4487
Movieformer: Motion-resolved 4D MRI reconstruction using a network with spatiotemporal attention1Department of Medical Physics, Memorial Sloan Kettering Cancer Center, New York, NY, United States, 2Department of Radiology, Memorial Sloan Kettering Cancer Center, New York, NY, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: Investigate utility of self-attention deep learning to exploit global temporal information in motion-resolved 4D MR imaging.
Goal(s): Design a novel hybrid convolutional-attention network to reconstruct motion-resolved 4D images without explicit k-space data consistency.
Approach: A hybrid Unet-style 4D reconstruction network was developed to incorporate windowed multiscale spatiotemporal multihead self-attention. Training and testing were performed on free-breathing data acquired on patients with abdominal tumors.
Results: Spatiotemporal attention successfully captured motion in multiple dimensions with improved image quality relative to state-of-the-art XD-GRASP reconstruction.
Impact: Self-attention deep learning mechanism can combine long-range spatial learning and global temporal learning to augment capabilities of convolutional networks for improved motion-resolved 4D MRI of mobile tumors.
Introduction
Motion-resolved 4D MRI can capture a variety of anatomical motion, enabling evaluation of cardiac/respiratory function1,2 and personalized radiotherapy of mobile tumors3,4. Several deep learning-based reconstruction networks have been developed to increase performance of 4D MRI, usually employing k-space data consistency5,6. Movienet7 is a recent model that instead exploits motion consistency to significantly reduce reconstruction time. However, previous work only used purely convolutional neural networks (CNNs), and therefore were unable to integrate long-range or even potentially global information. Vision transformers8,9 create data-adaptive filters with long-range receptive fields of view due to their use of the highly influential self-attention mechanism. Uformer is a Unet-style natural-image restoration network that demonstrated ability of a purely attention-based network to remove several types of image artifacts10. Dynamic MRI forms a natural application of this general framework as long-range spatial neighborhoods across temporal dimensions offer a twofold increase in information for the network to process. This work proposes Movieformer, a novel deep learning model that combines Movienet efficiency and multiscale spatiotemporal self-attention to reconstruct undersampled 4D MRI. Movieformer is tested on patients with abdominal tumors.Methods
Movieformer architecture: Movienet employs an encoder-decoder architecture with added residual shortcut blocks that enhance feature extraction in both downsampling and upsampling branches (Fig 2a). Locally-enhanced Window (LeWin) Transformer blocks, which serve as the basis of Uformer, perform multihead self-attention within small, nonoverlapping windows to limit self-attention’s quadratic computational complexity. Since transformer blocks vectorize data, local context that is paramount in image processing is not fully leveraged. LeWin blocks incorporate a 3x3 depthwise convolution in between fully-connected layers to encode 2D local information (Fig 2b,c). Movieformer combines these two and utilizes adapted residual blocks with a series of 3 LeWin blocks with window size = 8x8 at multiple internal feature resolutions.Data acquisition and motion sorting: 18 adults with abdominal cancer were scanned on different 3T scanners (MR750 and Premier, GE Healthcare) using a continuous radial golden-angle stack-of-stars acquisition with the following scan parameters: TR/TE = 3-4/1.5-2 ms, flip angle = 12°, in-plane resolution = 1.25x1.25 – 1.5x1.5 mm2, slice thickness = 4-5 mm, 1800 spokes (acquisition time = 4.5 min). k-space data were binned into 10 motion states using the respiratory motion signal estimated via PCA of the 1D IFFT of the central kx-ky position for each kz (as in the XD-GRASP technique11). 16 patients were used to train the network and 2 patients were employed for testing against XD-GRASP reconstruction.
Movieformer training: Movieformer was trained to perform slice-by-slice reconstruction on the axial orientation where the input was an aliased multicoil motion-resolved slice using 900 spokes and the reference for training was XD-GRASP reconstruction using 1,800 spokes, which represented a 2-fold acquisition acceleration. A smooth L1 loss and Adam optimizer with initial learning rate = 1e-4 were used.
