2795
Deep Learning with Spatio-Channel Regularization for Accelerated Cardiac Cine1Department of Medicine (Cardiovascular Division), Beth Israel Deaconess Medical Center and Harvard Medical School, Boston, MA, United States, 2Radiology, Beth Israel Deaconess Medical Center and Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Cardiovascular
Motivation: Evaluation of cardiac function with cine imaging remains long and requires repeated breath-holds that are sometimes corrupted with artifacts if patients have non-sinus rhythm or difficulty in breath-holding.
Goal(s): To develop a deep learning method with spatio-channel regularization with multi-channel k-space reconstruction for accelerated cine imaging.
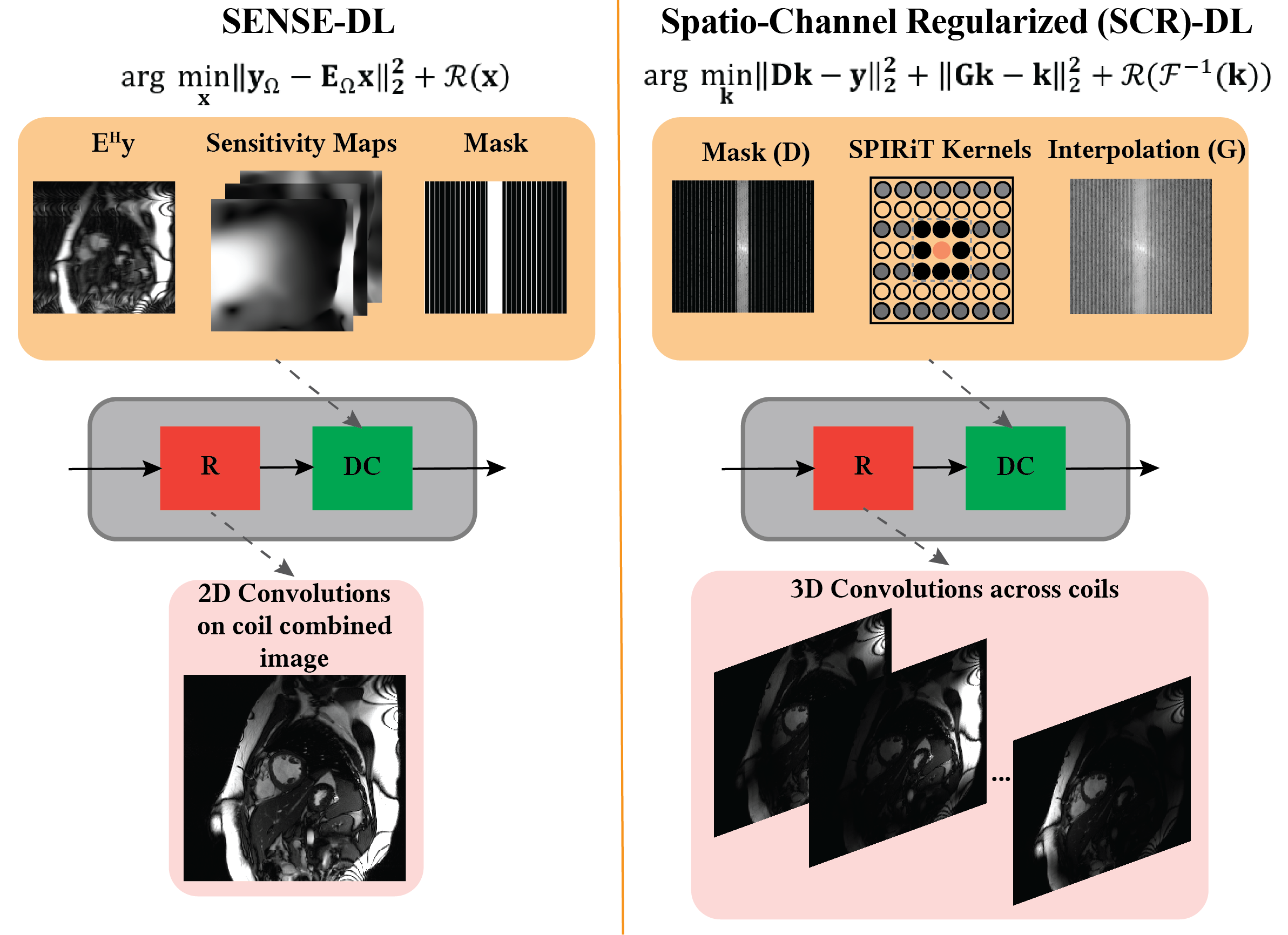
Approach: Coil-self consistency based deep learning (DL) was implemented with 3D regularization across spatial and channel dimensions in contrast to single coil-combined image used in sensitivity encoding (SENSE).
