2927
Segmentation of Deep Gray Matter Nuclei with Imperfect Annotations and Anatomy A Priori Embedded in Template1Shanghai Key Laboratory of Magnetic Resonance, East China Normal University, Shanghai, China, 2Department of Radiology, Ruijin Hospital, Shanghai Jiao Tong University School of Medicine, Shanghai, China, 3Philips Healthcare, Shanghai, China, 4Siemens Healthineers Ltd., Shanghai, China, 5Radiology, Wayne State University, Detroit, MI, United States, 6Department of Biomedical Engineering, Wayne State University, Detroit, MI, United States
Synopsis
Keywords: Gray Matter, Neuro
Motivation: Automated segmentation enables objective and repeatable quantitative analysis of deep gray matter nuclei, which is essential to Parkinson’s disease (PD) studies.
Goal(s): To combine the strengths of a classic segmentation algorithm and deep learning to achieve robust segmentation of deep gray matter nuclei without manual annotation.
Approach: A brain nuclei template was created to generate template-based ROIs containing anatomical priori information. A classic segmentation algorithm was used to create imperfect algorithm-based ROIs, which were combined with template-based ROIs for training of a segmentation deep learning (DL) model.
Results: The proposed model has achieved encouraging results, and still has room for improvement.
Impact: Accurate and automatic segmentation for deep gray matter nuclei is essential to PD studies. The proposed DL segmentation model requires no manual annotations and may make the automatic segmentation more accessible for large datasets.
INTRODUCTION
Parkinson’s disease (PD) is a neurodegenerative movement disorder, whose pathophysiology is associated with changes in deep grey matter nuclei volume and iron content1. Automated brain nuclei segmentation is the prerequisite for objective and reproducible downstream quantitative analysis. Deep learning (DL) has achieved remarkable success in medical image segmentation2, however, it requires large training data with pixel-level annotation, which is both expensive and time-consuming. In contrast, classic segmentation algorithms can accomplish the task without manual annotation, but they often produce discrepant results. DL combined with classic algorithms may be able to take advantage of the strengths of both methods. Thus, we proposed a new scheme which uses the priori anatomical knowledge embedded in template to regularize the training of a segmentation model with imperfect annotations generated by a classic algorithm. The template-guided framework can simultaneously segment the caudate nucleus (CN), globus pallidus (GP), putamen (PUT), red nucleus (RN), substantia nigra (SN), and dentate nucleus (DN) on T1W and quantitative susceptibility mapping (QSM) images, without using manual annotations.METHODS
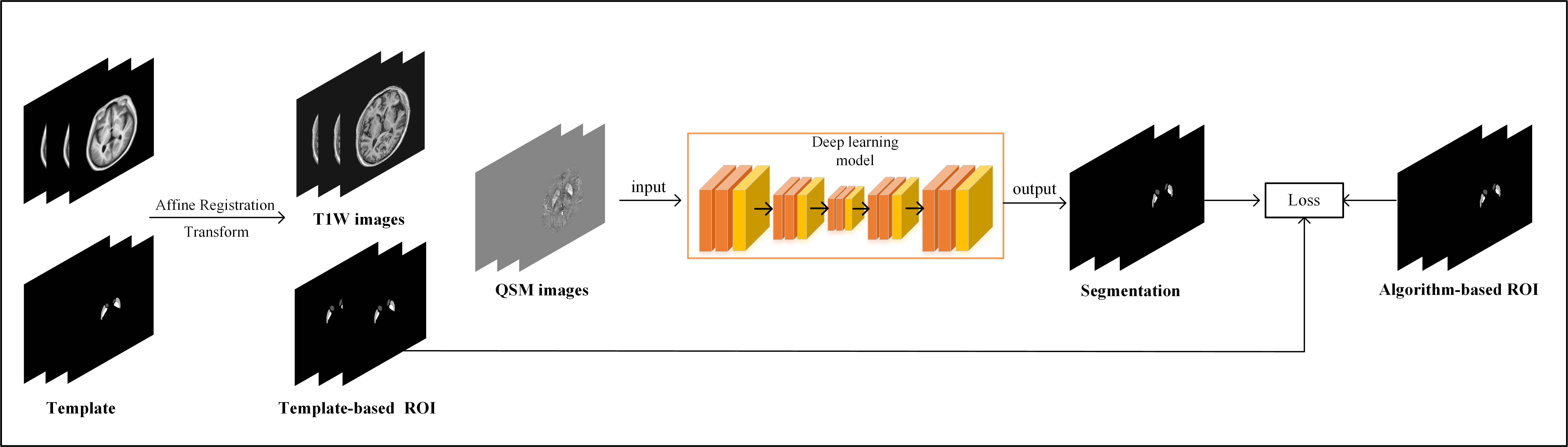
We retrospectively collected 1514 cases scanned with STAGE 3 protocol on two Philips 3.0T scanners. The dataset was randomly split into a template cohort (60 cases), a training cohort (1117 cases), and an independent test cohort (337 cases), which were used for template creation, model training and model evaluation, respectively. A previously-reported algorithm4 was utilized to create algorithm-based ROIs for all cases, while two neuroradiologists segmented the brain nuclei manually for cases in the template and test cohorts.The flowchart of this study is shown in Figure 1. One representative case in the template cohort was selected and T1W images of the remaining 59 cases were registered to it using affine transformation. The transformed images and ROIs were averaged to create a brain nuclei template. For each case in the training cohort, T1W images were aligned to the template to obtain the transformation field, which was used to obtain a template-based ROI. Then, the T1W, QSM, template-based ROI and algorithm-based ROI were used to train the network for precise segmentation (Figure 2).
