2830
Synthesising 3T DWI from ultra-low-field (64mT) acquisitions using generative diffusion models1University of Queensland, Brisbane, Australia, 2Monash University, Melbourne, Australia
Synopsis
Keywords: Low-Field MRI, Low-Field MRI
Motivation: Diffusion-weighted Imaging (DWI) at very-low fields like the 0.064 Tesla Hyperfine Swoop is limited by low signal-to-noise ratio (SNR), impeding clinical application.
Goal(s): This study aims to enhance DWI at such low fields by creating synthetic high-field images using pre-trained neural networks.
Approach: The Diffusion Probabilistic Model (DPM), an advanced generative AI, will be trained on high-quality 3T DWI images to learn their distribution. Low-field DWI images guide the DPM to conditionally synthesize high-quality images.
Results: With a well-trained DPM, we aim to produce high-quality, synthetic 3T-like DWI images that mirror the original low-field ones, bypassing the need for paired training data.
Impact: The method enhances DWI image quality at very-low field strength in an unsupervised manner, eliminating the need for paired high-field and low-field data, thus expanding training data availability. Zero-shot image reconstruction enhances its generalizability for diverse tasks.
Introduction
Ultra-low-field (ULF) MRI systems offer several advantages over conventional high-field MRI, such as improved safety, lower costs, and greater portability. Nonetheless, they are hindered by inferior spatial resolution and signal-to-noise ratio (SNR), which compromise the quality of intricate imaging sequences like diffusion-weighted imaging (DWI). The prevailing strategy for overcoming these limitations has been the application of deep learning algorithms to convert low-field images into high-field equivalents. However, this typically requires supervised learning that depends on the availability of paired images for model training. Given the limited global implementation of ULF MRI systems and the practical challenges associated with patients undergoing both ULF and high-field MRI procedures, this requirement presents a substantial obstacle.Addressing this gap, our study