4495
Scale Time-Equivariant Convolutional Neural Networks For Dynamic Magnetic Resonance Imaging1Department of Electrical and Electronic Engineering, University of Nottingham, Ningbo, China, Ningbo, China, 2Research Center for Medical AI, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, Shen Zhen, China, 3Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, Shen Zhen, China
Synopsis
Keywords: AI/ML Image Reconstruction, Image Reconstruction, cardiac, unrolled, deep neural network, equivariance
Motivation: The scale symmetry of anatomical structures commonly exists in dynamic magnetic resonance imaging (MRI) data but have rarely been explored.
Goal(s): Our goal is to effectively leverage the scale symmetry of local structures in both spatial and temporal dimensions to improve the reconstrcution quality in dynamic MRI.
Approach: We present a novel method that incorporates the scale equivariant convolution modules into an unrolled deep neural network.
Results: The proposed method was test on the cardiac cine MRI data reconstruction tasks and achieved the improved performance with a PSNR of 43.6967 and a SSIM of 0.9834.
Impact: Our method improved the data-efficiency for deep dynamic MRI reconstructions and robustness to drifts in scale of the images that might stem from the variability of patient anatomies or change in field-of-view across different MRI scanners.
Introduction
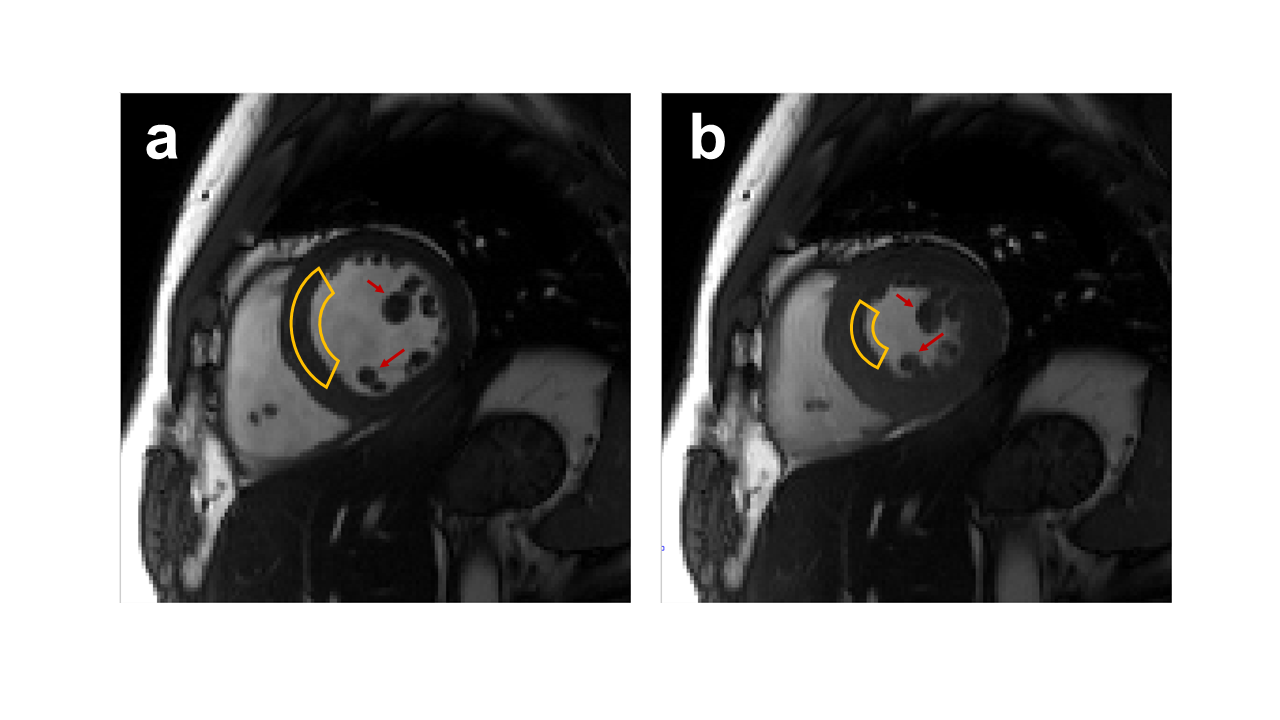
MRI is intrinsically slow due to physical limitations. For more advanced imaging applications, such as dynamic imaging, a large number of samples have to be acquired, leading to a longer imaging time. In the past few years, deep learning (DL)-based methods have shown its great potential in accelerating dynamic MR imaging. Equivariant convolutional neural networks (CNNs)1, a novel deep learning method used in computer vision tasks, encoding the symmetries into the architecture of CNNs and thus improves the learning capability of network.In most dynamic MRI samples, various symmetries of anatomical structures commonly exist in one frame or between different frames. As shown in Fig.1, scaled variants of the similar anatomical features commonly occur in the same image or in other frames. It is expected to effectively leverage these symmetries by using the equivariant CNNs. However, conventional equivariant CNNs cannot exploit scale symmetry along the temporal dimension due to the scale equivariance is not satisfied in the dynamic MRI reconstruction models.
