4486
Temporally-Aware Neural Networks For Cine MRI Reconstruction From Severely Undersampled Data1Department of Computer Science, University of California San Diego, La Jolla, CA, United States, 2Department of Bioengineering, University of California San Diego, La Jolla, CA, United States, 3Rady's Children Hospital, San Diego, San Diego, CA, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: MRI guidance of an interventional procedure requires fast image reconstruction. A neural network(NN)-based approach can exploit the similarities between consecutive frames to improve iMRI image reconstruction.
Goal(s): We investigate if an LSTM can reconstruct images from just ten spokes per frame in a timeframe compatible with iMRI.
Approach: A convolutional (conv)LSTM was trained using the open-source ACDC dataset. Results were compared with Multi-domain convolutional neural network (MD-CNN) - a recently-published 3D NN-based method for undersampled MRI reconstruction.
Results: ConvLSTMs can reconstruct frames at ~226 fps (17x faster than MD-CNN ~13 fps). SSIM for the convLSTM was slightly lower than the MD-CNN (0.85 vs 0.89).
Impact: With our LSTM-based model, we have achieved a 17x speed-up in the iMRI acquisition process without significant loss in image quality. This suggests that an LSTM-based method could be used to improve iMRI image speed and quality.
Introduction
Interventional MRI (iMRI) requires both fast image acquisition and display. This limits the number of samples available for reconstruction and also limits the computational complexity of the reconstruction process. However, iMRI imaging generates a time series with high temporal similarity. We aim to exploit this feature by using a temporally aware deep learning-based approach.Recent work by El-Rewaidy et al. showed that a multi-domain convolutional neural network (MD-CNN)[1] can reconstruct high-quality images from highly undersampled radial k-space data. However, Long Short-Term Memory (LSTM) networks are better for inferences based on time-series[2,3] as they intrinsically exploit temporal information and have a special memory unit that remembers long-term patterns and simultaneously forgets unimportant information. However, they can be more difficult to train.
In this work, we sought to test whether a convolutional-LSTM (convLSTM)--based [4] framework could quickly and accurately perform time-series forecasting on the iMRI sequence.
Method
Architecture
The MD-CNN architecture (Figure 1a) takes a sliding window of time-frames as input and reconstructs the central frame of the window, using the data from neighbouring frames. MD-CNN employs two different convolutional subnetworks. The first subnetwork operates on undersampled gridded k-space data. An inverse FFT (IFFT) operation transforms the data to the image domain, onto which a second subnetwork is applied. The architecture has 3D complex convolutional layers[6] and activations for k-space data.
In this work, we propose a 3-component convLSTM architecture (Figure 1b). We kept the IFFT operation and made the following modifications to the two subnetworks.
First, the k-space subnetwork was converted into a 2D convLSTM that interpolates missing k-space data in a coil-wise fashion. This reduced the FLoating-point OPerations (FLOPs) of the k-space subnetwork 38x from 140.9B (billion) to 3.7B.
Second, the image space subnetwork was streamlined to only include a Unet[7] (and remove two 3D convolutional layers), which reduced FLOPs from 12.4B to 8.5B.
The convLSTM was trained with intermediate supervision on the individual components. In addition to the final target image loss, we supervised using a k-space loss and an image loss immediately after the IFFT (before the image space UNet). The model was trained for 1000 epochs using an Adam optimiser and a Cyclic LR Scheduler with limits (1e-4,8e-5).
Dataset
The open-source Automated Cardiac Diagnosis Challenge (ACDC)[5] dataset consists of cine MR images from 150 patients, typically at ten different slice locations acquired during breath-holds. This dataset was used for simulated radial imaging, with 120 patients for training and 30 for testing.
All images were undersampled using the NUFFT. Ten golden-angle radial spokes per-frame of k-space were extracted to generate a time-series of undersampled k-space data. Receiver coils were simulated by multiplying the images with Gaussian masks (Figure 2). This generated a multi-coil k-space time-series, which was passed to both MD-CNN and conv-LSTM for reconstruction.
