3657
Synthetic derivative T2-weighted abdominal images from T1-weighted images using a generative adversarial network (GAN)1Radiology, Houston Methodist Research Institute, Houston, TX, United States, 2Electrical and Computer Engineering, University of Arizona, Tucson, AZ, United States, 3Medical Imaging, University of Arizona, Tucson, AZ, United States, 4Biomedical Engineering, University of Arizona, Tucson, AZ, United States
Synopsis
Keywords: Liver, Multi-Contrast, Image-to-image translation
Motivation: Either fast 2D T2-weighted abdominal imaging or 3D T2 MIP techniques have limitations. There remains a need for fast 3D T2 abdominal high-resolution imaging.
Goal(s): To develop a conditional GAN model to synthesize T2-weighted images from 3D high-resolution T1-weighted abdominal images preserving spatial resolution of the source images.
Approach: Abdominal images acquired from 39 volunteers were included for the study. A conditional GAN model was trained to generate T2-weighted images from T1-weighted images slice by slice.
Results: Overall, the generated T2-weighted images were similar to the real T2-weighted images, though some contrast differences in the bowels and kidneys were seen.
Impact: This proof of principle study shows the GAN model can be used to generate T2-weighted images from T1-weighted images, with the potential for rendering high quality volumetric 3D high-resolution abdominal T2-weighted images that is superior to current 3D MIP methods.
Introduction
For abdominal imaging, high-resolution 3D T1-weighted (T1w) gradient echo images can be acquired within a single breath-hold or while breathing regularly. In comparison, T2-weighted (T2w) single shot partial Fourier images are usually acquired 2D with multiple breath-holds or respiratory triggering over several minutes. Thus, cross-plane resolution of T2w images is lower than 3D T1w images, suffering from thicker slices, slice gaps, and misregistration of slices due to motion. Currently, generative adversarial networks (GANs) have shown feasibility for