3562
Unlocking Data-Consistent Synthesis of Clinical Contrasts from Magnetic Resonance Fingerprinting with Semi-Supervised Learning1Department of Electrical Engineering, Stanford University, Stanford, CA, United States, 2Stanford University, Stanford, CA, United States, 3Department of Radiology, Stanford University, Stanford, CA, United States, 4Department of Bioengineering, Stanford University, Stanford, CA, United States, 5Karolinska Institutet, Solna, Sweden, 6Department of Biomedical Physics, Stanford University, Stanford, CA, United States, 7Department of Radiology, Northwestern University, Chicago, IL, United States, 8Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey
Synopsis
Keywords: MR Fingerprinting, MR Fingerprinting
Motivation: We aim to introduce an end-to-end, ultra-fast acquisition and synthesis protocol for contrast-weighted image generation from magnetic resonance fingerprinting.
Goal(s): Our objective is to facilitate data compilation from large patient cohorts to enhance generalizability and accuracy of synthesis.
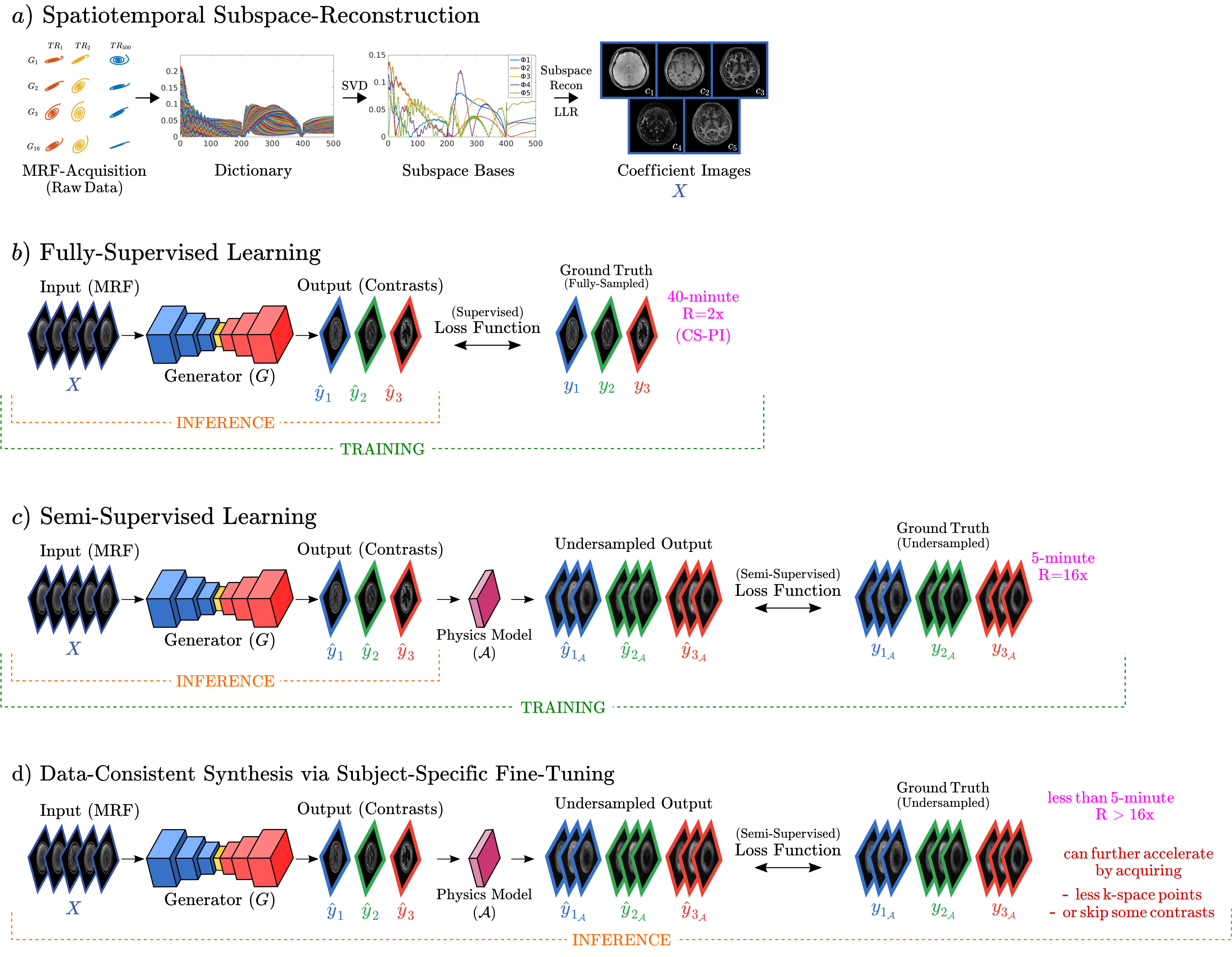
Approach: We leverage a semi-supervised framework to enable model training using highly-accelerated ground-truth data of the target contrasts, and introduce data-consistent synthesis in inference by performing subject-specific fine-tuning and validation.
