3559
Scalable Zero-Shot Self-Supervised Learning for Accelerated MR Fingerprinting1University of North Carolina at Chapel hill, Chapel Hill, NC, United States, 2Case Western University, Chapel Hill, NC, United States, 3University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
Synopsis
Keywords: MR Fingerprinting, MR Fingerprinting, deep learning
Motivation: Collecting ground truth tissue property maps for training deep learning networks for MR Fingerprinting reconstruction can be challenging.
Goal(s): We aim to reduce reliance on training datasets for deep learning based MR Fingerprinting.
Approach: We propose a novel zero-shot self-supervised MRF framework that requires only the undersampled k-space measurements. We develop strategies to rapidly retrieve fingerprints from the dictionary for efficient network training.
Results: Our method demonstrates promising results on 2x and 4x accelerated MRF without requiring supervised learning based on ground truth tissue property maps, laborious reconstruction, explicit dictionary matching, and network pre-training.
Impact: Our preliminary results validated the feasibility of zero-shot self-supervised MRF reconstruction from undersampled MRF data with the help of physics-based constraints.
Introduction
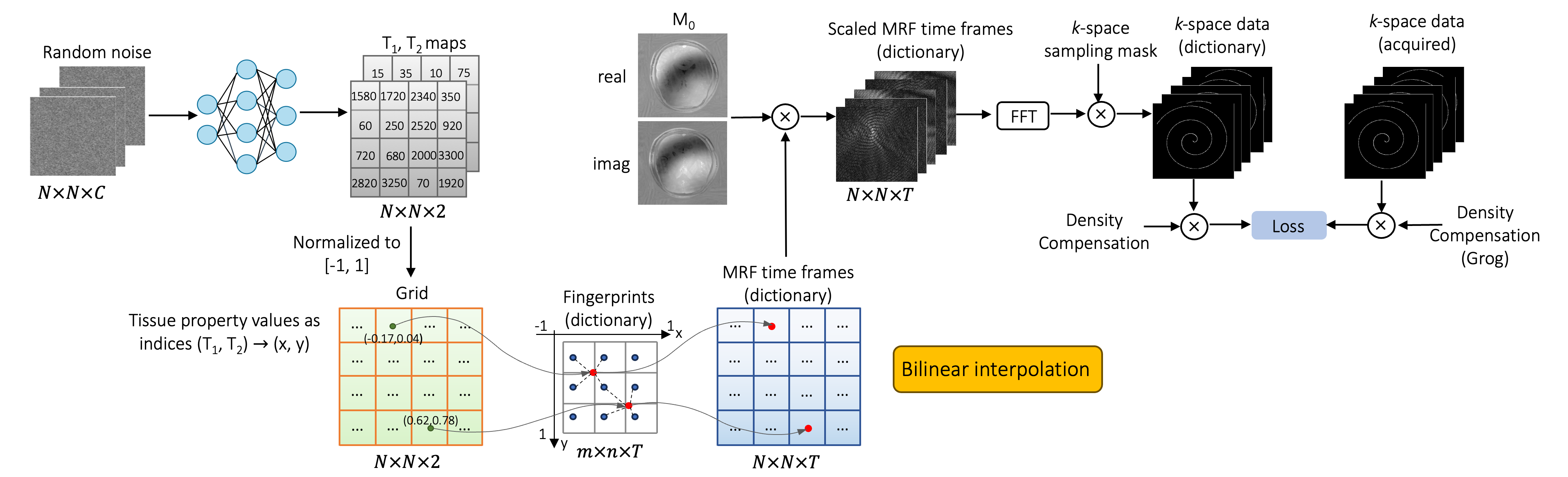
This work aims to reduce reliance on training datasets for deep learning based MR Fingerprinting (MRF) [1] for simultaneous T1 and T2 mapping. We propose a novel zero-shot self-supervised MRF framework where a deep network is optimized to predict tissue property parameters such that their associated voxel-wise fingerprints in the dictionary match the acquired fingerprints in terms of their k-space measurements. Particularly, we use the predicted tissue property pairs as indices for retrieving each fingerprint from the dictionary efficiently via bilinear interpolation, which is differentiable and amenable to GPU processing. Network optimization is performed de novo for each MRF scan using only its undersampled k-space measurements. Our method demonstrates promising results on 2x and 4x accelerated MRF without requiring supervised training based on tissue property maps estimated from fully sampled data, laborious reconstruction, explicit dictionary matching, and network pre-training.Method