introduces an innovative unsupervised learning strategy utilizing a cutting-edge generative AI model: the diffusion probabilistic model. This abstract will elucidate the process of leveraging low-field MRI measurements as the data consistency term to guide the controllable generation of synthetic high-quality 3T DWI images, substantially enhancing image resolution and quality of ULF DWI.
Methods
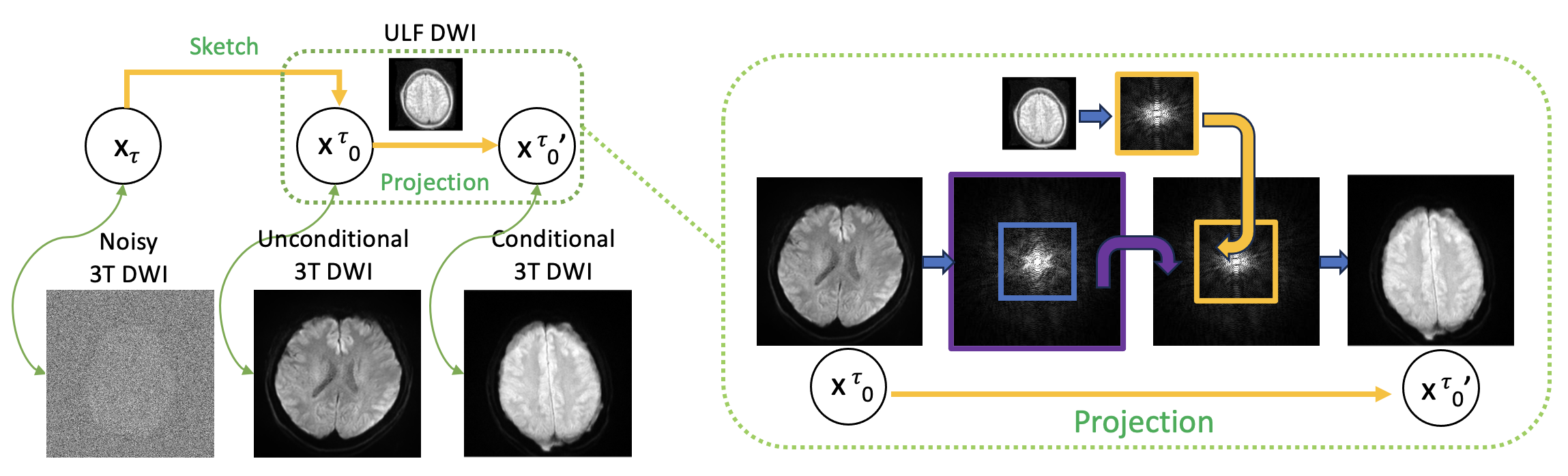
Denoising Diffusion Implicit Model (DDIM): DDIM [1] is a generative diffusion model, which can generate samples 10 to 50 times faster and can reuse pre-trained DDPM models. The DDIM paper highlighted that many non-Markovian diffusion processes could have identical marginals $$$q(\mathbf{x}_{t}\mid\mathbf{x}_{0})$$$ as DDPMs, and developed a more general reverse process (Figure 1):$$\mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \cdot \underbrace{\frac{\mathbf{x}_{t} - \sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_{t},t)}{\sqrt{\bar{\alpha}_{t}}}}_{\text{predicted } \mathbf{x}_{0} \text{ from step } t} + \sqrt{1-\bar{\alpha}_{t-1} } \cdot \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_{t},t) \label{eq_ddim2}$$As shown in Figure 1 and the above equation, the unconditional DDIM involves a rough prediction of the noise-free sample $$$\mathbf{x}_0$$$ during each reverse step. The conditional sampling method adds an extra correction sub-step by projecting the estimated $$$\mathbf{x}_0$$$ onto the ULF k-space measurement hyperplane of $$$\{\mathbf{x} \mid \mathbf{\Lambda}\mathbf{F}\mathbf{x} = \mathbf{y}\}$$$, where $$$\mathbf{y}$$$ is the ULF k-space measurement and $$$\mathbf{\Lambda}$$$ is the binary mask indicating central low-frequency k-space region of the high-field DWI for data consistency, as shown in Figure 1. The conditional reverse step can be formulated as:$$\mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \cdot \text{Proj} \underbrace{\frac{\mathbf{x}_{t} - \sqrt{1-\bar{\alpha}_{t}} \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_{t},t)}{\sqrt{\bar{\alpha}_{t}}}}_{\text{predicted } \mathbf{x}_{0} \text{ from step } t} + \sqrt{1-\bar{\alpha}_{t-1} } \cdot \boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\mathbf{x}_{t},t) \label{eq_ddim_orig}$$Here, the 'Proj' operator enforces data consistency [2]. To be more specific, the center and low-frequency k-space portion extracted from the predicted $$$\mathbf{x}_0$$$ is substituted with the k-space from the lower-resolution DWI image acquired via ULF MRI, ensuring data consistency. Training and Sampling Procedures: A dataset comprising 500 DWI images from a 3T scanner, each with dimensions of 256 by 256 pixels, was used to train the diffusion model employing the Variational Diffusion Model (VDM) architecture [3], an enhancement over the original DDPM. We integrated this model with a 32-depth U-Net, which was trained on an A100 GPU equipped with 40 GB of memory over two days. The process was set to iterate over 1000 steps. On the aforementioned GPU, generating a batch of four images takes approximately 2 minutes. During the conditional sampling phase, ULF DWI images with a resolution of 62 by 62 pixels served as the measurement input for the 'Proj' operator. This enforced data consistency, ensuring that the synthetically sampled high-resolution 3T DWI images retained the same central k-space characteristics as the original measurements from the ULF scanner.Results
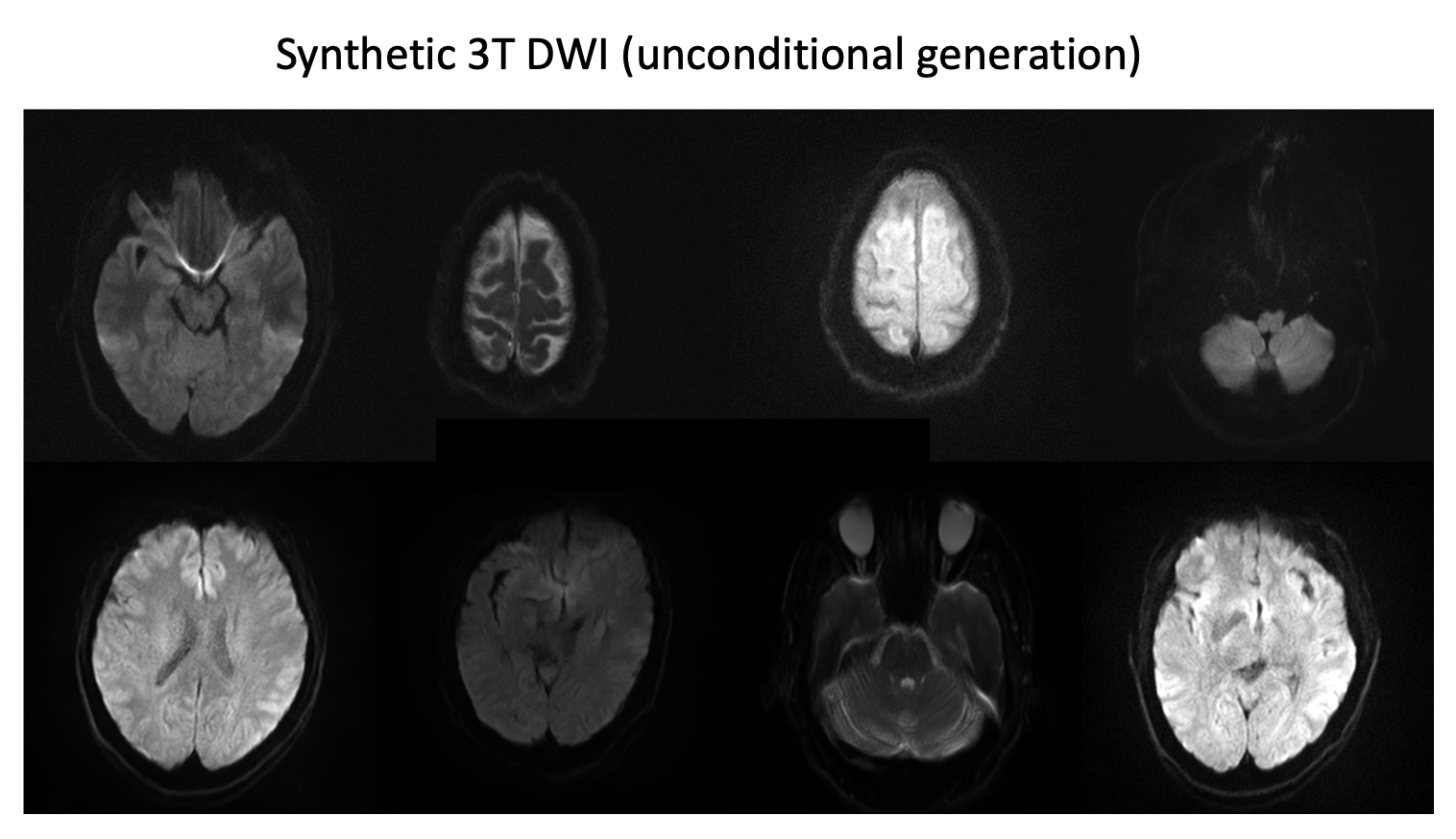
Figure 1 illustrates the conditional sampling workflow of DDIM, incorporating a projection phase to ensure data consistency with ULF MRI inputs.Figure 2 displays synthetic 3T DWI images produced unconditionally from the DDIM model, exhibiting high fidelity and inclusion of common DWI artifacts, which contributes to their realistic appearance. The variety in brain morphology and slice positioning further enhances the diversity of the dataset.
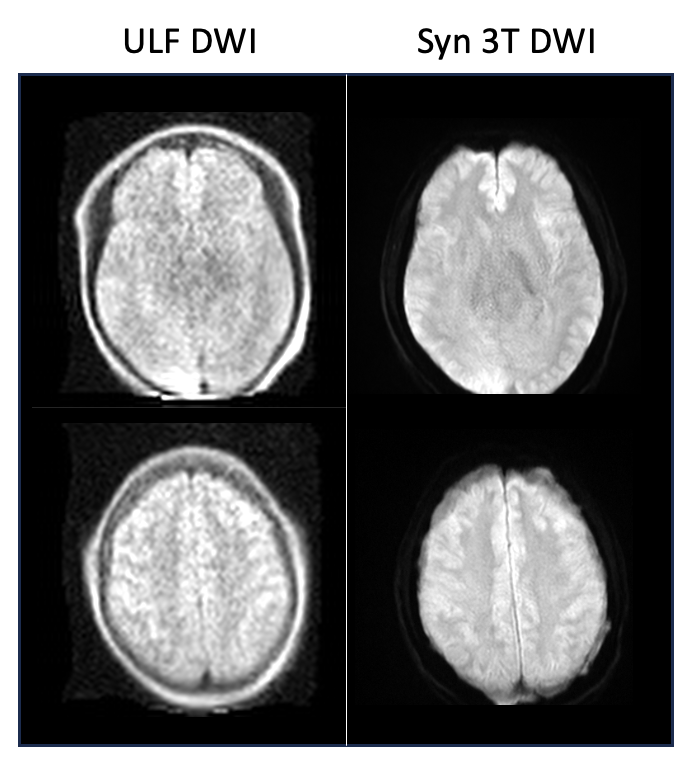
Figure 3 offers a comparative view of an original ULF DWI against its synthetic 3T counterpart. The ULF image suffers from low SNR and resolution, which limits its clinical utility, while the synthetic 3T image shows a marked improvement in both aspects, closely mirroring an image acquired directly from a 3T scanner.