Results: Our experiments indicate that the proposed method enables high-quality synthesis using network models trained on prospectively undersampled data of the contrast-weighted images. We show that data-consistent synthesis helps improve synthesis quality and mitigate hallucinations.
Impact: Conventional synthesis models for MRF perform a single-shot inference and are prone to hallucinations and inaccuracy. We introduce semi-supervised learning that enables data-consistency in inference, by merely getting an additional, ultra-fast 1-2min data of the target contrasts for subject-specific fine-tuning.
Introduction
Magnetic resonance fingerprinting (MRF) has made remarkable progress recently, driven by advancements in sequences 1-5 and reconstruction 6-8. These advances enable high-resolution, full-brain quantification with ultra-fast acquisitions (~2min) 9. However, clinical practice heavily relies on traditional MRI-contrasts (e.g., T1-weighted, T2-weighted) due to their long-standing familiarity 10. Therefore, translating MRF into contrast-weighted images has potential to streamline routine diagnostic use of MRF-technology.One approach to synthesize contrasts is MR-physics, but can become suboptimal due to incomplete modeling and magnetization transfer 11. Hence, several studies proposed data-driven synthesis through deep learning 9-14. Yurt et al. 11 introduced semi-supervision to reduce training data requirements. Their approach enabled training with accelerated contrast-weighted acquisitions, with undersampling up to R=8x. The key idea was to define loss only on acquired k-space points and use randomized sampling masks across subjects for homogenous k-space learning 11. However, this study mainly served as a proof–of-concept using retrospectively undersampled data. Its unaddressed limitations include implementing randomized sampling in contrast-weighted sequences and assessing semi-supervision on prospective undersampling.
To address these limitations, we propose an end-to-end acquisition and synthesis framework for MRF-to-contrast translation. We implement undersampled sequences (R=16x) for four clinical contrasts (T1-Cube, T2-Cube, FLAIR-Cube, DIR-Cube) with a 5min 26sec scan duration. We ensure that uniform random masks are generated and mask points are ordered on-the-fly. Using these sequences, we demonstrate that semi-supervision works effectively on prospectively undersampled data. Importantly, we propose semi-supervision as a data-consistency measure during inference, for subject-specific fine-tuning, helping mitigate hallucinations and improve out-of-domain performance.
Methods
Semi-Supervised Learning: Synthesizing contrast-weighted images begins with MRF-coefficients as input (5min acquisition), obtained through subspace-reconstruction (Fig.1a). Conventional fully-supervised learning requires fully-sampled contrasts as ground-truth label (40min acquisitions, R=~2-4x, parallel-imaging reconstructed) for direct loss calculation (Fig.1b), demanding prolonged, paired MRF and contrast acquisitions. To reduce data requirement, our semi-supervision enables ground-truth contrasts to be highly-accelerated acquisitions (e.g., 5min, R=16x). As accelerated contrasts prohibit direct loss calculation, we introduce a physics-module $$$\mathcal{A}$$$, applied on synthesized contrasts, to define loss on acquired k-space (Fig.1c), where $$$\mathcal{A}=P\mathcal{F}C$$$ with $$$P$$$ is sampling masks, $$$\mathcal{F}$$$ is Fourier-transform, and $$$C$$$ is coils.Data-Consistent Synthesis: As reliability and hallucination are common deep learning issues, we propose data-consistent synthesis through subject-specific fine-tuning during inference (Fig.1d). Given that input MRF-acquisition takes around 5min, adding 1-2min of ultra-fast contrast scans wouldn’t significantly increase total acquisition time, especially for hard-to-synthesize contrasts like FLAIR. The heavily-accelerated contrast data serve as a data-consistency measure to fine-tune and validate synthesis, by updating network weights of a pre-trained model to minimize semi-supervised inference loss.
