3925
Gradient Preemphasis Predicted by Reinforcement Learning1Institute of Imaging Science, Vanderbilt University Medical Center, Nashville, TN, United States, 2Biomedical Engineering, Vanderbilt University, Nashville, TN, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, System Imperfections: Measurement & Correction, Reinforcement learning
Motivation: Gradient hardware chains can exhibit dynamic nonlinearities that cannot be easily corrected with linear models and require more sophisticated approaches.
Goal(s): Our goal was to develop a flexible and dynamic approach to correct nonlinear MRI system imperfections.
Approach: We developed a reinforcement learning method for predicting gradient preemphasis and evaluated it in a realistic simulated environment with obscured state information.
Results: Reinforcement learning is able to accurately predict gradient preemphasis even when system state information is unknown.
Impact: The ability to dynamically correct system imperfections through reinforcement learning may allow the development of more robust imaging systems that can adapt to complex, nonlinear distortions, reducing the need for expensive hardware corrections or inflexible, system-specific system models.
Introduction
Gradient trajectory errors can have a considerable negative impact on image quality in magnetic resonance imaging. Trajectory deviations produce artifacts in non-Cartesian acquisitions1, and distortions in magnetization profiles2. Most frequently, the gradient chain and its imperfections are modeled as a linear time-invariant system3. Using a linear model, appropriate gradient pre-emphasis may be predicted and added to the nominal gradient waveform to produce the desired output4. However, the success of such methods assumes linearity, and gradient systems may have substantial nonlinearities. The gradient response has been observed to have nonlinear dependence on the input waveform5 and hardware heating1. Thus, nonlinear pre-emphasis approaches may be required to more completely correct gradient distortions.We hypothesize that a reinforcement learning6 (RL) approach can predict gradient waveform pre-emphasis. RL has been applied to several problems in MRI7-9. However, these applications assumed a fully observable environment, in which all state information is available. In general, many realistic environments are partially observable, with