3661
3D deep-learning image reconstruction for fast spin-echo triple-echo Dixon images acquired with flexible echo-spacing (FTED-Flex)1Department of Imaging Physics, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 2Department of Breast Imaging, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 3Department of Breast Surgical Oncology, The University of Texas MD Anderson Cancer Center, Houston, TX, United States
Synopsis
Keywords: Fat & Fat/Water Separation, Fat, Deep Learning, 3D Convolutional Neural Network
Motivation: The fast spin-echo triple-echo Dixon images acquired with flexible echo-spacing (FTED-Flex) can be used to generate separated water and fat images with enhanced T2-weighted contrast. However, their performance and clinical applications are limited by its long image reconstruction time.
Goal(s): Our goal is to develop a fast and accurate FTED-Flex image reconstruction method.
Approach: The time-consuming phase estimation was replaced by a 3D deep-learning neural network.
Results: The FTED-Flex integrated with a 3D deep-learning network was highly accurate (average Dice coefficient in volume-of-interest=0.989) and reduced the processing time for phase-estimation to a few seconds, compared to tens of minutes by conventional methods.
Impact: The developed FTED-Flex integrated with a 3D deep-learning network is highly accurate and reduces the processing time for phase-estimation to a few seconds, thus it has a great potential to expand clinical applications of FTED-Flex imaging.
INTRODUCTION
$$$\>\>\>\>$$$The fast spin-echo triple-echo Dixon imaging with flexible echo-spacing (FTED-Flex)1 is a scan-efficient and clinically useful Dixon imaging technique that acquires three sets of raw images for Dixon processing in a single scan. Separating water and fat signals requires voxel-by-voxel background phase estimation, which requires long image reconstruction time and large sizes of hardware memory2. In this work, we propose a fast and accurate FTED-Flex image reconstruction method replacing the time-consuming background phase estimation with a 3D deep-learning network.METHODS
$$$\>\>\>\>$$$A 3D deep-learning network was integrated with FTED-Flex image reconstruction to perform water $$$(W)$$$ and fat $$$(F)$$$ separation in four stages:1. Network Training
$$$\>\>\>\>$$$FTED-Flex images $$$(S_{1}=(W+Fe^{-j\omega})e^{j(\phi+\theta_{1})},$$$ $$$S_{2}=(W+F)e^{j\phi},$$$ $$$and$$$ $$$S_{3}=(W+Fe^{j\omega})e^{j(\phi+\theta_{2})}$$$ $$$where$$$ $$$e^{j\theta_{1}},$$$ $$$e^{j\theta_{2}},$$$ $$$and$$$ $$$e^{j\phi}$$$ $$$are$$$ $$$background$$$ $$$phases)$$$ were acquired with flexible echo-spacing, then used to calculate two sets of possible solution pairs $$$\left\{e^{j\theta_{1a}},e^{j\theta_{2a}}\right\}$$$ and $$$\left\{e^{j\theta_{1b}},e^{j\theta_{2b}}\right\}$$$ for the $$$e^{j\theta_{1}}$$$ and $$$e^{j\theta_{2}}$$$ estimates1 (Fig.1 and Fig.3). Between two sets of solution estimates, only one set is the true solution for $$$e^{j\theta_{1}}$$$ and $$$e^{j\theta_{2}}.$$$ In this work, the ground-truth of $$$e^{j\theta_{1}}$$$ and $$$e^{j\theta_{2}}$$$ was found with the jointly processing 3D region-growing algorithm1 assuming each voxel is either water-dominant or fat-dominant commonly for all three echo signals. Then, a 3D U-Net3,4 was trained with multislice $$$S_{1},$$$ $$$S_{2}$$$ and $$$S_{3}$$$ images to generate a 3D binary map as the network output which was semantically segmented as either “0” or “1” depending on which set is the true solution between two possible solution pairs.
