3806
Impact of Different Techniques for Slice Annotation Reduction on U-Net-Based Thigh Muscle MR Images Segmentation1Istituto di Tecnologie Biomediche, Consiglio Nazionale delle Ricerche, Segrate, Italy, 2Dipartimento di Medicina Molecolare, Università degli Studi di Pavia, Pavia, Italy, 3UO Radiologia, Dipartimento Diagnostico, Scienze Radiologiche, Azienda Ospedaliero-Universitaria di Parma, Parma, Italy, 4Istituto di Sistemi e Tecnologie Industriali Intelligenti per il Manifatturiero Avanzato, Consiglio Nazionale delle Ricerche, Milano, Italy
Synopsis
Keywords: Other AI/ML, Segmentation, Supervised Deep Learning; Data Labeling
Motivation: Deep Learning (DL) for thigh muscle segmentation in MR images holds promise for musculoskeletal architectural assessment, however the process of generating annotated data in supervised approaches is time-consuming.
Goal(s): This study evaluates the impact of scarce annotated data on DL segmentation performance, investigating optimal annotation strategies of thigh muscle MR images.
Approach: Employing thigh MRIs from healthy subjects, the research compares the segmentation performance using various selection strategies and annotated data amount for training a U-Net.
Results: Results reveal high segmentation accuracy (Dice > 0.81) even with minimal annotations (3% of total labels), when selecting the most informative slices for annotation.
Impact: This research highlights the potential of significantly reducing the laborious task of annotating MR images for thigh muscle segmentation, while maintaining robust performance using DL. This efficiency enhancement could expedite the application of DL in muscle health assessment.
Introduction
The use of Deep Neural Networks (DNN) for the segmentation of thigh muscles in MR images holds great potential to assess musculoskeletal health, enabling the delineation of individual muscle bundles for quantitative measurements1. While supervised approaches have demonstrated effectiveness, they necessitate a substantial volume of annotated data for effective training. Typically, such data is generated by annotating each 2D slice within the acquired 3D volumes. However, the adjacent images in the axial position often contain redundant information due to the similarity of anatomical structures. To address the time-consuming nature of annotating all slices from the acquired volumes, it becomes essential to identify the most informative images for annotation. Implementing appropriate selection strategies can reduce the number of slices requiring annotation without significantly compromising segmentation performance2. This work aims to evaluate the optimal selection strategies, to reduce the number of annotated images when training a U-Net in thigh muscle segmentation.Methods
