4266
qDC-CNN: Model-based deep learning image reconstruction with a pixel-wise fitting network for accelerated quantitative MRI1Graduate School of Science and Technology, University of Tsukuba, Tsukuba, Japan, 2Medical Systems Research & Development Center, FUJIFILM Corporation, Minato-ku, Japan
Synopsis
Keywords: Quantitative Imaging, Image Reconstruction, Pixel-wise fitting network; Model-based deep learning
Motivation: Pixel-wise fitting networks are robust to error and enhance quantitative MRI (qMRI) over classical fitting. Combining them with qMRI reconstruction can achieve high performance in accelerated qMRI.
Goal(s): We propose qDC-CNN, combining a pixel-wise fitting network with an unrolled reconstruction network, improving qMRI reconstruction performance.
Approach: We simulated multi-slice multi-echo data using the Brainweb database, comparing five models with different reconstruction and parameter fitting networks.
Results: qDC-CNN provided the highest-quality image reconstructions among all tested models.
Impact: The exceptional reconstruction performance of qDC-CNN, which combines a pixel-wise fitting network with an unrolled reconstruction network, has broad applications in accelerating various quantitative MRI tasks, offering superior results and potential advancements in medical imaging and beyond.
Introduction
Due to the long acquisition time of quantitative MRI (qMRI), deep learning has been actively investigated in recent years to speed up data acquisition. In the pioneering work by Liu et al., 1 an image-to-image mapping network, MANTIS, was proposed to estimate quantitative maps from multiple zero-filled images using U-Net directly. Unrolled network architectures for image reconstruction from undersampled k-space data have recently been reported to outperform MANTIS.2On the other hand, pixel-wise fitting network architectures have been reported to have much faster operation speed, performance, and robustness than conventional pixel-wise least-squares fitting methods.3,4 Therefore, combining an unrolled image reconstruction network with a pixel-wise fitting network is expected to improve the reconstruction performance of qMRI.
