4170
Fast Multi-contrast MRI using Deep Factor Model1University of Iowa, Iowa City, IA, United States, 2University of Wisconsin–Madison, Madision, WI, United States, 3Champaign Imaging, LLC, Minneapolis, MN, United States
Synopsis
Keywords: Sparse & Low-Rank Models, Multi-Contrast, low-rank, Brain imaging, Quantitative MRI, MR fingerprinting
Motivation: 3D MR fingerprinting (MRF) and MPnRAGE acquire a large number (400-1000+) of non-steady state images with different encodings to estimate quantitative relaxometry parameters. The large number of volumetric images presents serious computational and memory issues for many advanced image reconstruction techniques, especially those utilizing deep learning.
Goal(s): This work develops a memory efficient, pretrained deep factor model (DFM) for high quality, high temporal images.
Approach: We apply a progressive training and pre-training strategy to accelerate the convergence for a self-supervised DFM.
Results: DFM recovers 384 3D brain images (1mm isotropic resolution) from a 2.3 minutes MPnRAGE scan within 30 minutes of reconstruction time.
Impact: The proposed pretrained deep factor model enables fast MRF reconstruction from accelerated acquisition in a 3D+time setting. It has the potential to significantly shorten the acquisition time for quantitative MRI, while providing high quality weighted MRI results.
Introduction
MPnRAGE1 acquires highly undersampled 3D radial datasets corresponding to different inversion times, followed by fitting to gridded source images to derive quantitative T1 maps. Despite yielding high-quality maps at 1mm isotropic from 9 minutes scans, the source images exhibit under-sampling artifacts. Constrained