Results
Even though trained only on axial slices, Movieformer accurately captured motion in the coronal and sagittal planes (Figures 3-4). In the patient with a cyst in the right kidney, Movieformer reduced streaking artifacts compared to XD-GRASP without compromising motion imaging (Figure 3). In the patient with multiple metastatic lesions in the liver, Movieformer improved motion visualization along the lower-resolution z-dimension presenting sharper structures in the coronal and sagittal planes.Discussion
Combining transformer blocks with a CNN into a hybrid reconstruction network successfully removed aliasing artifacts and preserved anatomical deformation in motion-resolved 4D MRI. Pure transformers typically require extremely large datasets to account for their lack of visual inductive bias8, so creating a model that alternates between convolutional and transformer layers can allow those transformer layers to process features that preserve 2D information, potentially minimizing acceptable training dataset sizes. Convolutions and attention have also been shown to be complementary functions (high-pass filters and low-pass filters, respectively)12, which further justifies their combination.Conclusion
Movieformer offers initial evidence that transformers can be leveraged for motion-resolved 4D MRI. Integration of large spatial and global temporal receptive fields of view can further increase capability of deep learning reconstruction methods to achieve diagnostic fidelity on higher acceleration factors and with larger amounts of more finely resolved motion states.Acknowledgements
This work was supported by NIH grants R01-244532 and R01-255661References
[1] Coppo S, Piccini D, Bonanno G, et al. Free-running 4D whole-heart self-navigated golden angle MRI: initial results. Magn Reson Med. 2015;74:1306-1316. doi:10.1002/mrm.25523
[2] Feng L, Delacoste J, Smith D, et al. Simultaneous evaluation of lung anatomy and ventilation using 4D respiratory-motion-resolved ultrashort echo time sparse MRI. J Magn Reson Imaging. 2019;49:411-422. doi:10.1002/jmri.26245