Here, we developed a network combining one unrolled network, a deep cascade of convolutional neural network (DC-CNN) 5, with a pixel-wise fitting network. We proposed an end-to-end (E2E) architecture, quantitative DC-CNN (qDC-CNN), which performs image reconstruction and quantitative value estimation in a single step and verify its performance.
Method
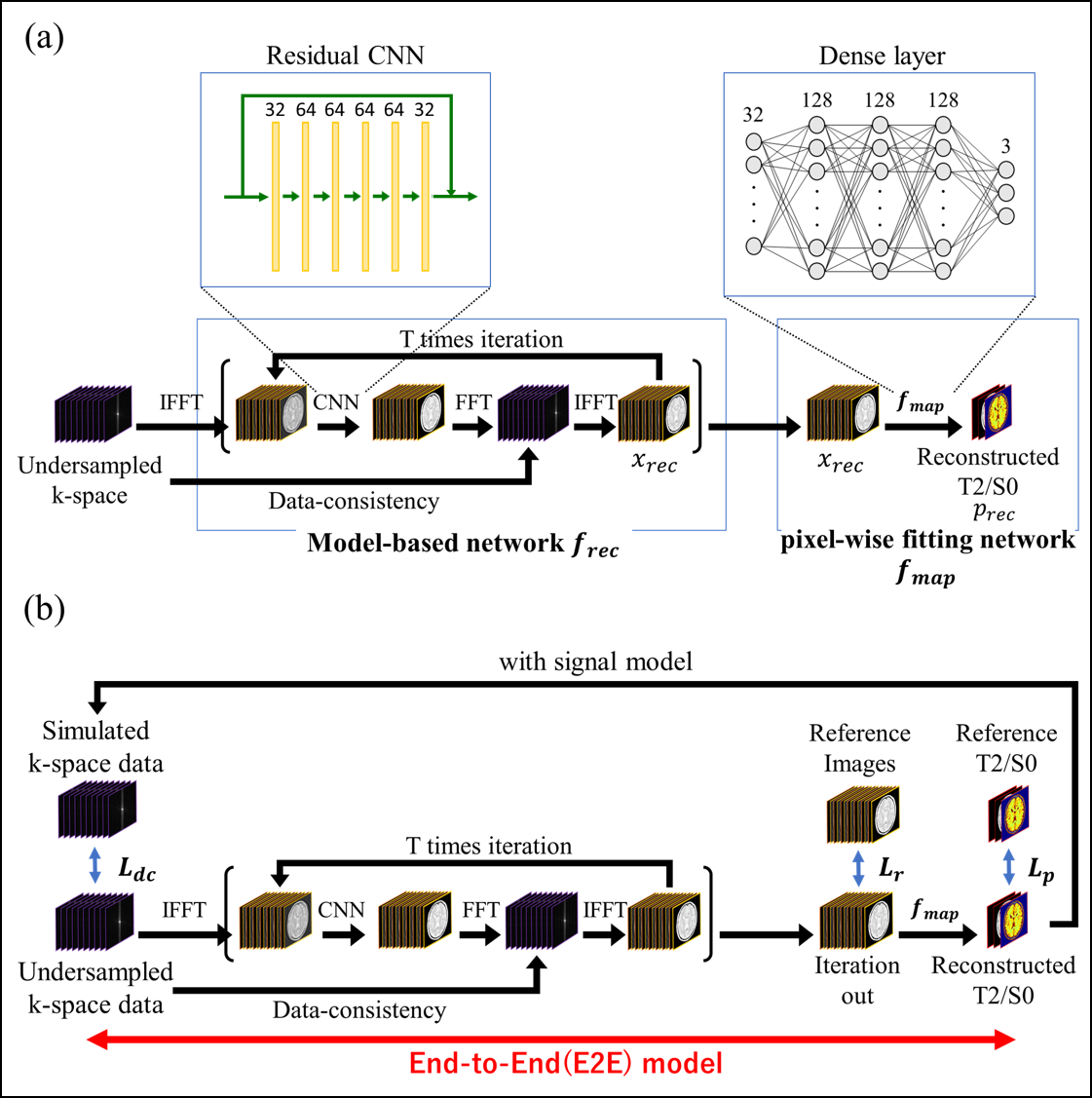
Our proposed architectureFig. 1-(a) shows the network structure of the qDC-CNN. qDC-CNN consisted of two modules: the unrolled network $$$f_{rec}$$$, which reconstructs multi-echo images $$$x_{rec}$$$ from undersampled k-space data , and the pixel-wise fitting network $$$f_{map}$$$, which maps $$$x_{rec}$$$ into quantitative images $$$p_{rec}$$$.
$$x_{rec}=f_{rec}(y_0)$$
$$p_{rec}=f_{map}(y_{rec})$$
$$$y_0=(y_{{TE}_1},y_{{TE}_2},...,y_{{TE}_n})$$$ is the network input where $$$y_{{TE}_i}$$$ is the k-space data acquired with the i-th echo time ($$$TE_i$$$). $$$f_rec$$$ consisted of CNN layers and a data-consistency layer that is repeated T times. We have trained qDC-CNN in E2E scheme (Figure 1-(b)). The following three losses were used in the study:
$$L_r=||x_{gt}-x_{rec}||^2_2$$
$$L_p=||p_{gt}-p_{rec}||^2_2$$
$$L_{dc}=||y_0-FFT(A(p_{rec}))||^2_2$$
where $$$x_{gt}$$$ and $$$p_{gt}$$$ are the ground truth (GT) of image and parameter maps, respectively. $$$A$$$ was a signal model. $$$L_r,L_p$$$ are the loss of image domain and parameter domain.$$$L_{dc}$$$ evaluates the data consistency between reconstructed parameter maps and the measured k-space $$$y_0$$$.The loss functions are weighted:
$$L_{total}={\lambda_r}{L_r}+{\lambda_p}{L_p}+{\lambda_{dc}}{L_{dc}}$$
In this study, $$$\lambda_r=1,\lambda_p=1.0\times10^{-3},\lambda_{dc}=1.0\times10^{-6}$$$.
Dataset
We used a 2D multi-slice multi-spin echo sequence in this study. We simulated fully-sampled (FS) data with the single exponential decay model from quantitative parameters in Brainweb database6. Undersampled (US) k-space data was retrospectively undersampled from FS data with different sampling patterns were used for data acquired with other TEs.