reconstruction algorithms, such as global and local low-rank methods2-6, can be employed to reduce scan time and enhance source image quality. However, these algorithms are associated with extended reconstruction times, especially in a 3D context.Deep Factor Model
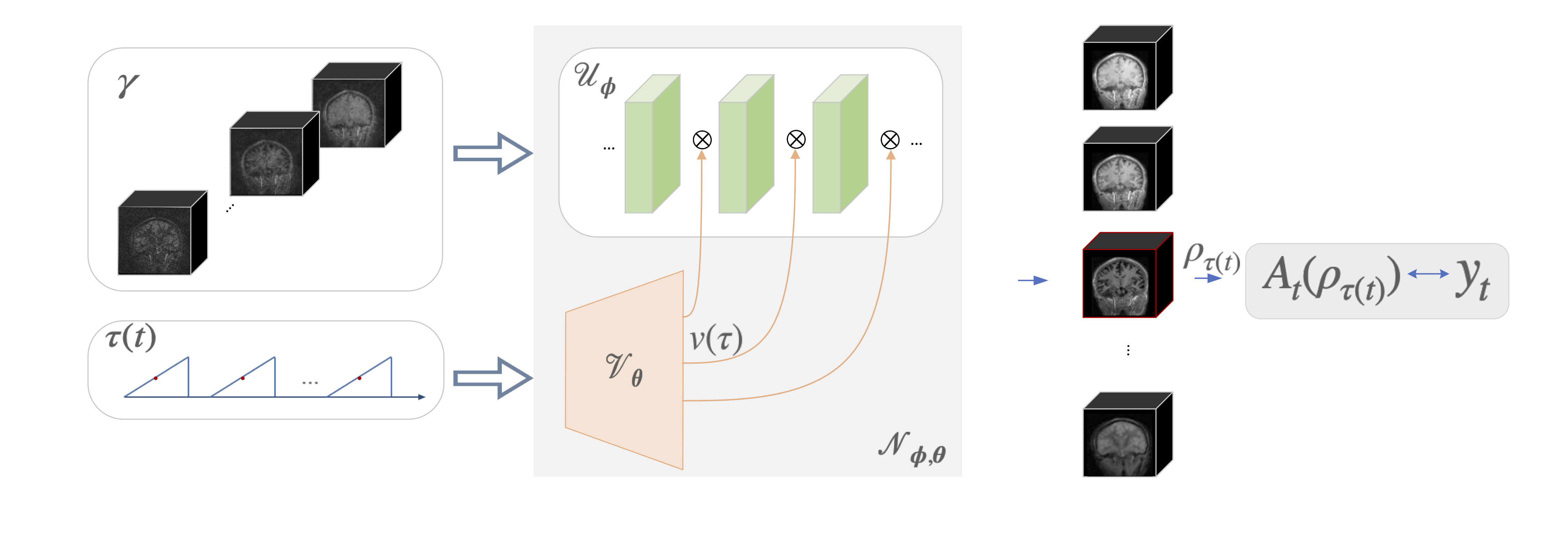
MRF7 acquires a series of images, each corresponding to a different magnetization weighting depending on the specific sequence. The forward model at a specific time instant can be denoted as $$y_t=A_t\rho_t+ n_t$$ Where $$$\rho_t$$$ and $$$y_t$$$ denote the image and measurements at time point t associated with forward operator $$$A_t$$$, and $$$n_t$$$ is noise in k-space. DFM models the images $$$\rho_t=N_{\phi,\theta}(\gamma, \tau(t))$$$ as the output of a neural network $$$N_{\phi,\theta}$$$, whose architecture is shown in Fig. 1. Note that this approach is a non-linear generalization of factor models, including low-rank methods that express the image time series as the product of spatial and temporal factors. The weights of DFM $$$N_{\phi,\theta}$$$ are learned from k-space measurements. $$ \{ \phi^*,\theta^*\} = \arg \min_{ \phi,\theta} \sum_t \| y_t-A_t\big( N_{ \phi,\theta}( \gamma,\tau)\big)\|^2$$ $$$\phi$$$ and $$$\theta $$$ denote weights of CNN and MLP, respectively. DFM is trained in an unsupervised fashion by matching the k-space data of the generated images to the actual measurements, similar to the deep image prior8. It eliminates the need for fully sampled reference datasets to train supervised methods, which are expensive to acquire in the MRF setting.Enhanced Deep Factor Model
