3762
Synthesizing multiple realistic MR phase images using a multi-modal generative model1Radiology and Biomedical Imaging, University of California, San Francisco, San Francisco, CA, United States, 2Electrical Engineering and Computer Science, University of California, Berkeley, Berkeley, CA, United States
Synopsis
Keywords: Synthetic MR, Machine Learning/Artificial Intelligence
Motivation: Deep learning MRI reconstruction methods face challenges in available datasets to train models. Clinical scans can be a source for diverse data but a challenge is obtaining MRI phase.
Goal(s): We propose a method to generate multiple plausible synthetic phase images from a single magnitude-only input.
Approach: We train a multi-modal generative model enforcing consistency in the latent space during training. We evaluate the effect of latent vector dimension on diversity and quality of the synthetic images with FID score and training image reconstruction models with this synthetic data.
Results: Higher latent vector dimension resulted in more diverse and higher quality synthetic images.
Impact: This method could be used to generate multiple plausible phase images from a single scan to model effects of varying field homogeneity, RF coils, echo time, motion, flow, and susceptibility
Introduction
Clinical scans offer several advantages in creating MRI datasets used in deep learning MRI reconstruction, however they typically don't retain the raw k-space. One major challenge is obtaining MRI phase, as only magnitude images are typically saved and used for clinical assessment