2798
Attention-based two-stage network for non-cartesian multi-coil ASL MRI reconstruction1Computer Science, State University of New York at Binghamton, Vestal, NY, United States, 2Zhejiang University, Zhejiang, China, 3Beth Israel Deaconess Medical Center and Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence
Motivation: High-resolution arterial spin labeling (ASL) imaging is time-consuming, limiting its clinical applications in studying small brain structures.
Goal(s): To reconstruct high-resolution ASL images from 8-time accelerated ASL image acquisition, an under-sampled non-Cartesian k-space sampling.
Approach: We proposed an attention-based deep learning (DL) model.
Results: The proposed DL model can successfully reconstruct 8-fold under-sampled, non-cartesian, multi-coil data from k-space.
Impact: Our proposed attention-based deep learning model can reconstruct under-sampled non-cartesian multi-coil data in k-space and thereby significantly decrease long MRI acquisition time required for high-resolution ASL MRI imaging, which may enable clinical applications in studying small brain structures.
Introduction
Arterial spin labeling (ASL) is a powerful non-invasive magnetic resonance imaging (MRI) technique used to quantitatively measure cerebral blood flow (CBF)1, 2. However, high-resolution ASL imaging is very time-consuming, limiting its clinical applications in studying small brain structures. Compressed sensing3 and parallel imaging4 can accelerate ASL image acquisition by several folds but with an upper limit for its acceleration factor and tremendously increased time for image reconstruction. Deep learning (DL) has been introduced5, 6 to allow for fast reconstruction with comparable or improved image quality compared to traditional iterative reconstructions. However, these DL reconstructions are mainly concentrated on Cartesian k-space trajectories6, 7, 8. In this work, we proposed a DL network that can reconstruct heavily under-sampled non-Cartesian ASL data, which is an ill-conditioned problem with traditional parallel imaging reconstruction. The proposed DL reconstruction uses the attention mechanism10 which is a huge roadblock for large language models such as ChatGPT and has an end-to-end design.Methods
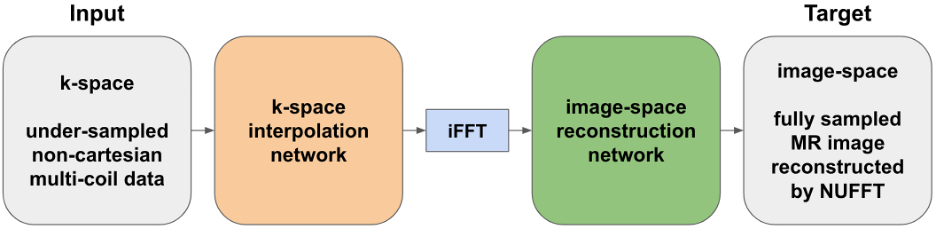
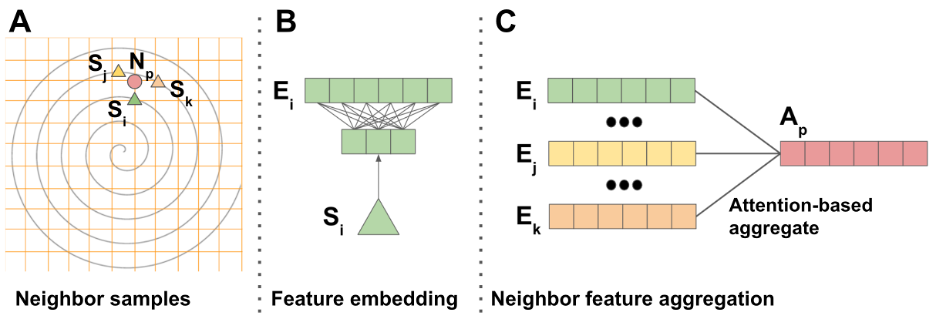