synthesizing derivative images with different contrasts in brain and spine1-3. In this study we evaluate the feasibility of training a GAN network to derive T2w abdominal images from T1w images. The overarching objective is to provide high-resolution 3D T2w abdominal images, in all planes, without gaps or misregistration. With fewer acquisitions needed, the total study scan time would be reduced.Methods
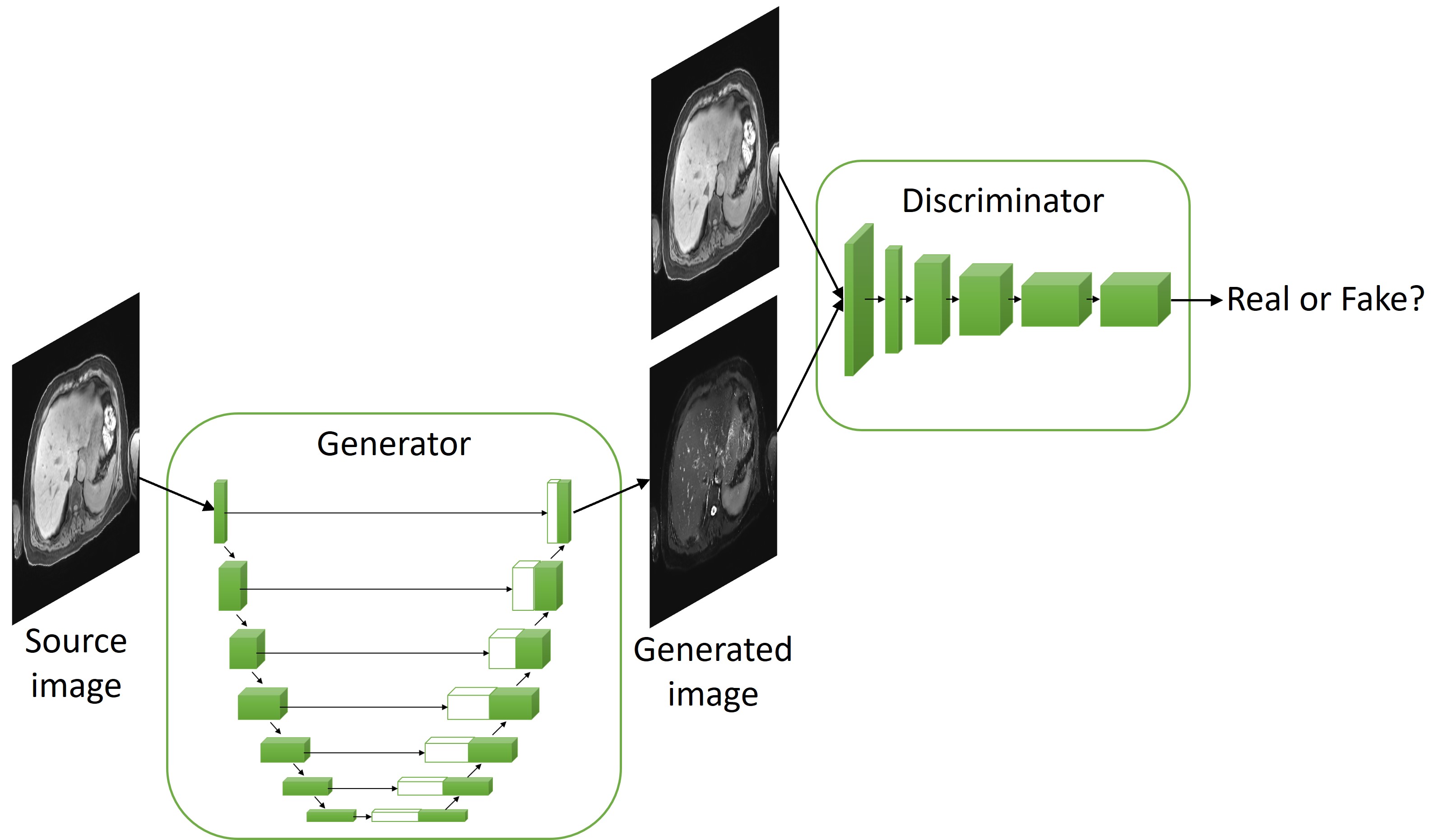
The study was approved by the local IRB. Imaging data from 39 volunteers acquired on a 3T MRI scanner (Siemens Vida) were included for the study. The axial T1w images were acquired using a single breath-hold 3D Dixon VIBE sequence with a 3 mm slice thickness. The axial fat suppressed T2w images were acquired using a breath-hold multi-slice 2D HASTE sequence with a 5 mm slice thickness, 20% slice gap, and a typical TR/TE 1100/100 ms. The 39 volunteers’ datasets were randomly divided into training (31), validation (4) and testing (4) datasets. The T1w images were first interpolated at the slice locations of the T2w images, and then interpolated to the same in-plane resolution as the T2w images. Non-rigid image registration was performed between the interpolated T1w images and T2w images using ANTs. The images were resized to 256*256 and scaled to -1 to 1. After preprocessing, each dataset had 1384, 196 and 165 image slices respectively.In our image-to-image translation task, the generator was an encoder-decoder model of a U-Net structure with 7 layers and the discriminator was a patch GAN discriminator based on a deep convolutional neural network of 5 layers4. The model structure is shown in Fig. 1. The loss function was a combination of binary cross entropy and mean absolute error with a weight of 1 and 100. The model was trained on 100 epochs with a batch size of 14 and learning rate of 0.0001. The training images were augmented by random flip up and down and left and right at the beginning of each epoch. TensorFlow was used to build the model. An NVIDIA A100 GPU was used for training.