2. Background Phase Estimation
$$$\>\>\>\>$$$After training, a 3D binary map was generated directly from independent test images, then $$$e^{j\theta_{1}}$$$ and $$$e^{j\theta_{2}}$$$ were reconstructed by replacing the 3D binary map with corresponding true solution pairs which are either $$$\left\{e^{j\theta_{1a}},e^{j\theta_{2a}}\right\}$$$ for “0” or $$$\left\{e^{j\theta_{1b}},e^{j\theta_{2b}}\right\}$$$ for “1” for each voxel (Fig.2 and Fig.4(a)).
3. Removal of Background Phases
$$$\>\>\>\>$$$The background phase $$$(e^{j\phi})$$$ of the 2nd echo signal $$$(S_{2})$$$ was eliminated from all three echo signals first, then followed by removing the estimated $$$e^{j\theta_{1}}$$$ and $$$e^{j\theta_{2}}$$$ from $$$S_{1}$$$ and $$$S_{3}$$$ (Fig.2).
4. The Final Water and Fat Separation
$$$\>\>\>\>$$$After eliminating background phases from $$$S_{1},S_{2}$$$ and $$$S_{3},$$$ only chemical-shift induced image phases $$$(\omega)$$$ remain in three echo signals $$$(S^{'}_{1}=W+Fe^{-j\omega},$$$ $$$S^{'}_{2}=W+F,$$$ and $$$S^{'}_{3}=W+Fe^{j\omega}).$$$ Once $$$\omega$$$ was calculated with the selected three echo-spacings (TE1/TE2/TE3) using a multi-peak signal model5,6, multislice water images $$$(W)$$$ and fat images $$$(F)$$$ were generated (Fig.2 and Fig.4(b)).
RESULTS
$$$\>\>\>\>$$$1,500 sets of multislice FTED-Flex images were acquired from triple-negative breast cancer (TNBC) patients on 3T whole-body scanners (GE Healthcare,Waukesha,WI,USA) with an 8 or 16 channel phased array breast coil. FTED-Flex scan parameters of Fig.3 and Fig.4 were FOV=32cm×32cm×22.4cm, NFE×NPE×Nss=352×352×56, Nx×Ny×Nslice=512×512×56, slice-thickness/slice-gap=4/0mm, TR=7.9secs, TE1/TE2/TE3=82.608/84.000/85.392ms, RBW=$$$\pm$$$200kHz, ETL=16, and scan-time=1:43min. They were randomly split into three groups: 1,450 sets for training (80%) and validation (20%) with 5 folds, and 50 sets for independent testing. We trained the 3D network with one Tesla V100 32GB GPU on a DGX-1 system (NVIDIA,Santa Clara,CA,USA) to learn 32 volumetric features for 1,000 epochs with the batch-size of 2.$$$\>\>\>\>$$$The performance of the network was evaluated with Dice coefficient (DI) between 3D binary maps from 50 patients in the test dataset and ground-truth (Fig.4(a) and Fig.5(a)). When background noise regions (smaller than 5% of the maximum intensity) were excluded as defined masks (Fig.4(a)), the network was able to reconstruct accurate binary maps with median DI=0.990 and average DI=0.989. The DI for the entire 3D maps was median DI=0.888 and average DI=0.884, respectively. The 3D binary map generated by the network was used to separate water and fat images (Fig.4(b)). Compared to the ground-truth, the 3D network reconstructed water images with median NRMSE (normalized root mean squared error)=0.00591 and average NRMSE=0.00870. The median NRMSE and average NRMSE of separated fat images were 0.00037 and 0.00048, respectively (Fig.5(b)). In the image reconstruction with 50 testing datasets, the developed 3D network estimated background phases only in 1.8~2.3 seconds with a laptop computer without using GPU memory (Intel 10-core i7-1265U 1.8GHz CPU and 16GB DDR4 memory) compared to 10~20 minutes of conventional method1 (two Intel 16-core Xeon Silver 4215 2.5GHz CPUs, 128GB DDR4 memory, and NVIDIA Quadro RTX4000 8GB GPU).
