2802
Latent-Optimized Adversarial Regularizers for accelerated MRI1School of Mathematical Sciences, Inner Mongolia University, Hohhot, China, 2Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 3Inner Mongolia Medical University, Hohhot, China, 4Reasearch Center for Medical AI, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Image Reconstruction, regularization method, interpretability, adversarial training
Motivation: Introduce latent optimization techniques to enhance the interpretability of learnable regularization methods, thereby improving the performance of MRI acceleration reconstruction.
Goal(s): Theoretically, we aim to elucidate the iterative direction of learnable regularization methods. Experimentally, we aim to achieve high-quality reconstruction of undersampled MRI data.
Approach: Revise the optimization objective of the network by incorporating a stochastic gradient descent generator, training learnable regularizers that guide the latent process during iteration, and accomplish reconstruction using the projected gradient method.
Results: Compared to other regularization methods, proposed method achieved a higher level of interpretability and accomplished higher-quality reconstruction.
Impact: The method directly learns the distribution information of real data and guides the iteration towards the real data manifold. We believe that the method and its theoretical properties are undoubtedly inspiring for researchers seeking to further acquire data distribution information.
Introduction
The acquisition of signals in MRI is a time-consuming process. Hence, there is an urgent need to address the challenge of accelerating the imaging speed in MRI. In recent years, with the advancement of hardware platforms, deep learning methods have witnessed significant development and demonstrated remarkable performance in various image processing tasks, including MRI reconstruction[1]-[3]. However, many deep learning approaches are data-driven and directly learn mappings from input to reconstructed images, lacking robustness and interpretability.To address the aforementioned limitations, a learnable regularization approach that integrates DL with regularization models has been introduced[4]-[5]. Notably, Lunz et al.[6] proposed Adversarial Regularizers (AR) trained by neural networks. They primarily aimed to develop regularizers capable of effectively representing the distance between the initial input and the real image manifold through adversarial learning. This represented a significant advancement in enhancing the interpretability of deep learning methods. However, a key limitation of this approach is that AR can only measure the distance between the initial input and the real image manifold. As the iterations progress, there may be a failure to maintain alignment between latent iterations and the relationship between the initial input and the actual data distribution, ultimately leading to errors in the iterative reconstruction. This limitation results in incomplete interpretability and poor performance of the AR method.
Although there are some defects, the idea of Lunz et al. is very pioneering. Based on their work, we introduced the technique of latent optimization, ultimately guiding the iterations towards the real data manifold. We proposed the Latent-optimized Adversarial Regularizers (LoAR) with both good interpretability and high performance.
Method
In this abstract, we presented the Latent-optimized Adversarial Regularizers (LoAR), which were defined as the solution to the following optimization problem:\begin{equation}\label{eq3}\arg\sup\limits_{f\in \Gamma } {\min_{x \in X}{f\left ( x \right ) } - \mathbb{E} _{ x^{+}\sim \mathbb{P} _{r} }\left[ f\left ( x^{+}\right ) \right ]} \quad \left ( 1 \right ) \end{equation}
where $$$\Gamma$$$ represents the set of 1-Lipschitz continuous functions with a lower bound, $$$X$$$ denotes a finite-dimensional normed space in which the samples are located, $$$\mathbb{P} _{r}$$$ is the distribution of true data $$$\left \{ x^{+} \right \} $$$. Such a solution $$$f\left ( x \right )$$$ can assess whether the sample $$$x$$$ resides on the real data manifold.