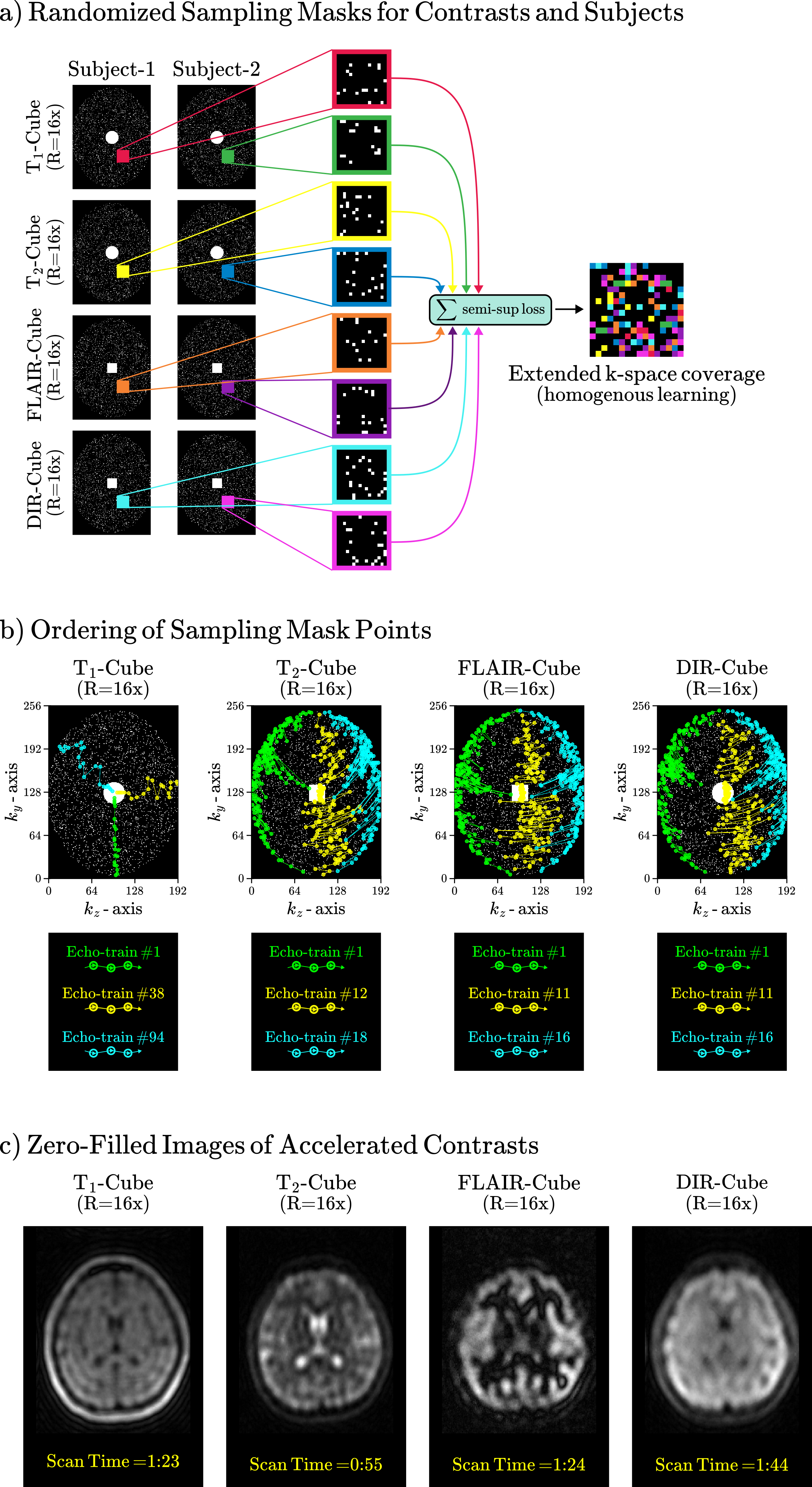
Sequence and Sampling Mask Design for Contrasts: In sampling masks, randomness across different subjects and contrasts ensures semi-supervised loss spread across all possible k-space locations (Fig.2a). Therefore, we developed uniform random sampling in four clinical contrast-weighted sequences: T1-Cube, T2-Cube, FLAIR-Cube, DIR-Cube. Echo-train lengths and mask ordering were carefully tuned for each sequence to capture correct contrasts (Fig.2b).
