3768
An Inpainting-based Method for MRI Synthesis1SubtleMedical, Shanghai, China, 2SubtleMedical, Menlo Park, CA, United States, 3Institute of Diagnostic and Interventional Radiology, Shanghai Sixth People's Hospital Affiliated to Shanghai Jiao Tong University School of Medicine, Shanghai, China, 4Department of Radiology Intervention, Shanghai Sixth People's Hospital Affiliated to Shanghai Jiao Tong University School of Medicine, Shanghai, China
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence, Image Synthesis, Inpainting-based
Motivation: The existing deep learning-based MRI sequence synthesis methods are prone to obscure or simulate pathology.
Goal(s): To develop an inpainting-based image synthesis network (IBSNet) for MRI sequence high-fidelity synthesis.
Approach: We designed a dual-branch structure to focus on global and local information extraction. Moreover, a joint loss is proposed to constrain the network from signal intensity, structural similarity, and edge preservation. An attention module is used to refine the intermediate feature maps from both the channel and spatial dimensions.
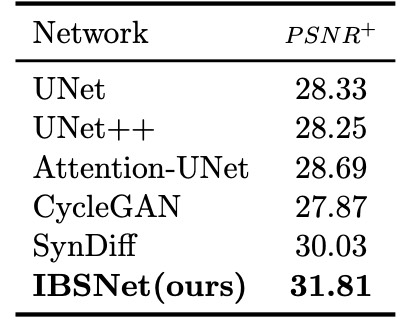
Results: The results show that our method outperforms other methods based on the encoder-decoder network, generative adversarial network (GAN), and diffusion model.
Impact: Our proposed inpainting-based image synthesis network can generate the target sequence from existing sequences, which can reduce the scanning time of MRIs and improve the patient experience.
Introduction
Deep learning-based image synthesis methods use CNNs for end-to-end learning of the non-linear mapping between the source and target images, showing higher accuracy than other methods. The deep encoder-decoder network cannot synthesize high-frequency components, so the output image is blurred. GANs are sensitive to data distribution and are prone to generating fabricated features, resulting in misdiagnoses. In addition, the diffusion models have the problems of long iteration sampling time and low efficiency. We propose an inpainting-based network for high-fidelity image synthesis to address the above issues.Materials and Method
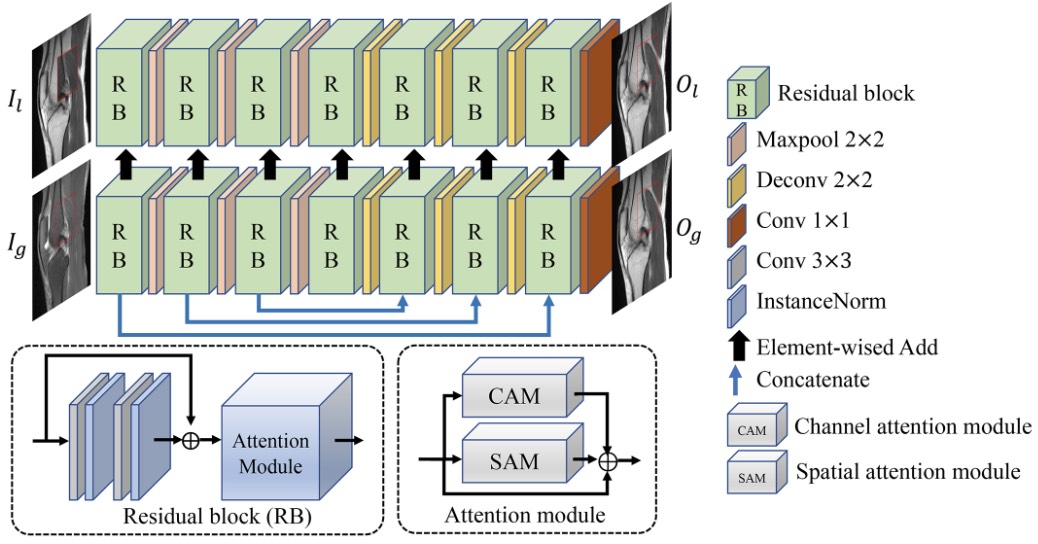
The proposed method is trained and validated on ten patients’ knee MRIs, with sagittal T2 FS series as the source and sagittal PD series as the target.Inpainting-based Image Synthesis Convolution Network. As shown in Figure 1, IBSNet has two branches, i.e., local branch (LB) and global branch (GB). Image inpainting fills missing regions with plausible alternative contents originating from existing regions. Inspired by it, when training, we randomly selected patches on the source image as missing holes and replaced other regions with the corresponding content of the target image as input to LB. The LB focuses on restoring local information, which is less prone to visual artifacts and color differences because the value of missing holes is another expression of target content than invalid values. Denote the paired source and target images as $$$I_{source}$$$ and $$$I_{target}$$$. We generate the input of the LB and GB according to the following formulas,
$$I_{l} = I_{source}*I_{mask}+I_{target}*(1-I_{mask}), I_{g} = I_{source}$$
where $$$I_{mask}$$$ is the mask and the size is the same as $$$I_{source}$$$ and $$$I_{target}$$$, with value 1 representing the missing hole (drawn in red in Figure 1 and value 0 representing the other regions. During inference, set $$$I_{mask}$$$ to all 1; in this way, $$$I_{l}$$$ and $$$I_{g}$$$ are the same source image. GB contributes global structural semantic information to LB. Local and global semantic information drove the boundaries of recovery holes to be more continuous.
