4498
Detail-preserving self-supervised federated learning for undersamped MR image reconstruction1Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, shenzhen, China, 2School of Physics and Optoelectronics, Xiangtan University, xiangtan, China, 3Peng Cheng Laboratory, shenzhen, China
Synopsis
Keywords: AI/ML Image Reconstruction, Data Processing
Motivation: Self-supervised learning-based MR image reconstruction learn a prior on the data distribution, but data in medical imaging settings are highly diverse, which consists of different corruptions or degradation factors. Existing methods need improvement in preserving details for undersampled image reconstruction with different degradation factors.
Goal(s): Our goal is to preserve details for undersampled image reconstruction with different degradation factors.
Approach: A detail-preserving self-supervised federated learning method is proposed to preserve details by employing personalized federated models to refine undersampled training data iteratively.
Results: Experiments show that promising results are achieved by proposed method, and details are preserved and refined for undersampled image reconstruction.
Impact: Detail-preserving self-supervised federated learning method can effectively preserve more details compared to self-supervised learning methods.
Introduction
Magnetic resonance imaging (MRI) is an effective tool for disease assessment. However, the long scanning time of MRI limits its wide applications. Undersampled data acquisition is an effective approach to accelerate MRI, and self-supervised learning methods are widely used to reconstruct MRI images directly from undersampled data by learning a prior on the data distribution1,2. However, data in medical imaging settings are highly diverse as collected using different imaging scanners or protocols, which causes different corruptions and degradation factors in undersampled data, more specially, different undersampled aliasing artifacts. These different undersampled aliasing artifacts from diverse data can’t be represented by a prior on specific data distribution, and undersampled MR image reconstruction suffers from fine-detail loss.FL-based approaches can learn valuable priors from diverse data with different imaging scanners or protocols3-5. It is a potential strategy to remove a wider range of undersampled aliasing artifacts and capture image details. As such, we propose to train personalized federated models from multi-institutional undersampled data to refine undersampled training data iteratively and capture image details for accurate MR reconstruction.
Method
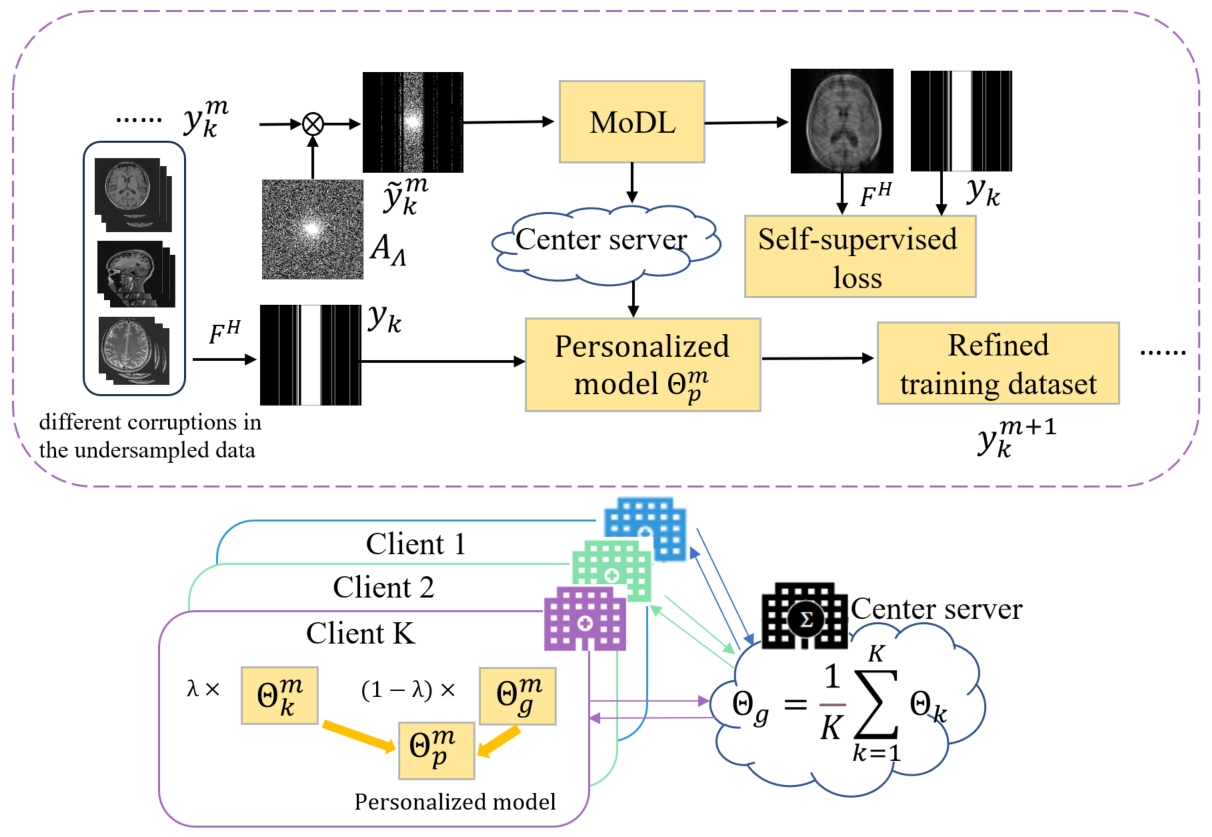
The proposed method targets at preserving details for undersampled MR image reconstruction. The overall framework is shown in Figure 1. The method is executed in multiple optimization stages to refine undersampled training data, each consisting of three steps. These steps include: (1) the local training with self-supervised learning, (2) acquiring personalized models through learning the different data prior distributions adaptively, and (3) optimizing the undersampled training dataset at the local client. Step (1) local training: we assume that the undersampled dataset $$$S=\{S_{1},\ldots, S_{K}\}$$$ from K sites participate in federated learning training. The paired training data in the local training of each client can be represented as follows:The self-supervised training dataset of client $$$k$$$: $$$\{\tilde{y}_{k}^{i},y_{k}^{i}\}_{i=1}^{N}$$$