Models
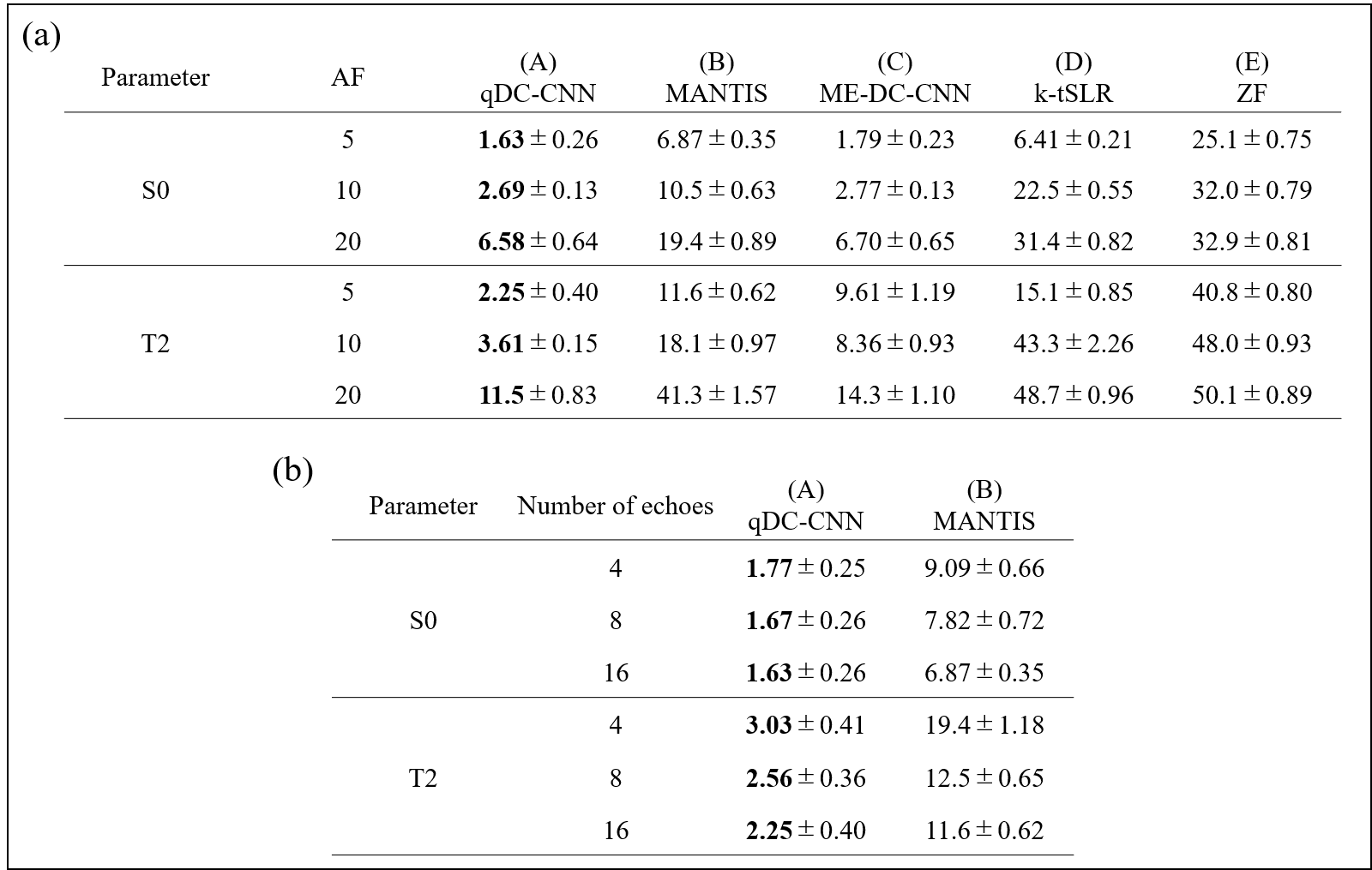
We compared the performance of 5 different reconstruction methods (A) - (E).