Joint loss. Structural Similarity($$$SSIM$$$) and $$$l1$$$ loss are commonly used for image generation; the former is effective in constructing structure information, while the latter is to ensure signal intensity consistency. However, the network's output under these two constraints is still blurred, has low resolution, and lacks visual clarity. To solve this problem, we propose edge loss to boost the network by reconstructing clearer edge information while learning Gaussian noise that makes images look more realistic. The edge loss is calculated by,
$$\mathcal{L}_{edge} = |O_{g}-f(O_{g}), I_{target}-f(I_{target})|$$
Where $$$f$$$ is the Gaussian filtering function and $$$O_{g}$$$ is the output of GB. It is noted that for LB, we only calculate the loss of missing holes. In summary, the joint loss is denoted as,
$$L = \lambda_{1}\mathcal{L}_{ssim}+\lambda_{2}\mathcal{L}_{l1}+\lambda_{3}\mathcal{L}_{edge}$$
Attention module. CBAM is a plug-and-play attention module that refines feature maps at the channel and spatial dimensions; it increases performance without bringing significant complexity. However, its spatial attention generated from aggregated feature maps of channel information failed to learn the relationship between distant pixels. In this work, we replaced the spatial attention module of CBAM with strip pooling, which uses long and narrow kernels of $$$1\times{N}$$$ and $$$N\times1$$$ to learn significant information at the spatial dimension of feature maps. Strip pooling enables backbone networks to model long-term dependencies effectively and contributes to the overall recovery of skeletal structure in MRI. To make the training easy, the refined feature maps are fused into the main branch in the form of residuals.
Results and Conclusion
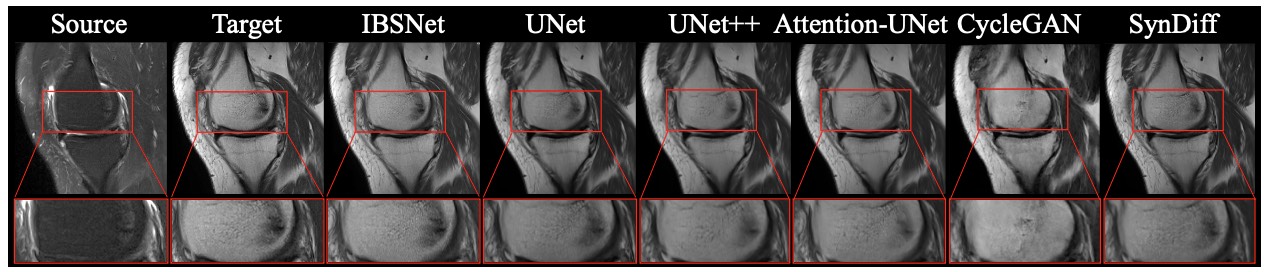
We performed ablation experiments using the IBSNet without attention module and joint loss as the baseline. As shown in Table 1, CAM and SAM bring performance improvement of 1.62 and 1.13, respectively, while simultaneous use will bring that of 1.79. When introducing the edge loss constraint to the network, i.e., using joint loss, the network performance increased by 1.44 over baseline. Ultimately, IBSNet integrated with the attention module and joint loss performs best, improved by 16% over the baseline. As shown in Table 2, IBSNet outperforms the other five methods in detail restoration and syntheses more realistic results (as shown in Figure 2). In summary, we developed a high-fidelity medical image synthesis network (IBSNet) using an inpainting-based method. The attention module and joint loss in IBSNet make it perform excellently and have a high application prospect.Acknowledgements
No acknowledgement found.References
- Qibin Hou, Li Zhang, Ming-Ming Cheng, and Jiashi Feng. Strip pooling: Rethinking spatialpooling for scene parsing. In Proceedings of the IEEE/CVF conference on computer visionand pattern recognition, pages 4003–4012, 2020.
- Muzaffer ̈Ozbey, Salman UH Dar, Hasan A Bedel, Onat Dalmaz, S ̧aban ̈Ozturk, AlperG ̈ung ̈or, and Tolga C ̧ ukur. Unsupervised medical image translation with adversarial diffusion models. arXiv preprint arXiv:2207.08208, 2022.3
- Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-AssistedIntervention–MICCAI 2015: 18th International Conference, Munich, Germany, October5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on Computer Vision, pages 2223–2232, 2017.4
Figures