[3] Stemkens B, Paulson ES, Tijssen RHN. Nuts and bolts of 4D-MRI for radiotherapy. Phys Med Biol. 2018;63:21TR01. doi:10.1088/1361-6560/aae56d
[4] Otazo R, Lambin P, Pignol JP, et al. MRI-guided radiationtherapy: an emerging paradigm in adaptive radiation oncology. Radiology. 2021;298:248-260. doi:10.1148/radiol.2020202747
[5] Küstner T, Fuin N, Hammernik K, et al. CINENet: deeplearning-based 3D cardiac CINE MRI reconstruction with multi-coil complex-valued 4D spatio-temporal convolutions. SciRep. 2020;10:13710. doi:10.1038/s41598-020-70551-8
[6] Freedman JN, Gurney-Champion OJ, Nill S, et al. Rapid 4D-MRI reconstruction using a deep radial convolutional neural network: Dracula. Radiother Oncol. 2021;159:209-217. doi:10.1016/j.radonc.2021.03.034
[7] Murray V, Siddiq S, Crane C, et al. Movienet: Deep space–time-coil reconstruction network without k-space data consistency for fast motion-resolved 4D MRI. MagnReson Med. 2023;1-15. doi: 10.1002/mrm.29892
[8] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale. arXiv:201011929 [cs]