Unfortunately, the DFM's unsupervised learning strategy is computationally expensive (~10 hours of run time), in 3D+time setting. In addition, this approach does not allow the use of information from prior scans to guide the reconstruction. To further minimize run-time, we propose two key enhancements:(a) Progressive learning: We adopt a progressive approach by gradually increasing both the image-size and temporal resolution throughout the training process. Initially, we condense the original data into 32 inversion-times, substantially reducing the number of CNN and NUFFT forward evaluations. Once training for this scale is completed, we expand the number of bins and image dimensions, building upon the previously learned model parameters. Similarly, the image dimension grows progressively from 1283 to 2563.
(b) DFM with pretraining: We propose a self-supervised pretraining strategy to further reduce the run time. We pretrain the network parameters $$$(\phi_0,\theta_0)$$$ from N training datasets in a self-supervised fashion using progressive learning. These network parameters are used as initialization for unsupervised learning on new datasets. The approach significantly reduces the number of iterations for convergence. Furthermore, this approach also allows us to transfer the prior information from better sampled reference datasets (e.g 9 min scans) to the undersampled setting (e.g. 2.25 min scans).
Experiments and Results
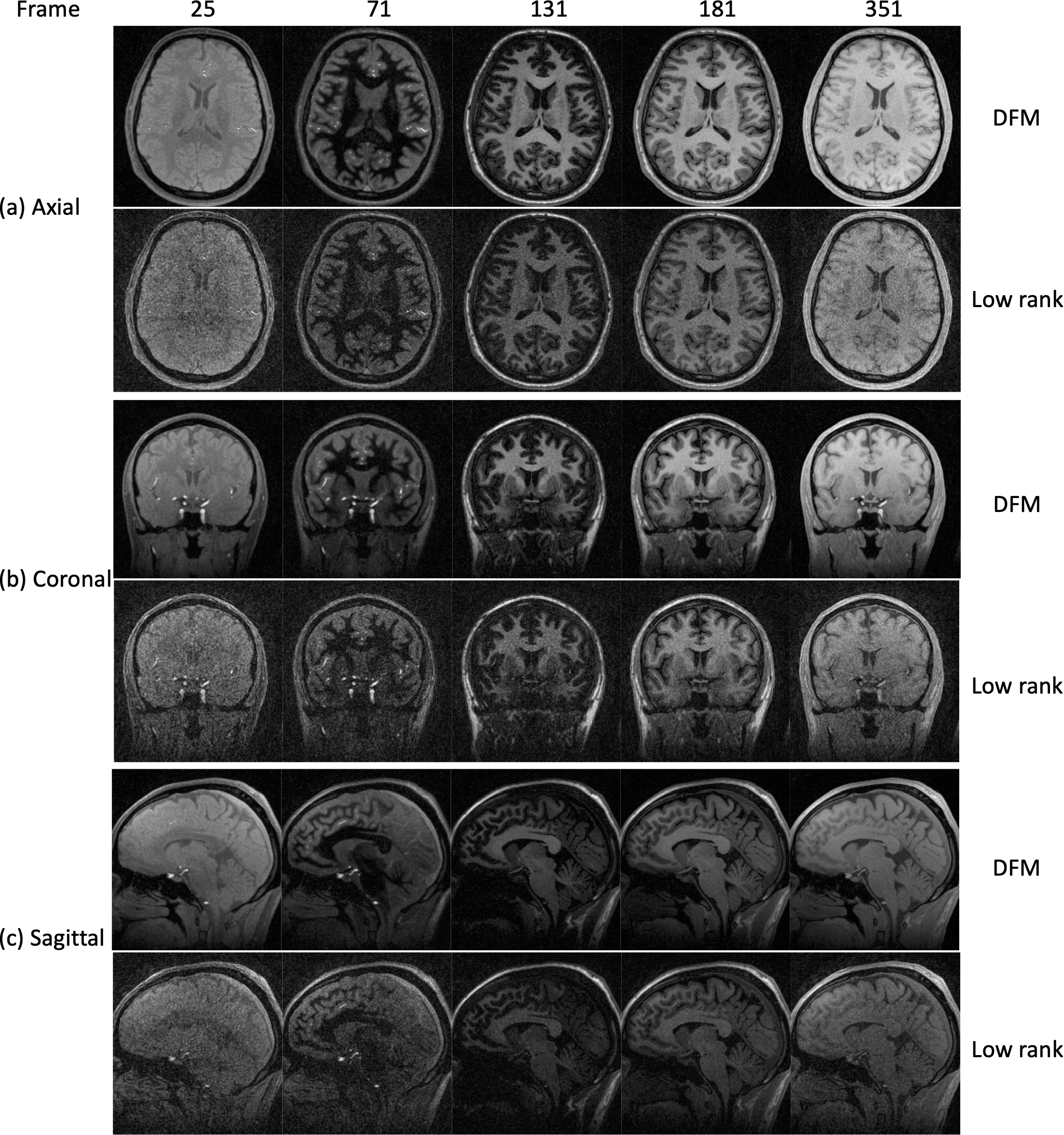
Sequence: We demonstrate DFM on a 3T scanner with a 3D radial inversion recovery sequence for T1 relaxometry (MPnRAGE), where a series of 384 excitation pulses is played after an 180-inversion pulse in each inversion block, followed by a delay of 500ms. A 9 min reference scan, which previously demonstrated