3571
Towards Vector Encoding Methods on GPUs for Dictionary Search Memory Optimization1Center for Adaptable MRI Technology (AMT Center), Institute of Medical Sciences, School of Medicine, Medical Sciences & Nutrition, University of Aberdeen, Aberdeen, United Kingdom
Synopsis
Keywords: MR Fingerprinting, Quantitative Imaging, Dictionary Search, GPU
Motivation: GPU memory size can be a limiting factor for MRF dictionary search. Accelerated grouped search on GPUs was implemented previously without addressing GPU memory constraints.
Goal(s): To investigate the feasibility of GPU memory footprint reduction through vector storage format compression.
Approach: We built a CPU-only prototype search engine storing dictionaries as approximations enabling 2x and 4x memory reduction. Additionally, we implemented a post processing step that refines approximate results using the non-approximated vectors.
Results: Refinement was effective at mitigating errors from vector compression. Overall, 2x group memory compression resulted in no quality loss and speed gains, while 4x compression resulted in speed loss.
Impact: Dictionary search errors from vector storage compression of up to 4x have been found to be well mitigated by an uncompressed refinement step. This indicates the feasibility of implementing compression on GPUs to make efficient use of limited GPU memory.
Introduction
Dictionary search is an important tool for the reconstruction of MR Fingerprinting (MRF)1 data. However, when properties beyond relaxation times are considered, dictionary size grows exponentially with the number of encoded parameters. Brute force search is a popular algorithm for MRF dictionary search that calculates the inner product (IP) between every voxel fingerprint and dictionary entry. While GPUs have accelerated brute force search, GPU memory constraints can become a bottleneck. Singular