In this study, we propose a scale time-equivariant CNN for dynamic MRI. A novel 1D temporal-equivariant convolution layer was proposed to preserve the scale equivariance of the proximal operators in the reconstruction model. The proposed method was compared against the compressed sensing method L+S 2, a deep learning method dynamic MoDL 3 and DL-ESPIRiT (named as R2plus1D) 4.
Methods
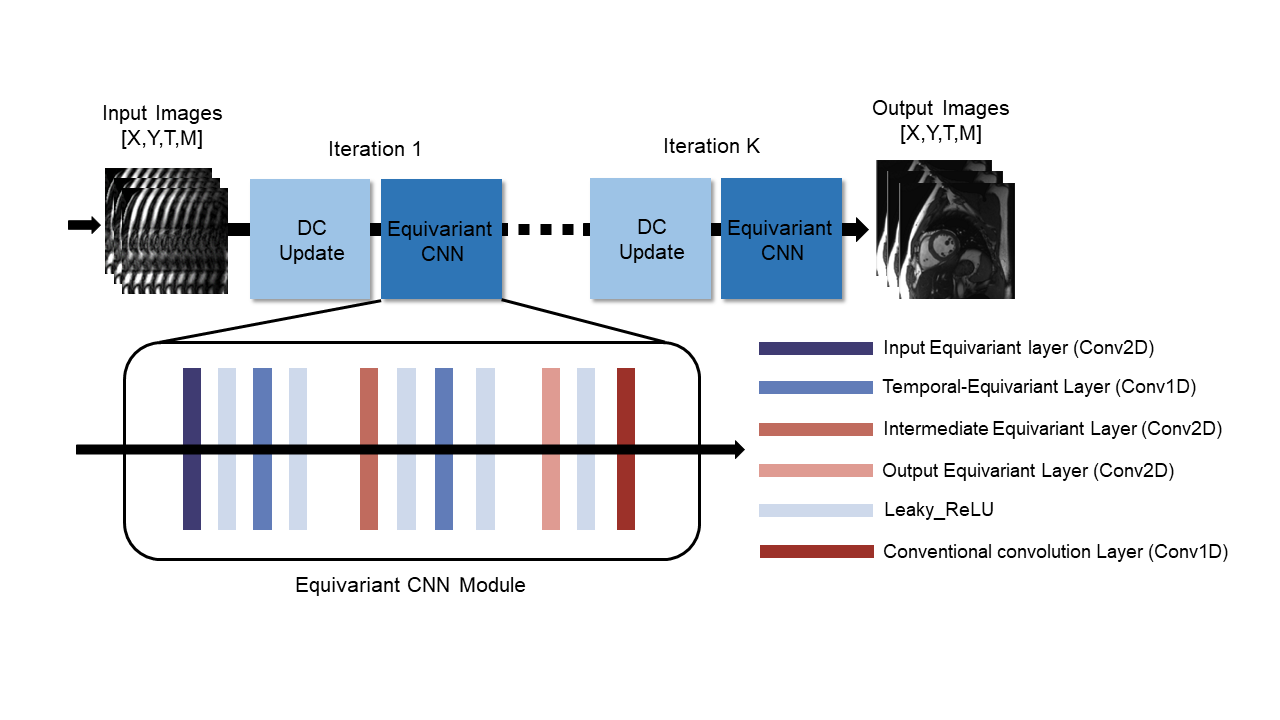
Our method is based on an unrolled PGD network: DL-ESPIRiT model. Fig.2 presents the schematic representation of our network framework. The network adopts a zero-filled reconstruction of a 2D cardiac cine slice with its corresponding ESPIRiT map as the input and then alternates between 3D spatiotemporal CNN blocks and data consistency steps. All the 3D convolutions are replaced with (2+1)D convolutions in each spatiotemporal CNN block to decrease the trainable parameters of the network while preserving the same learning ability5. The regular 2D convolution layers in the network can be directly