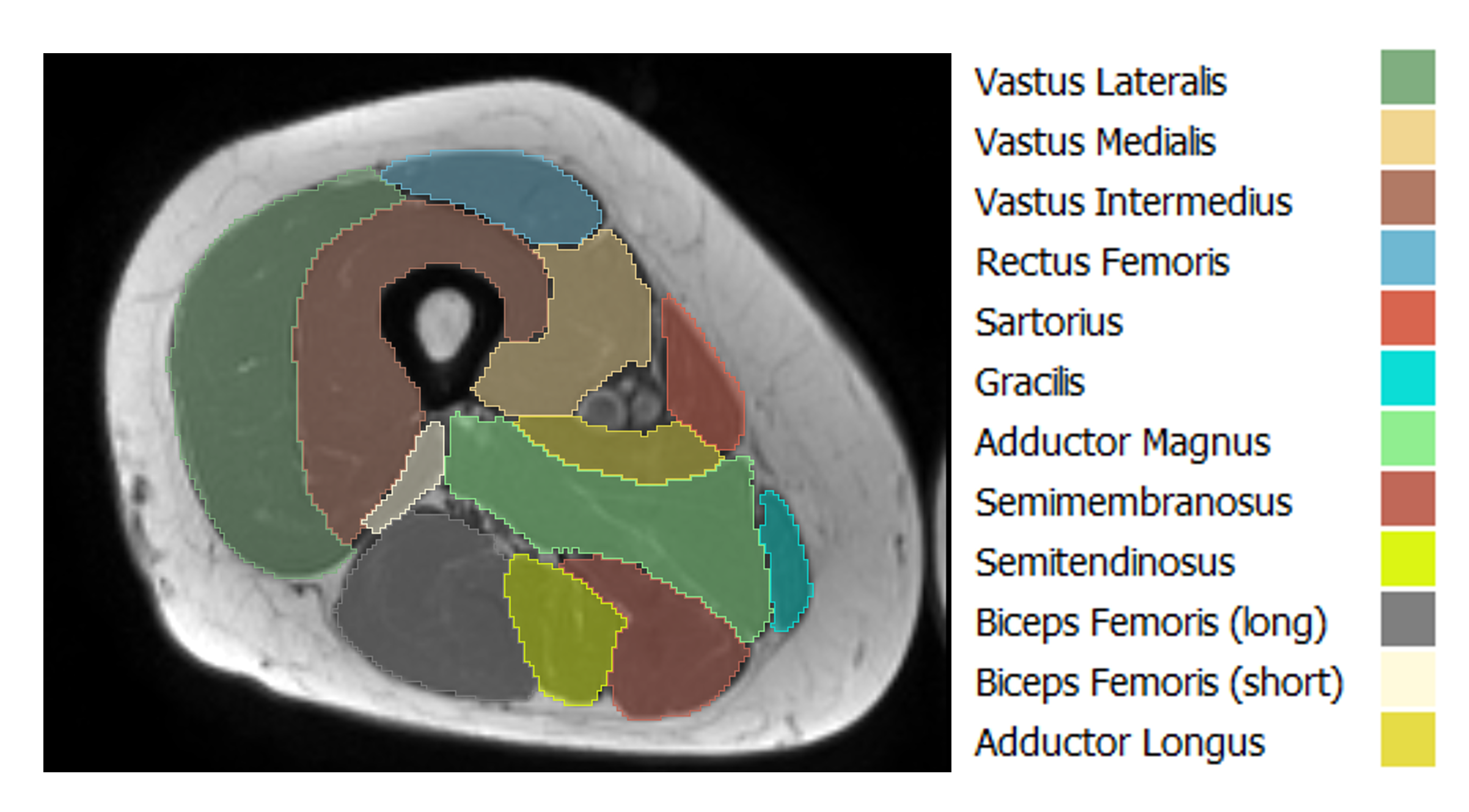
DatasetFifty-two healthy subjects (18 males, 34 females, age=66 ± 10 y) underwent thigh MRI using a T1-weighted turbo spin echo sequence on an MR Philips Healthcare 1.5T scanner. Reference manual segmentation of twelve thigh muscles was performed on each 2D axial slice in each volume (Fig.1), resulting in approximately 35 annotated slices per volume. Forty volumes were assigned for training and validation sets, while twelve volumes were reserved for the test set.
Slice selection
Various training sizes were employed by decreasing the number of annotated slices in the training set. Out of the forty volumes available, performances were compared using different percentages of the total number of annotated data, namely: 100%, 50%, 25%, 13%, 6%, 3%. These percentages correspond approximately to the number of annotated data contained in 40, 20, 10, 5, 2 and 1 subject(s), respectively. The training conducted with the complete set of annotated data served as the benchmark. The training/validation set was formed by randomly splitting the selected slices into an 80/20 ratio.
Selector strategies
Several selection strategies were compared to determine how experts should choose the most suitable images for annotation. These included:
- Random selection: Randomly selecting the required percentage of slices.
- Keepn: Selecting every nth slice from each volume for annotation (e.g., every 2 slices for 50% training, every 4 for 25%, etc.).
- K-means clustering: Applying the k-means algorithm using as input the slices flattened into a vector of pixel intensities, choosing k = 10. A fixed number of slices were randomly selected from each cluster to obtain the desired number of annotated data.
- Full patient selection: Annotating all the slices contained from randomly chosen volumes (e.g., 1 volume for 3%, 2 for 6%, etc.).
The architecture chosen is a U-Net with ResNet-503 backbone, with the 2D MR image as input, and the segmentation mask of the twelve muscles as output. Every network was trained for 80 epochs using a batch size of 8, Adam optimizer with learning rate of 6.6·10-4, and a combined Dice-Focal loss function. 5-fold cross validation strategy was adopted. The study utilized the Keras framework with TensorFlow backend and a NVIDIA GeForce RTX 3070 Ti GPU.