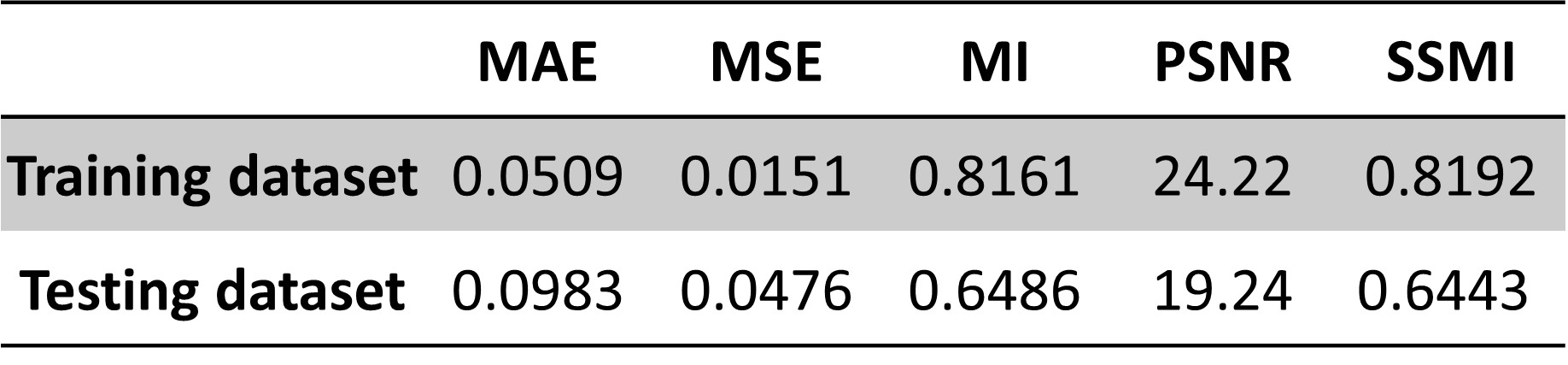
The accuracy of the synthesized image compared with the real T2w image was evaluated using five metrics, mean absolute error (MAE), mean squared error (MSE), peak signal-to-noise ratio (PSNR), mutual information (MI) and structural similarity index (SSIM).
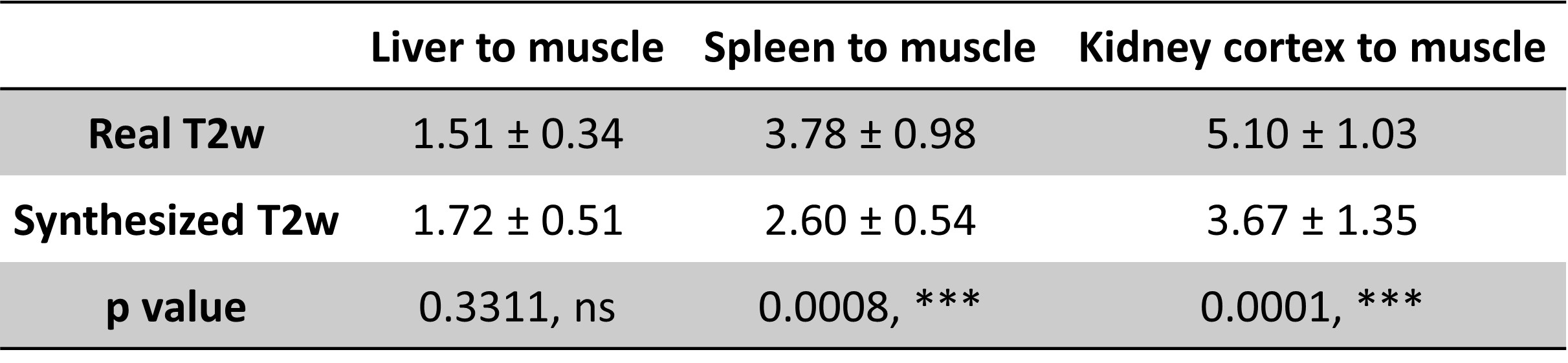
To compare the relative tissue contrast ratios between real and synthesized T2w images, ROIs were drawn manually on the liver, spleen, kidney cortex and muscle of a subset of the testing dataset images. Paired two-tailed t-test was performed to determine whether the differences were statistically significant.