important state information obscured10. In the case of gradient predistortion, the most salient state information (the current timestep's error between nominal and preemphasized waveform) can only be known after the gradient waveform has been played out, not during its timecourse. To overcome this partial observability, we incorporate a recurrent neural network (RNN) to model unobservable states over the waveform timecourse11. This abstract presents a preliminary assessment of the ability of RL to pre-compensante gradient waveforms based upon gradient system measurements3.
Methods
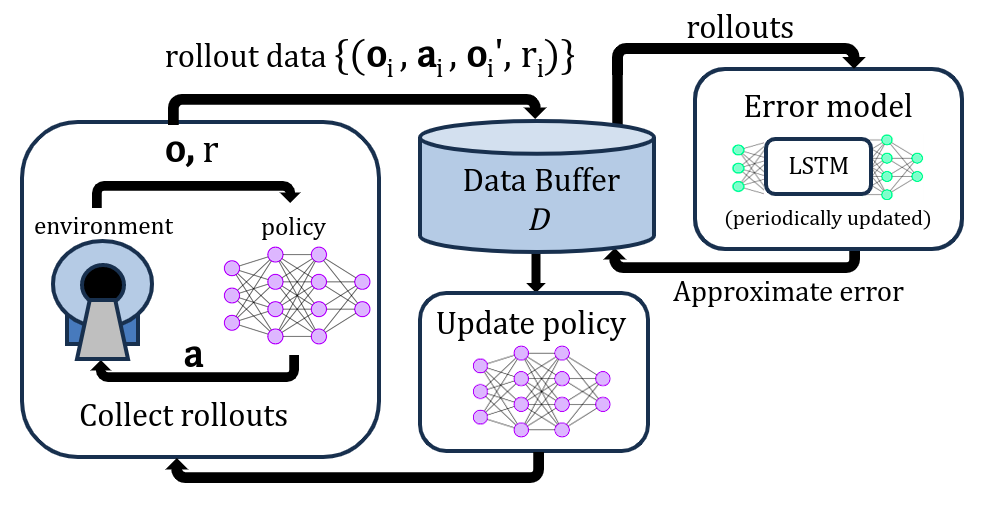
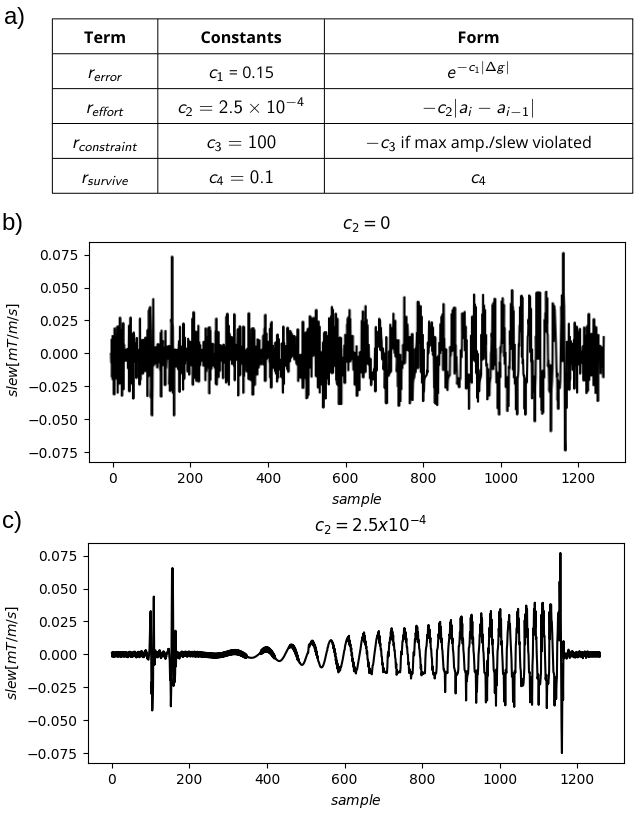
The RL framework utilized in this work is shown in Fig.1. An off-policy RL algorithm, TD312, was employed using Stable Baselines313 and hyperparameter tuning was performed with Optuna14. TD3 learns a policy which predicts the optimal next gradient preemphasis action a given a current observed system state o. The action space from which actions ai at timepoint i are selected was continuous over (-1, 1), and determined normalized change in gradient slew. The observation space was oi=[slewi, errori]. Only the slewi state is observable. To predict unobservable errori, a RNN with one LSTM layer and one fully connected layer was used to estimate error based on waveform history. This network was trained on 8 unique gradient waveforms, including chirps and trapezoids, measured on the 7T system at 7 gradient amplitudes. To direct the agent to satisfy system constraints, reward shaping15 was used. The total timestep reward was $$$r_i=c_1r_{error,i}+c_2r_{effort,i}+c_3r_{constraint,i}+c_4r_{survival,i}$$$. To verify that the error modeling RNN adequately approximates hidden states, the RL agent was trained to develop a preemphasis policy under two different conditions: 1) with access to the exact error for errori, and 2) with the RNN's prediction of errori.The training environment was constructed from gradient waveform measurements on the z-axis of on a 7T Bruker preclinical BioSpec system (Bruker Corporation, Billerica, MA, USA) using variable prephasing16. These measurements were used to build a GIRF gradient model3. Training was performed using multiple measured chirp and trapezoidal gradient waveforms17. Training was repeated with and without the effort reward term reffort,i to demonstrate the impact of reward shaping.