DISCUSSION
$$$\>\>\>\>$$$In this work, we verified that the 3D network can be successfully integrated with FTED-Flex image reconstruction to replace time-consuming phase estimating process while separating water and fat images with high fidelity. Once the training is complete, the voxel-by-voxel phase estimation for the entire imaging volume does not require large system memory and any GPU memory. The phase estimation with the 3D network takes only a few seconds, compared to tens of minutes by the conventional voxel-by-voxel method.Acknowledgements
No acknowledgement found.References
1. Son JB, Hwang KP, Madewell JE, Bayram E, Hazle JD, Low RN, and Ma J. A flexible fast spin echo triple-echo Dixon technique. Magn Reson in Med. 2017;77:1049-1057.
2. Son JB, Hwang KP, Scoggins ME, Dogan BE, Rauch GM, Pagel MD and Ma J. Water and fat separation with a Dixon conditional generative adversarial network (DixonCGAN). In Proc of the 28th Annual Meeting of Intl Soc Mag Reson Med, 2020. (Abstract 823)
3. Çiçek Ö, Abdulkadir A, Lienkamp SS, Brox T, and Ronneberger O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. Med Image Comput Comput Assist Interv. 2016:424-432.
4. Isensee F, Jaeger PF, Kohl, SA, Petersen J, and Maier-Hein KH. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods. 2021;18(2):203-211.
5. Eggers H, Brendel B, Duijndam A, and Herigault G. Dual-echo Dixon imaging with flexible choice of echo times. Magn Reson Med 2011;65:96-107.
