4491
Deep Learning-Based High Frequency Constrained Fast Image Reconstruction for 4D Cardiac MRI1Cardiovascular Innovation Research Center, Heart Vascular Thoracic Institute, Cleveland Clinic, Cleveland, OH, United States, 2Chemical and Biomedical Engineering, Cleveland State University, Cleveland, OH, United States, 3Case Western Reserve University, Cleveland, OH, United States, 4Cardiovascular Medicine, Heart Vascular Thoracic Institute, Cleveland Clinic, Cleveland, OH, United States, 5Imaging Institute, Cleveland Clinic, Cleveland, OH, United States, 6Biomedical Engineering, Case Western Reserve University & Cleveland Clinic, Cleveland, OH, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Cardiovascular
Motivation: Online image reconstructions for prospectively undersampled cardiac MRI data are noisy as the naïve approach fails to remove undersampling artifacts. Compressed sensing (CS) reconstruction reduces artifacts but is time and memory intensive, making it an offline reconstruction option only.
Goal(s): Our aim was to address these constraints by training a Deep Learning (DL) model to obtain high resolution online reconstructions.
Approach: We achieved this by implementing a spatiotemporal UNET with a weighted high frequency loss.
Results: We found the results of the DL model comparable to the CS reconstruction in image quality, with lower computational cost, making it suitable for online reconstructions.
Impact: Our image denoising Deep Learning (DL) model showed similar results to the time consuming, more computationally expensive compressed sensing (CS) reconstruction (gold standard), thus demonstrating its potential for online reconstruction of prospectively undersampled cardiac MRI data.
Introduction
Compressed sensing (CS)1 is a well-known solution to reconstruct undersampled MRI data to improve image quality and enable fast imaging applications2. However, CS requires manual tuning of hyperparameters for each subject, is often time consuming, and requires high performance computing infrastructure3. These drawbacks limit CS in online reconstruction workflows. Deep Learning (DL) based image denoising can potentially overcome these problems as DL models are computationally efficient, and consistently applicable at inference4. However, many DL-based denoising models cause blurring due to properties of the mean squared error loss5,6. In this work, we propose to train a DL denoising model with a high frequency weighted loss function to enable fast, efficient cardiac magnetic resonance imaging (CMR) reconstruction. We evaluate our method on 4D cine, a particularly computationally expensive imaging paradigm.Methods
Data: We acquired time-resolved 3D cardiac cine data (Figure 1A) for 31 subjects under a Cleveland Clinic IRB approved protocol on a 3T MR System. The data was prospectively undersampled in each axial slice using a variable density sampling pattern (Figure 1B). The 4D (3D spatial + time) data was split into 2D axial slices with all the cardiac phases of the slice stacked as the 3rd dimension (Figure 1C) to fit the data into a single GPU.Model: We employed a 3D UNET7 for image denoising to capture spatiotemporal consistencies in tissue visualization. Following a supervised training paradigm, we used the CS reconstructions of the undersampled data as the gold standard “denoised” images. The CS reconstructions were implemented in 4 dimensions with total variation regularization applied temporally. We modified the loss function to a weighted sum of the Mean Squared Error (MSE)5 loss (=$$$\frac{\sum_{}^{}\left(y_{i}-\widehat{y_{i}}\right)^{2}}{n}$$$) and Focal Frequency8 loss (=$$$\frac{1}{MN}\sum_{u=0}^{M-1}\sum_{v=0}^{N-1}w\left(u,v\right)\left|F_{CS}\left(u,v\right)-F_{DL}\left(u,v\right)\right|^{2}$$$) , where $$$w\left(u,v\right)=\left|F_{CS}\left(u,v\right)-F_{DL}\left(u,v\right)\right|$$$, $$$F\left\{.\right\}=Fourier Transform\left(image\right)$$$, to ensure that high frequency details of the images are preserved by the model.
Analysis: We used Peak Signal-to-noise Ratio (PSNR)9 to quantify the quality of the DL-enhanced images in comparison with the CS reconstructions. The difference maps are the differences between the CS reconstruction and DL enhancement with respect to the naïve reconstructions. We further compare ejection fraction found via manual segmentations of the left ventricle in three slices of the short-axis (SAX) view in each test dataset between the DL-denoised results and the naïve reconstructions to ensure cardiac motion is preserved. The in-plane displacement maps10 are computed using a single line through the heart along the slice encoding direction through time to observe cardiac motion. The data was split into training/validation/testing set of 22/5/4 subjects respectively.
Results
Training the UNET took 10 hours for 50 epochs with batch size 8 on an Nvidia A100 GPU. After training, the inference time for a whole volume was 1.5 seconds. In contrast, whole volume data took 27 minutes to reconstruct using CS. The reconstruction results are shown in Figure 2. The DL-enhanced PSNR (35.180$$$\pm$$$5.616) does not drop compared to the PSNR of the CS reconstructions (32.437$$$\pm$$$2.495), which in accordance with the images in Figure 2, shows that the enhancement quality of the UNET results is comparable to the quality of the CS reconstructions. We calculated the left ventricle ejection fractions (LVEF) to be 47.13%$$$\pm$$$5.78% for the UNET enhanced images and 49.90%$$$\pm$$$6.33% for the naïve reconstructions (Figure 3). Qualitatively, there is high correlation between the displacement maps between our DL model, the naïve reconstructions and the CS reconstructions (Figure 4).Discussion
We show that our DL model achieves similar results with the CS reconstruction paradigm but with much higher computational efficiency. Although individually the CS reconstruction was much faster than training the DL model, the actual inference time was a fraction of the time compared to CS reconstruction. Reconstructing a single dataset using CS also requires high computational capacity as it requires all 30 cardiac frames of a 3D dataset to be loaded onto the GPU for each iteration (thus cannot use V100 GPUs). The UNET model allows more flexibility in comparison as we can load 30 frames of a 2D slice and decide how many slices to process at once when using a single GPU. Given the model is only 86 MB, it can fit on a single A2000 GPU. Therefore, DL-based denoising is a potential solution for online image reconstruction.In future work, we will increase the number of datasets to train the model and also evaluate the model for generalizability.