Results
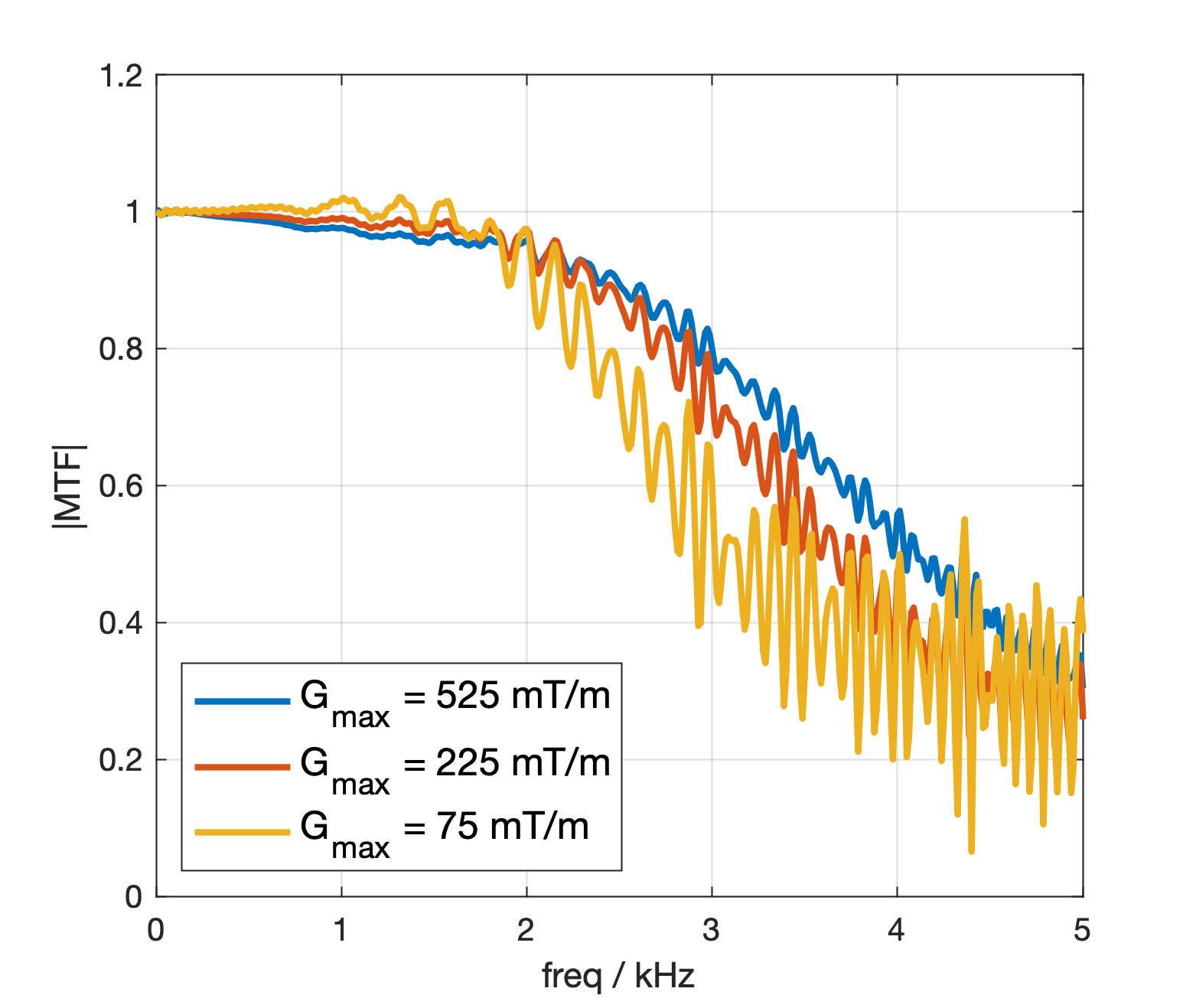
Fig.2 shows the gradient modulation transfer function measured on the system in our methods, which exhibits clear nonlinearity.Fig.3a defines the reward given to the agent at each timestep, while Fig.3b-c shows the impact that reward shaping can have on the dynamics of the learned gradient control. If no effort penalty is imposed, the agent creates rough, unrealizable waveforms.