6. Yu H, Shimakawa A, McKenzie CA, Brodsky E, Brittain JH, and Reeder SB. Multiecho water-fat separation and simultaneous R2* estimation with multifrequency fat spectrum modeling. Magn Reson Med 2008;60:1122–1134.
Figures
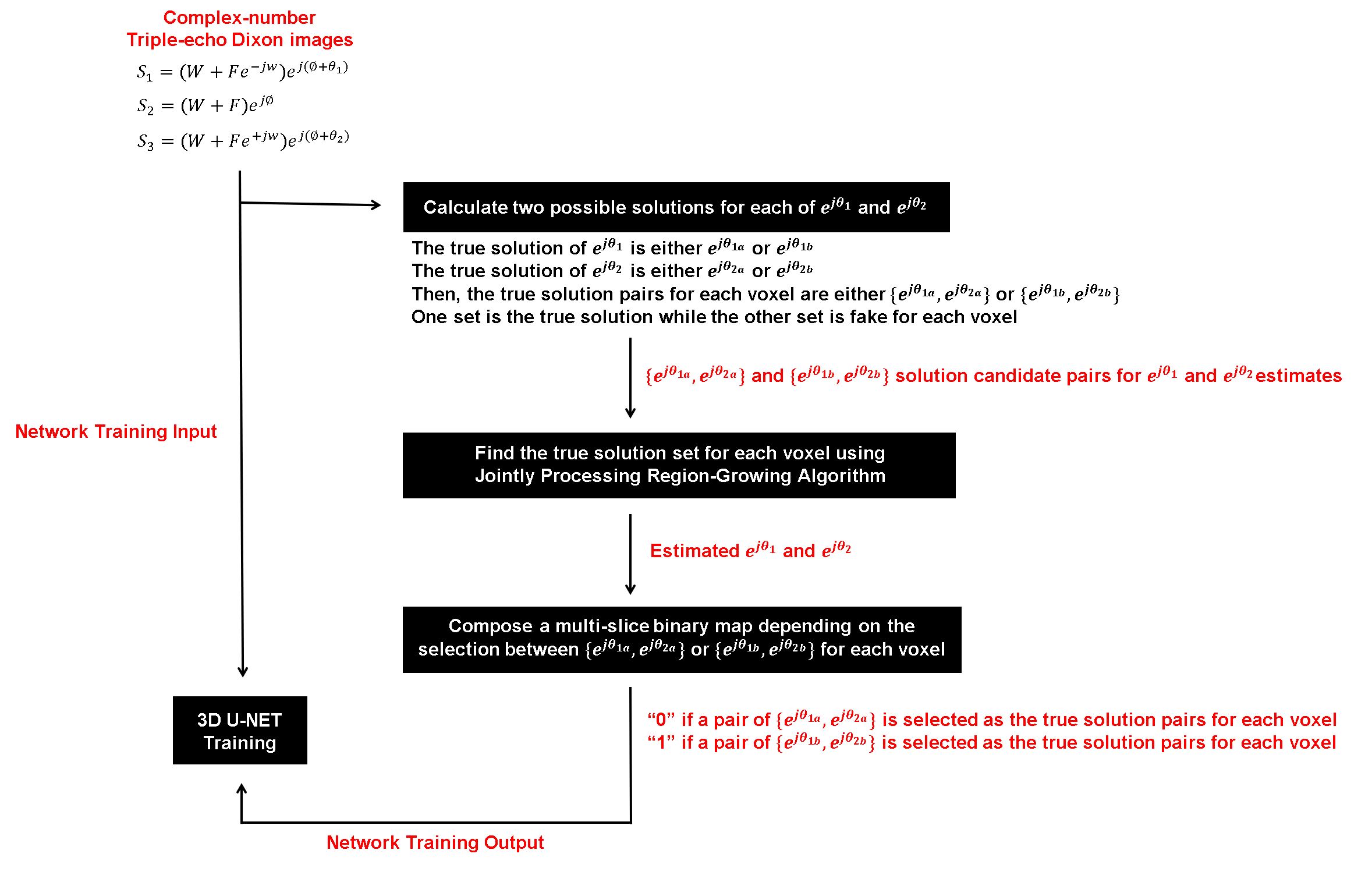
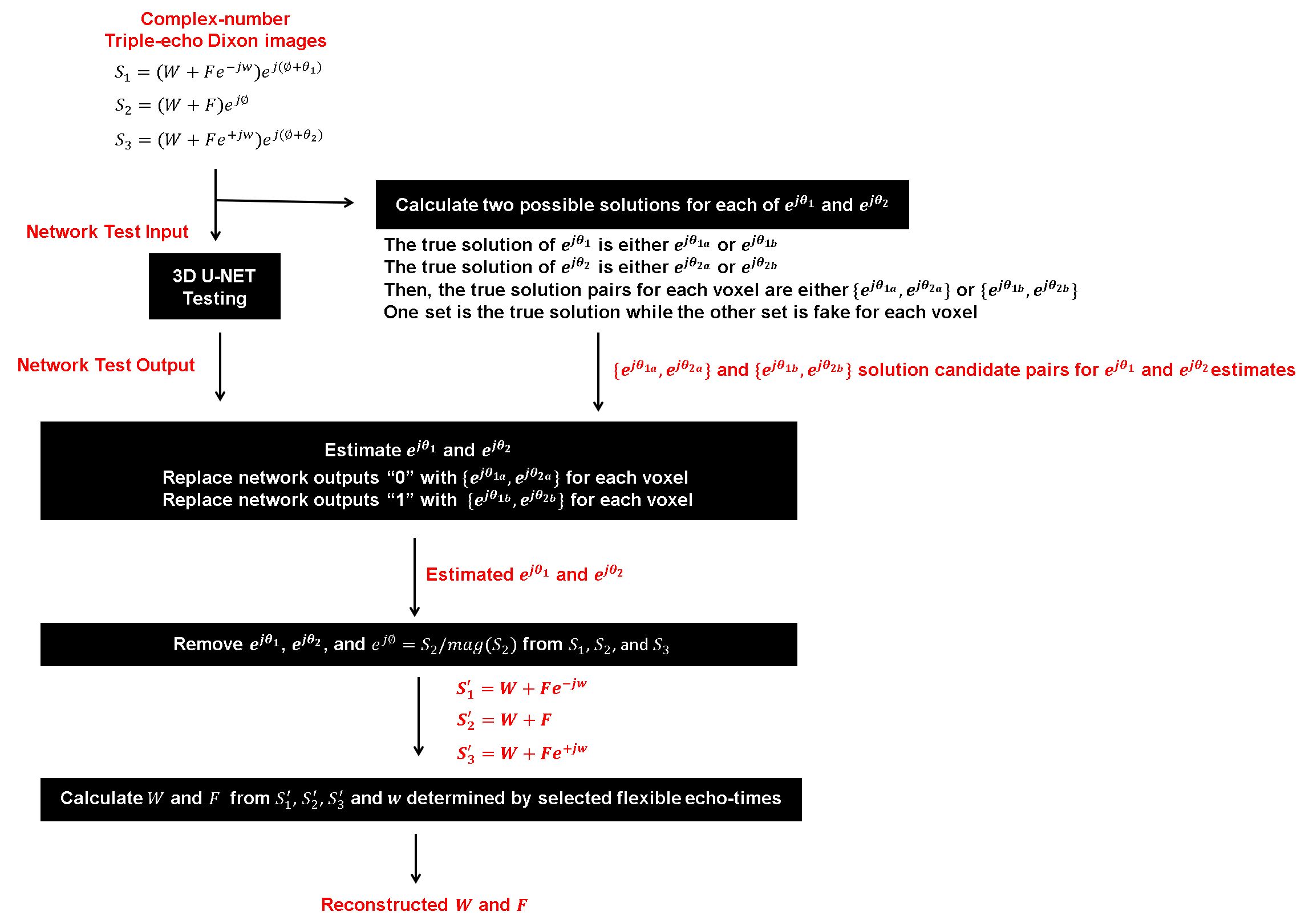

Figure 3. (a) 1450 training and validation sets of FTED-Flex images were scanned, (b) then used to calculate two sets of possible solution pairs {ejθ1a,ejθ2a} and {ejθ1b,ejθ2b} for the ejθ1 and ejθ2 estimates. Between them, only one set is the true solution. (c) Voxel-by-voxel ground-truth of ejθ1 and ejθ2 was found with the jointly processing 3D region-growing algorithm. (d) Then, a 3D U-Net was trained to generate a 3D binary map as the network output which was semantically