4270
Implementing Deep learning MRI reconstruction on a RISC-V Hardware Accelerator1Radiology and Biomedical Imaging, University of California, San Francisco, San Francisco, CA, United States, 2Electrical Engineering and Computer Science, University of California, Berkeley, Berkeley, CA, United States
Synopsis
Keywords: Image Reconstruction, Image Reconstruction
Motivation: Deep Learning MRI reconstruction requires access to high-performance compute hardware (GPUs) but reconstruction times can still remain slow.
Goal(s): Use domain specific hardware accelerators to speed up deep learning MRI reconstruction compared to classic CPU/GPU implementations.
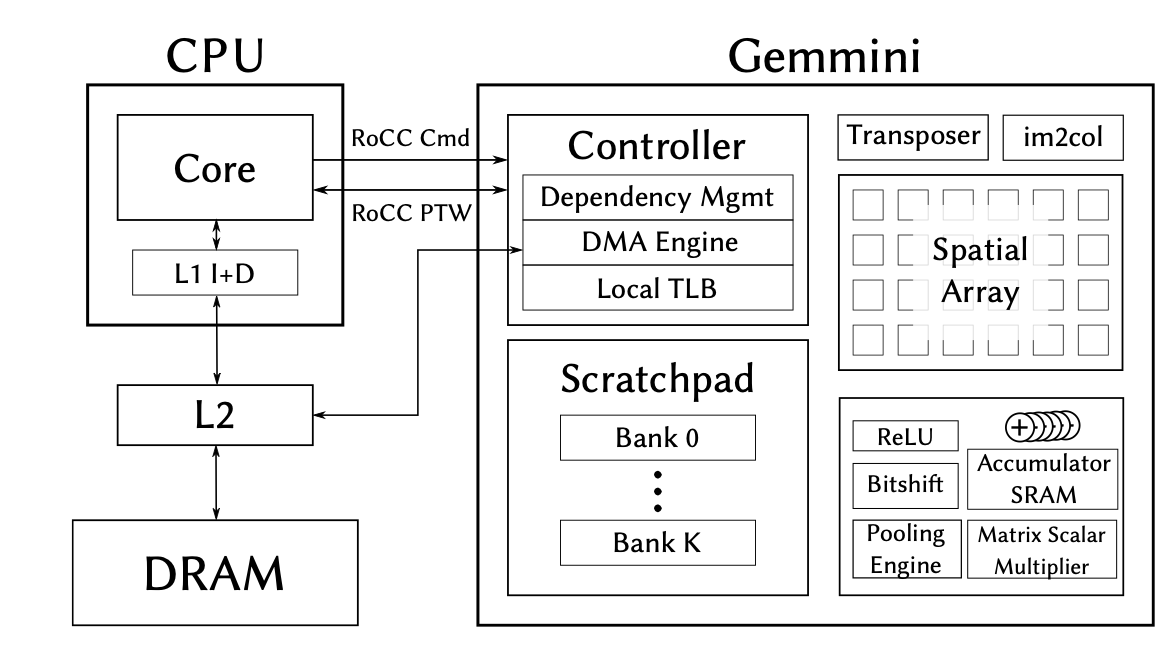
Approach: We use an open source SoC design and simulation framework, Chipyard, and a neural network accelerator, Gemmini, to run inference on a pretrained MRI reconstruction network. The results are measured on FireSim, an FPGA simulation framework.
Results: Simulated inference times of pretrained models on Gemmini are much faster compared to CPU and show similar image quality metrics compared to the inference run on a GPU.
Impact: Shows the potential of developing custom compute hardware designed to accelerate deep learning MRI reconstruction.