In the encoder of network, T1W and QSM images were input into two parallel branches to extract modality-specific features. Cross modality module5 was utilized to capture cross-modality interactions. Transformer was used to extract global features in the last encoder layer. In the decoder, the modality-weighted features created by the encoder were concatenated with deconvolutional features through skip connection. The template-based ROI was input into the anatomical gate to guide the segmentation. In the multi-scale features aggregation stage, features created at four different scales of the decoder were upsampled to the same size and concatenated before a scale attention module6 was used to create nuclei segmentation.
Combination of Dice and focal loss was used as loss function. The intersection (consistent) and symmetric difference (inconsistent) of the template-based and algorithm-based ROIs were assigned different weights to make use of both types of ROIs:
$$L_{dice}=1-\frac{2}{K}\sum_{k\in K}^{}\frac{ {\textstyle \sum_{i\in I}^{}} p_{i}^{k}g_{i}^{k}}{ {\textstyle \sum_{i\in I}^{}p_{i}^{k}+ {\textstyle \sum_{i\in I}^{}g_{i}^{k}} } }$$
$$L_{focal}=-\frac{1}{K}\sum_{k\in K}^{} \sum_{i\in I}^{} (\alpha (1-p_{i}^{k})^\gamma g_{i}^{k}log(p_{i}^{k}) + (1-\alpha ){p_{i}^{k}}^\gamma (1-g_{i}^{k}) log(1-p_{i}^{k}) )$$
$$Loss=0.8\times (L_{{dice}}^{consistent} + L_{{focal}}^{consistent}) + 0.2\times (L_{{dice}}^{difference} + L_{{focal}}^{difference}) $$
where K is the number of nuclei to segment, gi and pi represent label and predicted probability of the voxel i, and N is the is the number of total voxels. Hyper-parameters α and γ were set to 0.25 and 2, respectively.
Online data augmentation of random shifting, rotation, flip and elastic transformation were used in training. Adam optimizer with an initial learning rate of 10-3 was used to minimize the loss and the batch size was 2. The training process was stopped if the validation loss did not decrease for 20 epochs.
RESULTS
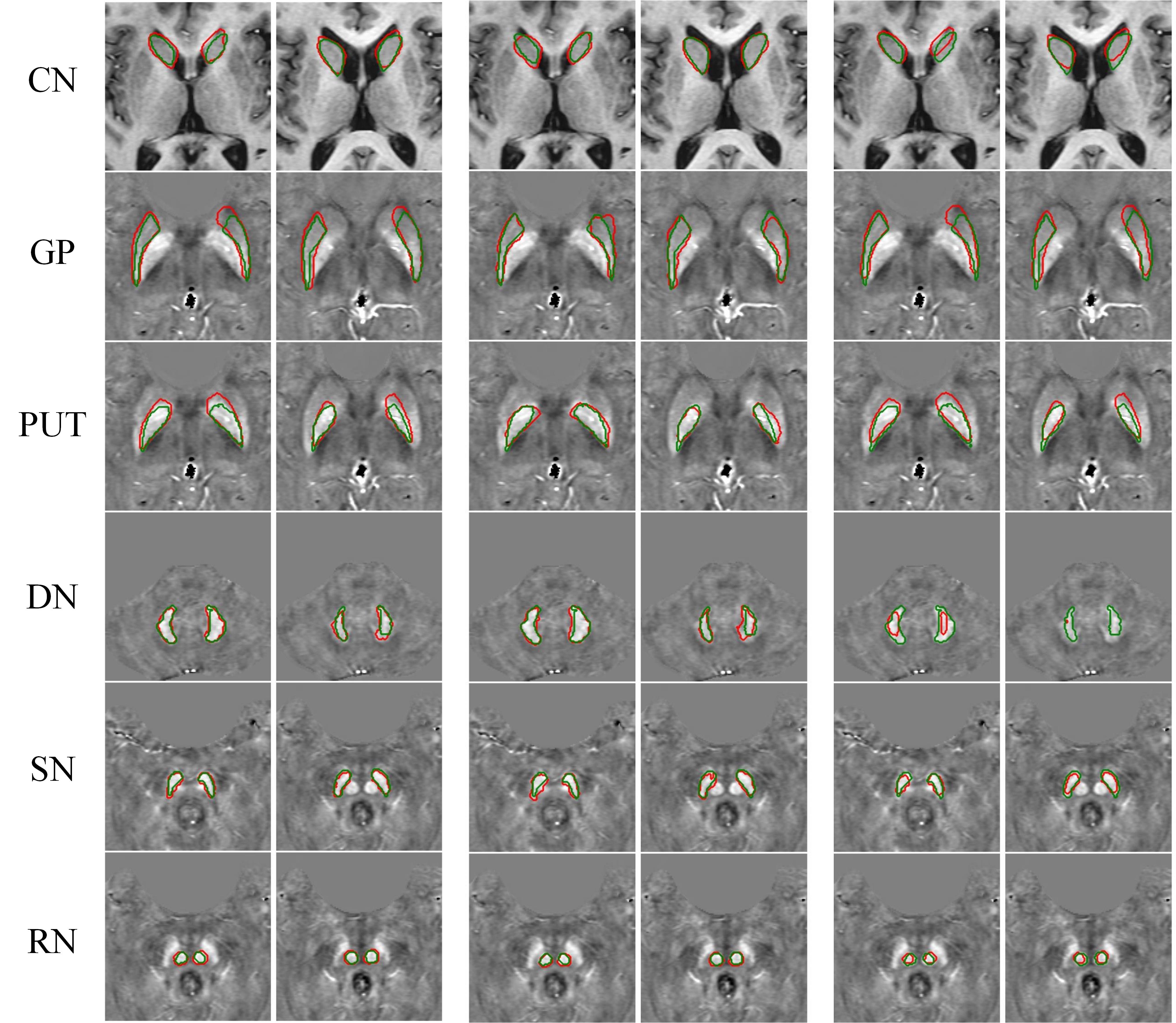
In the test cohort, the proposed model achieved mean Dice scores of 0.723 ± 0.096, 0.773 ± 0.050, 0.763 ± 0.067, 0.717 ± 0.095, 0.714 ± 0.086, and 0.750 ±0.082 for CN, GP, PUT, DN, SN, and RN, respectively. Performance metrics of different algorithms are listed in Table 1, and the visual comparation is shown in Figure 3.DISCUSSION AND CONCLUSION