where $$$\tilde{y}_{k}^{i}=M_{\Lambda}y_{k}^{i}=M_{\Lambda}M_{\Omega}y_{0,k}^{i}$$$, $$$y_{0,k}^{i}$$$ represents fully sampled data for sample $i$ in client $$$k$$$, and $$$N$$$ represents the number of samples in the training dataset. The reconstruction loss function of the model can be represented as:
$$\widehat{\Theta}=\arg\min_{\Theta}\mathbb{E}[\parallel M_{\Omega}(f_{\Theta}(\tilde{Y})-Y\parallel_{2}^{2}\mid\tilde{Y}]$$
Step(2)Acquiring personalized models through adapting to the different centers’ data distributions : After L rounds of local training, in each client, all the parameters of the local reconstruction networks are uploaded to the central server. By averaging the parameters $$$\Theta_{k}$$$ of these local models, an aggregated global model is obtained:
$$\Theta_{g}=\frac{1}{K}\sum_{k=1}^{K}\Theta_{k}$$
where $$$\Theta_{g}$$$ represents the parameters of the global model. However, the differences in imaging protocols, imaging scanners, and other factors in data acquisition cause performance degradation of the global model. Therefore, we initialize personalized models for each client by aggregating the parameters of the global model and local model dynamically. The personalized models $$$\Theta_{p}$$$ can be described as follows:
$$\Theta_p=\lambda\Theta_k+(1-\lambda)\Theta_g$$
where $$$\lambda\in[0,1]$$$ represents the weight parameter to balance the relationship between the global model and local model.
Step (3) Optimizing the undersampled training dataset at the local client: This method divides the model training process into multiple optimization stages. In each optimization stage, we pass the undersampled training dataset through the personalized model $$$\Theta_{p}$$$ obtained in step (2) before training dataset is employed to calculate the loss function. We assume that the undersampled training dataset for optimization stage $m$ is defined as $$$\{\tilde{y}^{m+1,i},y^{m+1,i}\}_{i=1}^{N}$$$. At first stage, we first perform local training with the initial undersampled training dataset $$$\{\tilde{y}_{k}^{1, i},y_{k}^{1,i}\}_{i=1}^{N}$$$ in client $$$k$$$. At optimization stage $$$m$$$, passing the training dataset for the next optimization stage through personalized model $\Theta_p^m$ can be seen as an offline test of the local training data. Therefore, the input of $$$\Theta_p^m$$$ is initial undersampled data $$$y_{k}^{1}$$$, rather than $$$\tilde{y}_k^1$$$. The generation of the training dataset for optimization stage $m+1$ can be represented as follows:
$$\mathrm{y}_{k}^{m+1}={\mathcal F}(\Theta_{p}^{m};y_{k}^{1})$$
where $$$\Theta_p^m$$$ represents the personalized model at optimization stage $$$m$$$. The optimized self-supervised training dataset $$$\{\tilde{y}^{m+1,i},y^{m+1,i}\}_{i=1}^{N}$$$ is only used for local training in the next optimization stage.