Introduction
Deep learning MRI reconstruction methods have shown utility successfully speeding up MRI reconstruction inresearch settings, however adapting them to clinical settings still faces many challenges. Most new MRI systems that are delivered to hospitals, clinics, and outpatient settings do not include access to high-performance compute systems (e.g GPUs) for implementing deep learning based reconstruction techniques for real time use. With the slowing of Moore’s law, there is a recent trend to develop specialized hardware to accelerate different tasks particularly deep learning (e.g. Google's TPU, Apple Neural Engine).However prototyping and designing hardware for different types of algorithms escalates development costs. Chipyard1 is an open-source integrated system-on-chip design, simulation, and implementation environment for specialized compute systems allowing for rapid hardware prototyping. Here, we demonstrate the deep learning MRI reconstruction network, AUTOMAP2 running inference on a RISC-V3 hardware accelerator using Gemmini4 a neural network accelerator implemented in the Chipyard framework. We simulate this implementation using FireSim5 an open-source platform that enables cycle-accurate FPGA simulations. Previous work in this area has focused on more classic image reconstruction approaches including parallel imaging6 , compressed sensing7 and optimization algorithms8. The main contributions of this work are i) implementing an end-to-end deep learning MRI reconstruction approach on a hardware accelerator, ii) integration in the larger RISC-V ecosystem, and iii) evaluation of the precision of the weights on MRI reconstruction performance.
Methods