Data Acquisition:
Training Data: MRF (5:57min) and contrasts (T1-Cube 1:23min, T2-Cube 0:55min, FLAIR-Cube 1:24min, DIR-Cube 1:44min, each at R=16x) from 20 volunteers.
Testing/Evaluation Data: MRF (5:57min) and contrasts (T1-Cube 5:56min, T2-Cube 3:58min, FLAIR-Cube 5:06min, DIR-Cube 5:04min; each at R=3x) from 2 volunteers. Contrasts were reconstructed with L1-wavelet and served as reference in qualitative/quantitative evaluations.
Results
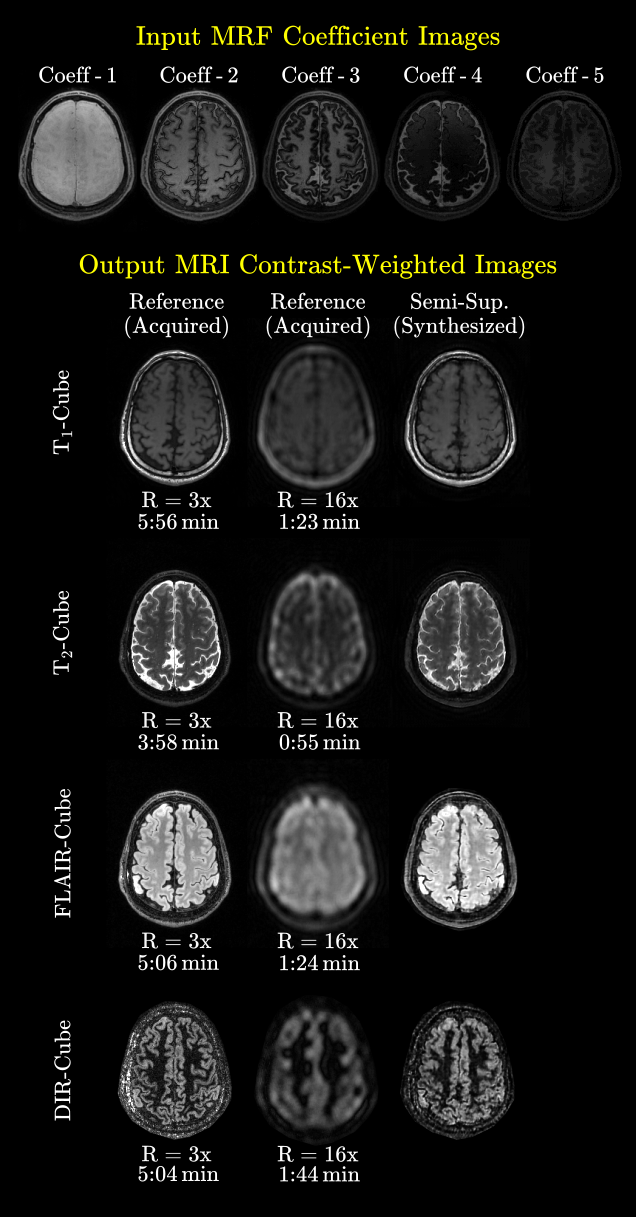
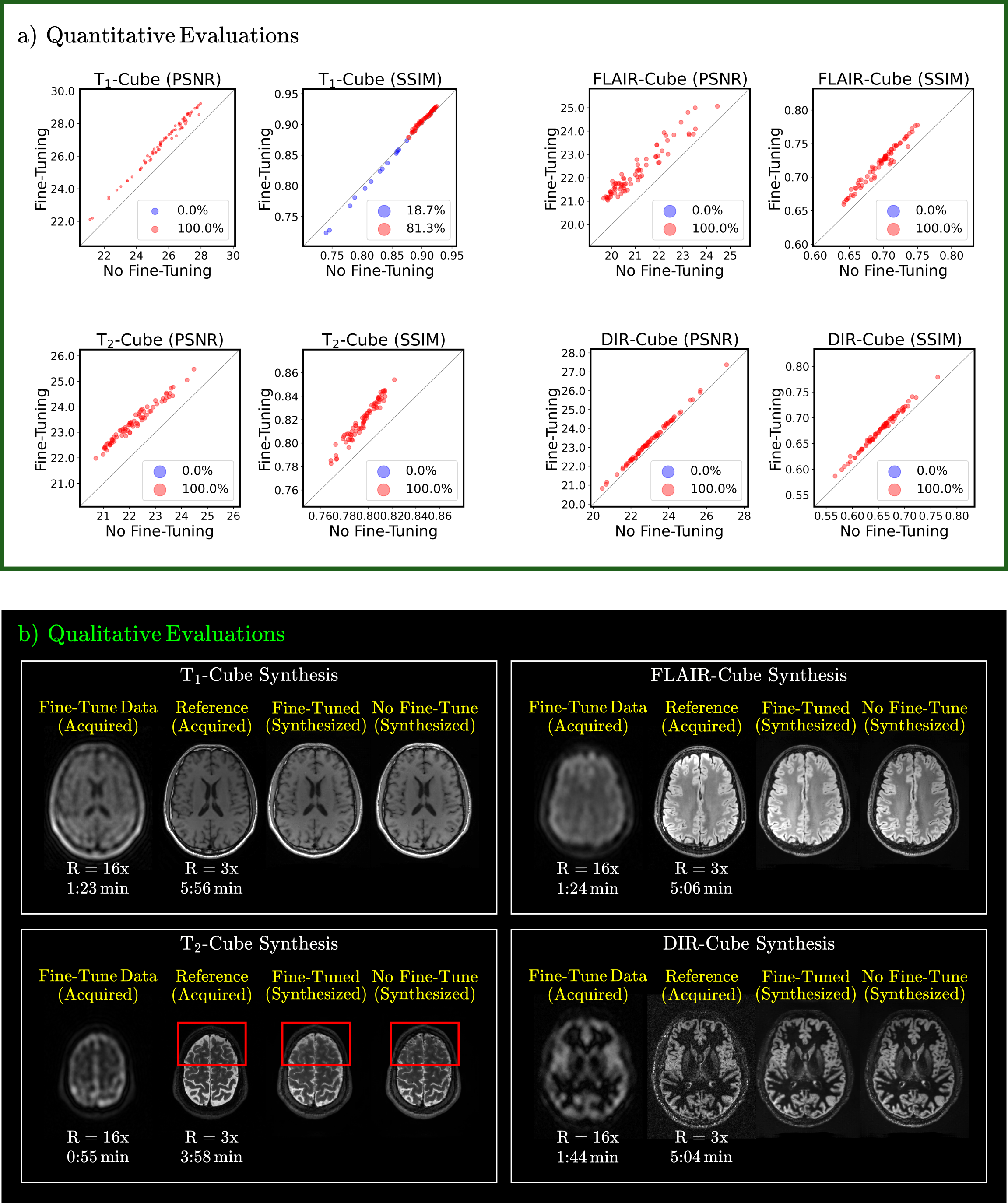
We first demonstrated semi-supervision on prospectively undersampled data. We trained a semi-supervised model using accelerated contrast-weighted acquisitions (R=16x). Synthesized images are displayed in Fig.3 and indicate high-quality synthesis of the four contrasts. Note that the synthesis is only learned from highly-accelerated ground-truths.Next, we showcased our proposed data-consistent synthesis. We fine-tuned network weights of a pre-trained model to minimize semi-supervised inference loss on a given subject. This subject was a new test subject, who also had R=16x acquisitions for the target contrasts. Fig.4a shows PSNR and SSIM measurements of two models, one with inference-time fine-tuning, and one without any fine-tuning. The measurements are displayed through butterfly plots, where PSNR and SSIM values for individual 2D slices are reported with scatter dots. Color red is used for indicating the fine-tuned model, and blue for no fine-tuned model. The proportion of which model performed better is also shown in the figure legend.
Finally, Fig.4b displays the synthesized images from the fine-tuned and no fine-tuned models, together with reference acquisitions and inference-time fine-tuning data. The results suggest that subject-specific fine-tuning qualitatively improves the capture of true contrast (see FLAIR-Cube) and reduces hallucinations (see T2-Cube).