replaced by three types of scale equivariant layers: input, intermediate and output equivariant layers. In the input layers, the channels of filters have been extended by the scale group. In the intermediate layers, a complex operation was employed on the channels of filter, which can be expressed as follows:$$\left(\tilde{\phi}\star F\right)^{C}=\sum_B^S \tilde{\phi}^{C,C^{-1}B}\star F^{B}$$
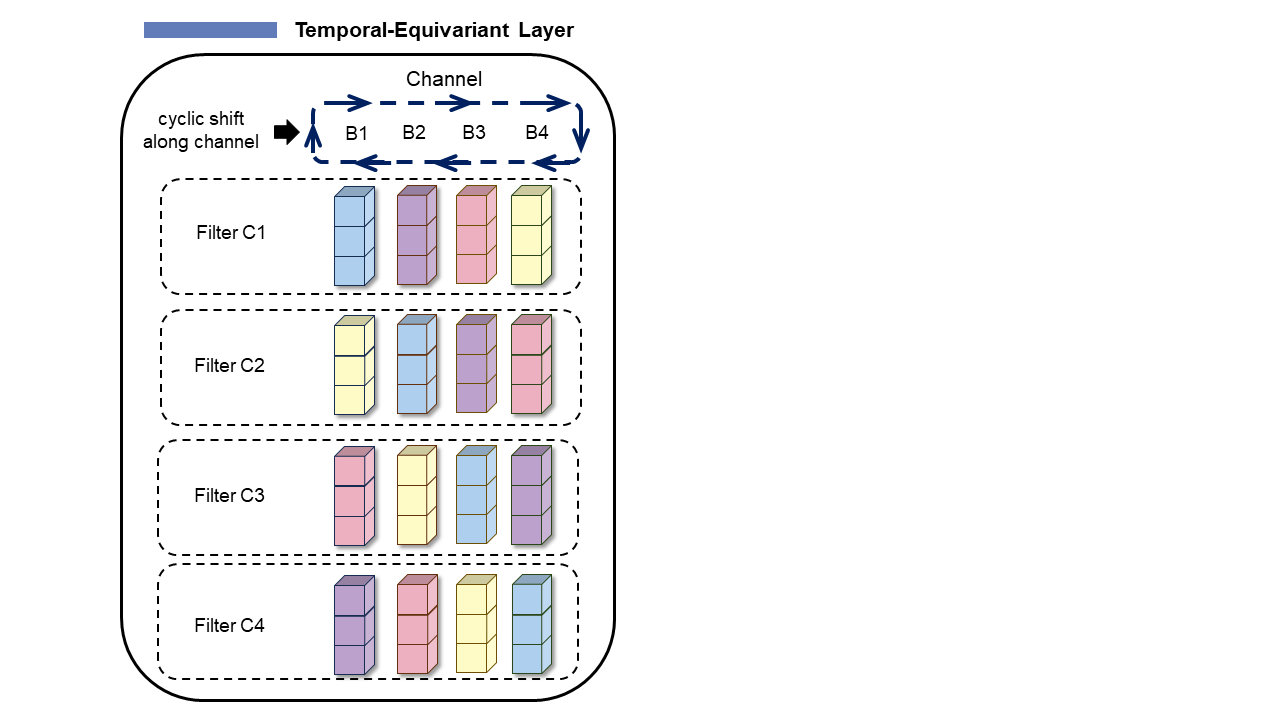
where $$$\tilde{\phi} $$$ denotes the convolution for intermediate layer, F denotes an intermediate feature map. The scaling matrixes B and C are group elements of the scale group S. To specific, this operation can be implemented by cyclically shifting the channels of scaled filters along a third mode. However, the regular convolutions along temporal dimension destroyed the scale equivariance between two spatial equivariant layers. To tackle this, we propose a novel 1D Temporal-Equivariant convolution layer to preserve the global equivariance of the unrolled network, which is shown in Fig. 3.