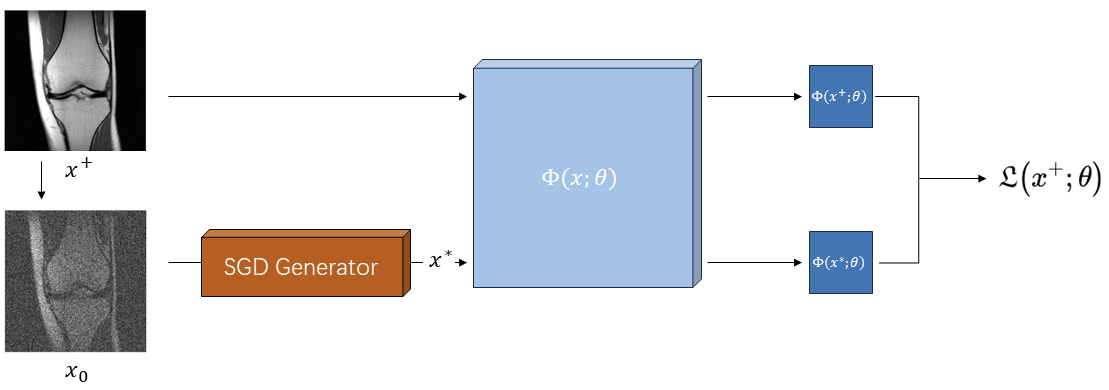
To find such a solution $$$f\left ( x \right )$$$, we adopted the neural network $$$\Phi \left ( x;\theta \right ) $$$ to represent $$$f\left ( x \right )$$$. We aimed to train the eligible $$$\Phi \left ( x;\theta \right )$$$ using the loss function of the neural network. To compute the expectation in (1), we replaced it with a simple average of the training samples. For the term $$$\min\limits_{x \in X}{f\left ( x \right )}$$$, in this study, we introduced significant levels of noise interference to real images represented by $$$x^{+}$$$, generating the input images $$$x_{0}$$$, and employed stochastic gradient descent(SGD) during training to solve $$$\min\limits_{x\in X}\Phi \left ( x;\theta \right )$$$, generating corresponding samples $$$x^{*}$$$.
The loss function utilized the Wasserstein loss with a gradient penalty term to ensure the 1-Lipschitz continuity property of the nets.
$$\mathfrak{L}\left ( x^{+};\theta \right )= \frac{1}{n}\sum_{i=1}^{n}{\Phi\left ( x^{+}_{i};\theta \right )}- \frac{1}{n}\sum_{i=1}^{n}{\Phi\left ( x^{*}_{i};\theta \right )} + \lambda\cdot \mathbb{E}\left [ \left (\left \| \bigtriangledown _{x} \Phi\left ( x;\theta \right )\right \| -1\right )^{2} \right ]$$