AUTOMAP casts the MRI reconstruction problem as a supervised learning task where the input into the model is data acquired in k-space and the output is the reconstructed image. The network itself consists of 3 fully connected layers followed by 2 convolution layers. To get the model to run on Gemmini, we converted a trained model from Tensorflow to ONNX9 format using the tf2onnx package.Gemmini is a full system, full stack Deep Neural Net accelerator within the open source Chipyard framework. It uses a systolic array architecture which accelerates computations like convolutions and matrix multiplications allowing for a good mapping of AUTOMAP operations to the Gemmini architecture.
FireSim is a cycle accurate simulation platform that is accelerated by FPGA. It allows for accurate comparisons of cycle numbers between models run on the same hardware configuration. The chosen SoC configuration consists single-core Rocket CPU and a single Gemmini core with a frequency of 10MHz. To run our trained AUTOMAP ONNX model on Gemmini, we use FireMarshall, a workload generation tool specifically for RISC-V machines. Marshal builds and installs the boot binary consisting of a compiled RISC-V C++ AUTOMAP binary and builds the root file system for RISC-V linux. In essence, i) a stripped down version of linux is booted onto the FPGA and ii) the compiled ONNX binary runs inference.
Experiments and Evaluation
We trained 3 AUTOMAP models in Tensorflow on 5000 T1 MR images for 100 epochs on a Titan RTX GPU with single precision, half-precision, and quantized (int8) weights. To test the performance and accuracy of Gemmini, we looked at two main measurements: 1) quality of reconstructed images compared to the ground truth fully sampled images and 2) image throughput on Gemmini compared compared to a single core in-order Rocket CPU.
Results and Discussion
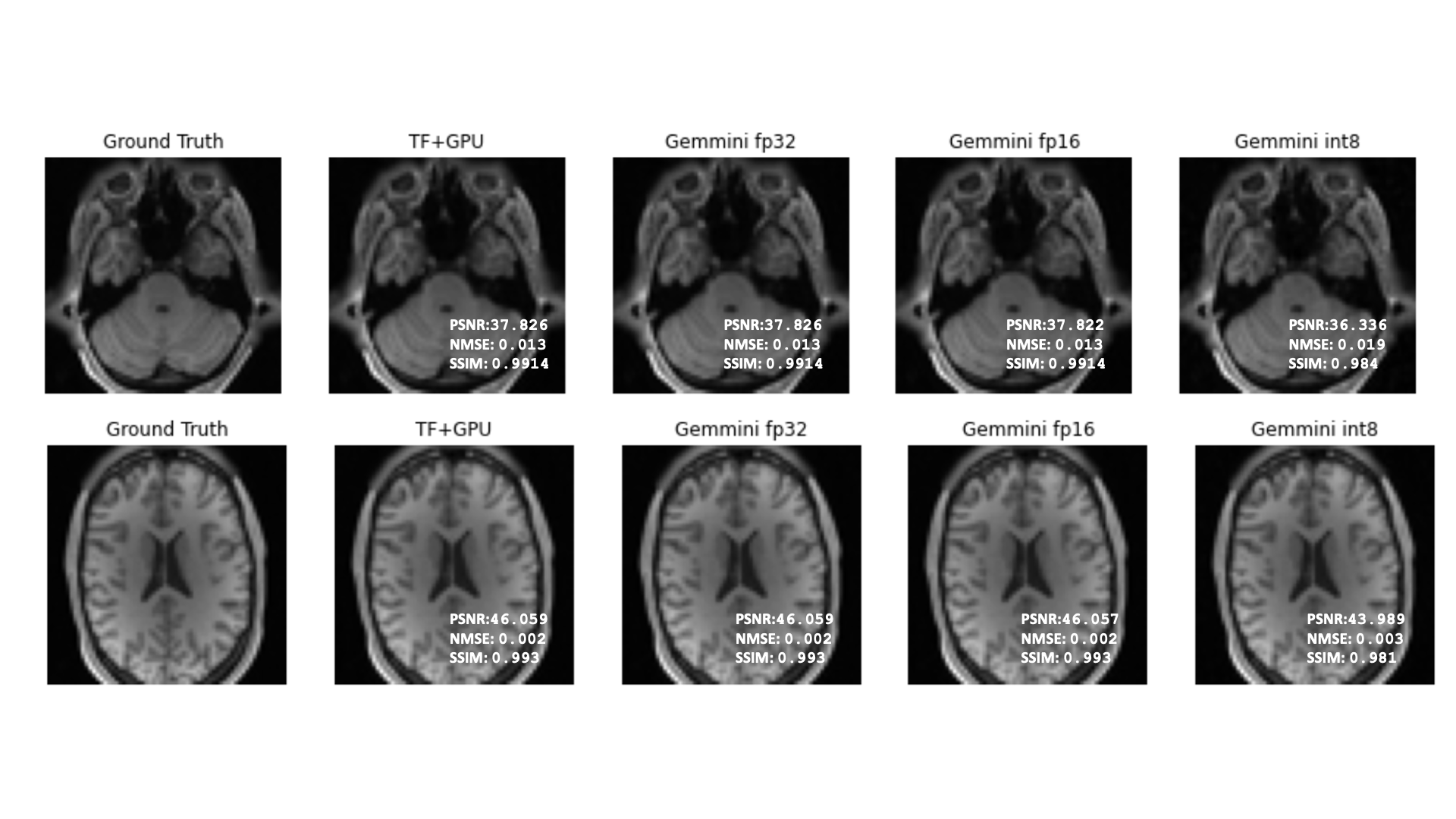
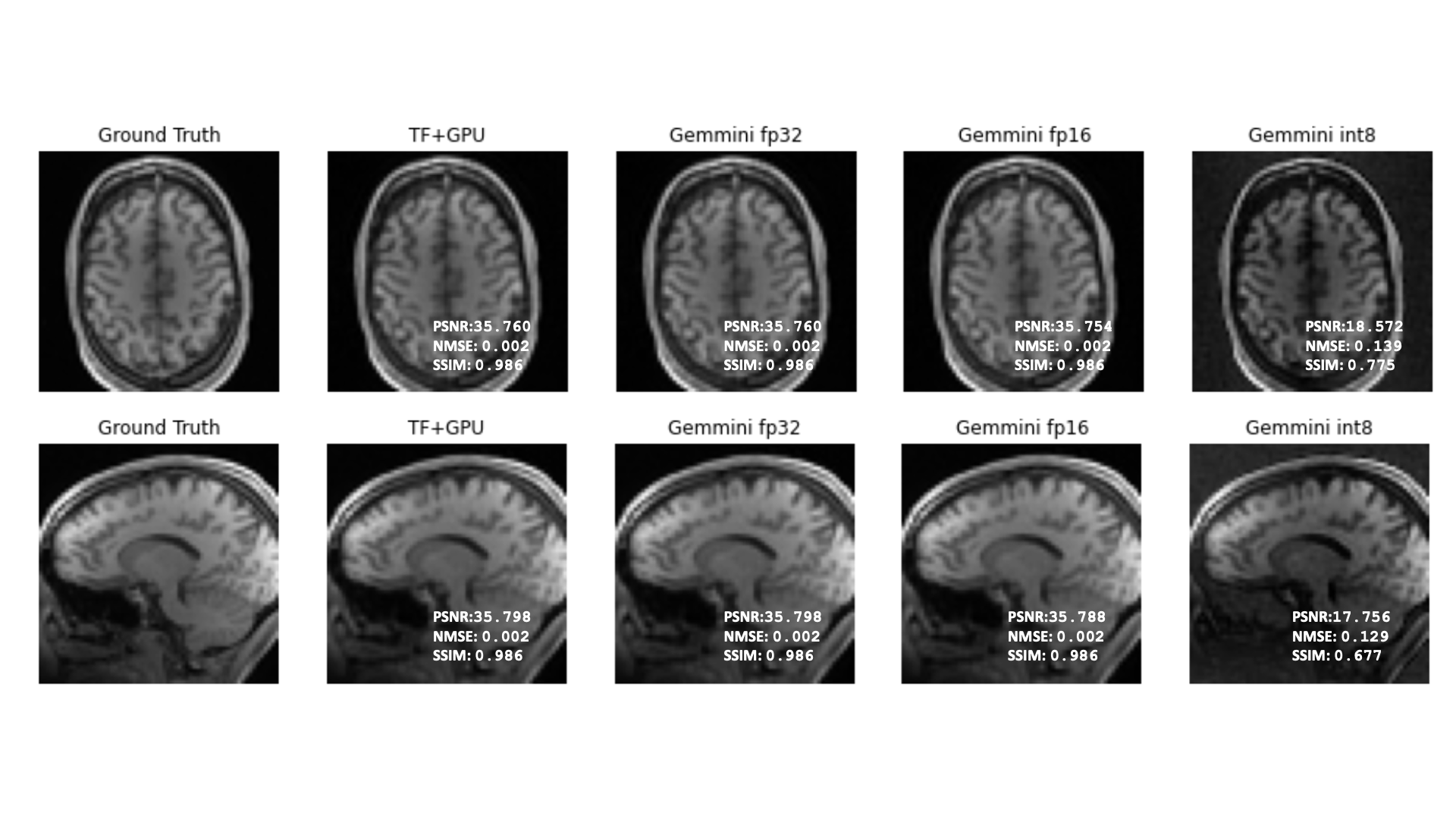
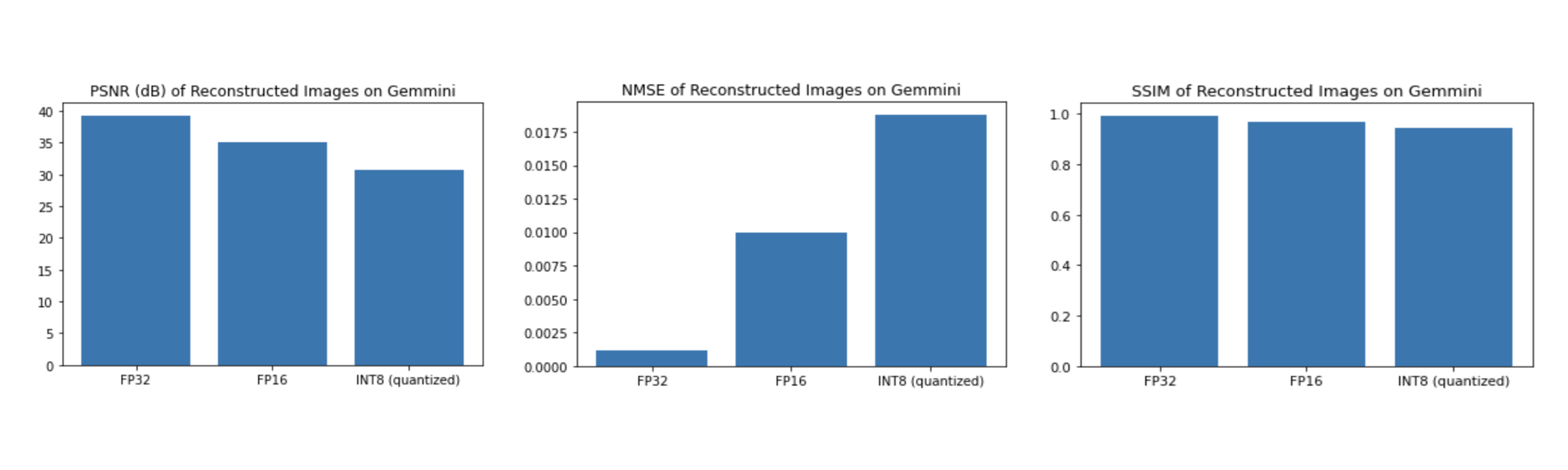
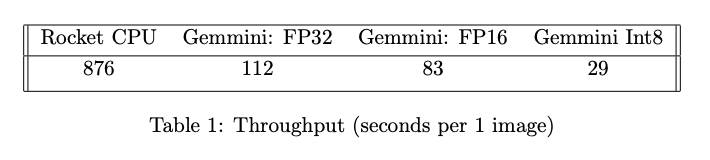