To combine the strengths of both classic algorithm and DL model, we created a brain nuclei template, which was used to regularize segmentation model training using algorithm-based ROIs. Compared with previous studies7 on brain nuclei segmentation, no manually annotated ROIs were used in model training. Though the performance of the proposed algorithm has room for improvement, the current results are encouraging. In the future, new network structure and loss functions can be designed to further improve the model performance while minimizing the annotation workload.Acknowledgements
This work was supported by the National Natural Science Foundation of China (grant number: 82271954, 81971576, 61731009). This work was supported by Xing-Fu-Zhi-Hua Foundation of ECNU, Microscale Magnetic Resonance Platform of ECNU, and the Open Project of Shanghai Key Laboratory of Magnetic Resonance. This work was supported, in part, Chinese National Science & Technology Pillar Program (grant number: 2022YFC2009900/2022YFC2009905) and the Innovative Research Team of High-level Local Universities in Shanghai.References
1. Feigin V L, Abajobir A A, Abate K H, et al. Global, regional, and national burden of neurological disorders during 1990–2015: a systematic analysis for the Global Burden of Disease Study 2015. The Lancet Neurology, 2017, 16(11): 877-897.
2. Chen X, Wang X, Zhang K, et al. Recent advances and clinical applications of deep learning in medical image analysis. Med Image Anal. 2022;79: 102444.
3. Chen Y, Liu S, Wang Y, et al. STrategically Acquired Gradient Echo (STAGE) imaging, part I: Creating enhanced T1 contrast and standardized susceptibility weighted imaging and quantitative susceptibility mapping. Magn Reson Imaging. 2018; 46:130-139.
4. Jokar M, Jin Z, Huang P, et al. Diagnosing Parkinson's disease by combining neuromelanin and iron imaging features using an automated midbrain template approach. Neuroimage. 2023; 266:119814.
5. Zhang Y, Yang JW, Tian J, et al. Modality-Aware Mutual Learning for Multi-modal Medical Image Segmentation, Lect Notes Comput Sc. 2021; 12901: 589-599.
6. Gu R, Wang G, Song T, et al. CA-Net: Comprehensive Attention Convolutional Neural Networks for Explainable Medical Image Segmentation. IEEE Trans Med Imaging. 2021;40(2):699-711.
7. Wang Y, He N, Zhang C, et al. An automatic interpretable deep learning pipeline for accurate Parkinson's disease diagnosis using quantitative susceptibility mapping and T1-weighted images. Hum Brain Mapp. 2023;44(12):4426-4438.
Figures