The entire training process is illustrated in Fig.1.
When the training of LoAR was completed, we utilized the iterative method to reconstruct the undersampled image. In other words, we solve the optimization problem,$$x=\arg\min\limits_{x\in X}{\left \| Ax-b \right \| +\lambda f\left ( x \right )}$$In this study, we employed the projected gradient descent method.
Result
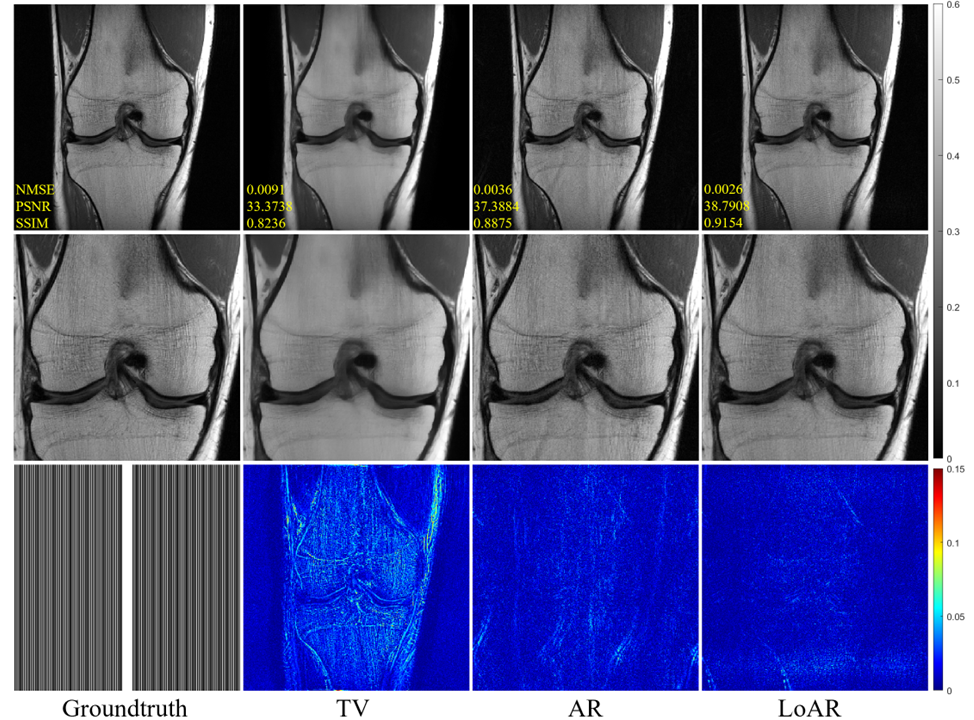
The evaluation was performed on the knee and brain MR dataset. Considering that LoAR is a regularization method, we included several other regularization methods for comparison. These methods include TV regularization[7], a classical regularization technique, and AR (Adversarial Regularization)[6], which has not only inspired our current research but is also a deep learning approach.Fig 2. displays the results of the comparative experiment under uniform threefold acceleration using knee data.
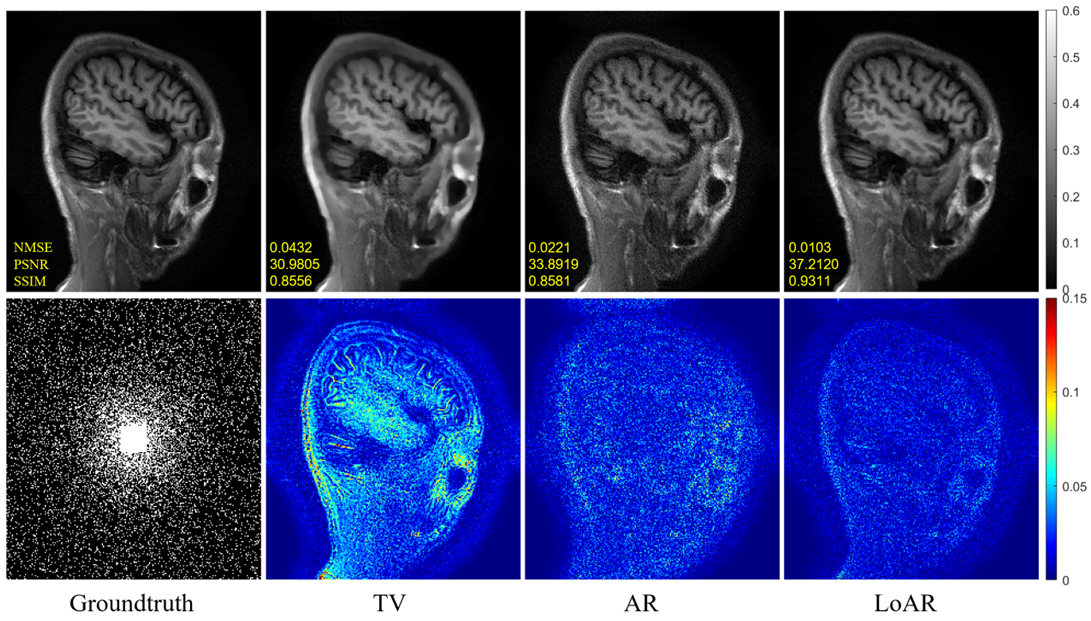
Fig 3. displays the results of the comparative experiment under random 6-fold acceleration using brain data.