and diagnosis. Our prior work1 addressed synthetic phase generation using a one-to-one image translation model2 but resulted in blocking artifacts. Since MRI phase varies inherently for the same magnitude information, it would be advantageous to generate multiple plausible phase images from a single magnitude image to generate samples that include effects of varying field homogeneity, RF coils, echo time, motion3, flow4,5 and susceptibility6.Here, we present an approach to generate multiple plausible realistic synthetic phase images from a single magnitude input. We use a multi-modal generative model and asses the effect of the dimensionality of the latent vector, which encodes ground truth phase images during training, on the diversity and quality of generated phase images. We evaluate our synthetic data using a standard generative model metric and by evaluating the performance of image reconstruction models trained using this synthetic data.
Methods
DatasetWe used data (40762 training, 8890 test) from the Stanford SKM-TEA Dataset7 consisting of raw k-space with corresponding magnitude images. The images were acquired using a 3DqDESS GRE sequence.
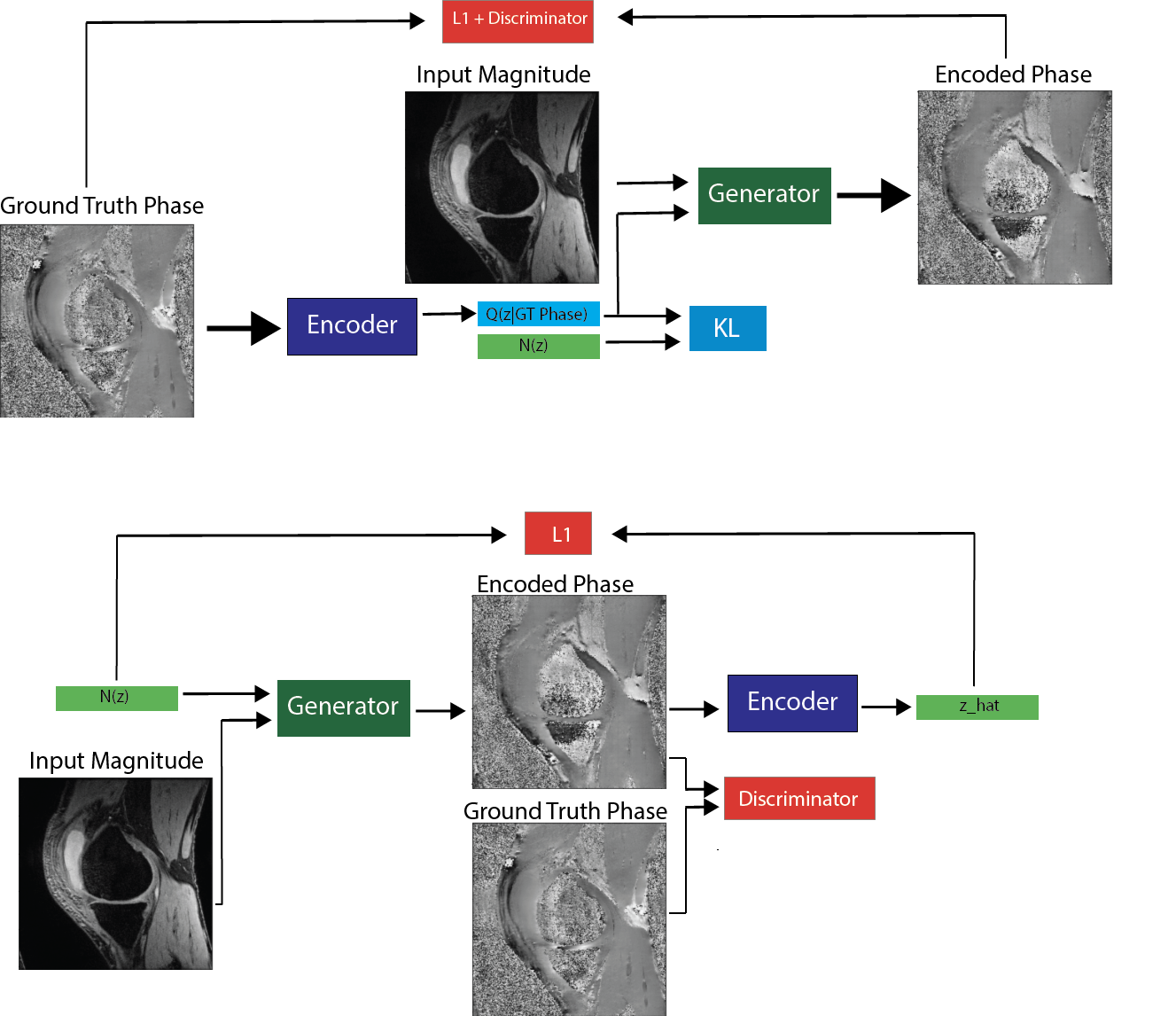
We trained a BicycleGAN8 which enforces consistency in the latent space and consists of two different GAN architectures. The first, cVAE-GAN consists of 3 losses functions and encodes the ground truth phase image to a latent code z and then reconstructs a plausible synthetic phase. The second, cLR-GAN, consists of 2 loss functions and generates a plausible phase image conditioned on the input magnitude image and an input random noise vector to reconstruct the latent vector.