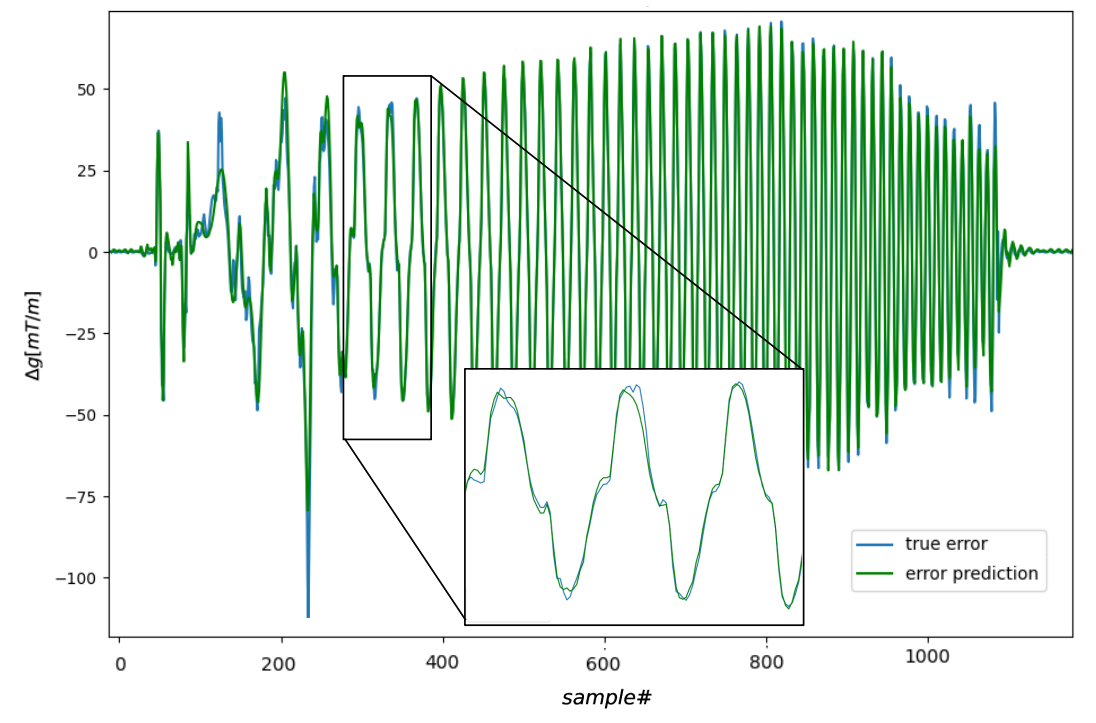
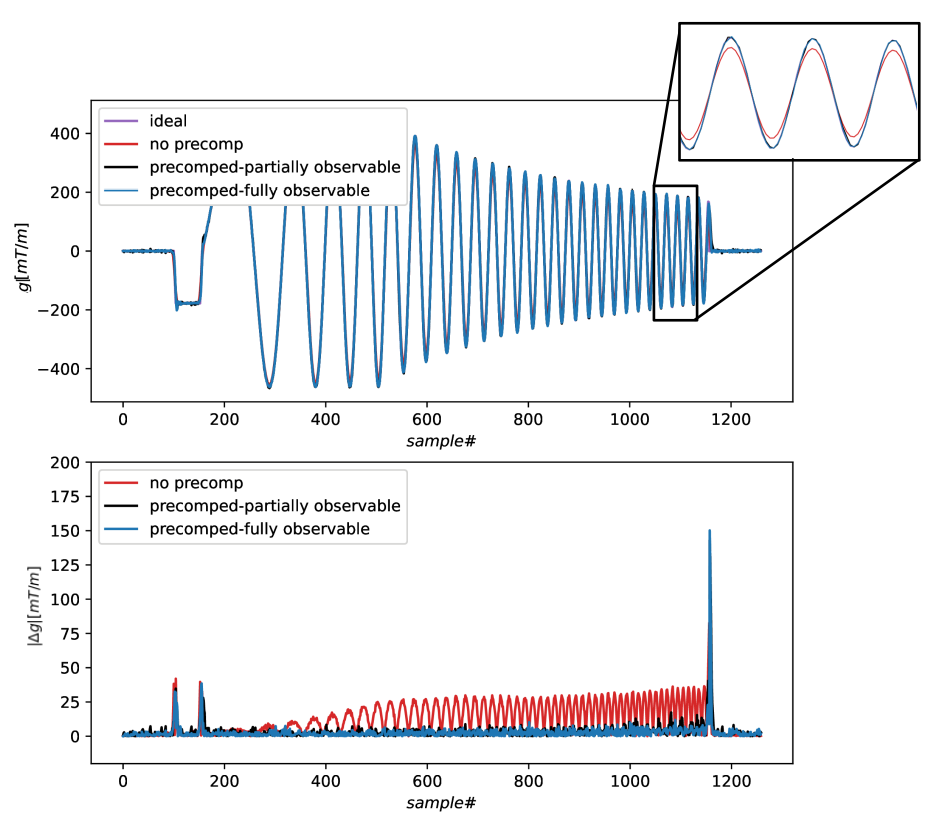
Fig.4 show that the error prediction RNN provides accurate estimation of error over a pulse's timecourse. Across 32 evaluation waveforms, the RNN achieved a test RMSE of 6.8E-3. The learned predistortion of a test waveform is shown in Fig.5. The TD3 RL agent learns precompensation slew which reduces the trajectory error to small values regardless of error state observability.