Evaluation metrics
The segmentation results were evaluated on the test set predicted masks using the Dice similarity coefficient and the Average Symmetric Surface Distance (ASSD).
Results
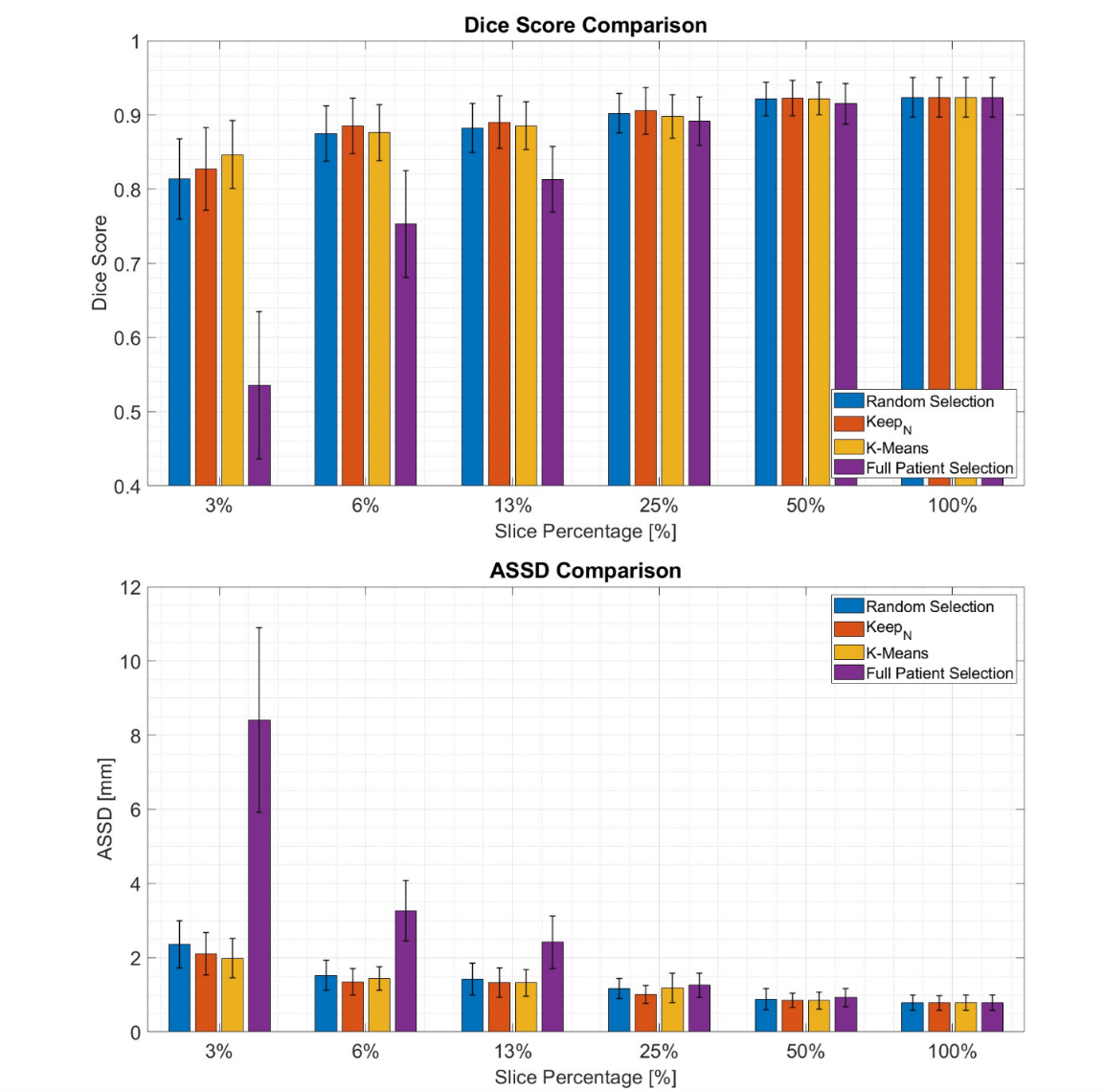
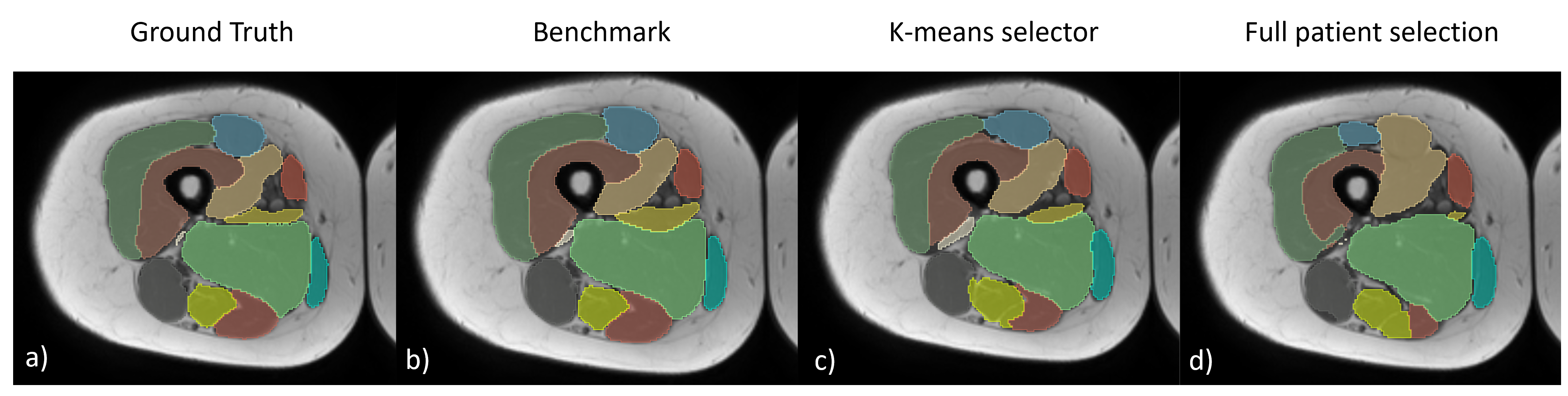
As shown in Fig.2, the DNN achieved high mean Dice scores (> 0.81) even with the lowest number of annotations tested (3%) for all selectors strategies adopted, except from full patient selection (Fig.3). In the 3% case, when utilizing a selector such as K-means, the performance drop for the Dice score was only 8% compared to the benchmark (Dice=0.847 ± 0.046 vs 0.924 ± 0.027). K-means and Keepn provided the best results across all the percentages tested. Full patient selection was found to be the worst strategy in all cases.Discussion
The study demonstrates that using a U-Net for muscle thigh segmentation can yield good results using a very limited number annotated data. Given the redundancy of information in adjacent axial thigh images, it is more effective to select a few slices from all acquired subjects, rather than segmenting all the slices from a limited number of subjects to reduce annotation time. Using a K-means clustering algorithm proved to be beneficial when selecting a minimal number of slices to annotate (3%).Conclusion
The results highlight the possibility of achieving robust segmentation performance with a reduced number of annotated slices, selected using appropriate strategies. This approach demonstrates the potential for a more efficient annotation process when using DNN for image segmentation tasks.Acknowledgements
This study was supported and funded by the Italian Ministry of University and Research, grant protocol number 20202020477RW5, PRIN (PROGETTI DI RICERCA DI RILEVANTE INTERESSE NAZIONALE), Bando 2020.References
1. Engelke, K. et al. Magnetic resonance imaging techniques for the quantitative analysis of skeletal muscle: State of the art. Journal of Orthopaedic Translation. 2023; 42: 57–72.
2. Payer, T., Nizamani, F., Beer, M., Götz, M. & Ropinski, T. Medical volume segmentation by overfitting sparsely annotated data. Journal of Medical Imaging. 2023; 10(4):044007.
3. He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016; pp. 770-778.
Figures