$$ G^{*}, E^{*} = \mathcal{L}^{VAE}_{GAN}(G,D,E) + \mathcal{L}^{VAE}_{1}(G,E) + \mathcal{L}^{cLR}_{GAN}(G,D) + \lambda_{latent}\mathcal{L}^{latent}_{1}(G,E) + \lambda_{KL}\mathcal{L}_{KL}(E) $$
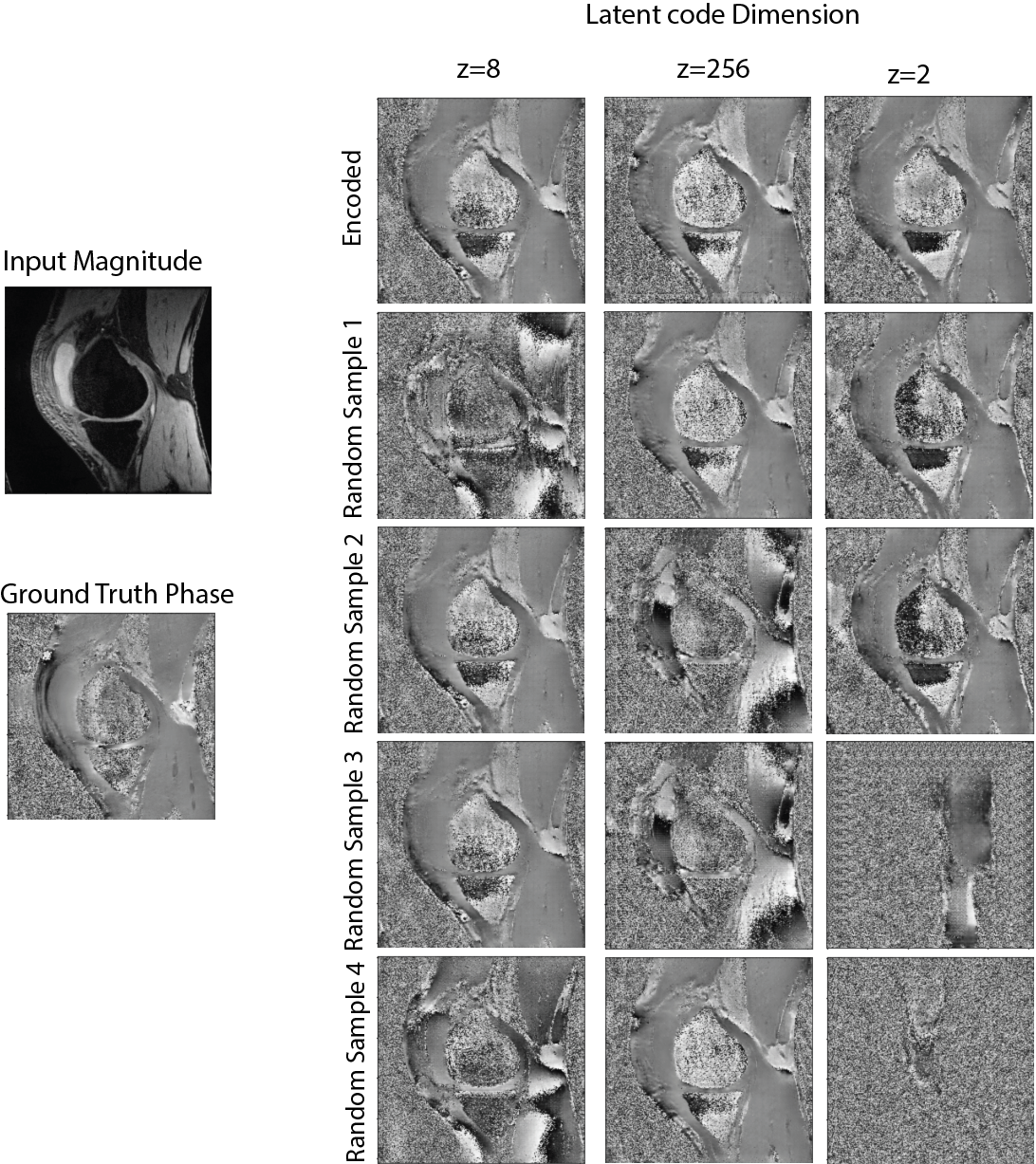
Three different BicycleGAN models were trained to assess the effect of the dimension of the latent code on the diversity and quality of the synthetic phase images. An encoded phase image and 4 random sample images derived from each trained latent vector were generated for each input magnitude image.
Evaluation
We first compared the distribution of generated images with ground truth images using the Frechet Inception Distance (FID)9:
$$ d^{2}((m_{r}, C_{r}), (m_{s}, C_{s})) = ||m_{r} - m_{s}||^{2}_{2} + Tr(C_{r} + C_{s} - 2(C_{r}C_{s})^{1/2})$$
where $$$(m_{r},C_{r})$$$, correspond to the mean and covariance of real (ground truth images) respectively and $$$(m_{s},C_{s})$$$ correspond to the mean and covariance of synthetic images respectively
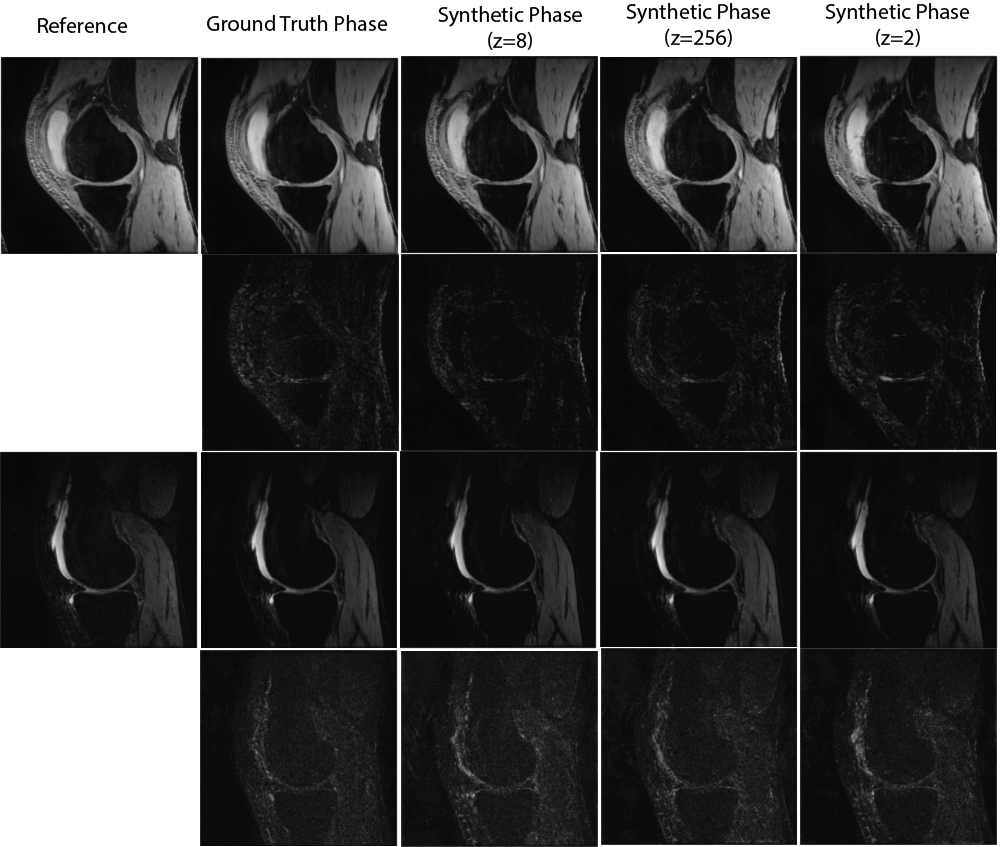
We then evaluated the utility of the generated synthetic phase images by combining them with the corresponding input magnitude images and sensitivity maps derived via SENSE10 to generate synthetic multi-coil k-space. Synthetic, and ground-truth k-space were undersampled at R = {4,8} acceleration factors and used to train Variational Network11 image reconstruction models to assess performance of synthetic phase used as training data.