high accuracy in the HPI Systems phantom9, was used as the “gold standard”. We retrospectively select adjacent subsets of this reference dataset to determine the ability of DFM to reduce the scan time.DFM with no pretraining (Fig.2): We apply self-supervised learning to recover 384 3D brain images from a 9 min MPnRAGE scan. We compare our results with a simple low-rank scheme, where we perform gridding reconstruction of each time frame by projecting it with the temporal basis functions in k-space. We observe that the proposed approach can provide a significant reduction in noise compared to the low-rank method.
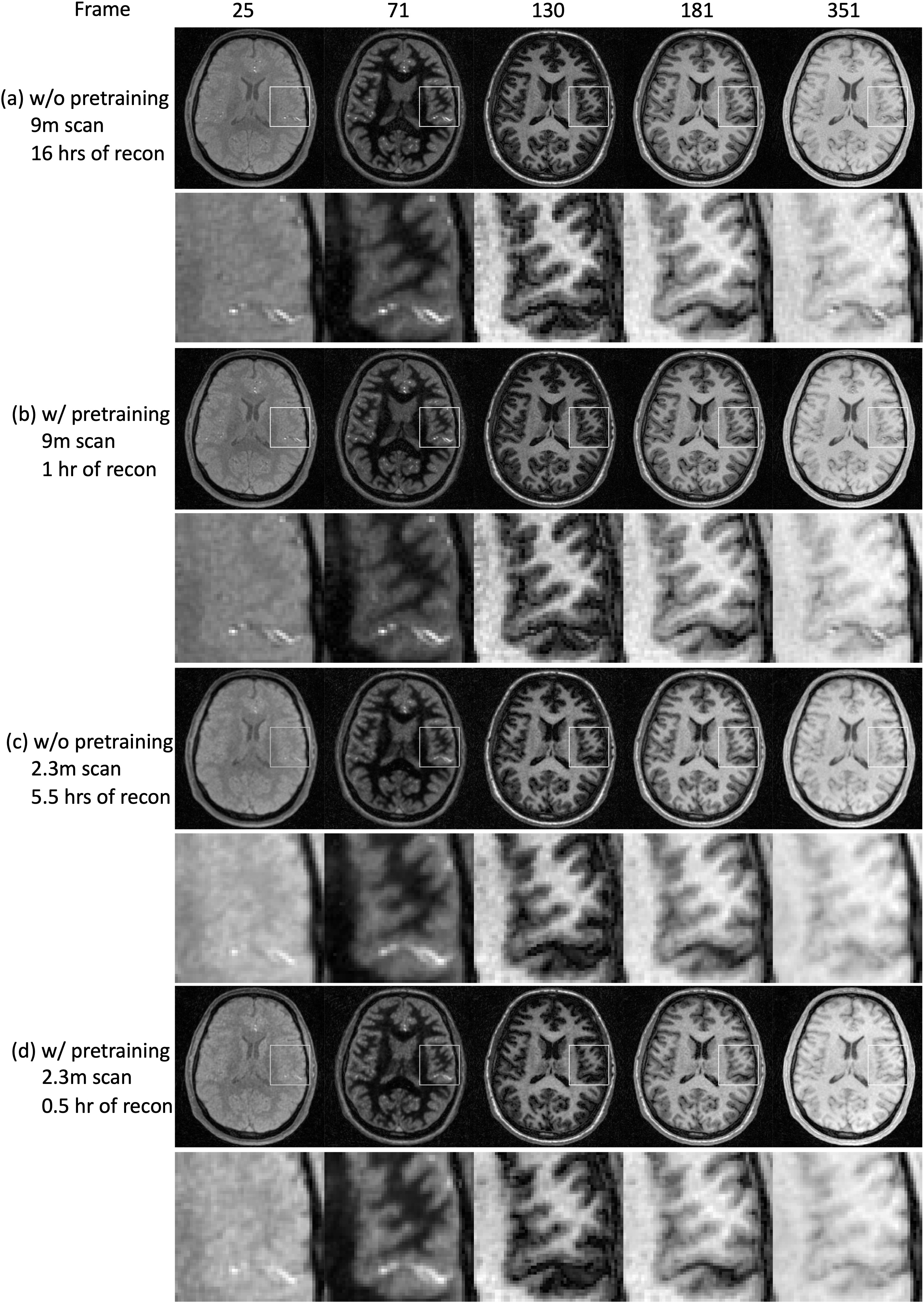
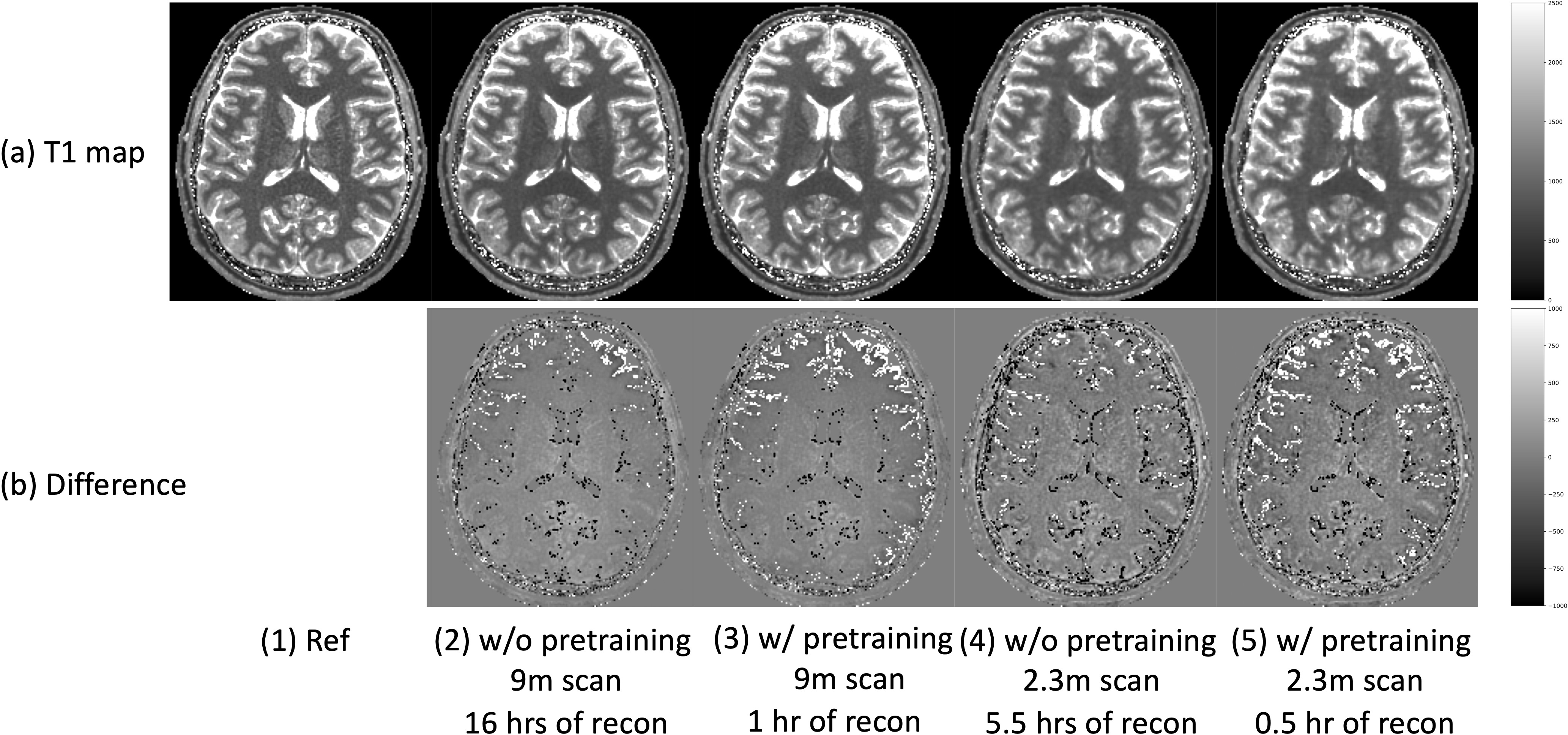
DFM with pretraining (Fig.3 and Fig.4): We first pretrain DFM on a training dataset from a 9 min scan. These network parameters are used as initialization during inference, which accelerates the reconstruction. The results show that the pretrained DFM is able to significantly reduce the run-time for both 9 min and 2.3 min scans without sacrificing the image quality (Fig.3) or T1 accuracy (Fig.4).
Conclusion
The enhanced DFM recovers high quality and high temporal images in a self-supervised manner. Both reconstruction and scan time are significantly shortened using pretrained DFM.Acknowledgements
This work is supported by R01-AG067078, R01-EB031169, R01-EB019961, NIH R43MH122028, NIH R01AG067078, NIH P50HD103556, NIH S10OD025025, R01 HD108868, University of Iowa Hawk-IDDRC.
University of Iowa and University of Wisconsin-Madison receive research support from GE Healthcare.
References
