2801
Denoising very low field magnetic resonance images using native noise modeling and deep learning1Department of physiology, Makerere University, Kampala, Uganda, 2Department of Electrical and Computer Engineering, Makerere University, Kampala, Uganda, 3Accessible MR Laboratory, Icahn School of Medicine at Mount Sinai, New York, NY, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Low-Field MRI, Denoising, Native noise
Motivation: Low-field MRI (LF-MRI) can increase accessibility in low-income countries where high-field MRI is not available due to cost, power and siting requirements. However, noise significantly affects LF-MR image quality.
Goal(s): This study aims to enhance the signal-to-noise ratio (SNR) in very LF-MRI (0.05T) images using native noise modeling and deep learning.
Approach: We extracted noise from 0.05T phantom MRI images, modeled it, added it to high-field brain MRI (1.5T & 3T), trained two deep-learning algorithms, and evaluated them on in vivo brain MRI images.
Results: Our approach improves the SNR of in-vivo LF images by a factor of approximately two.
Impact: Using native noise while developing deep-learning denoising algorithms for LF-MRI images is better than using synthetic random noise. As a result, the developed algorithms are more explainable and follow domain knowledge on noise in LF-MRI improving trust in the models.
Introduction
Magnetic resonance imaging (MRI) is widely used to diagnose neurological disorders, but its accessibility has remained limited to just one-third of the global population as of 20181. The primary barriers to broader access are the complex nature of MRI system development, construction, maintenance, and substantial installation costs. This scarcity extends more to low- and middle-income countries, with the scanner density falling below 1 per million people in LMICs as compared to High-income Countries where scanner density exceeds 30 per million people2.The recent resurgence of low-field MRI (LF-MRI) scanners with field strengths below 1 Tesla (<1T) offers a promising solution to the inaccessible high-field MRI scanners (>1T). These LFMRI scanners present a more cost-effective, compact, and less shield-dependent alternative, effectively addressing the limitations of high-field scanners. However, LF-MRI scanners significantly suffer from reduced signal-to-noise ratio (SNR), hence producing poor-quality images compared to their higher-field scanner counterparts. To overcome this limitation, various noise reduction techniques have been proposed3,4,5,6, encompassing both software and hardware solutions. Deep learning approaches, including the Cycle-GAN7 and Multi-channel Denoising Convolution Neural Network (MCDnCNN)5, have shown promising results. However, these approaches use randomly simulated data and were evaluated primarily on high-field MRI. Alternatively, native noise denoising network (NNDnet) demonstrated consistent performance for 1.5T & 0.36T data8.
In this work, we extend the concept of native noise denoising to very low-field MRI (0.05T). We develop and evaluate two robust deep-learning algorithms to denoise in-vivo low-field brain MRI images.
Methods
This study utilized three forms of data: Pro-MRI phantom data and the in vivo data, both obtained at 0.05T scanner along with the open-source IXI brain development dataset containing 3T(T2w) and 1.5T(T2w) images. We assessed the SNR of the 0.05Tphantom data and then acquired native noise data from it to simulate the characteristic noise profile of the LFMRI system. The extracted noise from the 0.05T Pro-MRI phantom was added to the 3T IXI dataset until the SNR matched that of the phantom data, resulting in the 3T IXI noisy data as shown in Fig. 1. We split the 3T IXI noisy data into 64x64 patches for efficient model training, allowing the model to focus on only noise rather than learning the specific spatial features during training. Furthermore, the dataset was divided into 90% training set and 10% validation set to monitor the model's performance and generalization.Training utilized UNet and ResNet architectures, with the Adam optimizer monitoring mean square error loss. IXI dataset contributed 1952 (256x256) image slices, yielding 10528 (64x64) patches for model training. The phantom dataset provided 750 (155x155) slices, and the in-vivo human brain T2w dataset included 3 (80x80) slices. To quantitatively assess our models' effectiveness in enhancing the image quality, we employed standard performance metrics, including Peak Signal-to-Noise Ratio(PSNR) and Structural Similarity Index (SSIM), to measure the improvements in image quality achieved by our denoising models. We generated gradient-weighted activation maps to visually evaluate the denoising mechanism implemented in our models, providing insights into the working of the models.
Finally, we conducted three experiments to assess our model: the in-distribution tests using simulated IXI noisy data as input to the model, the out-of-distribution tests using 0.05 phantom data, and an evaluation of the model using the in-vivo data at 0.05T. We obtained the SNR for all inputs and compared it to that of the input images.