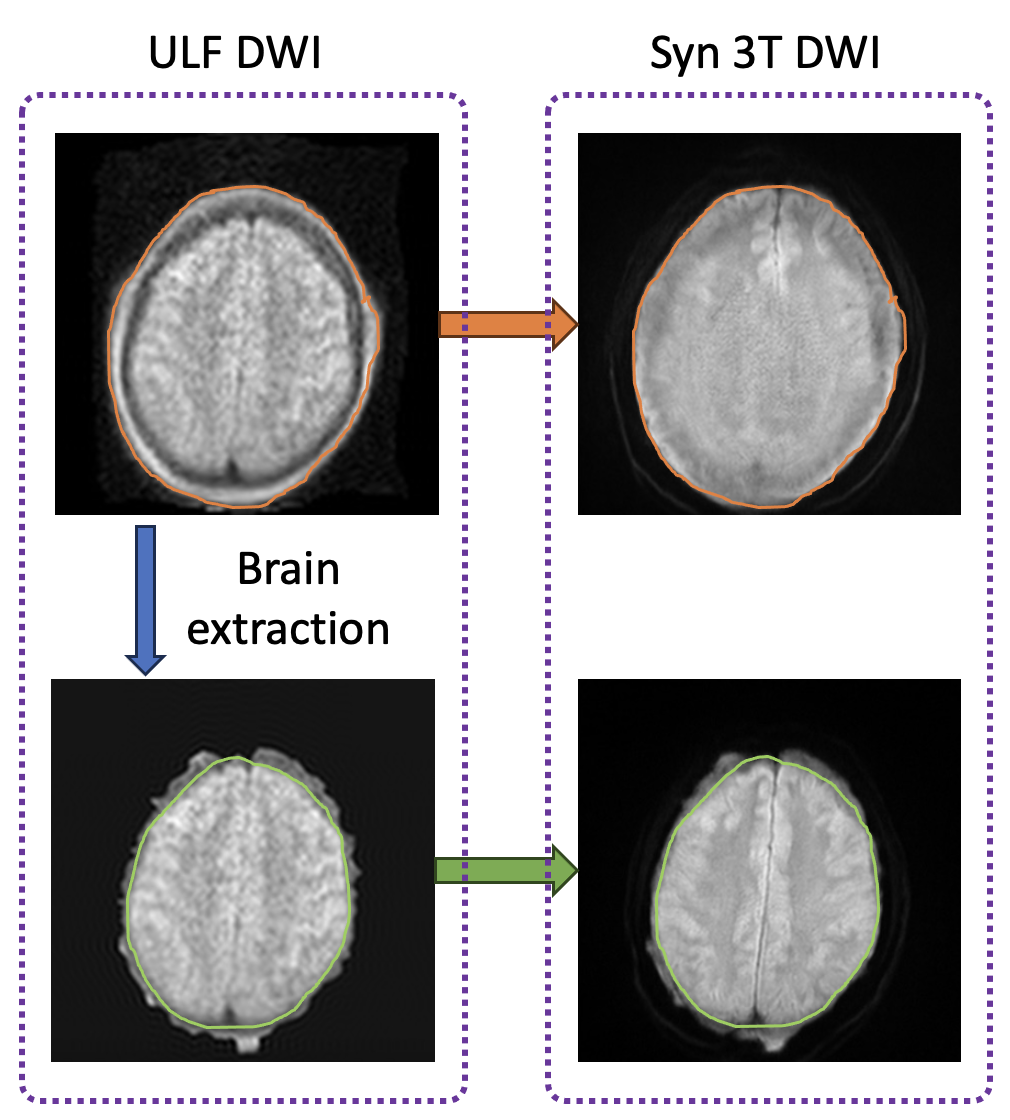
Figure 4 underlines the significance of skull stripping in this imaging approach. It highlights how the bright skull contrast in ULF DWI images, if not removed, can lead to confusion during the conditional sampling, potentially causing the model to misclassify skull as brain tissue. Properly executed skull stripping prior to the sampling process significantly refines the accuracy of the generated 3T images.
Discussion
Our preliminary findings show that advanced diffusion probabilistic models can successfully create synthetic 3T DWI images, using ULF measurements to guide the sampling. This technique could potentially apply to other imaging beyond ULF DWI, provided that the inherent differences between low- and high-field images are properly managed.Acknowledgements
This study was funded by the National Imaging Facility (NIF) and Hyperfine Inc. We thank the NIF, an NCRIS capability, for their facilities and invaluable support at Monash Biomedical Imaging, Monash University and the School of Electrical Engineering and Computer Science, University of Queensland. HS acknowledges support from the Australian Research Council (DE210101297, DP230101628).References
1. Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprintarXiv:2010.02502 (2020).
2. Song Y, Shen L, Xing L, Ermon S. Solving inverse problems in medical imaging with score-based generative models. arXiv preprint arXiv:2111.08005. 2021 Nov 15.
3. Kingma D, Salimans T, Poole B, Ho J. Variational diffusion models. Advances in neural information processing systems. 2021 Dec 6;34:21696-707.
Figures