(A) qDC-CNN ($$$f_{rec}+f_{map}$$$)
(B) MANTIS 1
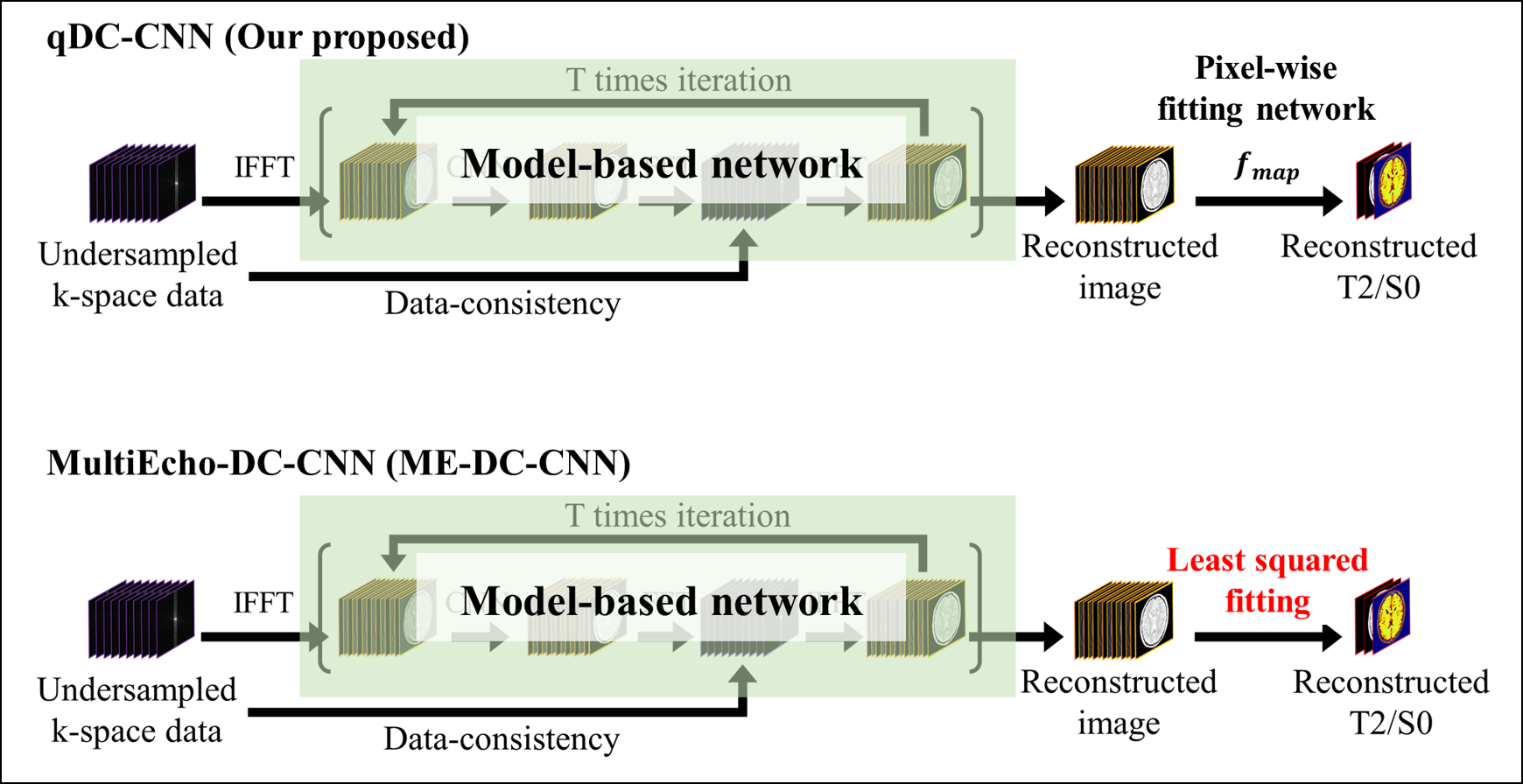
(C) ME-DC-CNN: Multiecho-DC-CNN ($$$f_{rec}$$$) + least squares fitting (LSF)
(D) k-t SLR7 + LSF
(E) Zero-filled reconstruction + LSF
In model B, $$$L_{dc}$$$ and $$$L_{p}$$$ were used as loss terms. Model C was the same as model A except that the pixel-wise fitting network $$$f_{map}$$$ was replaced by LSF to investigate the contribution to performance made by $$$f_{map}$$$(Figure 2). k-t SLR was a non-DL reconstruction method. In models C-E, $$$p_{rec}$$$ were calculated from $$$x_{rec}$$$ using LSF.
Experiment
We conducted two experiments to assess the network performance:
Experiment 1:
Comparison of all models under acceleration factor (AF) of 5, 10, and 20.
Experiment 2:
Comparison of models A and B varying the number of echoes to 4, 8, and 16 under AF = 5.
In both experiments, TE = 10 - 150 ms (every 40 ms) at 4 echoes, 10 - 150 ms (every 20 ms) at 8 echoes, and 10 - 160 (every 10 ms) at 16 echoes. 960, 120, and 120 images were used for training, validation, and testing respectively. The learning rate was $$$1.0\times10^{-4}$$$ and and optimizer was Adam. We monitored validation loss and terminated the study if there was no 10 epoch improvement. We used normalized root mean squared error (NRMSE) as an evaluation metric.