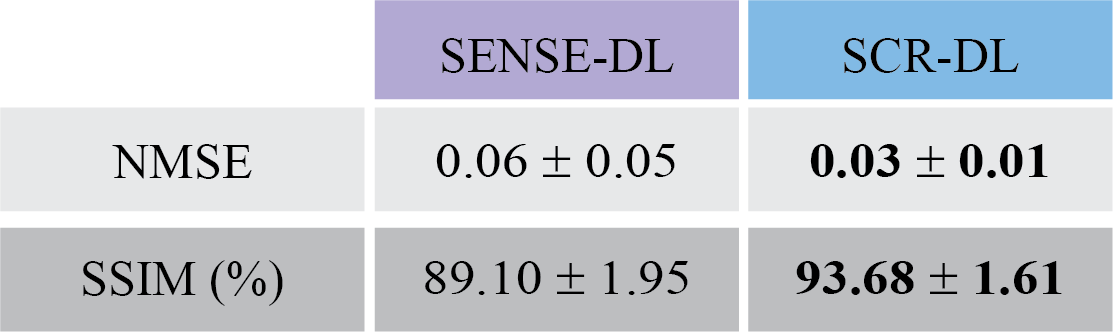
Results: Our approach at 5-fold acceleration showed quantitative improvements over SENSE-based DL on retrospectively accelerated data and showed good agreement with left ventricular (LV) measurements on prospectively accelerated data.
Impact: The spatio-channel regularized DL reconstruction shortens the scan time by a factor of 5, leading to fewer breath-holds and 2–3-minute scans. This can greatly benefit patients struggling with breath-holding and accelerate the overall scan time.
INTRODUCTION
CMR cine is the primary technique for assessing cardiac volume and function. However, it often necessitates multiple breath-holds to cover the whole heart, resulting in extended acquisition times. Additionally, scans from patients with irregular heart rhythms or difficulties in breath-holding may suffer from image artifacts. Deep learning (DL) has been used to accelerate cine images beyond what can be accomplished with current acceleration techniques1. While DL achieves higher acceleration rates, the conventional sensitivity-encoding (SENSE)-based approach only utilizes a single coil-combined image, thereby limiting the full potential of the acquired multi-channel k-space data. We sought to develop an iterative self-consistent parallel imaging reconstruction (SPIRiT)-based approach that provides insights into each channel image within regularization by applying 3D convolutions across spatial and channel dimensions.METHODS
Spatio-channel Regularized Deep Learning (SCR-DL):Regularized MRI reconstruction is formulated as:
$$\arg \min _{\mathbf{\kappa}} \left\|\mathbf{D}\mathbf{\kappa}-\mathbf{y}\right\|_2^2 +\left\|\mathbf{G}\mathbf{\kappa}-\mathbf{\kappa}\right\|_2^2 + \lambda R(F^{-1}(\kappa)), \quad\quad (1)$$
where D is the subsampling operator that relates reconstructed k-space ($$$\kappa$$$) to the acquired data, G is the SPIRiT self-consistency operator that convolves entire k-space with calibration kernels across all channels2, $$$\lambda$$$ is a weight term, $$$R(\cdot)$$$ is a regularizer and $$$F^{-1}(\cdot)$$$ is the inverse Fourier transform. SENSE-based DL (SENSE-DL) algorithms lead to a coil combined image relying on data-consistency with the acquired points. This is followed by a regularization process which is implicitly solved using a convolutional neural network operating on the coil-combined image. In contrast to SENSE-DL opponents, the proposed approach leverages the 3D convolutions within its regularizer, facilitating a comprehensive exploration of all channels, rather than relying on 2D convolutions applied to coil-combined images. Coil-wise self-consistency is followed by a regularizer that operates on individual channel images which are inverse Fourier transform of the interpolated k-spaces. A schematic of the proposed approach is depicted in Fig. 1.
