, pp. 3055–3071, 2018.
[2] Aggarwal HK, Mani MP, Jacob M, MoDL: Model-based deep learning architecture for inverse problems, IEEE Trans Med Imag, vol. 38, no. 02, pp. 394–405, 2019.
[3] Knoll F, Hammernik K, et al., Deep-learning methods for parallel magnetic resonance imaging reconstruction, IEEE Signal Processing Magazine, vol. 37, no. 1, pp. 128–140, 2020.
[4] Yaman B, Hosseini SAH et al., Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data, Magn Reson Med, vol. 84, no. 6, pp. 3172–3191, 12 2020.
[5] Sim B, Oh G, et al., Optimal transport driven cyclegan for unsupervised learning in inverse problems,” SIAM J Imag Sci, vol. 13, pp. 2281–2306, 2020.
[6] Jalal A, Arvinte M, et al., Robust compressed sensing MRI with deep generative priors, in Proc. NeurIPS, 2021, vol. 34, pp. 14938–14954.
[7] Zhao T, Hu X, Iterative GRAPPA (iGRAPPA) for improved parallel imaging reconstruction, Magn Reson Med, vol. 59, no. 4, pp. 903–907, 2008.
[8] Zhu JY, Park T et al., Unpaired image-to-image translation using cycle-consistent adversarial networks, In Proc. ICCV pp. 2223-2232 2017.
[9] Chen D, Tachella J, Davies ME, Equivariant imaging: Learning beyond the range space. In Proc. ICCV pp. 4379-4388 2021.
[10] Tachella J, Chen D, Davies M, Unsupervised learning from incomplete measurements for inverse problems, In Proc. NeurlPS vol. 6, no. 35, pp. 4983-4995 2022.
[11] Kim J, Lee W, et al., A noise robust image recon- struction deep neural network with cycle interpolation, in Proc. ISMRM, 2023, p. 3717
[12] Zhang C, Akçakaya M, Uncertainty-Guided Physics-Driven Deep Learning Reconstruction via Cyclic Measurement Consistency, ICASSP 2024.
[13] Knoll F, Zbontar J, Sriram A, et al., fastMRI: A publicly available raw k-space and DICOM dataset of knee images for accelerated MR image reconstruction using machine learning. Radiology: Artificial Intelligence 29;2(1):e190007 2020.
[14] Van Essen DC, Smith SM, et al., The WU-Minn Human Connectome Project: an overview, Neuroimage, vol. 80, pp. 62–79, 2013.
[15] Yaman B, Gu H, Hosseini SA, et al., Multi‐mask self‐supervised learning for physics‐guided neural networks in highly accelerated magnetic resonance imaging. NMR in Biomedicine 35(12):e4798 2022.
[16] Cauley SF, Polimeni JR, Bhat H, et al., Interslice leakage artifact reduction technique for simultaneous multislice acquisitions, Magn reson in med 72(1):93-102 2014.
[17] Demirel OB, Yaman B, Dowdle L, et al., 20-fold accelerated 7T fMRI using referenceless self-supervised deep learning reconstruction. In Proc. EMBC pp. 3765-3769 IEEE 2021.