Image Quality Assessment
Image quality of the reconstructions was assessed using the Root Mean Squared Error (RMSE) and Structural Similarity Index (SSIM). Two-tailed paired t-tests were used to compare the image quality metrics of images generated with MD-CNN and convLSTM reconstructions. For this, the 15th cardiac bin and 5th slice per patient was used.
Results
The ability of a convLSTM to share data across time is shown in Figure 3. MD-CNN takes 77 ± 3 milliseconds to reconstruct a frame (~13 FPS). The convLSTM method was 17 times faster (4 ± 0.2 ms per frame, ~226 FPS).Figure 4 shows representative images reconstructed by both methods. Across the cohort, the average SSIM of MD-CNN was (p < 0.05, 0.89 ± 0.03 higher) than that of convLSTMs (0.85 ± 0.04, Figure 5). Similarly, the RMSE of MD-CNN was lower (0.034 ± 0.008, p<0.05) compared to convLSTM (0.046 ± 0.007) with the RMSE.
Discussion and Conclusions
An LSTM-based approach enabled fast (>200 fps) image reconstruction from severely undersampled data. In addition to the fast compute time, the LSTM network eliminates the need for a user-defined hyperparameter to govern the extent of temporal information to be shared. Lastly, the use of 2D convolution makes the approach memory efficient and could be leveraged to analyse several slices in parallel for simultaneous multi-slice imaging applications.Despite the LSTM-based method yielding relatively high SSIM values for the level of radial undersampling, SSIM values for the MD-CNN were higher. One potential cause of this difference is that the image-space subnetwork in the MD-CNN has access to multiple frames, while our UNet-based image-space subnetwork analyses each frame independently. Analysing multiple frames or converting this subnetwork into another LSTM could further improve our image reconstruction. Moreover, an LSTM-based image subnetwork would also further accelerate the reconstruction.
Acknowledgements
Supported by NIH R01HL162671References
El-Rewaidy H, Fahmy AS, Pashakhanloo F, Cai X, Kucukseymen S, Csecs I, Neisius U, Haji-Valizadeh H, Menze B, Nezafat R. Multi-domain convolutional neural network (MD-CNN) for radial reconstruction of dynamic cardiac MRI. Magn Reson Med. 2021 Mar;85(3):1195-1208. doi: 10.1002/mrm.28485. Epub 2020 Sep 13. PMID: 32924188.
Wenjie Lu, Jiazheng Li, Yifan Li, Aijun Sun, Jingyang Wang, and Abd E. I.-Baset Hassanien. 2020. A CNN-LSTM-Based Model to Forecast Stock Prices. Complex. 2020 (2020). https://doi.org/10.1155/2020/6622927
Yu Chen, Ruixin Fang, Ting Liang, Zongyu Sha, Shicheng Li, Yugen Yi, Wei Zhou, Huilin Song, and Yi-Zhang Jiang. 2021. Stock Price Forecast Based on CNN-BiLSTM-ECA Model. Sci. Program. 2021 (2021). https://doi.org/10.1155/2021/2446543
Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-kin Wong, and Wang-chun Woo. 2015. Convolutional LSTM Network: a machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1 (NIPS'15). MIT Press, Cambridge, MA, USA, 802–810.