Imaging Experiments:
Breath-hold ECG-gated segmented cine were collected at 3T (MAGNETOM Vida Siemens Healthineers, Erlangen, Germany) in the left ventricular (LV) short axis with the following imaging parameters: 1.8-fold GRAPPA acceleration, resolution=1.7×1.7mm2, matrix size=156-208×208, and slice-thickness=8mm. These data were further retrospectively undersampled to R=5 by sampling every other 8th line while keeping 24 center lines in k-space. Prospectively accelerated data were acquired on 5 subjects with the same imaging parameters. For comparison, baseline images were acquired at 1.8-fold GRAPPA in the same session. The current imaging pipeline acquires one slice per breath-hold, resulting in 10-12 breath-holds. This highly accelerated acquisition translates to only 2-3 breath-holds, depending on the subject's heart rate.
Implementation Details:
A supervised training was performed between fully-sampled segmented cine and retrospectively accelerated cine using 32 subjects, all slices, and every other 5th time-frame. Variable splitting with quadratic penalty was used to unroll the algorithm in Eq. 1 that alternates between data consistency and regularizer 10 times. A 3D spatio-channel regularizer was used based on a 3D ResNet structure across 8-channels that were coil-compressed from 32 channels3. Adam optimizer, LR=1⋅10-4, mixed normalized $$$\ell_1-\ell_2$$$ loss in both image and frequency domain were used. SPIRiT kernels2,4 were calibrated on the full range of ACS region using 9×9 rectangular kernels and Tikhonov regularization with a penalty of 10-3. SENSE-DL reconstruction was implemented with the same hyper-parameters, and sensitivity maps were generated, followed by the ESPIRiT implementation5.
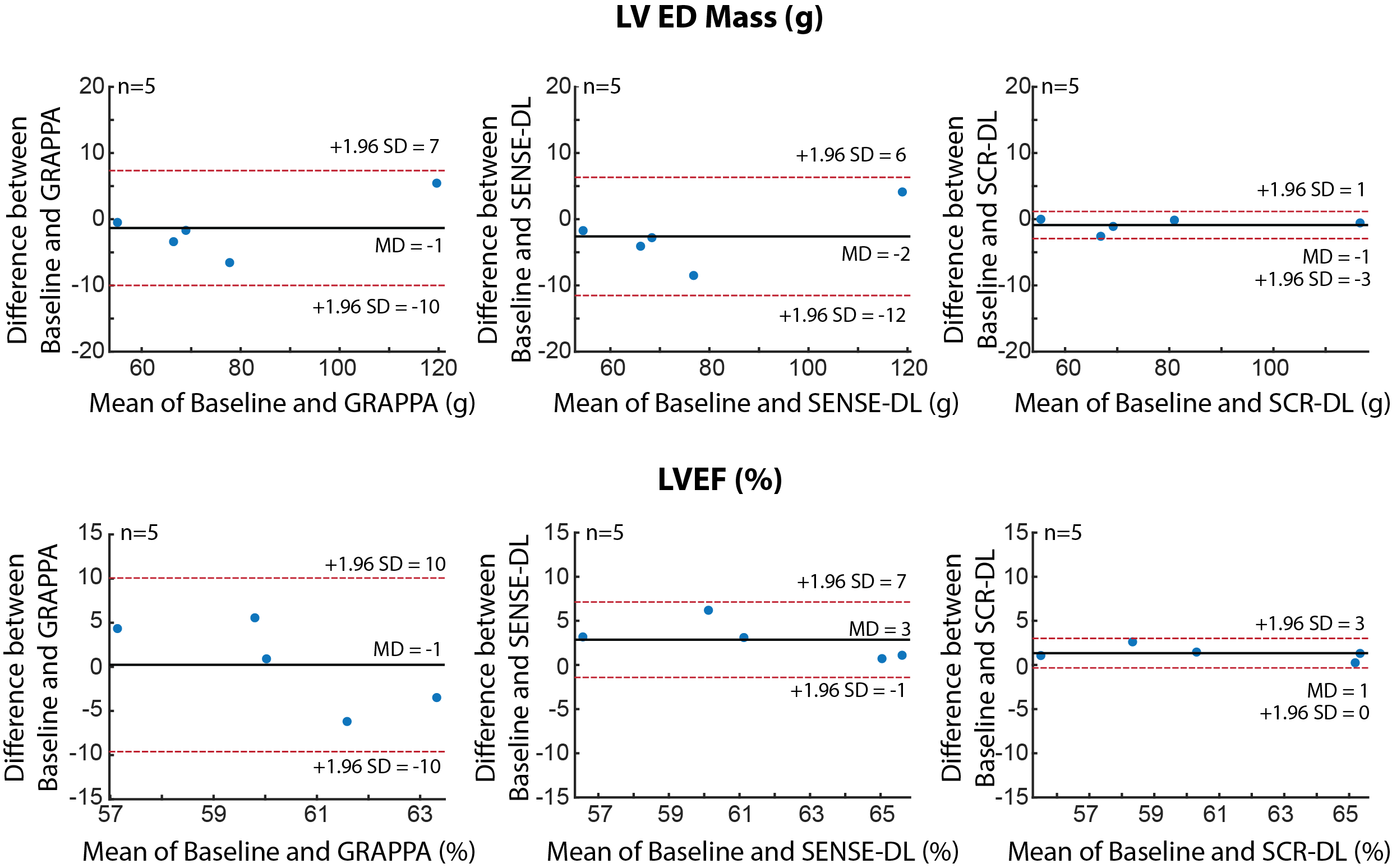
Testing was performed on 10 subjects retrospectively in whom k-space data were undersampled by 5-fold, using all slices and time-frames unseen by the network. Normalized mean square error (NMSE) and structural similarity index measure (SSIM) were calculated and assessed using a paired t-test (P<.05 considered significant). LV ejection fraction (LVEF) and LV mass were manually calculated and assessed with Bland-Altman compared to 1.8-fold accelerated images in prospectively accelerated acquisitions.