Discussion
This initial implementation of reinforcement learning based gradient preemphasis demonstrates in simulation the feasibility of using RL to compensate for system imperfections, in particular for temporally nonlinear gradient. The design of rewards is critical to the success of RL agents, and it was shown to have profound effects on the characteristics of the learned preemphasis. An adequate reward function must be designed for the task at hand. Partial observability is a challenging problem for RL algorithms that can make real-world implementation of RL agents impossible in many cases10. This issue is rarely addressed in MRI applications of RL. We show that in the context of learned gradient preemphasis, partial observability can be overcome with a RNN predicting hidden states. This method provides a general framework for flexibly correcting nonlinear gradient distortions due to system nonlinearities and changing system response.Acknowledgements
The authors gratefully acknowledge funding from grants NIH RO1 EB031954 and NIH T32 EB001628 which made this work possible.References
[1] Graedel N., Kasper L., Engel M., Nussbaum J., Wilm B., Pruessmann K., andVannesjo S., Feasibility of spiral fMRI based on an LTI gradient model. Neuroimage. 2020; 245(1):1-10.
[2] Tse D. H. Y., Wiggins C. J., and Poser B. A. Estimating and eliminating the excitation errors inbipolar gradient composite excitations caused by radiofrequency-gradient delay: Example of bipolarspokes pulses in parallel transmission. Magnetic Resonance in Medicine. 2017; 78(5):1883–1890.
[3] Vannesjo S., Haeberlin M., Kasper L., Pavan M., Wilm B., Barmet C., and Pruessmann K. Gradient System Characterization by Impulse Response Measurements with a Dynamic Field Camera. Magnetic Resonance in Medicine. 2013; 69:583-593.
[4] Ahn C, Cho Z. Analysis of the Eddy-Current Induced Artifacts and the Temporal Compensation in Nuclear Magnetic Resonance Imaging. IEEE TMI. 1991; 10:47-52.
[5] Nussbaum, J. Advanced Modeling of Gradient Systems in MRI. 2020; PhD. Thesis.
[6] Arulkamaran K., Deisenroth M., Brundage M., Bharath A. Deep Reinforcement Learning: A Brief Survey. 2017; 34(6): 26-38.
[7] Zhu B., Liu J., Koonjoo N., Rosen B., Rosen M. AUTOmated pulse SEQuence generation (AUTOSEQ) using Bayesian reinforcement learning in an MRI physics simulation environment. Proc. Intl. Soc. Magn. Reson. Med. 2018; 26:438.
[8] Zheng D., Sandino C., Nishimura D., Vasanawala S., Cheng J. Reinforcement Learning for Online Undersampling Pattern Optimization. Proc. Intl. Soc. Magn. Reson. Med. 2019; 27:1092.
[9] Shin D., Kim Y., Oh C., An H., Park J., Kim J., Lee J. Deep Reinforcement Learning-Designed Radiofrequency Waveform in MRI. Nature Machine Intelligence. 2021 3:985-994.
[10] Liu Q., Chung A., Szepesvari C., Jin C. When Is Partially Observable Reinforcement Learning Not Scary? PMLR. 2022; 178:5175-5220.
[11] Meng L., Gorber R., Dana K. Memory-based Deep Reinforcement Learning for POMDPs. IEEE IROS. 2021; p5619-5626.
[12] Fujimoto S., van Hoof H., Meger D. Addressing Function Approximation Error in Actor-Critic Methods. ICML. 2018; 35:1-15.
[13] Raffin A., Hill A., Gleave A., Kanervisto A., Ernestus M., Dormann N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. JMLR. 2021; 22:1-8.
[14] Akiba T., Sano S., Yanase T., Ohta T., Koyama M. Optuna: A Next-Generation Hyperparameter Optimization Framework. Proc. KDD. 2019; 25:2623-2631.
[15] Grzes, M. Reward Shaping in Episodic Reinforcement Learning. AAMAS. 2017; 16:565-573.[16] Addy N., Wu H., Nishimura D. Magnetic Resonance in Medicine. 2011; 68(1):120-129.
[16] Harkins D., Does M. Efficient Gradient Waveform Measurements with Variable-Prephasing. J Magn. Reson. 2021; 327:106945.
[17] Addy N., Wu H., Nishimura D. Simple Method for MR Gradient System Characterization and k-space Trajectory Estimation. Magnetic Resonance in Medicine. 2011; 68(1):120-129.
Figures