[9] Liu Z, Lin Y, Cao Y, et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:210314030 [cs]
[10] Wang Z, Cun X, Bao J, Zhou W, Liu J, Li H. Uformer: a general U-shaped transformer for image restoration. arXiv:210603106 [cs]
[11] Feng L, Axel L, Chandarana H, Block KT, Sodickson DK, Otazo R. XD-GRASP: golden-angle radial MRI with reconstruction of extra motion state dimensions using compressed sensing. Magn Reson Med. 2016;75:775-788. doi:10.1002/mrm.25665
[12] Park N, Kim S. How Do Vision Transformers Work? arXiv:220206709 [cs]
Figures
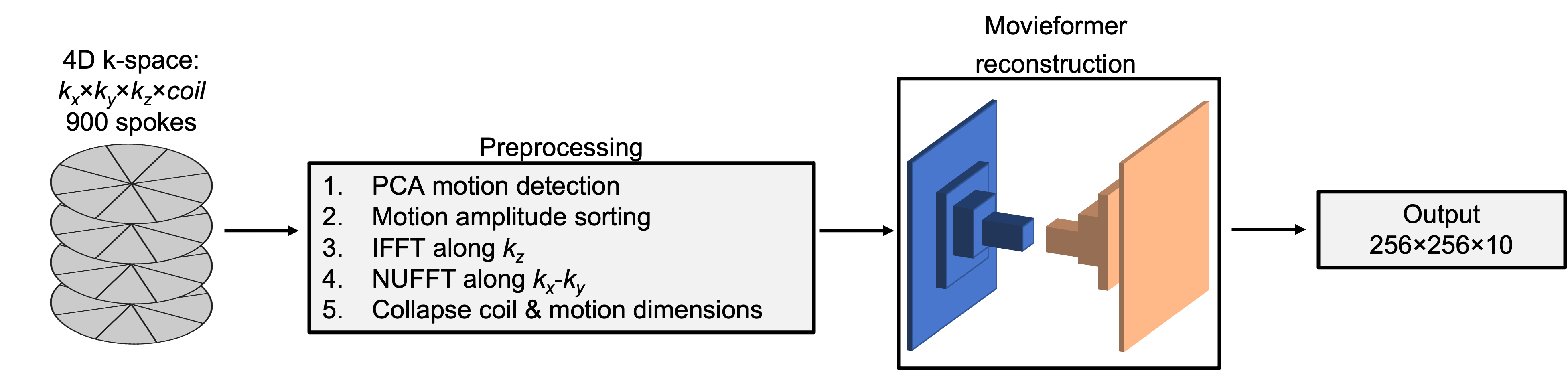
Figure 1: Overall workflow. Continuous radial golden-angle stack-of-stars acquisitions are transformed into 10 aliased motion-resolved images and reconstructed by the network. The coil and motion state dimensions are combined to let the network learn spatiotemporal features. Movieformer is inspired by the Unet style of Movienet with windowed transformer blocks added at every internal resolution. The input to the network uses 900 spokes and the reference for training uses 1,800 spokes, resulting in 2-fold acceleration