segmented as either “0” or “1” depending on which set is true solution between {ejθ1a,ejθ2a} and {ejθ1b,ejθ2b}.
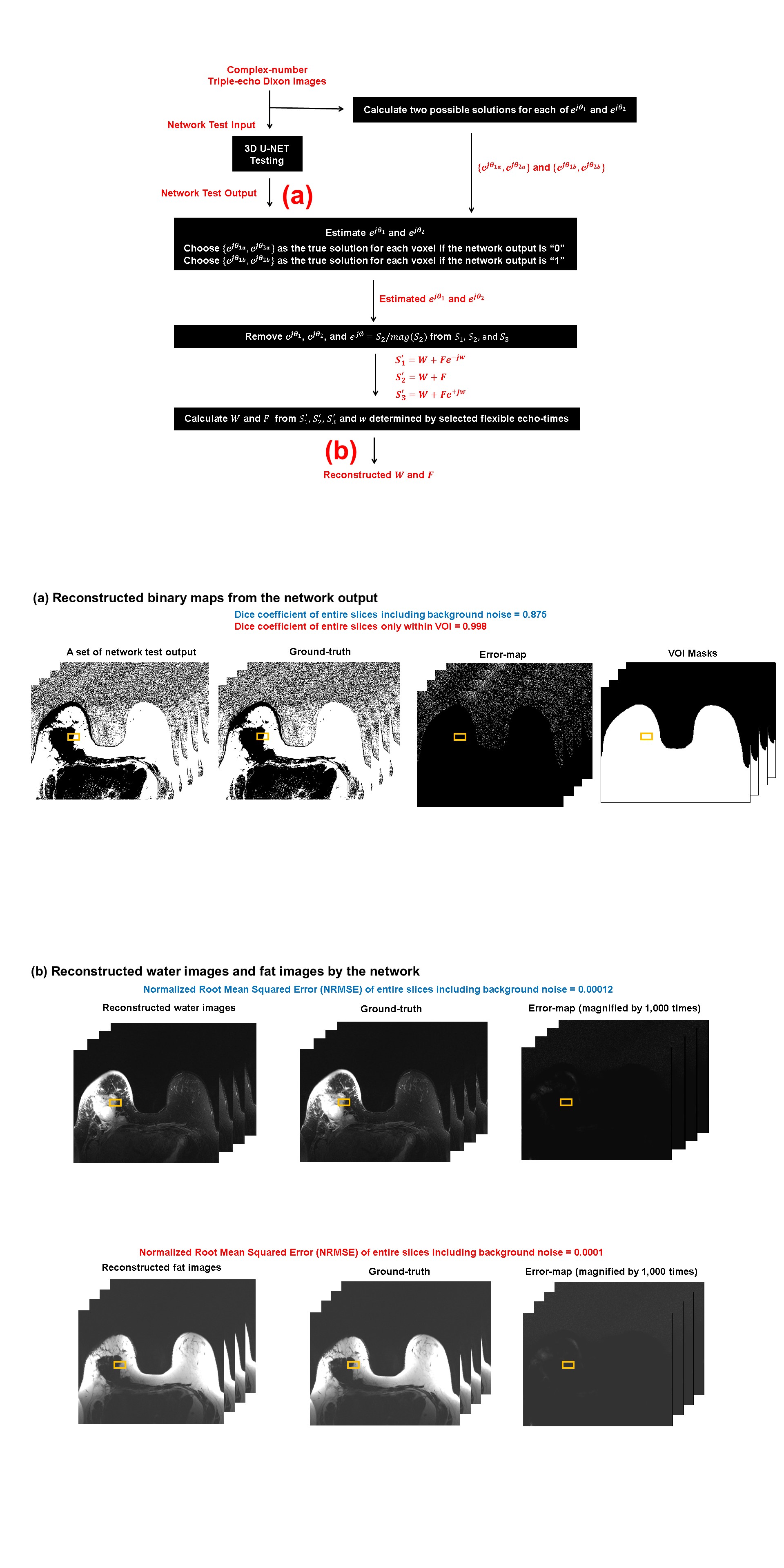
Figure 4. (a) After training, 3D binary maps were generated directly from 50 sets of independent test images, then ejθ1 and ejθ2 were reconstructed by replacing the 3D binary map with the corresponding true solution pairs which are either {ejθ1a,ejθ2a} for “0” or {ejθ1b,ejθ2b} for “1” for each voxel. (b) After eliminating background phases (ej∅, ejθ1, and ejθ2) from S1, S2, and S3, only chemical-shift induced image phases (ω) remain in three echo signals. Once ω was calculated with the selected echo-spacings (TE1/TE2/TE3), multislice water images (W) and fat images (F) were generated.