Results
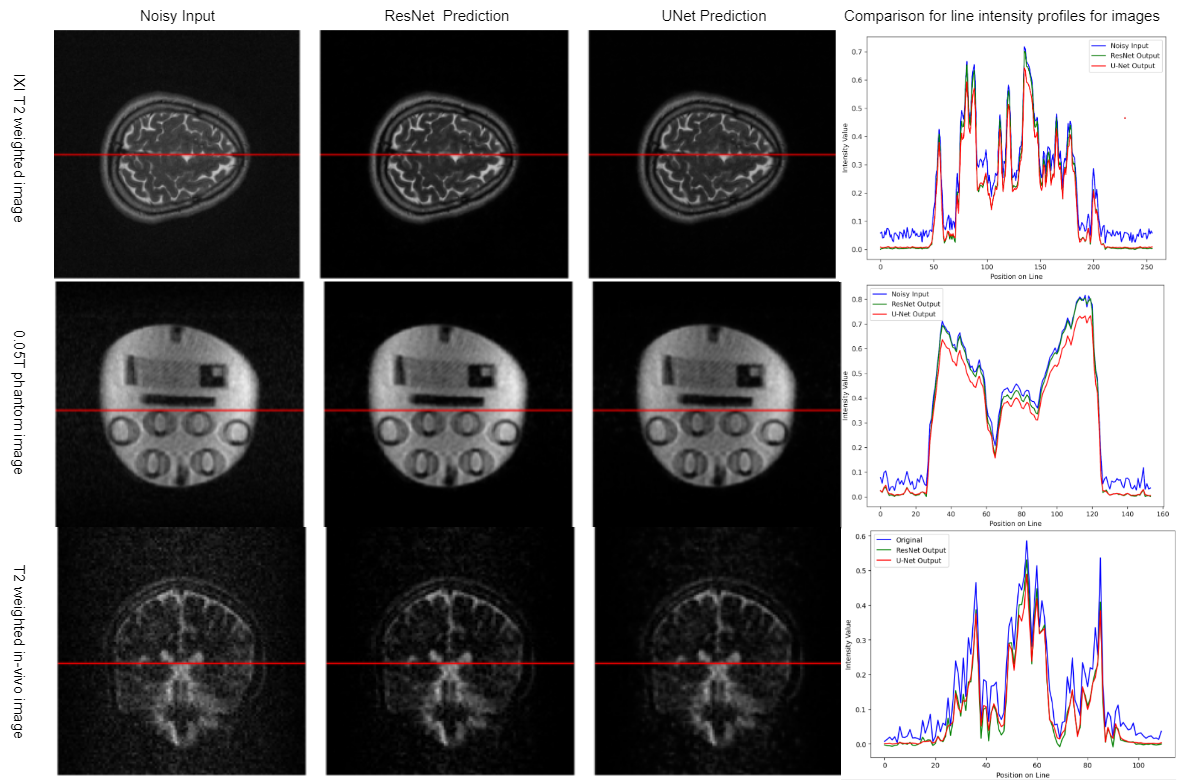
Qaulitatively, the U-Net and ResNet models learnt how to remove noise while preserving the brain anatomy as seen in Fig. 2. The models maintained performance when evaluated on low-field phantom data as shown in Fig. 3. Furthermore, this performance was maintained even on the in vivo data as shown in Fig. 4. It can be observed in Fig. 5 that the models maintain the high-frequency information in the images across all the three datasets.Quantitatively, the UNet outperformed ResNet with SSIM values of 0.9986 (training) and 0.9980 (validation) compared to ResNet's 0.9892 (training) and 0.9979 (validation) SSIM values. The ResNet had a 0.0130MSE and 53.1809 PSNR during validation, while the UNet achieved 0.0099 MSE and 56.1810 PSNR. In denoising 0.05T phantom images, both models significantly improved SNR. For ResNet, SNR increased from 21.9838 dB to 49.7794 dB; for UNet, it increased from 21.9838 dB to 51.1890 dB.
Conclusion
Our models consistently enhanced SNR across diverse datasets, preserving anatomical details. A visual assessment of the activation maps confirmed their efficacy in noise reduction.Acknowledgements
We gratefully acknowledge the grant support from SMART Africa Network through the Chan Zuckerberg Initiative (CZI), which enabled us to carry out this research.References
Geethanath and Vaughan, JMRI, 2019. Accessible magnetic resonance imaging. Epub 2019 Jan 14, https://doi.org/10.1002/jmri.26638
Anazodo, U. C. (2022, November 2022 Oct 19th). Denoising very low field magnetic resonance images using native noise. NMR in Biomedicine, 36(3), 16. https://doi.org/10.1002/nbm.4846
Koonjoo, N., Zhu, B., Bagnall, G.C., Bhutto, D. and Rosen, M.S., 2021. Boosting the signal-to-noise of low-field MRI with deep learning image reconstruction. Scientific reports, 11(1), p.8248.