The overview of our framework is shown in Fig. 1. A 5-level U-Net [2] is trained in a self-supervised manner to enforce consistency between the predicted and acquired fingerprints via an MRF forward model. The typical forward model includes a) retrieving the MRF signal evolutions from an MRF dictionary given the tissue property maps, b) coil sensitivity encoding, c) Fourier transform, and d) k-space undersampling. We observe that the tissue property values, when normalized, can be used as indices for retrieving the corresponding fingerprints from the dictionary. Hence, we accelerate the retrieval process by directly letting the network output a spatial grid of size N x N x 2 with continuous index values normalized to [-1, 1]. The dictionary is then interpolated onto the grid to generate the predicted MRF time frames. As a preprocessing step, the tissue values in the dictionary are first sorted in ascending order and then rearranged as a table of size m x n, where m, n is the number of unique T1 and T2 values, respectively. Correspondingly, the fingerprints in the dictionary are also rearranged as m x n x T, where T denotes the number of time points of each fingerprint. The consistency between the predicted and the acquired k-space measurements is measured by MAE loss. After training, the tissue property maps are readily obtained simply by un-normalizing the predicted indices.Considering the memory cost brought by the high dimensionality of MRF data, we train for each coil data individually and combine their outputs as the final result. To avoid the time-intensive non-uniform fast Fourier Transform (NUFFT), the MRF spiral k-space data are first gridded to Cartesian locations using GROR [3] and the visitation count for each location is recorded for density compensation.
All imaging was performed on a Siemens 3T Prisma scanner with a 32-channel head coil. The fast imaging with steady state precession (FISP) sequence was used for acquiring the MRF data of axial human brain slices. A total of 2,304 time points were acquired for each scan only for evaluation purposes. Retrospectively undersampled MRF data with 25% and 50% of the total time points are used for training, i.e., 576 and 1152 time points. Other imaging parameters: FOV, 30 cm; matrix size, 256x256; slice thickness, 5 mm; flip angles, 5°~12°.
Results and Discussion
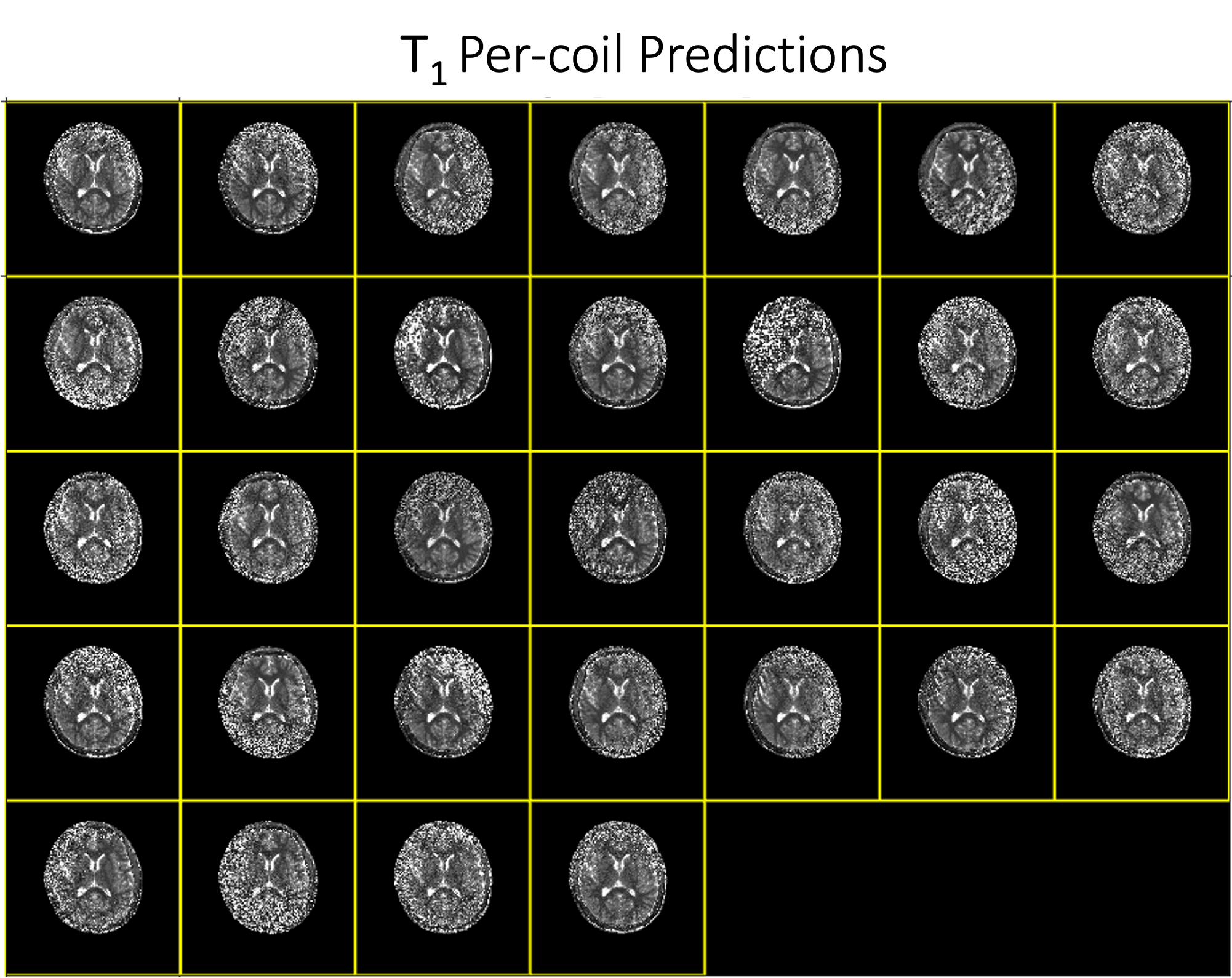
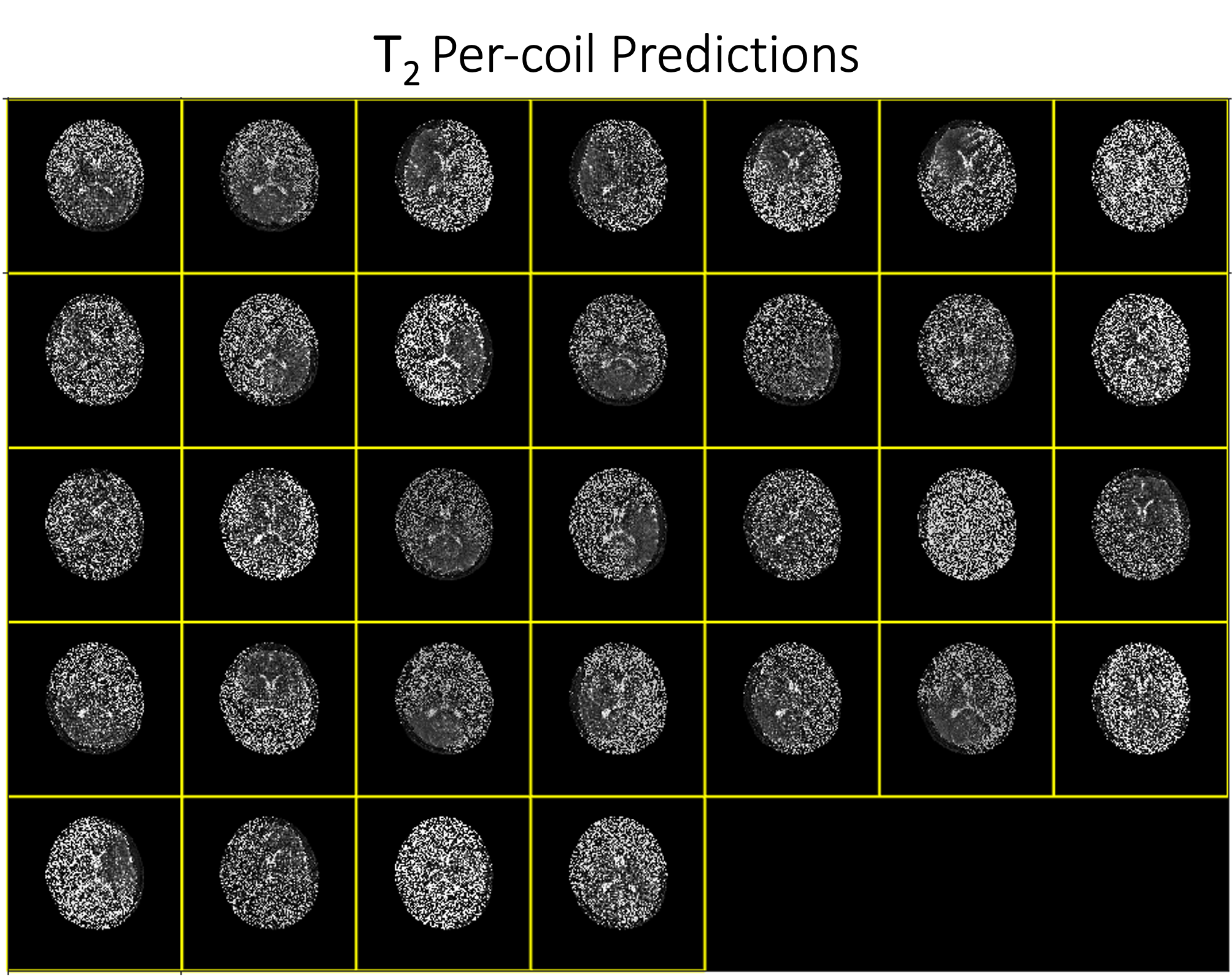
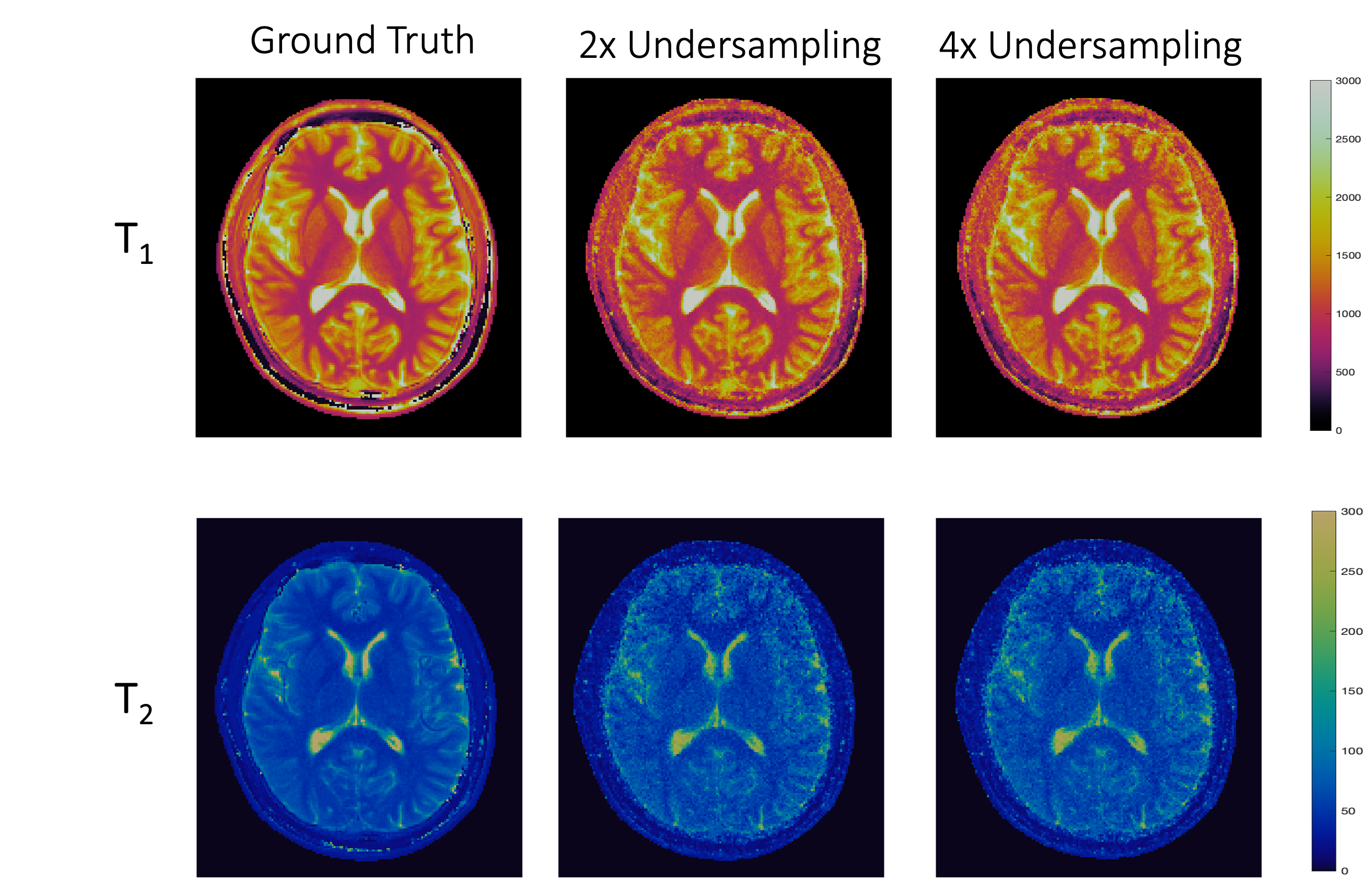
We conducted experiments for a proof of concept. Fig. 2 and Fig. 3 show the estimated T1 and T2 maps for each coil. Fig. 4 qualitatively shows the results with all coils combined, and Fig. 5 summarizes the quantitative results. The results show that T1 quantification using our method is generally more accurate than T2 quantification. This may be partially due to the inherently noisy coil data, which we used for training to alleviate the memory burden. Performance is likely to be improved when more computational resources are available for training with multi-coil data or by using a more parsimonious network architecture. Overall, these preliminary results validated the feasibility of zero-shot self-supervised MRF reconstruction with the help of physics-based constraints.Conclusion
In this work, we introduced a zero-shot self-supervised framework for MRF. We proposed strategies to rapidly retrieve fingerprints from the dictionary for efficient network training. Our method involves minimal data processing. We demonstrated method validity and performance with undersampled MRF data.Acknowledgements
This work was supported in part by National Institutes of Health (NIH) under grant R01CA266702.References
[1] Ma, et al. Nature, pp. 187–192, 2013.
[2] Ronneberger, et al. MICCAI, 2015.
[3] Seiberlich, et al. MRM, 2007.
Figures