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, et al. "Deep Learning Techniques for Automatic MRI Cardiac Multi-structures Segmentation and Diagnosis: Is the Problem Solved ?" in IEEE Transactions on Medical Imaging, vol. 37, no. 11, pp. 2514-2525, Nov. 2018 doi: 10.1109/TMI.2018.2837502
El-Rewaidy H, Neisius U, Mancio J, et al. Deep complex convolutional network for fast reconstruction of 3D late gadolinium enhancement cardiac MRI. NMR Biomed. 2020:e4312
Ronneberger, O., Fischer, P., Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab, N., Hornegger, J., Wells, W., Frangi, A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science(), vol 9351. Springer, Cham. https://doi.org/10.1007/978-3-319-24574-4_28
Figures
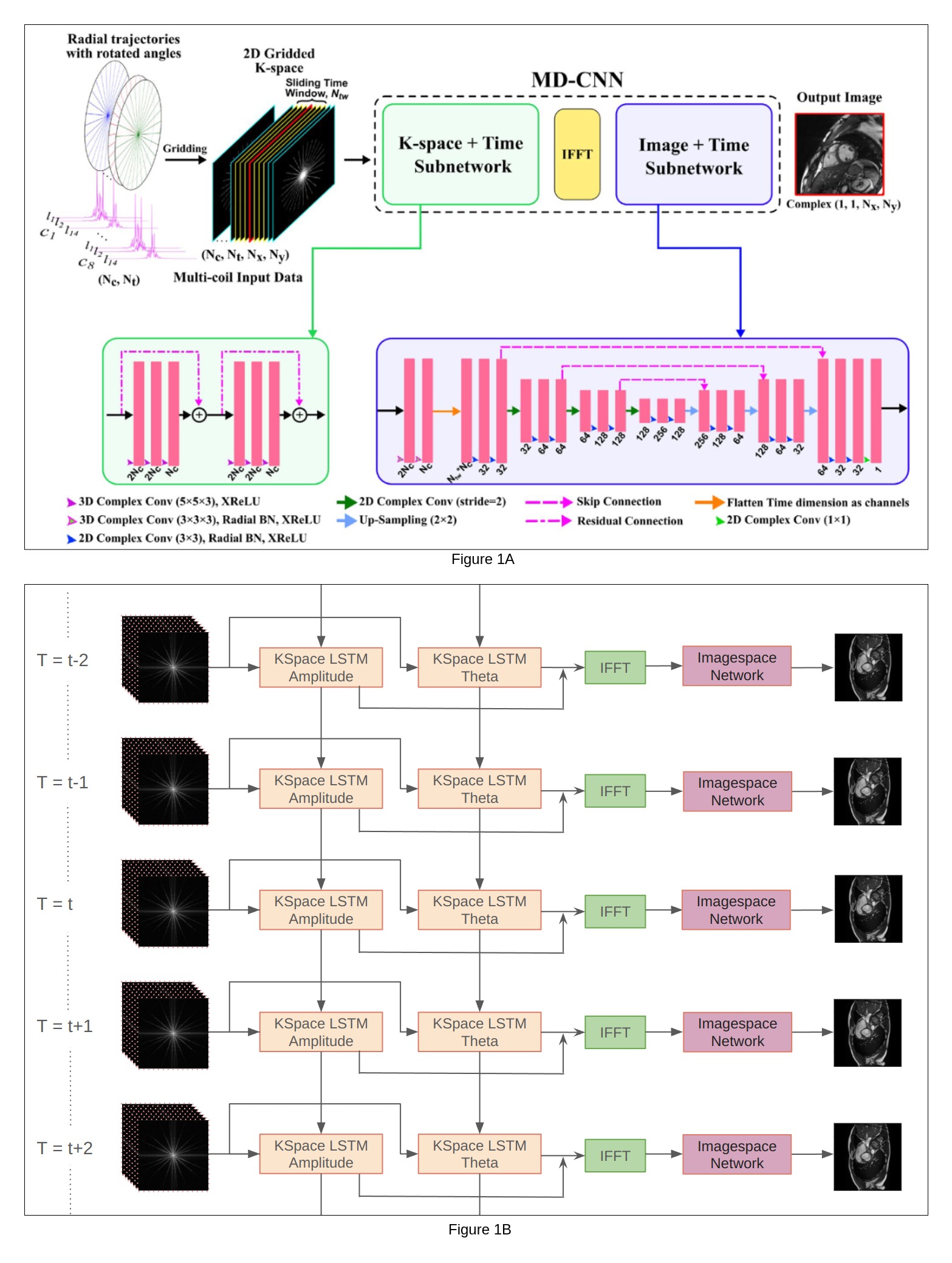
Fig 1a: MD-CNN Architecture[1]. The input has (Nc*Nw) frames where Nc is the number of coils, Nw is the size of the sliding window. The model predicts the centre frame of this window. Fig 1b: Diagram of the proposed architecture. At every time T Nc frames are taken as input. The KSpace Network has two LSTMs for amplitude and theta. Amplitude and theta can represent any complex number. LSTMs exploit temporal similarities between successive frames to fill in missing k-space data. This is followed by an IFFT and the ImageSpace UNet that performs artefact removal and image enhancement.