The 3D ASL images were acquired with a stack of spirals (32 slices) on a 3 Tesla GE MR750 scanner using 32-channel phased array coil from 60 healthy subjects for a different project9. Each slice contained 13 golden angle variable-density spiral trajectories with 1536 points per trajectory. Each single spiral trajectory had an 8-fold under-sampling of the outer k-space.We designed a DL model (Figure 1) which uses the attention mechanism10 and takes a single-spiral (non-Cartesian and 8-fold under-sampled) 32-channel k-space data as input. The image reconstructed from 13-spirals (fully-sampled) 32-channel k-space data using nonuniform fast Fourier transform (NUFFT) serves as ground-truth. The model contains a k-space interpolation network followed by the inverse FFT and image-space reconstruction network. The k-space interpolation network was designed to re-grid samples from an under-sampled non-cartesian grid (Fig. 2A, a gray spiral) to a cartesian grid (Fig. 2A orange grid) in k-space. For each point (circle in Fig. 2A) on the cartesian grid, we find a fixed number (M = 12) of neighbor samples (triangles in Fig. 2A) on the spiral trajectory to do the local interpolation. For each neighbor sample, its signal and coordinate features were embedded with the feature embedding layer (Fig. 2B) i.e., a fully connected (FC) layer. With this flexible feature embedding, any single spiral out of 13 spirals (not in the same spatial locations) can be the input. Embedded features from all the neighbors were aggregated using the attention mechanism (Fig. 2C) to get the interpolated k-space signal. After the 2D inverse FFT, we get coil-level reconstructed images, and those images are sent to a CNN-based decoder for coil combination and further image-domain learning.
Furthermore, for comparison purposes, we implemented a non-attention-based DL model with the same image-space reconstruction network but the k-space interpolation network as an FC layer from neighbor samples and reconstructed the single-spiral image using a parallel imaging reconstruction --- non-linear inverse reconstruction (NLINV). Five-fold cross-validation was used to test the performance of these DL models.
Results & Discussion
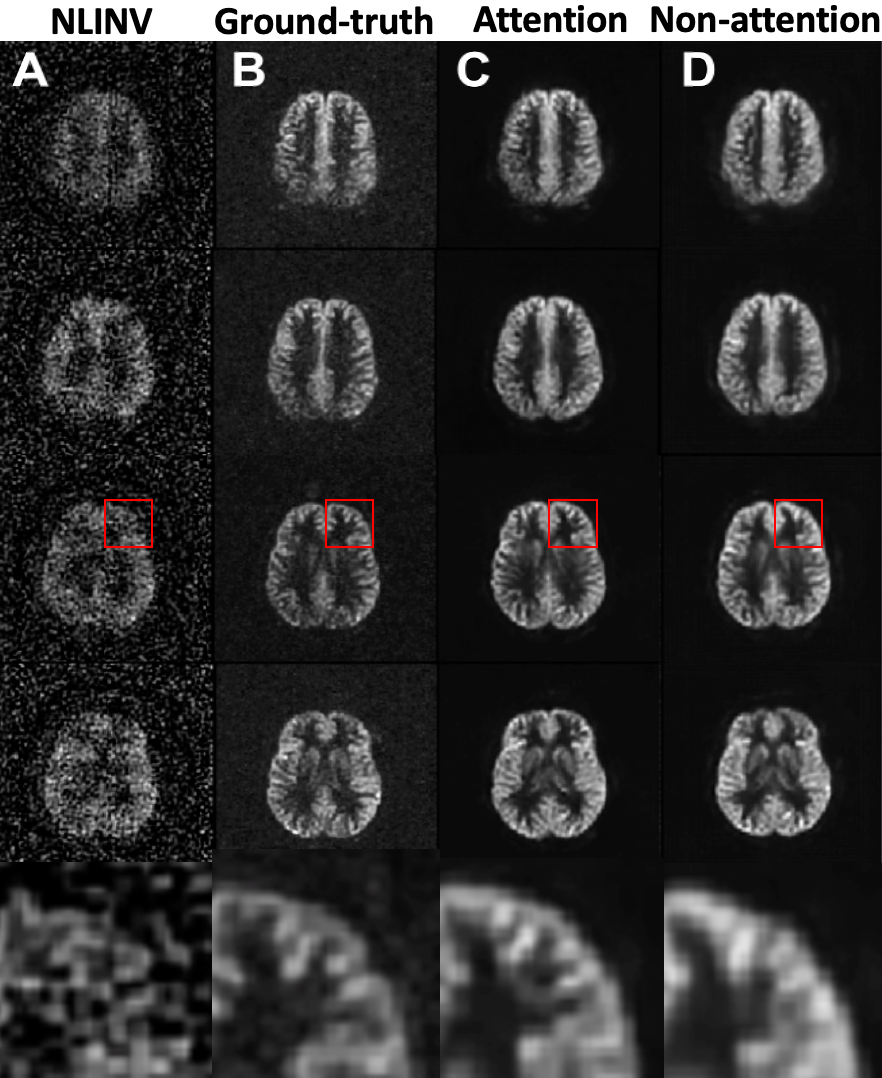
Figure 3 shows the reconstructed images from a single spiral trajectory using the attention-based and non-attention-based DL models. The images reconstructed from the same single-spiral trajectory using NLINV and those reconstructed from the fully-sampled dataset are shown for comparisons. Multiple image slices from the inferior to superior direction are shown as separate rows.The reconstructed images using NLINV take 30 minutes per subject and have very poor quality and SNR, as expected because the parallel imaging reconstruction from an 8-fold under-sampled k-space is an ill-posed problem. The images reconstructed