Conclusion
We trained a high frequency penalty-based DL model to denoise undersampled cardiac MRI data with results comparable to CS reconstructions, while lowering computational cost. Our model shows potential to achieve fast, high resolution online image reconstructions.Acknowledgements
No acknowledgement found.References
[1] Lustig, M., Donoho, D. L., Santos, J. M., & Pauly, J. M. (2008). Compressed sensing MRI. IEEE signal processing magazine, 25(2), 72-82.
[2] Menchón-Lara, R. M., Simmross-Wattenberg, F., Casaseca-de-la-Higuera, P., Martín-Fernández, M., & Alberola-López, C. (2019). Reconstruction techniques for cardiac cine MRI. Insights into imaging, 10, 1-16.
[3] Bustin, A., Fuin, N., Botnar, R. M., & Prieto, C. (2020). From compressed-sensing to artificial intelligence-based cardiac MRI reconstruction. Frontiers in cardiovascular medicine, 7, 17.
[4]Oscanoa, J. A., Middione, M. J., Alkan, C., Yurt, M., Loecher, M., Vasanawala, S. S., & Ennis, D. B. (2023). Deep learning-based reconstruction for cardiac MRI: A Review. Bioengineering, 10(3), 334.
[5] Zhao, H., Gallo, O., Frosio, I., & Kautz, J. (2016). Loss functions for image restoration with neural networks. IEEE Transactions on computational imaging, 3(1), 47-57.
[6] Mustafa, A., Mikhailiuk, A., Iliescu, D. A., Babbar, V., & Mantiuk, R. K. (2022). Training a task-specific image reconstruction loss. In Proceedings of the IEEE/CVF winter conference on applications of computer vision (pp. 2319-2328).
[7] Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 (pp. 234-241). Springer International Publishing.
[8] Jiang, L., Dai, B., Wu, W., & Loy, C. C. (2021). Focal frequency loss for image reconstruction and synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 13919-13929).
[9] Devnani, A., & Rawat, C. D. (2016, December). Comparative analysis of image quality measures. In 2016 International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC) (pp. 353-357). IEEE.
[10] Nguyen, C. T., Christodoulou, A. G., Coll‐Font, J., Ma, S., Xie, Y., Reese, T. G., ... & Li, D. (2021). Free‐breathing diffusion tensor MRI of the whole left ventricle using second‐order motion compensation and multitasking respiratory motion correction. Magnetic resonance in medicine, 85(5), 2634-2648.
Figures
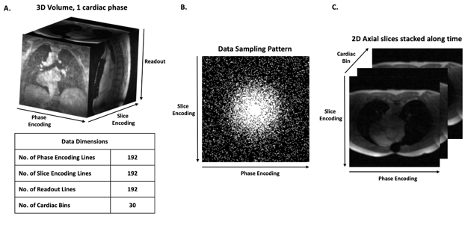
Figure 1: A. 4D cardiac MRI data dimensions. B. Example sampling pattern within a single 2D axial slice used to acquire the data. C. Data reshaped and stacked for DL network training.
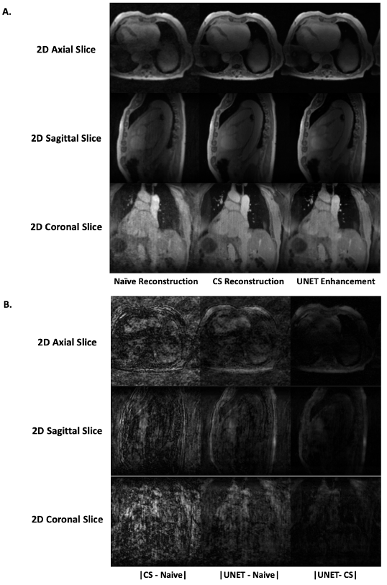
Figure 2: A. UNET-based image enhancement results compared alongside CS reconstruction results and the naïve image reconstruction. B. Difference maps comparing the absolute differences of CS reconstruction and UNET enhancement with respect to the naïve reconstruction.
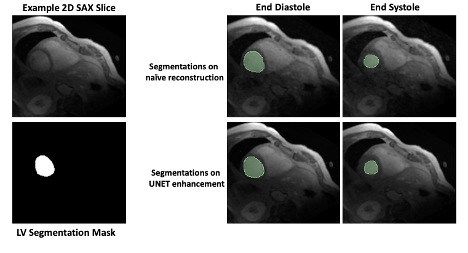
Figure 3: Left ventricle (LV) segmentations of end diastole and end systole phase overlayed on corresponding 2D SAX slice for one representative example.
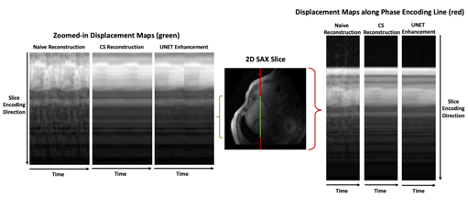
Figure 4: Displacement maps showing the cardiac motion over 30 time points in a single phase encoding line.