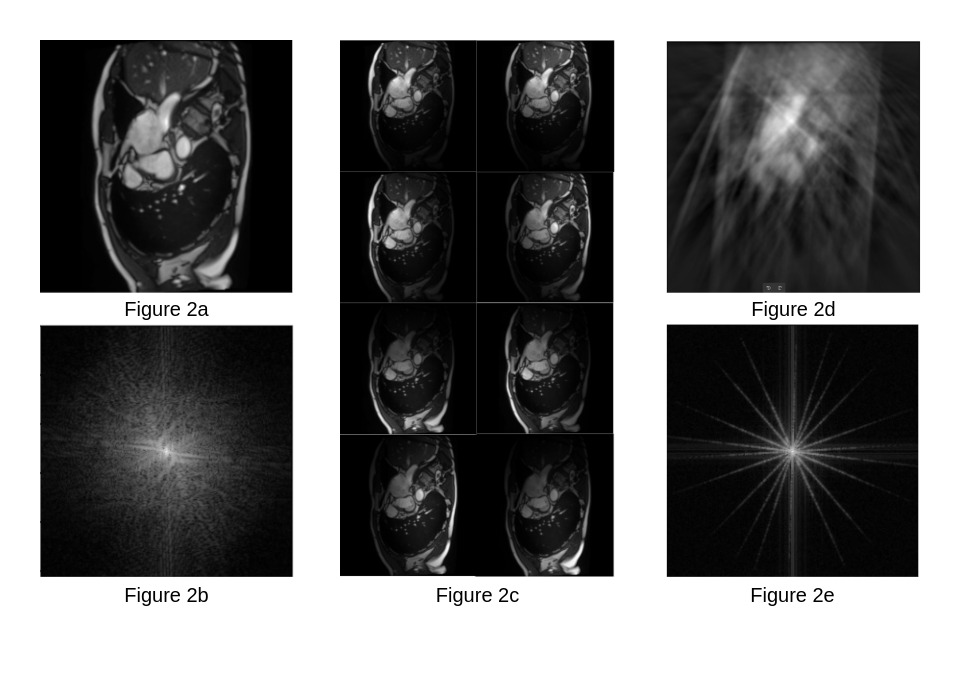
Fig 2a,2b: Ground truth cine MRI frame from the ACDC[5] dataset - image (top) and k-space (bottom).
Fig 2c: Images of simulated coils by multiplying the input frame with moving Gaussian blur masks. This is used as the ground truth for the images predicted by the k-space model.
Fig 2d,2e: (bottom) Undersampled Fourier transform computed using NUFFT. The spokes are chosen at Golden Angle intervals. This undersampled k-space data is the input to the convLSTM. We have also shown the inverse FFT (top) of this undersampled data to show how the reconstruction looks at such a severe undersampling.