From figures 2 and 3 we see that test image reconstructions from inference on Gemmini are very similar to inference reconstructions using a GPU implementation across the 3 trained models. From figure 4, SSIM seems independent of the precision of the model weights at inference time suggesting that for anatomical or structural applications model size can be cut by 1/4 with maintaining similar SSIM values. For the PSNR we see a steady decrease in performance as the precision of the weights in the model decreases. NMSE of each model drastically increases with decreasing precision of the weights at inference time on Gemmini. This suggests for applications involving measurement of manipulation of pixel values (e.g. quantitative MRI) a quantized model on Gemmini may not be the most appropriate choice. Finally, from Table 1, the quantized model performs the fastest while all models show speedup over an in-order single core Rocket CPU.Conclusion
In this work we have demonstrated a successful implementation of AUTOMAP running on Gemmini, a domain specific hardware accelerator. Our results suggest that image reconstruction algorithms can be incorporated and accelerated in a RISC-V ecosystem with image quality similar to state-of- the-art methods using a GPU. This ultimately could result in MRI reconstruction specific compute hardware for further processing and evaluation and eventual incorporation in a clinical workflow.Acknowledgements
We thank Abe Gonzalez, Prashanth Ganesh, and the rest of the CS 252A course staff at UC Berkeley for helpful insights.References
1] Alon Amid, David Biancolin, Abraham Gonzalez, Daniel Grubb, Sagar Karandikar, Harrison Liew, AlbertMagyar, Howard Mao, Albert Ou, Nathan Pemberton, Paul Rigge, Colin Schmidt, John Wright, Jerry Zhao,Yakun Sophia Shao, Krste Asanovic, and Borivoje Nikolic. Chipyard: Integrated design, simulation, andimplementation framework for custom SoCs. IEEE Micro, 40(4):10–21, July 2020.