by the proposed attention-based and non-attention-based DL models (Fig. 3C and Fig. 3D) take 5 seconds per subject and show similar gray-white matter contrasts to the ground-truth. Compared to the images from the non-attention-based DL model, those reconstructed from the attention-based DL model contain much more high-resolution details and similar contrast with the target, indicating the benefit of attention-based network in capturing details. Zoom-in images (the last row in Figure 3) are shown for better visualization of high-resolution details across different methods.
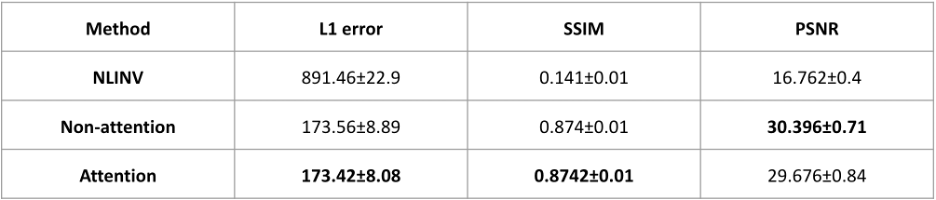
The PSNR, L1-error, and SSIM from 5-fold cross-validation were summarized in Table 1. Higher performance was observed for the proposed attention-based network, as shown by L1-error and SSIM. The quantitative performance is consistent with visual comparisons. However, PSNR shows the opposite. We postulate that PSNR may be a less accurate measure in characterizing the degree of brain high-resolution details.
Conclusion
We propose a two-stage attention-based DL model, which can reconstruct the 8-fold under-sampled non-cartesian multi-coil 2D data in k-space with great high-resolution details successfully. Further study will focus on the 3D MRI reconstruction and generalization to abnormal brains.Acknowledgements
No acknowledgement found.References
1. Detre, J.A., et al., Perfusion imaging. Magn Reson Med, 1992. 23(1): p. 37-45.
2. Williams, D.S., et al., Magnetic resonance imaging of perfusion using spin inversion of arterial water. Proc Natl Acad Sci U S A, 1992. 89(1): p. 212-6.
3. Lustig, M., D. Donoho, and J.M. Pauly, Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn Reson Med, 2007. 58(6): p. 1182-95.
4. Griswold, M.A., et al., Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn Reson Med, 2002. 47(6): p. 1202-10.
5. Schlemper, J., et al., A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imaging, 2018. 37(2): p. 491-503.
6. Zhu, B., et al., Image reconstruction by domain-transform manifold learning. Nature, 2018. 555(7697): p. 487-492.
7. Qin, C., et al., Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imaging, 2019. 38(1): p. 280-290.
8. Aggarwal, H.K., M.P. Mani, and M. Jacob, MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging, 2019. 38(2): p. 394-405.
9. Munsch, F., et al., Rotated spiral RARE for high spatial and temporal resolution volumetric arterial spin labeling acquisition. Neuroimage, 2020. 223: p. 117371.
10. D. Bahdanau, et al., Neural machine translation by jointly learning to align and translate, ICLR, 2014.
Figures