The fully sampled cardiac cine data were collected from 29 healthy volunteers on a 3T scanner (MAGNETOM Trio, Siemens Healthcare), and the protocols were approved by our Institutional Reviews Board (IRB). Finally, 800 multi-coil cardiac MR data are used for training, 30 for validation, and 118 for testing. We applied a variable density incoherent spatiotemporal acquisition (VISTA) sampling mask and set the acceleration factor to 16 in our experiments.
The number of iterations is set to be 10 empirically. The ADAM optimizer was employed to train the models, and the learning rate was set to 0.0005 and adjusted with an exponential decay rate of 0.95. The zoom-in images and the error maps were used to give visual comparisons. Two metrics peak signal to noise ratio (PSNR) and structural similarity index (SSIM) were calculated to evaluate performance.
Results
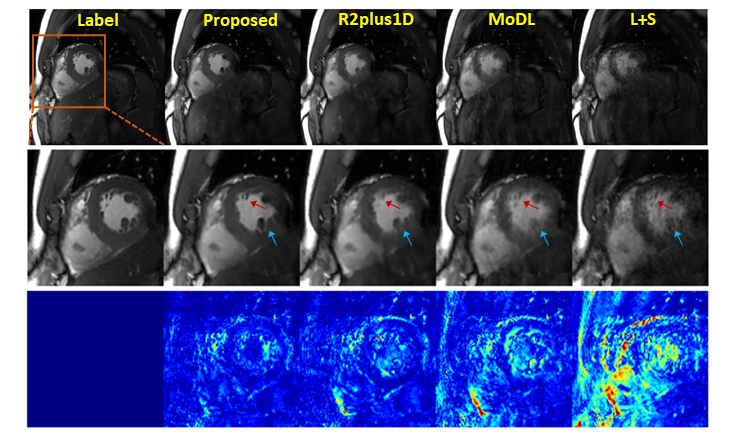
The qualitative comparisons were shown in Fig. 4, where the reconstructed images in the spatial domain, as well as the corresponding error maps, were provided. The results demonstrated that the proposed method can faithfully reconstruct the images with smaller errors and clearer anatomical details indicated by the error maps and the zoom-in images. Table 1 shows the quantitative results of proposed method and competitive methods. For a fair comparison, all the methods were set to have similar number of model parameters. Compared with other SOTA, the proposed method achieved the best performance with a PSNR of 43.4156 and a SSIM of 0.9830.Discussion and Conclusion
In this study, we propose a novel method that incorporates the scale equivariant convolution modules into an unrolled neural network for dynamic MRI reconstruction. The improved reconstruction performance has demonstrated that our method can effectively utilize the scale symmetry existing in both spatial and temporal dimension of the dynamic MRI data.Acknowledgements
This work was partially supported by the National Natural Science Foundation of China (62331028, 62106252), the National Key R&D Program of China (2023YFB3811400), and the Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2023B1212060052).References
- Cohen T and Max W. Group equivariant convolutional networks. International conference on machine learning. 2016; 2990-2999.
- Otazo R, Emmanuel C, and Daniel K. Low‐rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components. Magn. Reson. Med. 2015;73(3): 1125-1136.
- Aggarwal H, Merry P, and Mathews J. MoDL: Model-based deep learning architecture for inverse problems. IEEE transactions on medical imaging 2018;38(2): 394-405.
- Sandino C, Lai P, et al. Accelerating cardiac cine MRI using a deep learning‐based ESPIRiT reconstruction. Magn. Reson. Med. 2021;85(1): 152-167.
- Tran D, Wang H, et al. A closer look at spatiotemporal convolutions for action recognition. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018; 6450-6459.
Figures