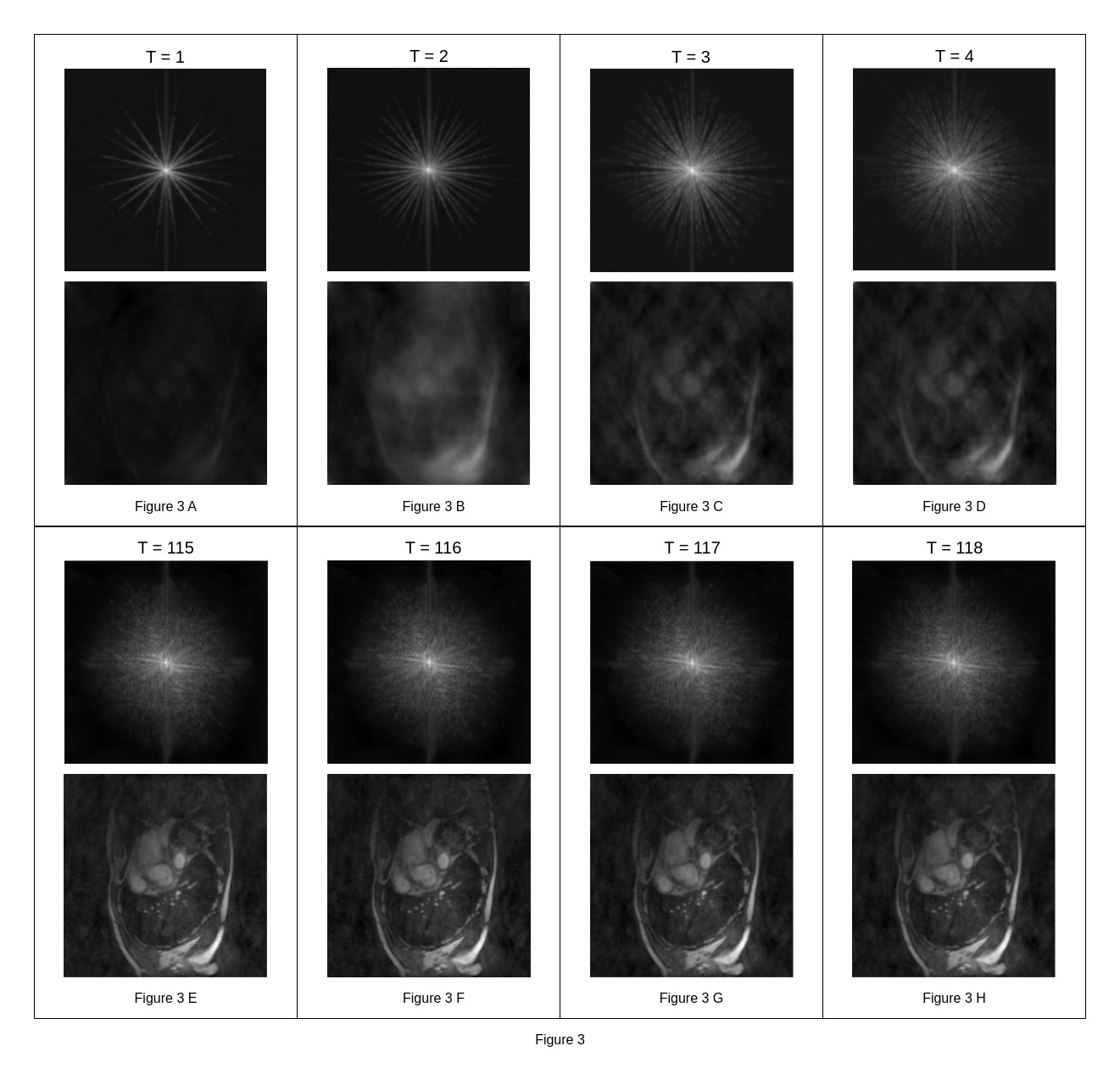
Representative images generated by the k-space subnetwork. The convLSTM generates images for all the coils, but just one coil is shown. Each pair of images corresponds to a different time frame. t=1 implies the first frame generated. Fig (A-D) The first frame is very similar to the 10-spoke input. But as more frames are passed to the LSTM network, it remembers information, and we can observe spokes being added to the Fourier transform. Fig (E-H) These images are much better quality since they are generated after the LSTM has processed several frames and has reached a steady state.