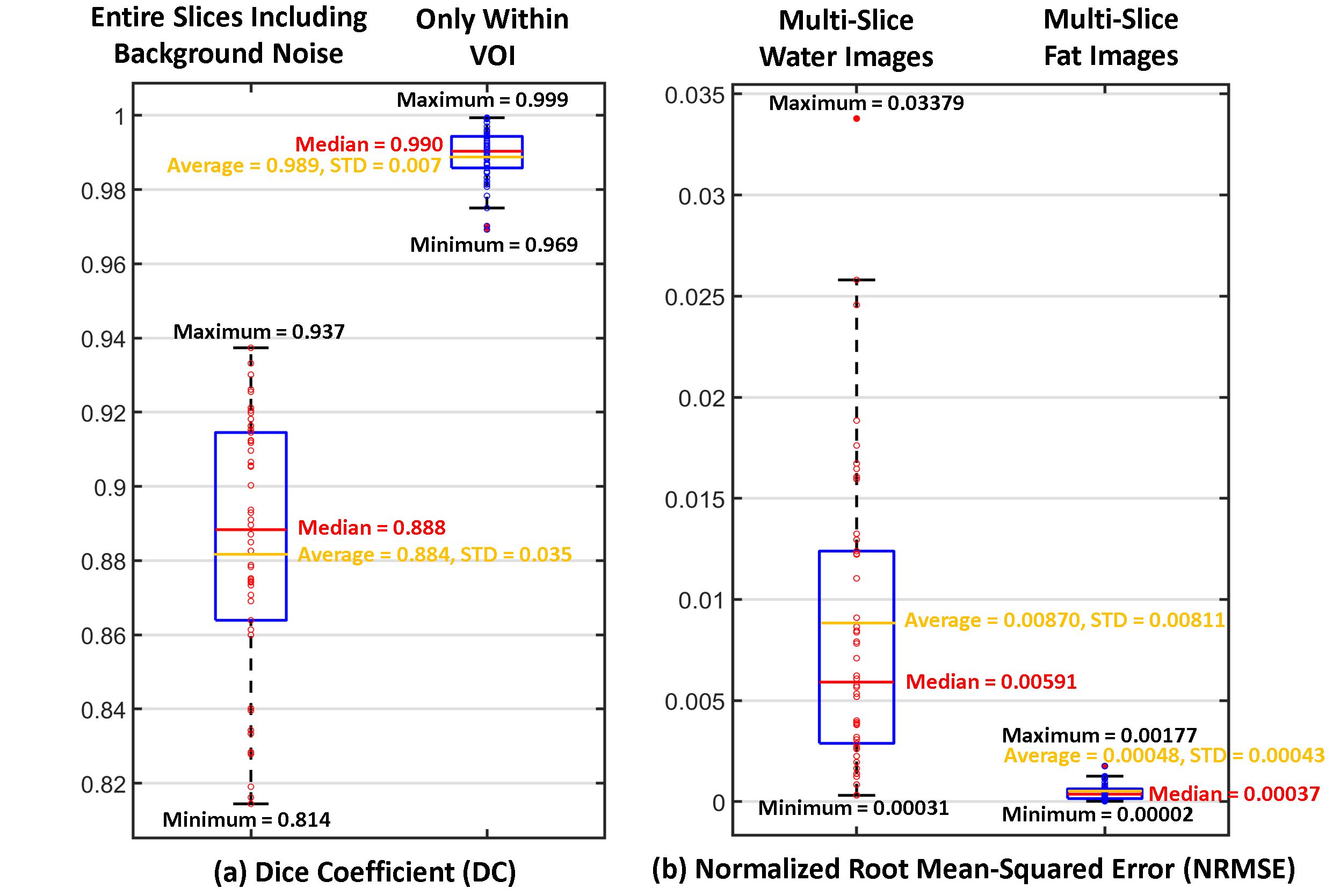
Figure 5. (a) The performance of the 3D network was evaluated with Dice coefficient (DI) between 3D binary maps from 50 patients and ground-truth. When background noise regions were excluded, the network was able to reconstruct accurate binary maps with median DI=0.990 and average DI=0.989. The DI for the entire 3D maps was median DI=0.888 and average DI=0.884, respectively. (b) The 3D binary map generated by the network was used to separate water and fat images. Compared to the ground-truth, the network reconstructed water images with median NRMSE=0.00591 and average NRMSE=0.00870.