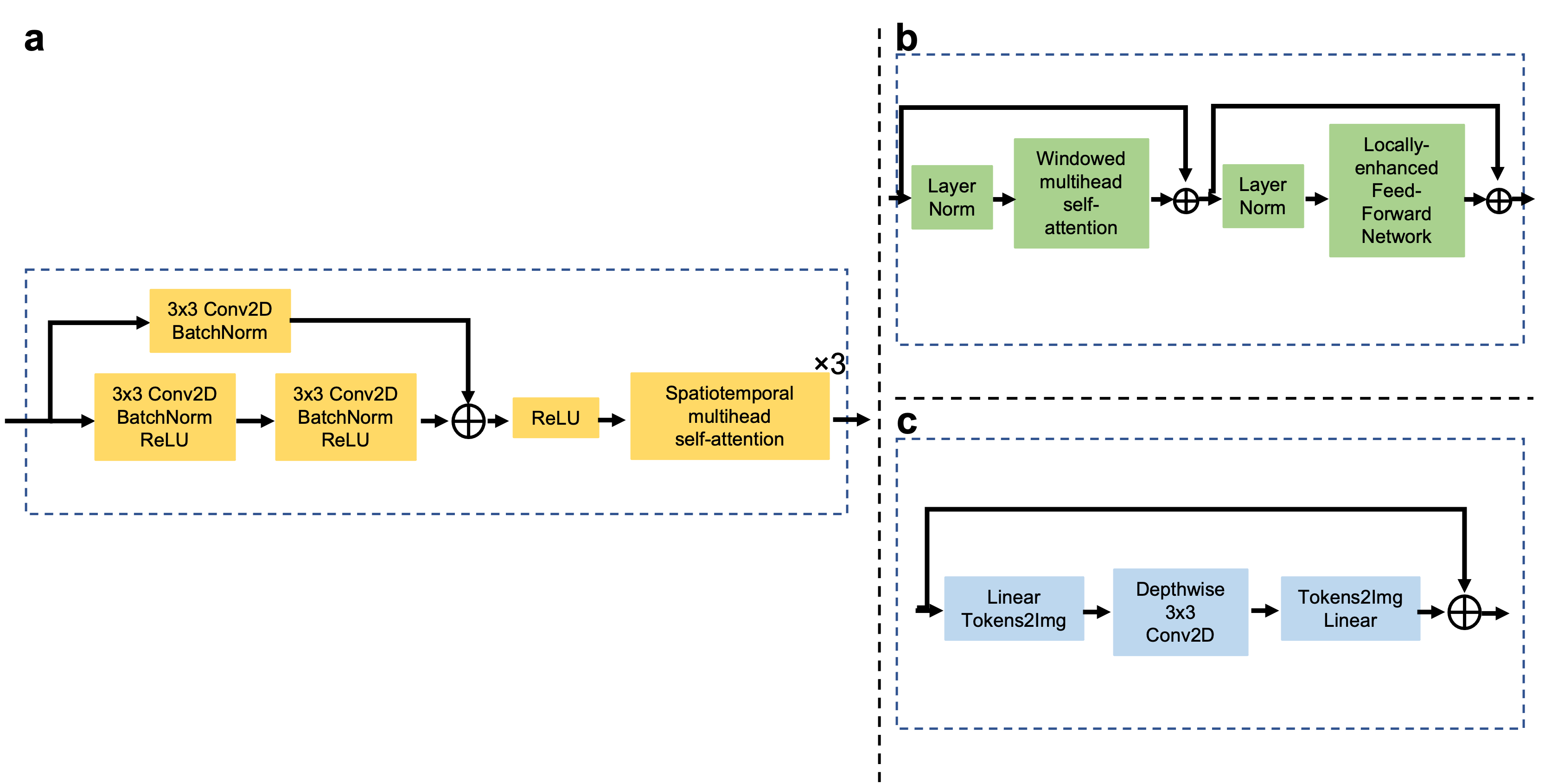
Figure 2: Movieformer architecture. (a) Modified Movienet Adapted Residual Block that processes data in 2 concurrent streams whose combination serve as input to a series of LeWin transformer blocks. These blocks increase the spatial receptive field of view across all temporal frames. (b) Details of LeWin transformer blocks which perform multihead self-attention in small nonoverlapping windows. (c) Uformer’s Locally-enhanced Feed-Forward Network (LeFF) retains 2D locality in attention-based features.
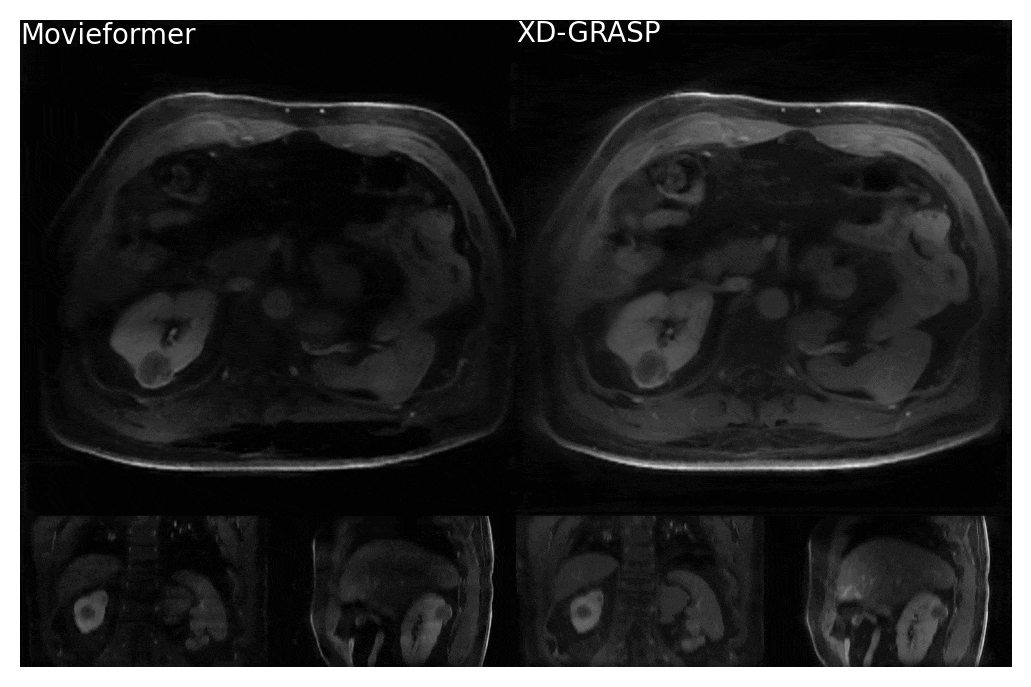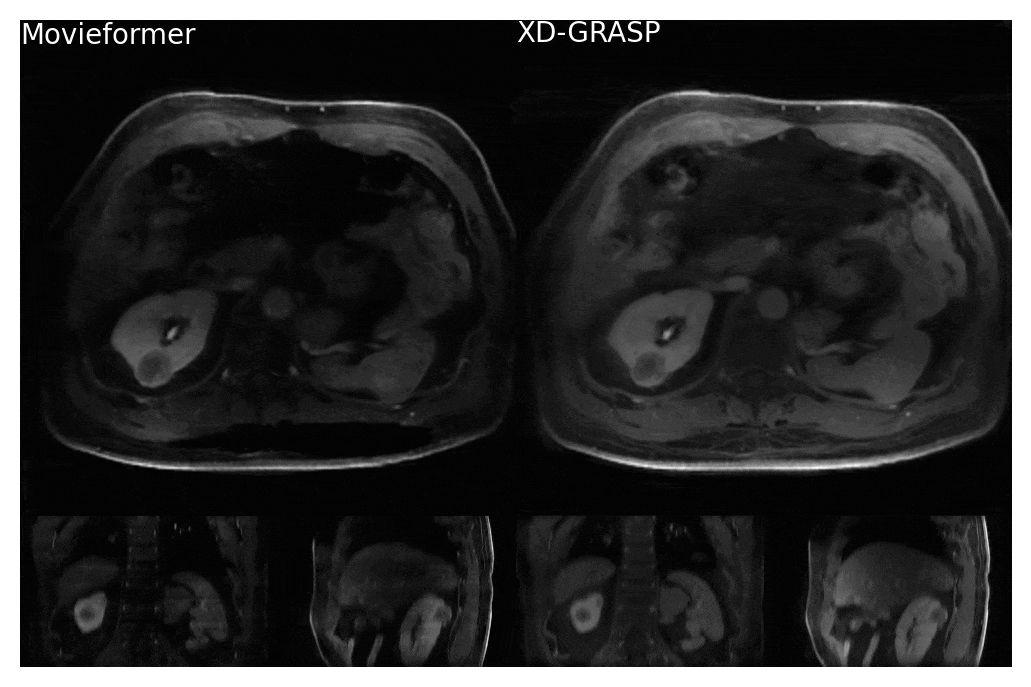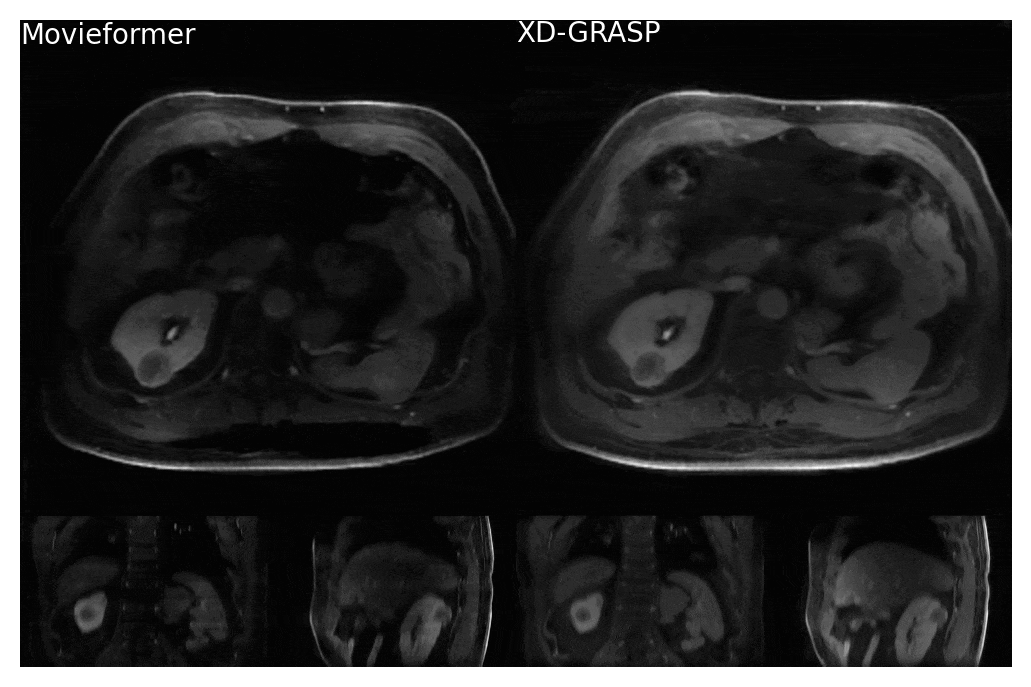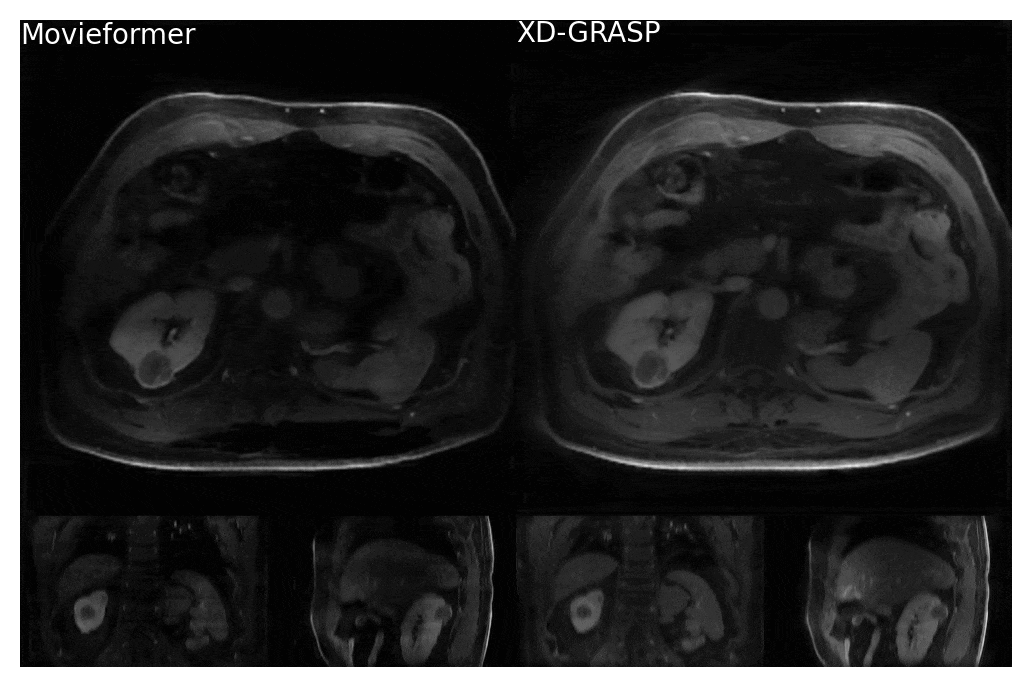
Figure 3: Comparison of Movieformer reconstruction against reference XD-GRASP reconstruction for a patient with a kidney cyst. Network is trained on 2D+motion axial slices and is still able to resolve 3D motion. Movieformer presents reduced streaking artifacts while preserving motion with respect to XD-GRASP.