Geethanath, S., Poojar, P., Ravi, K.S. and Ogbole, G., 2021, May. MRI denoising using native noise. In Proc Intl Soc Mag Reson Med (p. 2405).
Dongsheng, J., Weiqiang D., Luc V., Xiayu X., Yue S., Tao T., 2018. Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network, https://doi: 10.1007/s11604-018-0758-8
Qian, E., Poojar, P., Vaughan Jr, J.T., Jin, Z. and Geethanath, S., 2022. Tailored magnetic resonance fingerprinting for simultaneous non‐synthetic and quantitative imaging: A repeatability study. Medical physics, 49(3), pp.1673-1685.
- Fernando Vega, Abdoljalil Addeh, and M. Ethan MacDonald, Denoising Simulated Low-Field MRI (70mT) using Denoising
Autoencoders (DAE) and Cycle-Consistent Generative Adversarial
Networks (Cycle GAN)-2023 https://arxiv.org/pdf/2307.06338
Sairam Geethanath , Pavan Poojar , Keerthi Sravan Ravi , and Godwin Ogbole, MRI denoising using native noise,ISMRM, 2021.
Figures
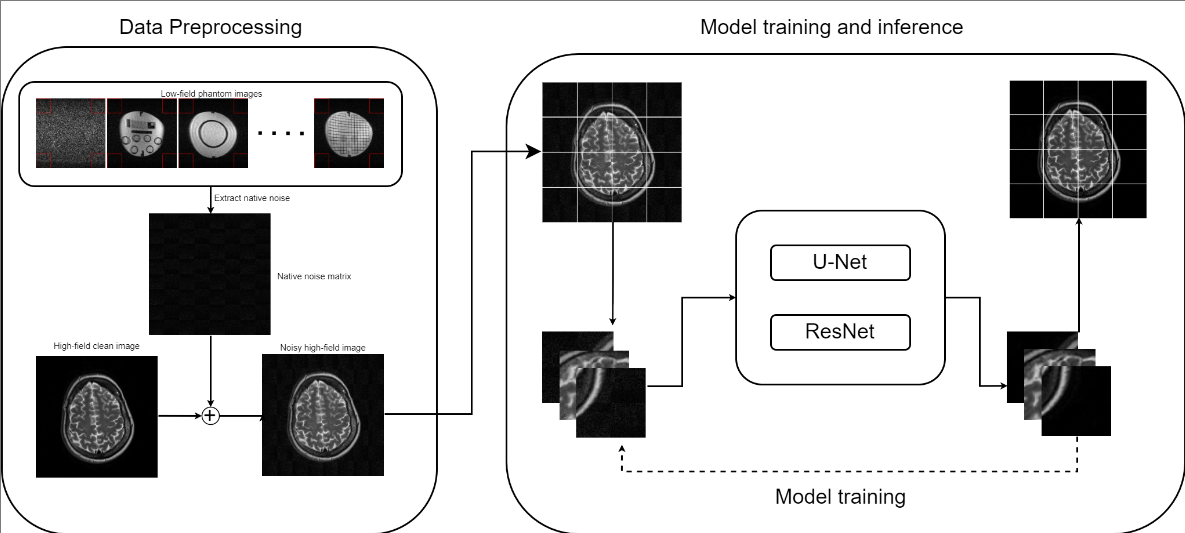
Fig. 1: Native noise modeling and Deep Learning Denoising Network: the data processing section involves extracting noise from the O.05T phantom images, combining them into one single large matrix, and adding this noise to the 3T IXI clean dataset until the SNR matches that of the phantom data. In the model training and inference section, both model architectures are trained using noisy IXI 64x64 image patches.
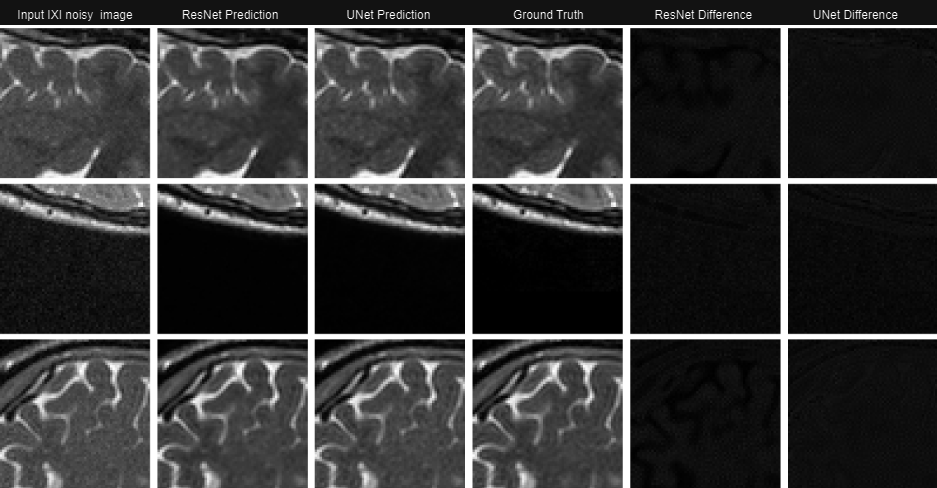
Fig.2 Denoising IXI noisy simulated image patches: T2-weighted noisy simulated image patches are denoised by the U-Net and ResNet models, and their corresponding outputs are shown. The 5th and 6th columns depict the difference between the predicted outputs and the inputs for both models. A reference IXI clean patch (ground truth) is provided in the 4th column for comparison.