Results
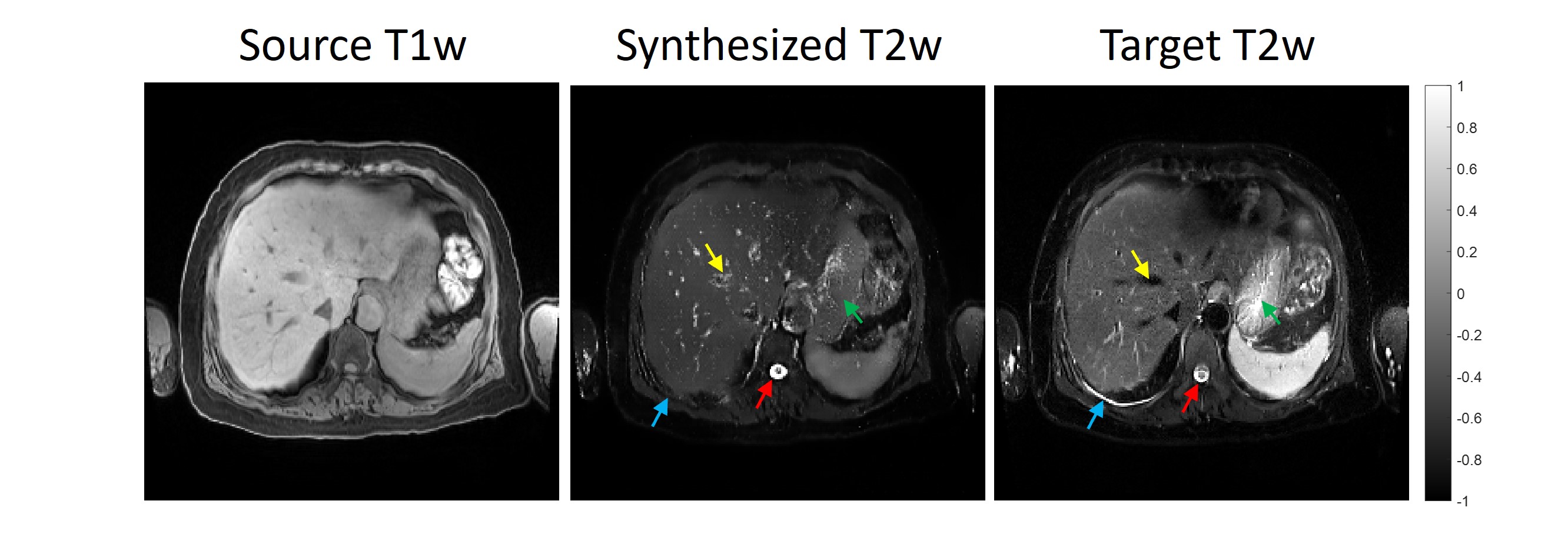
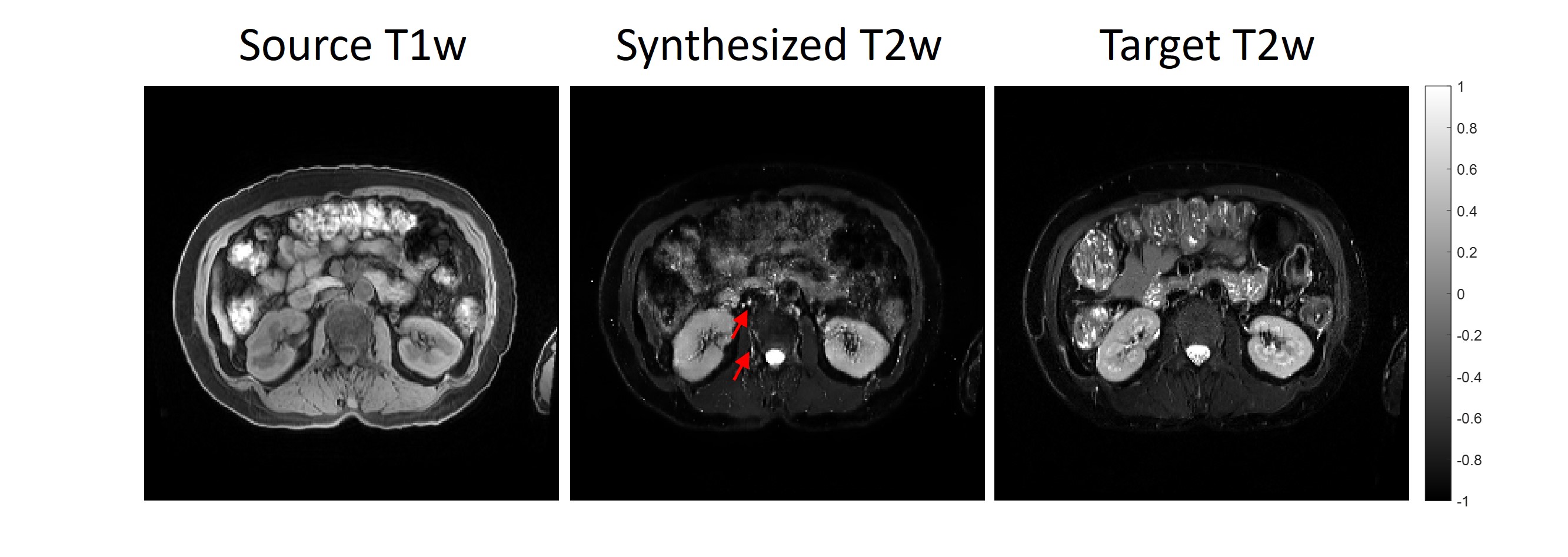
Figures 2 and 3 show the representative source T1w images, generated T2w images and the real T2w images for the liver, spleen, and kidney regions from the testing datasets. Overall, the generated T2w images appear similar to the real T2w images. CSF, liver/spleen/kidney cortex/muscle contrast ratios (Table 1) are well-rendered. Liver contrast ratios show no significant differences. However, spleen and kidney contrast ratios appear to have significant differences. Moreover, some contrast differences in the gastric fluid, bowels, blood vessels and kidneys were seen. The metrics for the training and testing datasets were shown in Table 2.Discussion and Conclusion
This study demonstrates the feasibility of synthesizing T2w images from 3D T1w images. Liver T2 contrast was similar. While spleen and kidney qualitatively are similar, measured values are different. We hypothesize that expanded training and injection of real T2w images into the training pipeline should reduce these contrast differences. Therefore, the next phase of the study will take the 3D T1w images as well as the 2D T2w images together as the inputs to the model for synthesized 3D T2w images. Moreover, the ongoing work includes continued accumulation of imaging data to enlarge the training dataset, further refinement of image registration, and exploration of unsupervised models. We will also introduce pathological patient cases to test diagnostic attributes of synthetic T2 images. In conclusion, this proof of principle study shows our GAN model can be used to generate T2w images from T1w images, with the potential for rendering high quality volumetric 3D high resolution abdominal T2w images.Acknowledgements
No acknowledgement found.References
- Yang Q, Li N, Zhao Z, et al. MRI Cross-Modality Image-to-Image Translation. Sci Rep. 2020;10: 3753.
- Kawahara D, Nagata Y. T1-weighted and T2-weighted MRI image synthesis with convolutional generative adversarial networks. Rep Pract Oncol Radiother. 2021;26(1):35-42.
- Schlaeger S, Drummer K, El Husseini M, et al. Synthetic T2-weighted fat sat based on a generative adversarial network shows potential for scan time reduction in spine imaging in a multicenter test dataset. Eur Radiol. 2023;33(8):5882-5893.
- Isola P, Zhu JY, Zhou T, et al. Image-to-Image Translation with Conditional Adversarial Networks. 2016;5967-5976.
Figures