value decomposition (SVD)-dictionary compression2 and SVD-compressed group search3 have been proposed to address speed and memory concerns. Non-compressed group search on GPU was recently demonstrated4. While promising acceleration was achieved, that approach did not address the required GPU memory. Here, we present preliminary CPU-only results indicating that simple vector-component compression-based group search on the GPU combined with an exact refinement on the CPU could be a strategy to reduce GPU memory consumption without sacrificing result quality.Methods
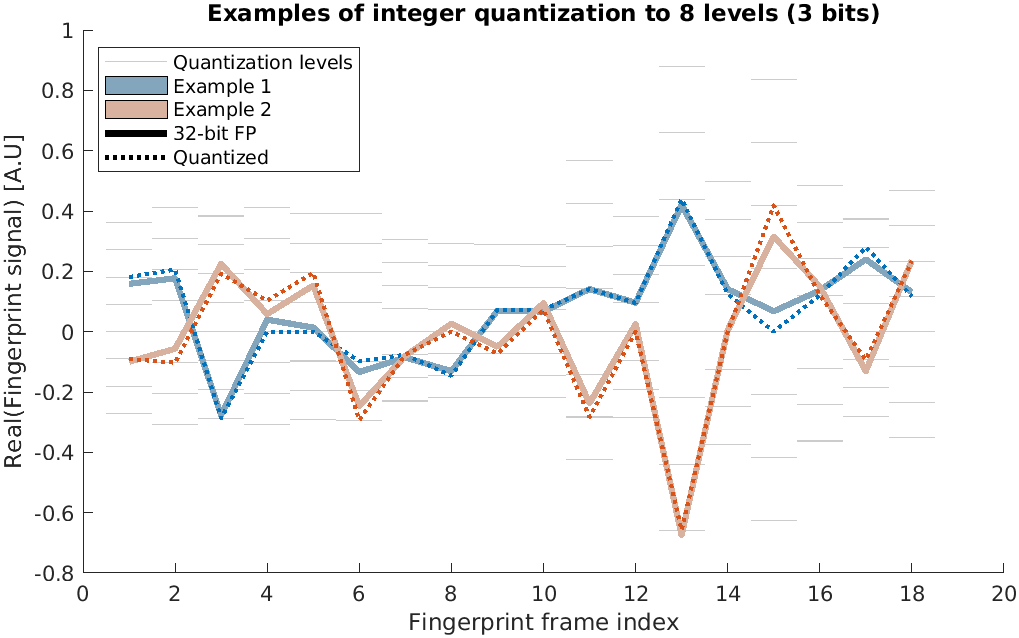
Previous GPU group search4 stored dictionary data exclusively in 32-bit floating point (FP) format. This work extended complex data support for Faiss’5 vector encoding routines and made two compressed storage formats available for complex vectors: 16-bit FP and 8-bit integer encoding. The latter requires a training step to determine for each vector dimension the minimum and maximum values in the dictionary and quantizes this range into 256 equidistant values, as illustrated in Figure 1. When accessing a vector during search, the IP is estimated based on the approximate representation of the encoded vector.To mitigate errors from approximate IP computation, the coarse search was designed to return a list of k candidates for each voxel, rather than a single candidate. This list of coarse candidates was refined by fetching the vectors’ uncompressed representations from a different storage pool and repeat the IP calculations in 32-bit precision to identify the candidate yielding the highest IP. In the present work, encoded and exact dictionary data, were kept in the computer’s memory. We evaluated our implementation on wrist data of a healthy volunteer. The acquisition was fully sampled with a matrix size of 101×31×31 and a resolution of 1.7×1.2×6.1 