[2] Bo Zhu, Jeremiah Z. Liu, Stephen F. Cauley, Bruce R. Rosen, and Matthew S. Rosen. Image reconstruction by domain-transform manifold learning. Nature, 555(7697):487–492, March 2018.
[3] "The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Document version 2.2", Editors Andrew Waterman, and Krste Asanovic, RISC-V Foundation, May 2017
[4] Hasan Genc, Seah Kim, Alon Amid, Ameer Haj-Ali, Vighnesh Iyer, Pranav Prakash, Jerry Zhao, Daniel Grubb,Harrison Liew, Howard Mao, Albert Ou, Colin Schmidt, Samuel Steffl, John Wright, Ion Stoica, JonathanRagan-Kelley, Krste Asanovic, Borivoje Nikolic, and Yakun Sophia Shao. Gemmini: Enabling systematicdeep-learning architecture evaluation via full-stack integration. In 2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, December 2021.
[5] Sagar Karandikar, Howard Mao, Donggyu Kim, David Biancolin, Alon Amid, Dayeol Lee, Nathan Pemberton,Emmanuel Amaro, Colin Schmidt, Aditya Chopra, Qijing Huang, Kyle Kovacs, Borivoje Nikolic, Randy Katz,Jonathan Bachrach, and Krste Asanovic. FireSim: FPGA-accelerated cycle-exact scale-out system simulationin the public cloud. In 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture(ISCA). IEEE, June 2018.
[6] Omair Inam, Abdul Basit, Mahmood Qureshi, and Hammad Omer. FPGA-based hardware accelerator forSENSE (a parallel MR image reconstruction method). Computers in Biology and Medicine, 117:103598, Febru-ary 2020.
[7] Yushan Su, Michael Anderson, Jonathan I. Tamir, Michael Lustig, and Kai Li. Compressed sensing MRIreconstruction on intel HARPv2. In 2019 IEEE 27th Annual International Symposium on Field-ProgrammableCustom Computing Machines (FCCM). IEEE, April 2019.
[8] Tianjian Lu, Thibault Marin, Yue Zhuo, Yi-Fan Chen, and Chao Ma. Accelerating mri reconstruction on tpus,2020.
[9] Junjie Bai, Fang Lu, Ke Zhang, et al. Onnx: Open neural network exchange. https://github.com/onnx/onnx,2019.5
Figures