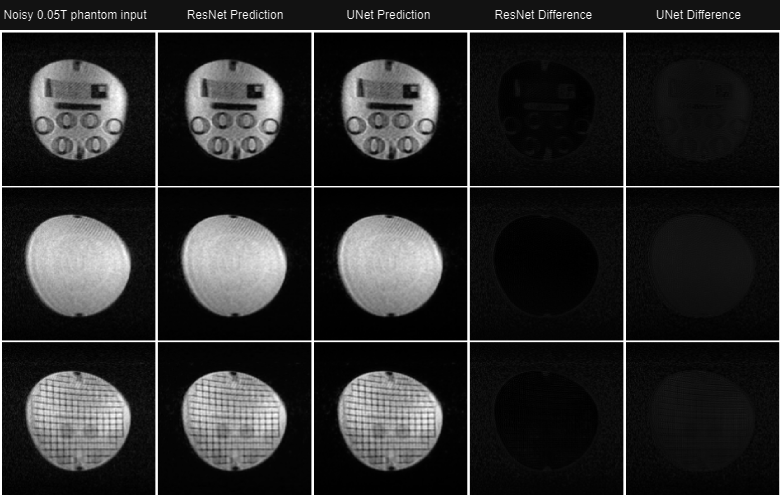
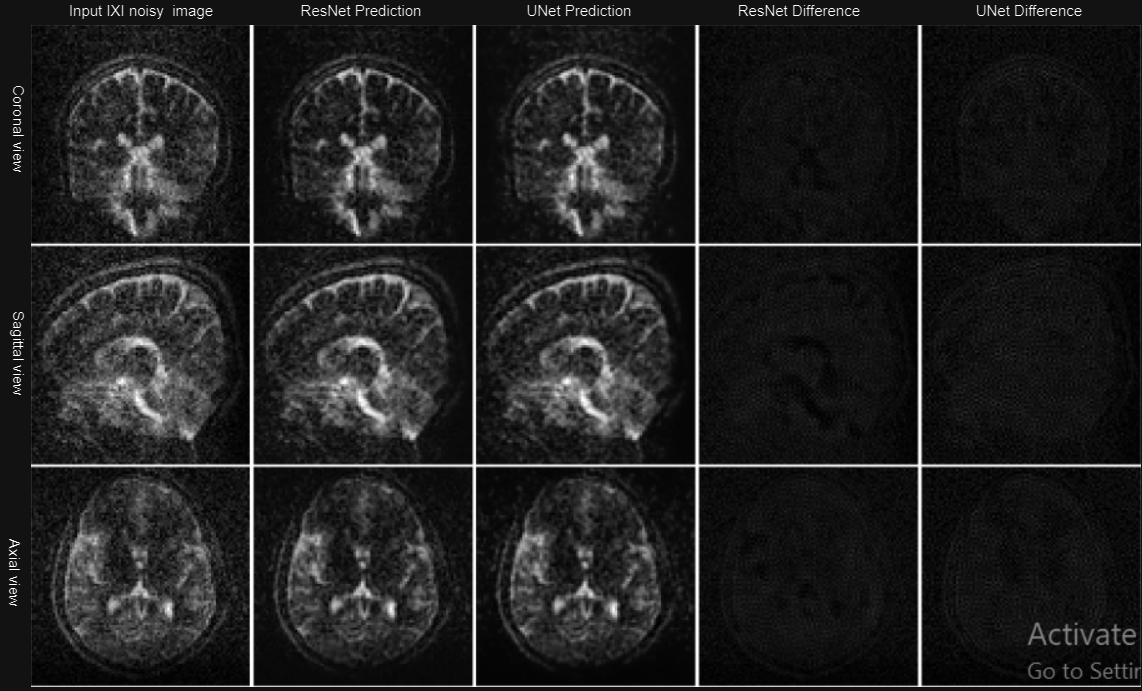
Fig.4. Denoising 0.05 T in-vivo T2-weighted images: The outputs for both ResNet and UNet in all three different image views are shown. The figure also shows the difference between the predicted outputs and the input noisy image for both models.