Results and Discussion
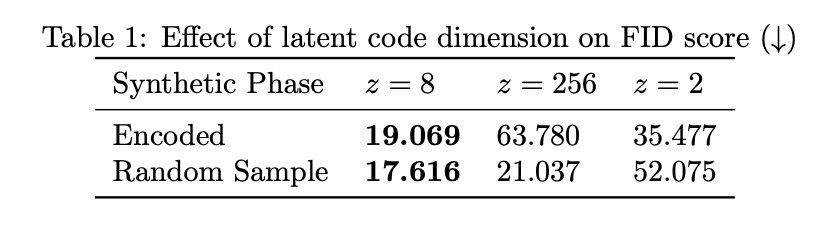
From Figure 2, phase images generated from models with a higher z value show more diversity and consistency with the ground truth phase image. Models trained at z=2 show some errors in consistency with structure of the knee absent from some synthetic phase images. The notable features of these phase images include appropriate phase noise levels, appearance of phase shifts between fat and water, and spatially appropriate phase wrapping patterns (e.g. no singularities and all phase jumps appear to be 2π). The random samples illustrate capturing of phase patterns that approximately match the phase from first and second TE data in this dataset.From Table 1, both the encoded and random sample phase images, with latent vector z=8 shows the lowest FID score. A latent code with z=256 dimensions shows a worse score for the encoded phase but a much better score from synthetic phase images sampled from the latent vector. A latent vector with z=2 shows higher FID score in the random sample pool suggesting the low dimension is not able to cover the diversity in the training set.
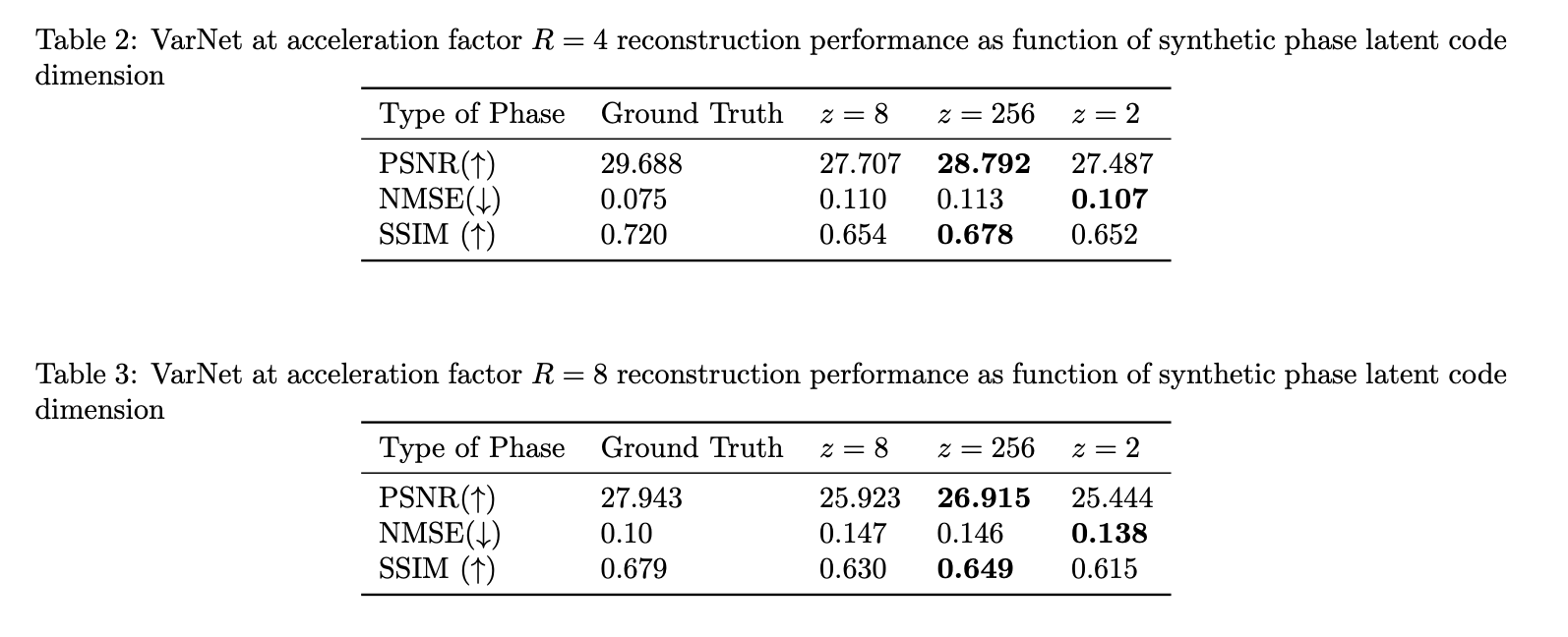
From Figure 3 and Table 2, VarNet trained on synthetic data derived from a latent code z=256 performed slightly better in PSNR and SSIM compared to models trained on synthetic data derived from latent codes z = {2,8} however the performance for all models was relatively similar. Visually there are no obvious artifacts in either methods.
Conclusion
Our results suggest that enforcing consistency in the latent space during training followed by sampling from this latent space at test time can generate multiple plausible and diverse synthetic phase images relative to the ground truth and strong performance for training VarNet.Acknowledgements
No acknowledgement found.References
[1] Nikhil Deveshwar, Abhejit Rajagopal, Sule Sahin, Efrat Shimron, and Peder E. Z. Larson. Synthesizing complex-valued multicoil MRI data from magnitude-only images. Bioengineering, 10(3):358, March 2023.
[2] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, July 2017.