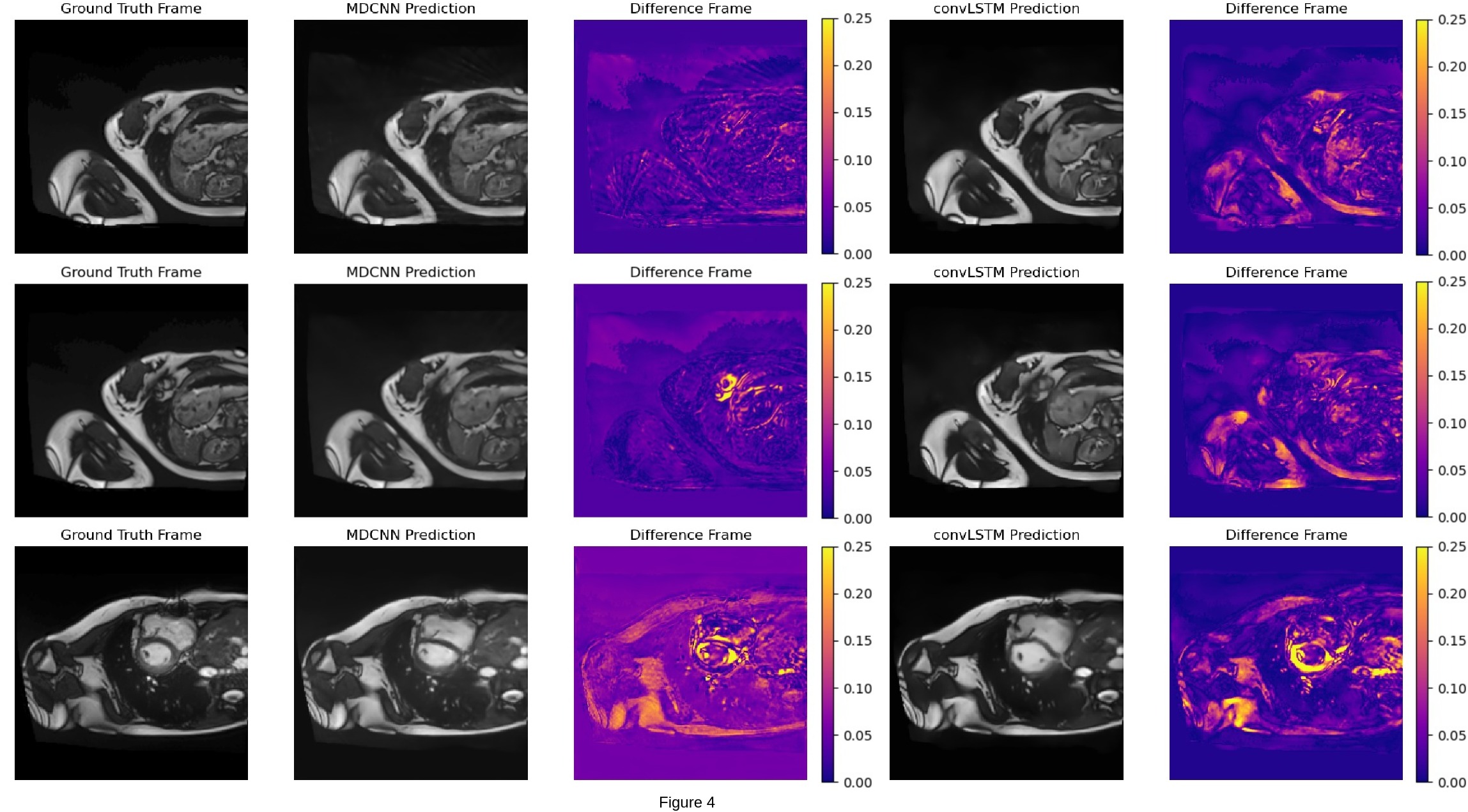
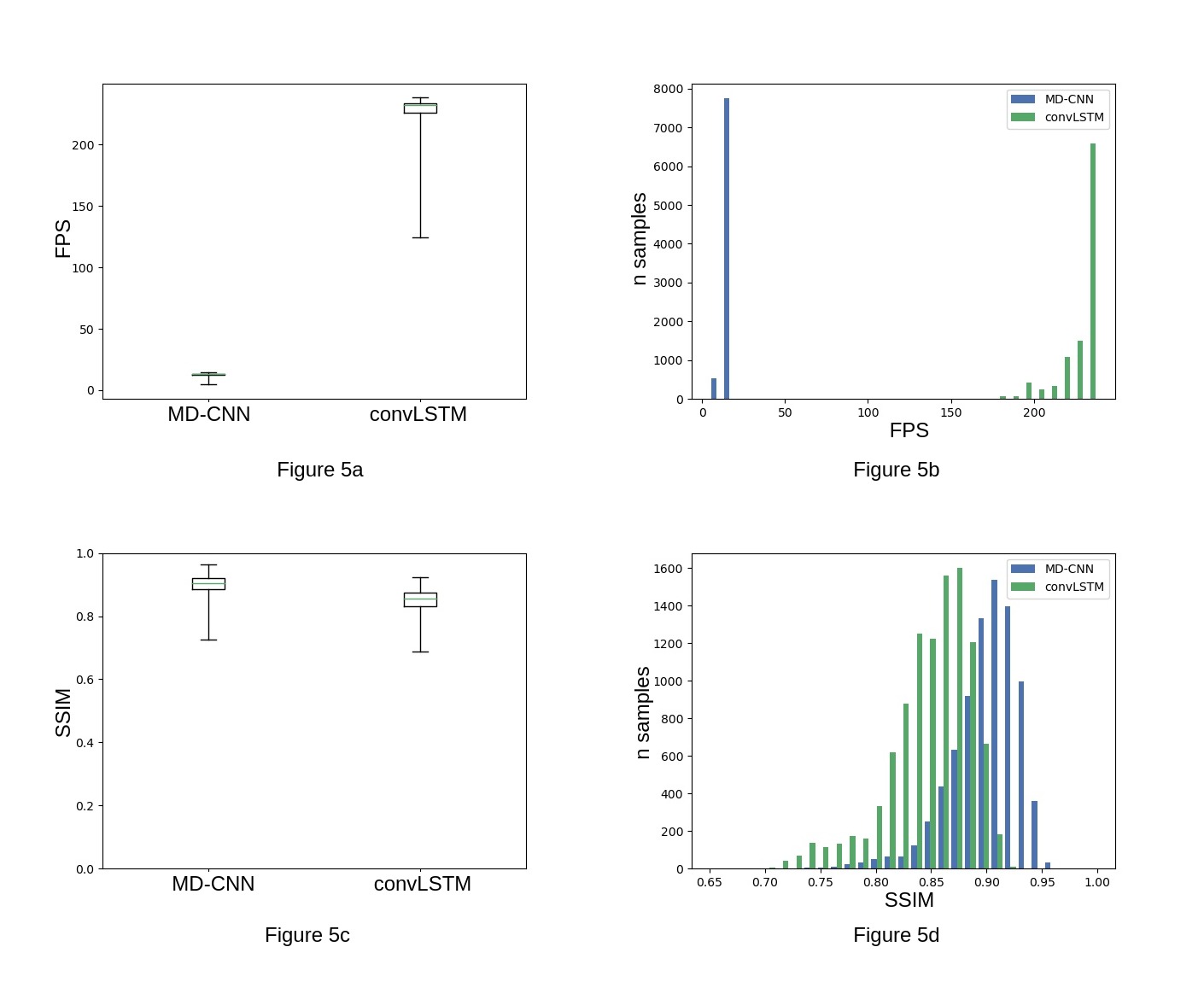
Fig 5a,5b: Boxplot and histogram of the Frames per Second (FPS) obtained by both methods. convLSTM reconstructs images at ~226 FPS, whereas MD-CNN has a 13 FPS.
Fig 5c, 5d: Boxplot and histogram of the SSIM scores obtained using MD-CNN (blue) and convLSTM(green). The distribution of MD-CNN SSIM scores has a higher peak than the convLSTM scores. This implies that the convLSTM has an overall worse reconstruction quality than the MD-CNN at the benefit of a 17x faster speed