mm3 for a total acquisition time of 8 min at 0.1T6. A dictionary containing 1.1M entries covering 18 timepoints for the parameters T1, T2, δB0 and B1+-fraction was simulated. This dictionary size is unlikely to cause memory issues but is well suited to perform feasibility studies and implementation validation. Our evaluation covered more than 3000 combinations of search parameters including the number of groups to form and probe during search, candidate list size k, and the encoding format. Outputs were compared to brute force search with 32-bit FP data from which the fraction of different voxels was calculated, limited to those voxels having an IP magnitude ≥0.85 to ignore noise-only voxels. We refer to this as the F metric.
We restrict our reporting to Pareto-optimal configurations, i.e., the fastest ones maintaining a given value of F. All experiments were performed on a workstation running Ubuntu 22.04, with an Intel Core i9-13900K CPU and 128 GiB RAM.
Results
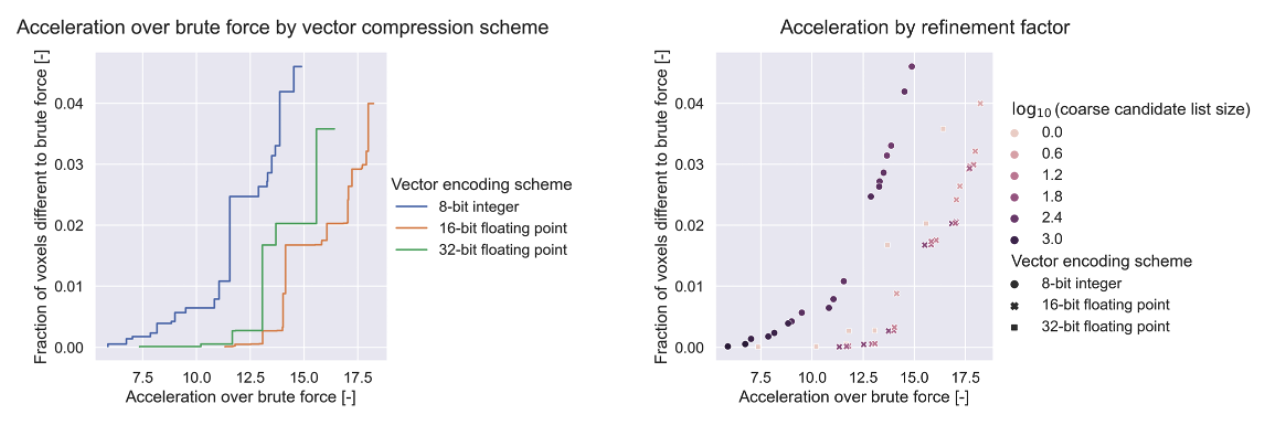
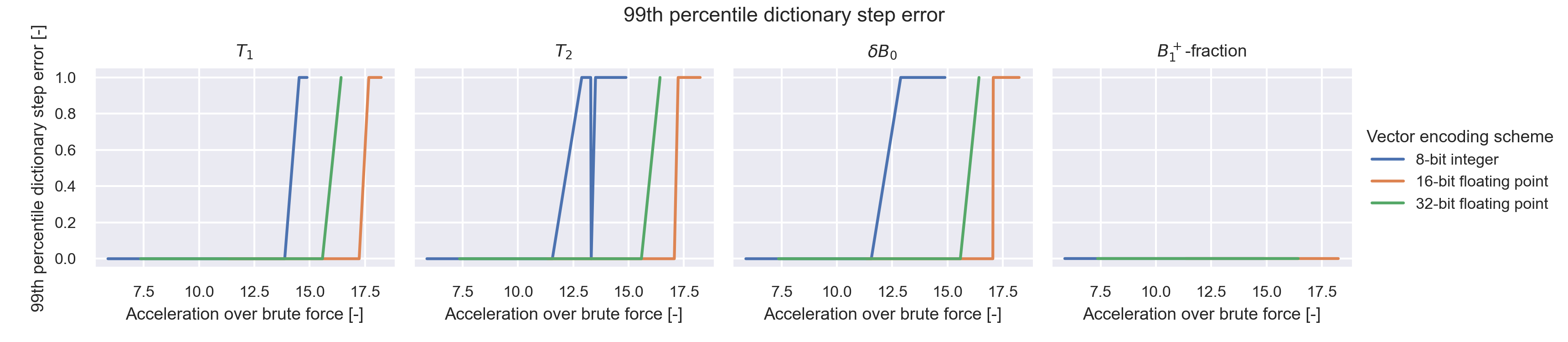
Figure 2 summarizes the tradeoff between search acceleration and the accompanying deviations from brute force results. Configurations with 16-bit compressed data are consistently faster than with uncompressed 32-bit data, while 8-bit data is consistently slower for a given level of accuracy. We note that for all storage formats, there exist configurations that can reach F<0.0002.MRF parameter errors of thresholded voxels were statistically assessed, and we report the 99th percentile of parameter errors in units of dictionary steps in Figure 3.
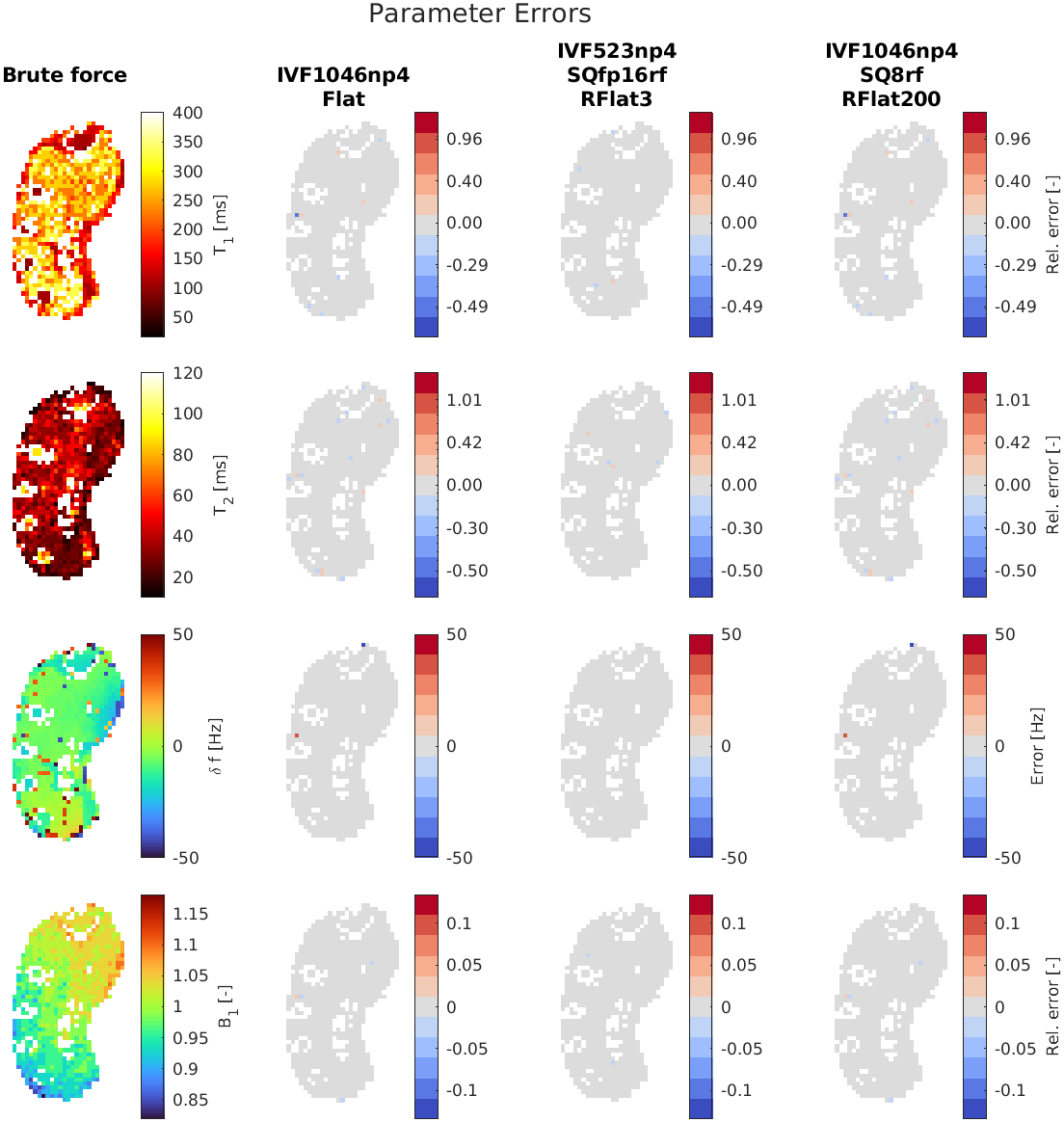
Figure 4 shows parameter and error maps for the fastest performing configurations with F<0.05. These configurations correspond to those at the top end of the traces in Figures 2 and 3.
Discussion and Conclusion