- Kecskemeti S, Samsonov A, Hurley S A, et al. MPnRAGE: A technique to simultaneously acquire hundreds of differently contrasted MPRAGE images with applications to quantitative T1 mapping[J]. Magnetic resonance in medicine, 2016, 75(3): 1040-1053.2.
- Mazor G, Weizman L, Tal A, Eldar YC. Low-rank magnetic resonance fingerprinting. Med Phys. 2018 Jul 4. doi: 10.1002/mp.13078. Epub ahead of print. PMID: 29972693.3.
- Assländer J, Cloos MA, Knoll F, Sodickson DK, Hennig J, Lattanzi R. Low rank alternating direction method of multipliers reconstruction for MR fingerprinting. Magn Reson Med. 2018 Jan;79(1):83-96. doi: 10.1002/mrm.26639. Epub 2017 Mar 5. PMID: 28261851; PMCID: PMC5585028.4.
- Zhao B, Setsompop K, Adalsteinsson E, Gagoski B, Ye H, Ma D, Jiang Y, Ellen Grant P, Griswold MA, Wald LL. Improved magnetic resonance fingerprinting reconstruction with low-rank and subspace modeling. Magn Reson Med. 2018 Feb;79(2):933-942. doi: 10.1002/mrm.26701. Epub 2017 Apr 15. PMID: 28411394; PMCID: PMC5641478.5.
- Zhang T, Pauly JM, Levesque IR: Accelerating parameter mapping with a locally low rank constraint. Magnetic Resonance in Medicine 2015; 73:655–661.6.
- Lima da Cruz G, Bustin A, Jaubert O, Schneider T, Botnar RM, Prieto C: Sparsity and locally low rank regularization for MR fingerprinting. Magnetic Resonance in Medicine 2019; 81:3530–3543.7.
- Ma D, Gulani V, Seiberlich N, et al. Magnetic resonance fingerprinting[J]. Nature, 2013, 495(7440): 187-192.
- Ulyanov D, Vedaldi A, Lempitsky V. Deep image prior[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 9446-9454.
- Kecskemeti S, Alexander AL. Three-dimensional motion-corrected T1 relaxometry with MPnRAGE. Magn Reson Med. 2020 Nov;84(5):2400-2411. doi: 10.1002/mrm.28283. Epub 2020 Apr 17. PMID: 32301173; PMCID: PMC7396302.
Figures