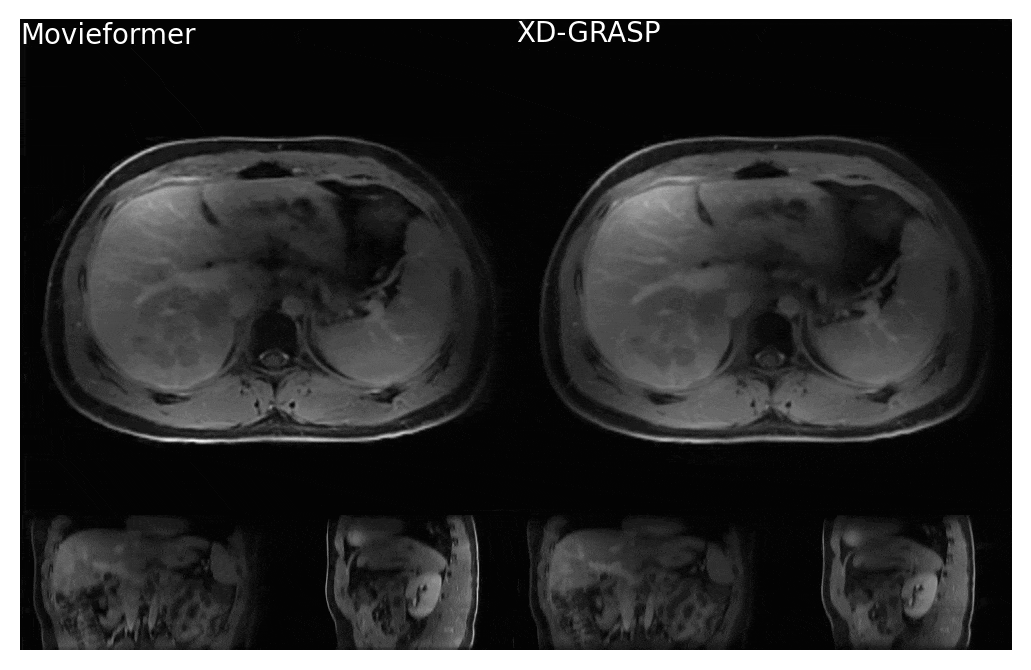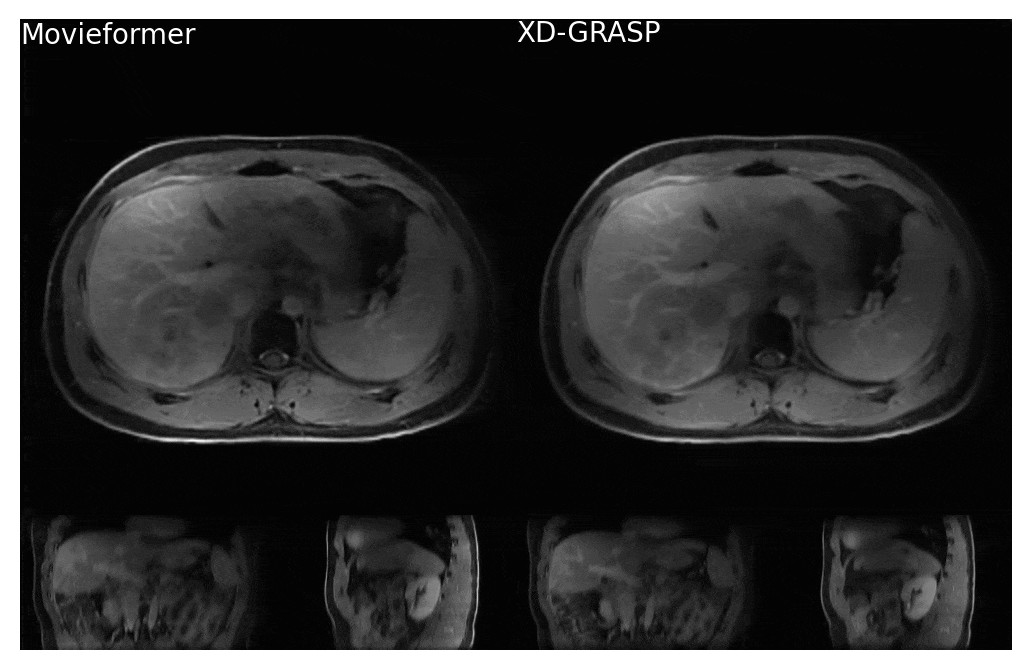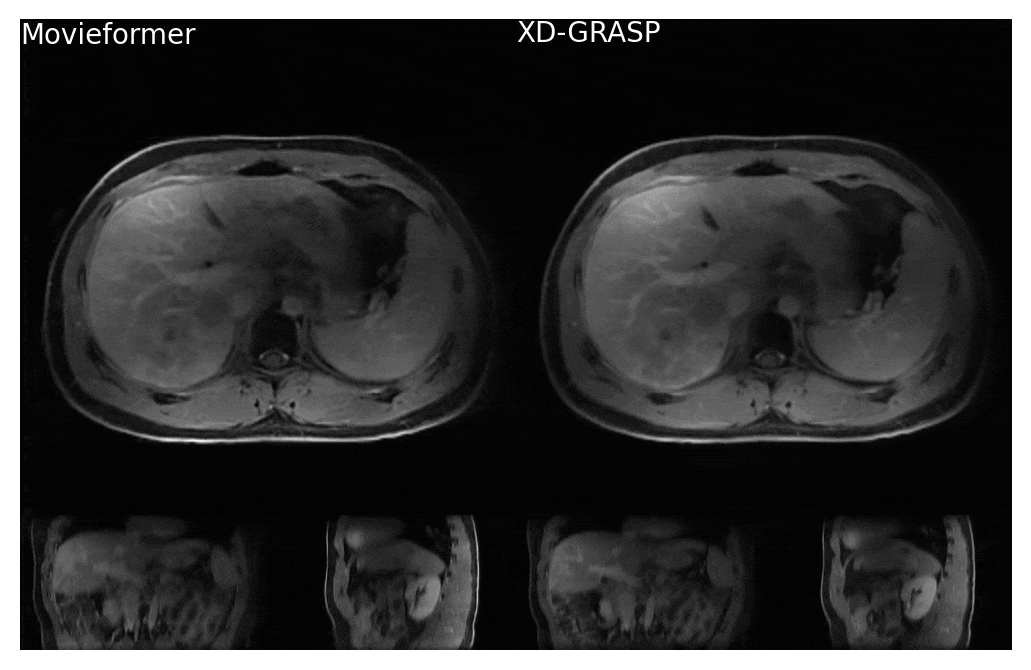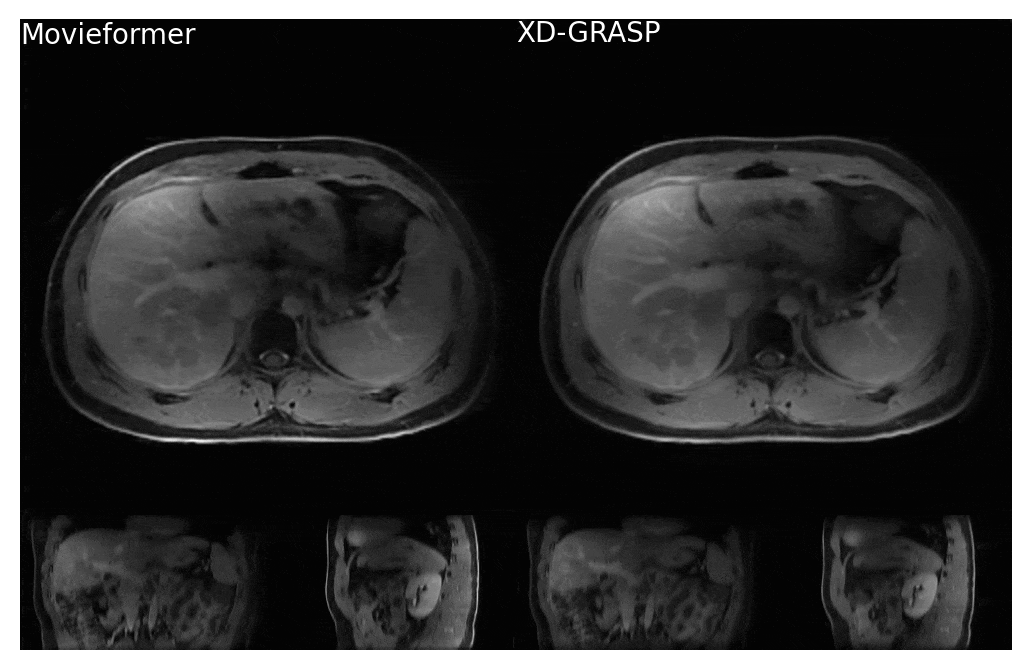
Figure 4: Comparison of Movieformer reconstruction against reference XD-GRASP reconstruction for patient with liver metastasis. Movieformer presents improved motion visualization in the sagittal and coronal planes with respect to XD-GRASP.