The 16-bit compressed storage format results in acceleration over the uncompressed format at no cost of accuracy. As less data must be read per vector, data access is faster resulting in a speedup that is large enough to accommodate the extra refinement step while still being faster. The 8-bit format required more demanding refinement configurations to yield accurate results, which made it slower overall despite its larger data access speed advantage. For our planned GPU implementation, where only compressed vectors will be stored on the GPU, we are interested in the memory savings during the in-group search and factors of 2 to 4 reduction over 32-bit FP using the 16, and 8-bit formats, respectively, appear possible. Future work will include implementing the GPU version, experiments with larger dictionaries and longer fingerprints to assess scalability and generalizability.Acknowledgements
No acknowledgement found.References
1. Ma, D. et al. Magnetic resonance fingerprinting. Nature 495, 187–192 (2013).
2. McGivney, D. F. et al. SVD Compression for Magnetic Resonance Fingerprinting in the Time Domain. IEEE Trans. Med. Imaging 33, 2311–2322 (2014).
3. Cauley, S. F. et al. Fast group matching for MR fingerprinting reconstruction. Magn. Reson. Med. 74, 523–528 (2015).
4. Zihlmann, G., Salameh, N. & Sarracanie, M. A Scalable High-Performance Magnetic Resonance Fingerprinting Search Engine using GPUs. in Proc. Intl. Soc. Mag. Reson. Med. 30 2520 (2022). doi:10.58530/2022/2520.
5. Johnson, J., Douze, M. & Jégou, H. Billion-Scale Similarity Search with GPUs. IEEE Trans. Big Data 7, 535–547 (2021).
6. Sarracanie, M. Fast Quantitative Low-Field Magnetic Resonance Imaging With OPTIMUM—Optimized Magnetic Resonance Fingerprinting Using a Stationary Steady-State Cartesian Approach and Accelerated Acquisition Schedules. Invest. Radiol. (2021) doi:10.1097/RLI.0000000000000836.
Figures