Results and Discussion
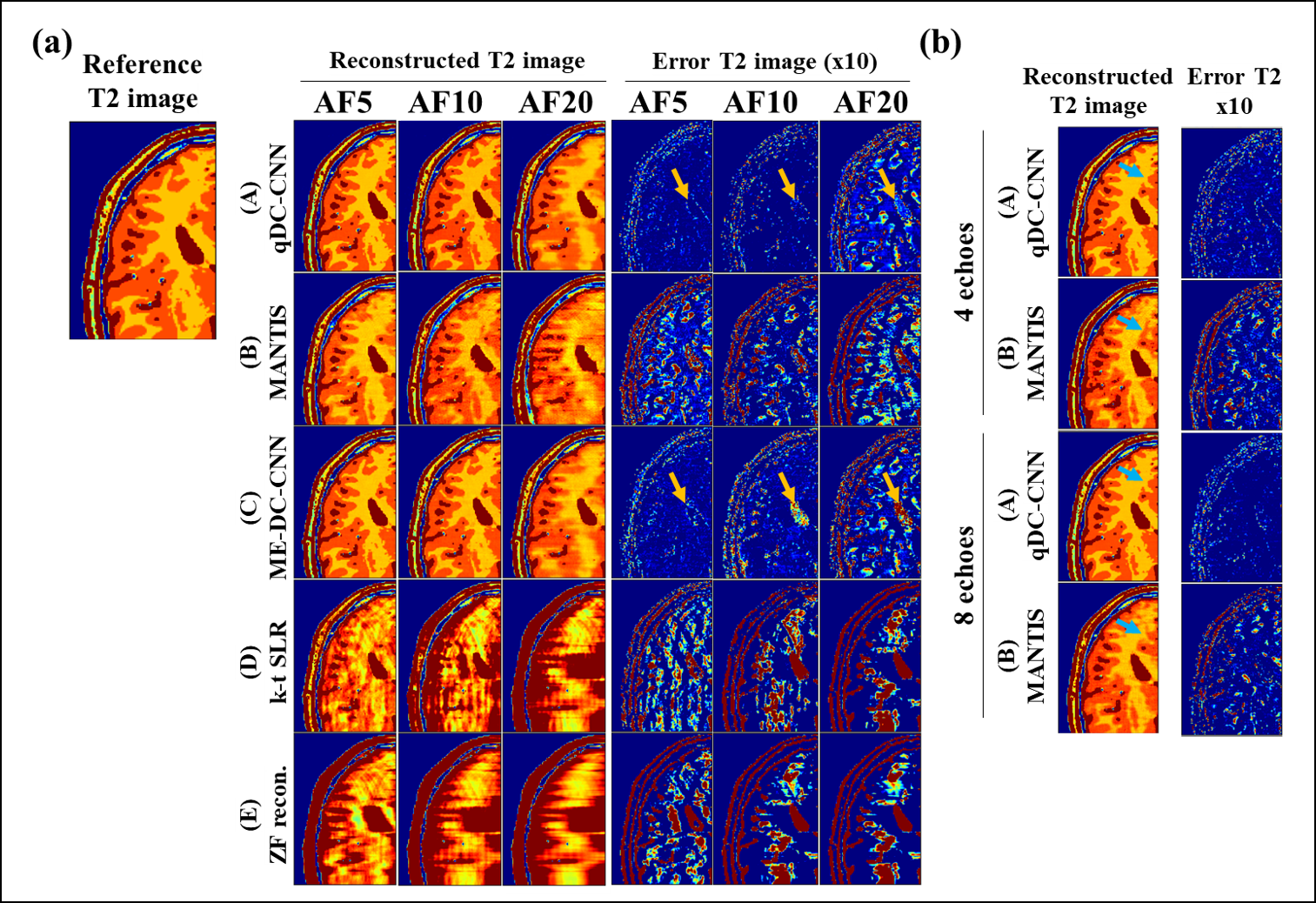
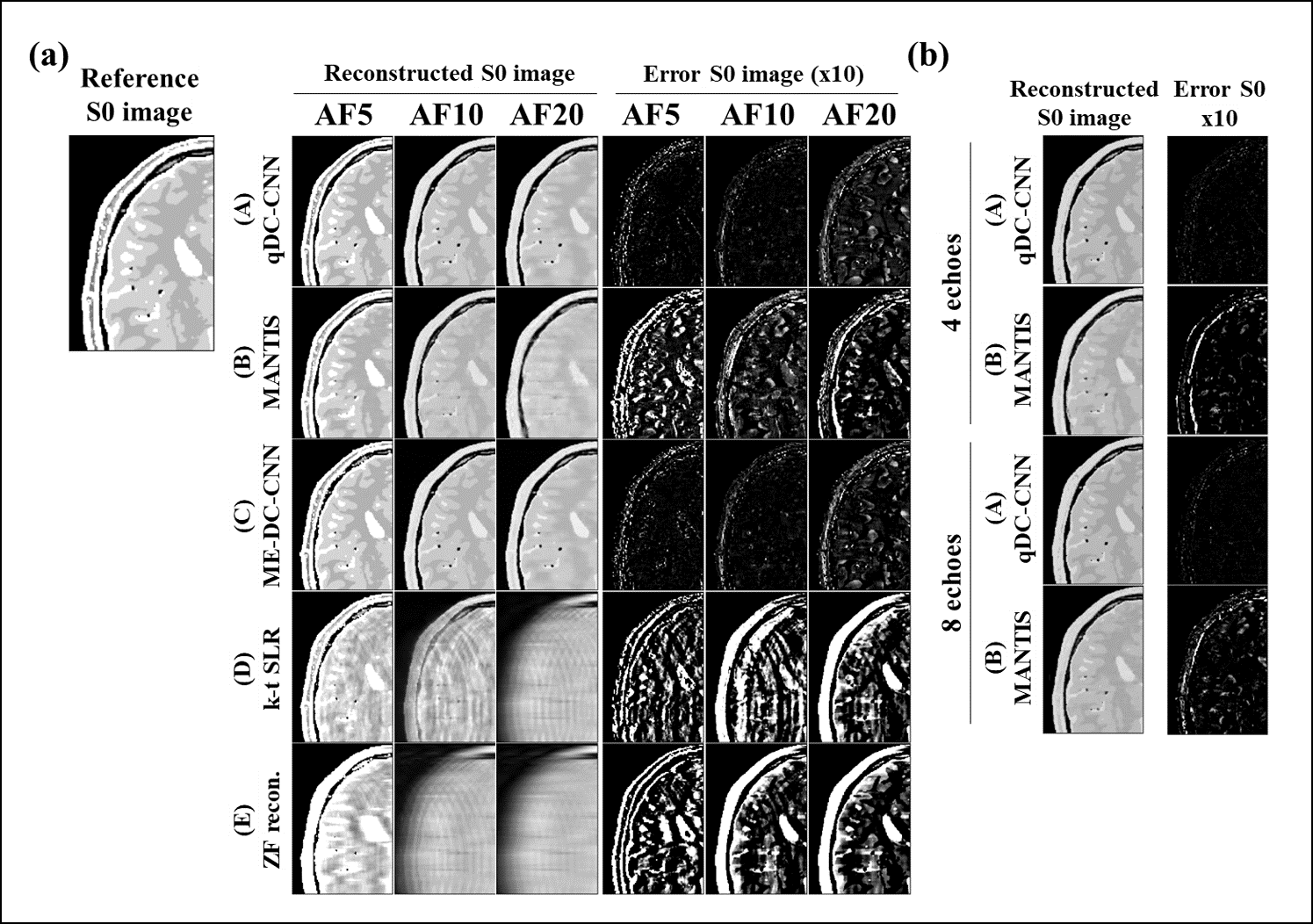
Figures 3 and 4 show the reconstructed T2 and S0 images, and Tables 1 and 2 list the results of quantitative evaluation. qDC-CNN (model A) was able to reconstruct the highest-quality images among all tested models, which was supported by the quantitative evaluation metrics.The results of Experiment 1 show that qDC-CNN performs better than ME-DC-CNN (model C) without the pixel-wise fitting network, especially in T2 reconstruction (Figure 3-(a), yellow arrows). This indicates that the pixel-wise fitting network is effective for quantitative value estimation.
The results of Experiment 2 show that as the number of echoes decreases, microstructures were lost for MANTIS (Figure 4-(a), blue arrows) but not for qDC-CNN. This indicates that qDC-CNN can maintain its performance even in small numbers of echoes.
Conclusion
This study shows the effectiveness of the proposed method, qDC-CNN, for qMRI. This method can be applied to other model-based architectures and quantitative parameters.Acknowledgements
No acknowledgement found.References
Figures