Figures
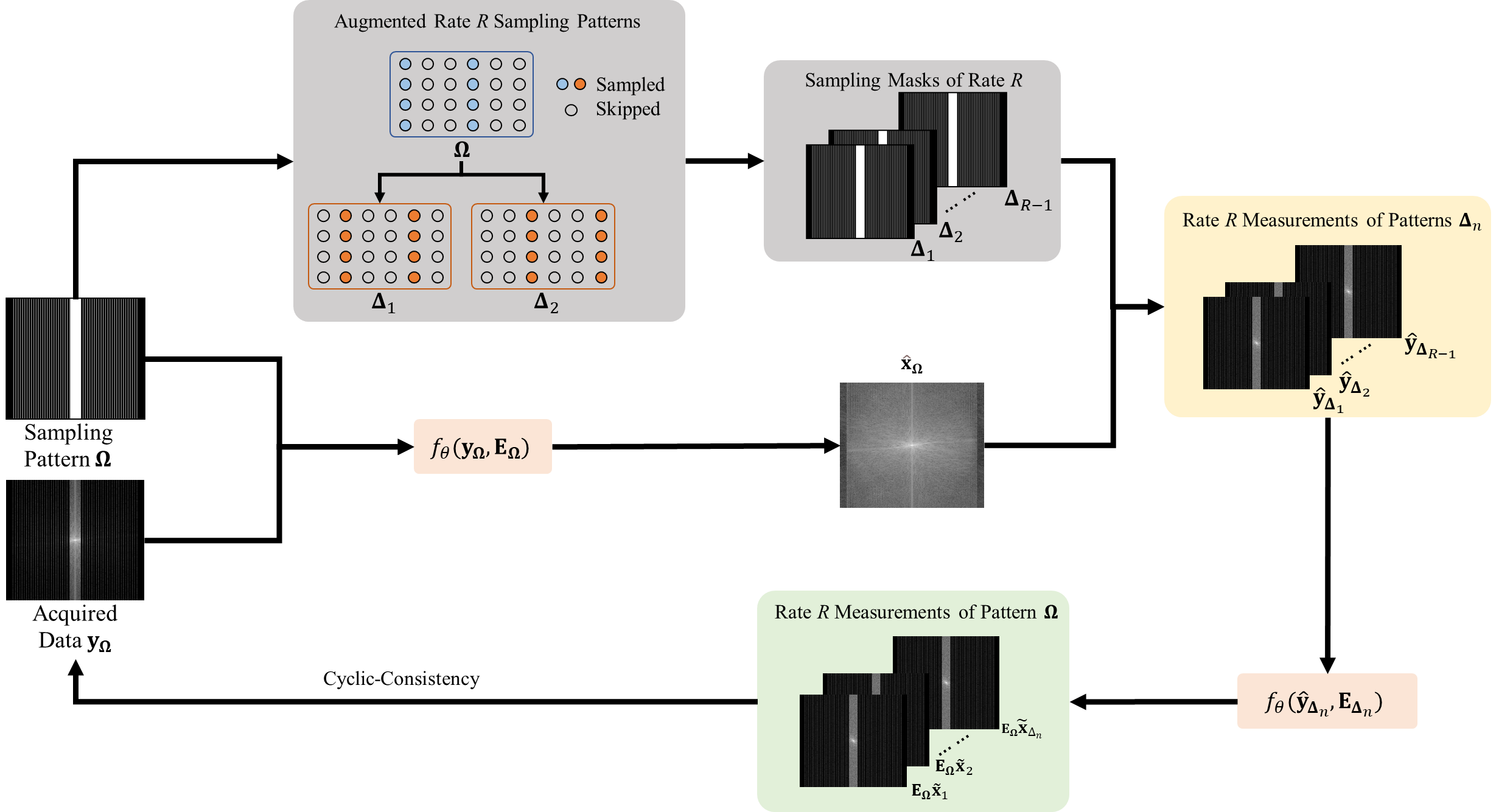
Illustration of cyclic-consistency with respect to acquired data. $$$\{{\bf \Delta}_{\it n}\}$$$ are undersampling patterns drawn from a similar distribution as the true pattern $$$\bf\Omega$$$. These are used to generate simulated measurements $$$\bf\hat{y}_{\Delta_{\it n}}$$$ from reconstruction $$$\bf\hat{y}_{\Delta_{\it n}}$$$. Reconstructions of $$$\bf \hat{y}_{\Delta_{\it n}}$$$ are fed to $$$\bf E_{\Omega}$$$ to re-estimate the acquired data, building $$$\bf \Omega \rightarrow \Delta_{\it n} \rightarrow \Omega$$$ consistency for PD-DL training.