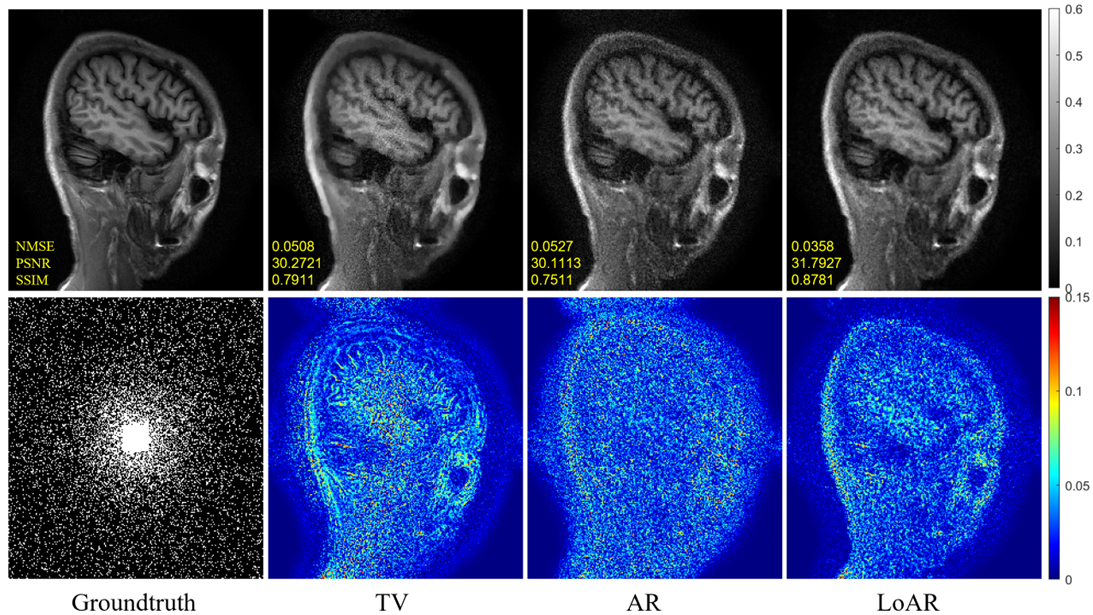
Fig 4. displays the results of the comparative experiment under random 6-fold acceleration using brain data with 50% standard Gaussian noise added to its normalized k-space data.
Conclusion
LoAR fully utilizes the prior information in the data and possesses good interpretability. The learned regularizers through deep learning can be used to measure the distribution position of samples and whether they reside on the true data manifold. Experimental results demonstrated that compared to other regularization methods, LoAR achieved high-quality reconstruction results on multiple datasets and exhibits good robustness when dealing with data contaminated by noise.Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (U21A6005, 62125111, 12026603, 62206273, 62201561,62106252, 61771463, 81830056, U1805261, 81971611, 61871373, 81729003, 81901736); National Key R&D Program of China (2020YFA0712202, 2021YFF0501503 and 2022YFA1004202); Natural Science Foundation of Guangdong Province, China (2018A0303130132); Shenzhen Key Laboratory of Ultrasound Imaging and Therapy (ZDSYS20180206180631473); Shenzhen Peacock Plan Team Program (KQTD20180413181834876); Innovation and Technology Commission of the government of Hong Kong SAR (MRP/001/18X); Strategic Priority Research Program of Chinese Academy of Sciences (XDB25000000).References
[1] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing, 2015.
[2] Cui, Zhuo-Xu, et al. "K-UNN: k-space interpolation with untrained neural network." Medical Image Analysis 88 (2023): 102877.
[3] Wang, Shanshan, et al. "DIMENSION: dynamic MR imaging with both k‐space and spatial prior knowledge obtained via multi‐supervised network training." NMR in Biomedicine 35.4 (2022): e4131.
[4] Aggarwal, Hemant K., Merry P. Mani, and Mathews Jacob. "MoDL: Model-based deep learning architecture for inverse problems." IEEE transactions on medical imaging 38.2 (2018): 394-405.
[5] Zhang, Jian, and Bernard Ghanem. "ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[6] Lunz S, Öktem O, Schönlieb C B. Adversarial regularizers in inverse problems[J]. Advances in neural information processing systems, 2018, 31.
[7] Rudin, Leonid I., Stanley Osher, and Emad Fatemi. "Nonlinear total variation based noise removal algorithms." Physica D: nonlinear phenomena 60.1-4 (1992): 259-268.
Figures