[3] F Godenschweger, U K ̈agebein, D Stucht, U Yarach, A Sciarra, R Yakupov, F Lu ̈sebrink, P Schulze, and O Speck. Motion correction in MRI of the brain. Physics in Medicine and Biology, 61(5):R32–R56, February 2016.
[4] Michael Markl, Frandics P. Chan, Marcus T. Alley, Kris L. Wedding, Mary T. Draney, Chris J. Elkins, David W. Parker, Ryan Wicker, Charles A. Taylor, Robert J. Herfkens, and Norbert J. Pelc. Time-resolved three-dimensional phase-contrast MRI. Journal of Magnetic Resonance Imaging, 17(4):499–506, March 2003.
[5] Michael Markl, Alex Frydrychowicz, Sebastian Kozerke, Mike Hope, and Oliver Wieben. 4d flow MRI. Journal of Magnetic Resonance Imaging, 36(5):1015–1036, October 2012.
[6] Chunlei Liu, Hongjiang Wei, Nan-Jie Gong, Matthew Cronin, Russel Dibb, and Kyle Decker. Quantitative susceptibility mapping: Contrast mechanisms and clinical applications. Tomography, 1(1):3–17, September 2015.
[7] Arjun D Desai, Andrew M Schmidt, Elka B Rubin, Christopher Michael Sandino, Marianne Susan Black, Valentina Mazzoli, Kathryn J Stevens, Robert Boutin, Christopher Re, Garry E Gold, et al. SKM-TEA: A dataset for accelerated MRI reconstruction with dense image labels for quantitative clinical evaluation. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
[8] Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A Efros, Oliver Wang, and Eli Shecht- man. Toward multimodal image-to-image translation. In Advances in Neural Information Processing Systems, 2017.
[9] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
[10] Klaas P. Pruessmann, Markus Weiger, Markus B. Scheidegger, and Peter Boesiger. SENSE: Sensitivity en- coding for fast MRI. Magnetic Resonance in Medicine, 42(5):952–962, November 1999.
[11] Anuroop Sriram, Jure Zbontar, Tullie Murrell, Aaron Defazio, C. Lawrence Zitnick, Nafissa Yakubova, Florian Knoll, and Patricia Johnson. End-to-end variational networks for accelerated MRI reconstruction. In Medical Image Computing and Computer Assisted Intervention – MICCAI 2020, pages 64–73. Springer International Publishing, 2020.
Figures