Result
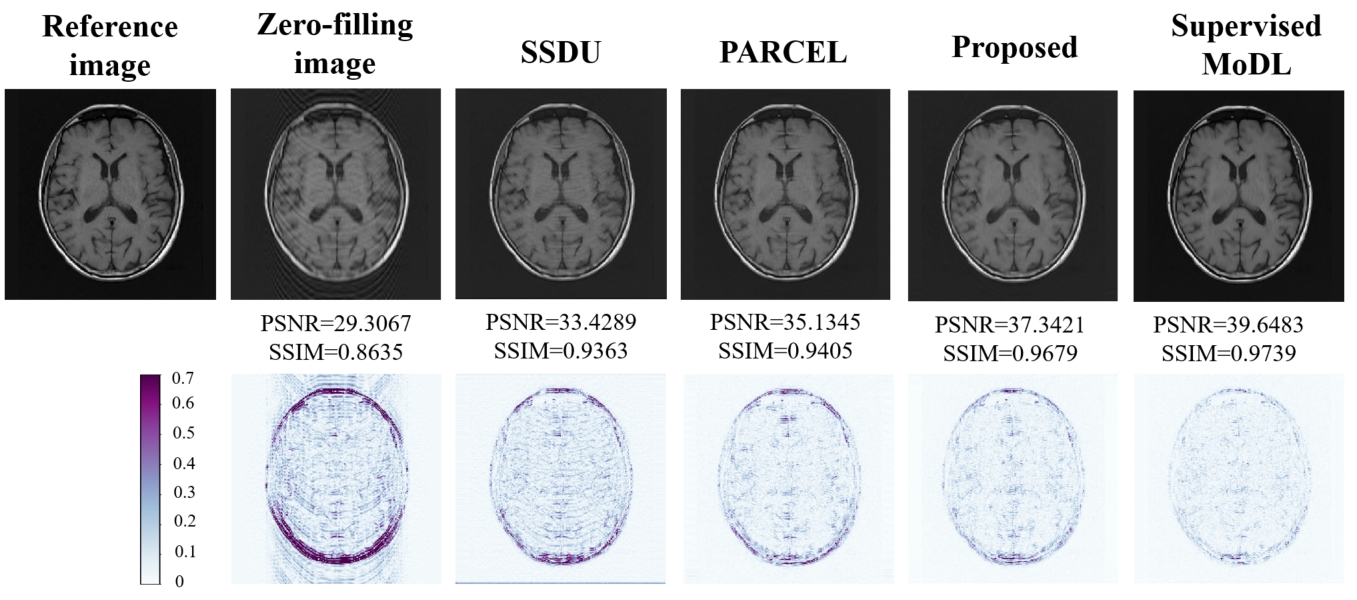
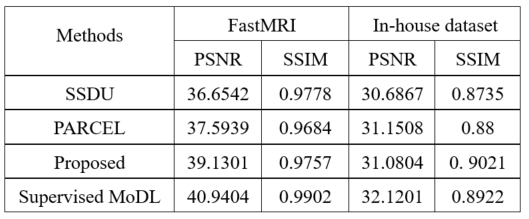
Four complex-valued datasets, namely, FastMRI, CC359, Modl dataset, and one in-house dataset are employed. Quantitative evaluation metrics including PSNR and SSIM. Figure 2 and Table 1 show some reconstruction results of the proposed approach compared with existing methods. From these qualitative results, we observe that our method can reconstruct images with smaller errors and is better at detail preservation and artifact removal when compared to the other self-supervised methods, and can achieve comparable performance with the baseline supervised method at detail preservation.Conclusion
We propose self-supervised federated learning to preserve details by employing personalized federated models to refine training data iteratively and capture image details for accurate MR reconstruction. Experimental results show that our method can achieve better reconstruction results compared to self-supervised learning methods.Acknowledgements
This research was partly supported by the National Natural Science Foundation of China (62222118, U22A2040), Guangdong Provincial Key Laboratory of Artificial Intelligence in Medical Image Analysis and Application (2022B1212010011), Shenzhen Science and Technology Program (RCYX20210706092104034, JCYJ20220531100213029), and Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052).References
[1] B. Yaman, S. A. H. Hosseini, S. Moeller, J. Ellermann, K. Ugurbil, and M. Akc¸akaya, “Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data,” Magnetic resonance in medicine, vol. 84, no. 6, pp. 3172–3191, 2020.
[2] S. Wang, R. Wu, C. Li, J. Zou, Z. Zhang, Q. Liu, Y. Xi, and H. Zheng, “PARCEL: Physics-based Unsupervised Contrastive Representation Learning for Multi-coil MR Imaging,” IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2022.
[3] P. Guo, P. Wang, J. Zhou, S. Jiang, and V. M. Patel, “Multi-institutional collaborations for improving deep learning-based magnetic resonance image reconstruction using federated learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2423–2432.
[4] C.-M. Feng, Y. Yan, S. Wang, Y. Xu, L. Shao, and H. Fu, “Specificity preserving federated learning for MR image reconstruction,” IEEE Transactions on Medical Imaging, 2022. [12] G. Elmas, S. U. Dar, Y. Korkmaz, E. Ceyani, B. Susam, M. Ozbey, S. Avestimehr, and T. C¸ ukur, “Federated learning of generative image priors for MRI reconstruction,” IEEE Transactions on Medical Imaging, 2022.
[5] J. Lyu, Y. Tian, Q. Cai, C. Wang, and J. Qin, “Adaptive channel modulated personalized federated learning for magnetic resonance image reconstruction,” Computers in Biology and Medicine, vol. 165, p. 107330, 2023.
Figures