Conclusion
We proposed semi-supervision for contrast-weighted images synthesis from MRF that is compatible with prospectively undersampled contrast data. We enhanced synthesis robustness to mitigate hallucinations via data-consistent synthesis. Future work involves large-scale patient studies.Acknowledgements
This work is supported in part by R01MH116173, R01EB019437, U01EB025162, P41EB030006, R01EB033206, U24NS129893, and by GE Healthcare.References
1. Cao X, Liao C, Srinivasan S, et al. Optimized multi-axis spiral projection MRF with subspace reconstruction for rapid 1-mm isotropic whole-brain MRF in 2 minutes. In: Proc. Intl. Soc. Mag. Reson. Med. ; 2021.2. Gómez PA, Cencini M, Golbabaee M, et al. Rapid three-dimensional multiparametric MRI with quantitative transient-state imaging. Sci Rep 2020;10:13769 doi: 10.1038/s41598-020-70789-2.
3. Iyer SS, Liao C, Li Q, et al. PhysiCal: A rapid calibration scan for B0, B1+, coil sensitivity and Eddy current mapping. In: Proc. Intl. Soc. Mag. Reson. Med. ; 2020. p. 661
4. Liang Z. Spatiotemporal imaging with partially separable functions. In: 2007 4th IEEE International Symposium on Biomedical Imaging: From Nano to Macro. Arlington, VA, USA: IEEE; 2007. pp. 988–991. doi: 10.1109/ISBI.2007.357020.
5. Cao X, Ye H, Liao C, Li Q, He H, Zhong J. Fast 3D brain MR fingerprinting based on multi‐axis spiral projection trajectory. Magn Reson Med 2019;82:289–301 doi: 10.1002/mrm.27726.
6. Zhao B, Setsompop K, Adalsteinsson E, et al. Improved magnetic resonance fingerprinting reconstruction with low-rank and subspace modeling: A Subspace Approach to Improved MRF Reconstruction. Magn. Reson. Med. 2018;79:933–942 doi: 10.1002/mrm.26701.
7. Assländer J, Cloos MA, Knoll F, Sodickson DK, Hennig J, Lattanzi R. Low rank alternating direction method of multipliers reconstruction for MR fingerprinting: Low Rank ADMM Reconstruction. Magn. Reson. Med 2018;79:83–96 doi: 10.1002/mrm.26639.
8. Cao X, Liao C, Iyer SS, et al. Optimized multi-axis spiral projection MR fingerprinting with subspace reconstruction for rapid whole-brain high-isotropic-resolution quantitative imaging. arXiv:2108.05985 [physics] 2021.
9. Schauman S.S., Iyer, S, Yurt, M, Cao, X, Liao, C, Zhong, Z, Wang, G, Zaharchuk, G, Vasanawala, S, Setsompop, K, “Toward a 1-minute high-resolution brain exam - MR Fingerprinting with fast reconstruction and ML-synthesized contrasts“ 2022 ISMRM Annual Meeting, London, UK
10. Wang K, Doneva M, Amthor T, et al. High Fidelity Direct-Contrast Synthesis from Magnetic Resonance Fingerprinting in Diagnostic Imaging. In: Proc. Intl. Soc. Mag. Reson. Med. ; 2020. p. 867.
11. Yurt M, Alkan C, Schauman S, Cao X, Liao C, Iyer S, Cukur T, Vasanawala S, Pauly J, Setsompop K, “Semi-supervision for clinical contrast-weighted image synthesis from magnetic resonance fingerprinting” 2023 ISMRM Annual Meeting, Toronto, Canada
12. Qiu S, Chen Y, Ma S, et al. Direct Synthesis of Multi-Contrast Images from MR Multitasking Spatial Factors Using Deep Learning. In: Proc. Intl. Soc. Mag. Reson. Med. 29. ; 2021. p. 2429.
13. Wang G, Gong E, Banerjee S, et al. Synthesize High-Quality Multi-Contrast Magnetic Resonance Imaging From Multi-Echo Acquisition Using Multi-Task Deep Generative Model. IEEE Trans. Med. Imaging 2020;39:3089–3099 doi: 10.1109/TMI.2020.2987026.
14. Tanenbaum LN, Tsiouris AJ, Johnson AN, et al. Synthetic MRI for Clinical Neuroimaging: Results of the Magnetic Resonance Image Compilation (MAGiC) Prospective, Multicenter, Multireader Trial. AJNR Am J Neuroradiol 2017;38:1103–1110 doi: 10.3174/ajnr.A5227.
Figures