RESULTS
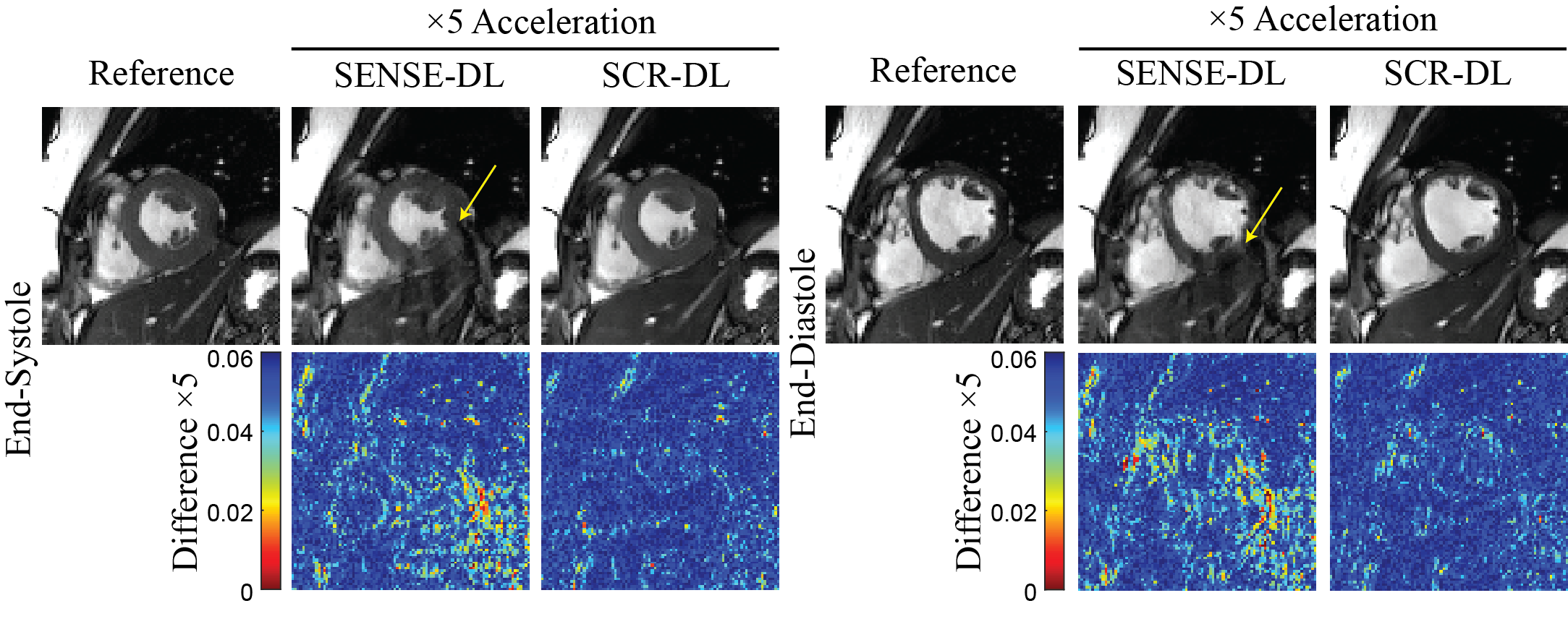
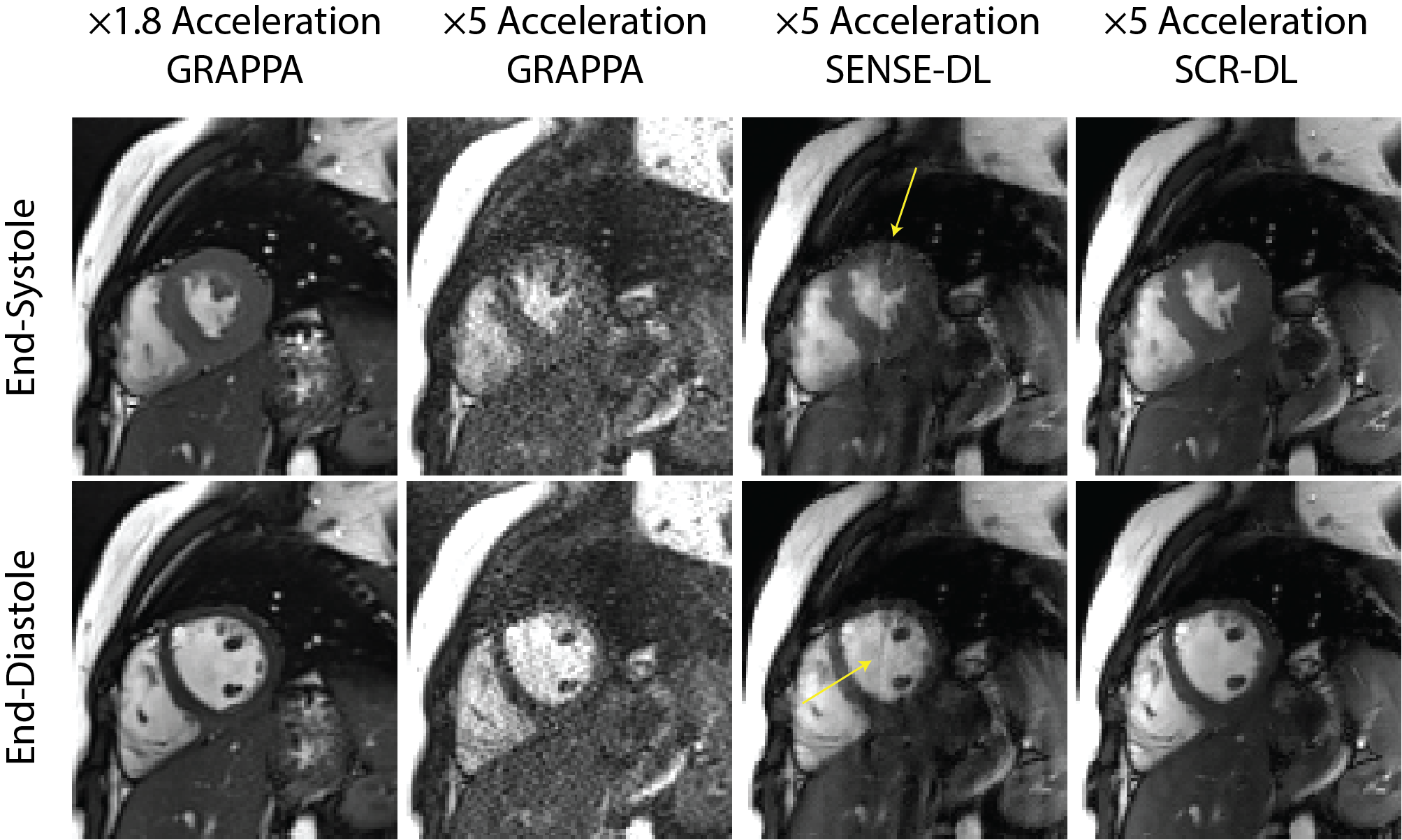
Fig. 2 shows representative cine from 5-fold retrospectively accelerated acquisition where SCR-DL improves upon SENSE-DL, particularly in myocardium regions (yellow arrows). Mean NMSE and SSIM measurements are given in Table 1, showing SCR-DL performance. Prospective subjects at 5-fold acceleration are depicted in Fig. 3, where SCR-DL shows improved image quality compared to GRAPPA and SENSE-DL. Bland-Altman analyses (Fig. 4) show good agreement between the SCR-DL at 5-fold acceleration and 1.8-fold accelerated images for LVEF and mass.CONCLUSION
The spatio-channel regularization applied to individual coils improved the image quality in accelerated cardiac cine and provided quantitative and qualitative improvements over existing methods.Acknowledgements
No acknowledgement found.References
1) Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. Ieee Transactions on Medical Imaging 2019;38(2):394-405.
2) Lustig M, Pauly JM. SPIRiT: Iterative Self-consistent Parallel Imaging Reconstruction From Arbitrary k-Space. Magnetic Resonance in Medicine 2010;64(2):457-71.
3) Zhang T, Pauly JM, Vasanawala SS, Lustig M. Coil compression for accelerated imaging with Cartesian sampling. Magnetic Resonance in Medicine 2013;69(2):571-82.
4) Lobos RA, Haldar JP. On the shape of convolution kernels in MRI reconstruction: Rectangles versus ellipsoids. Magnetic Resonance in Medicine 2022;87(6):2989-96.
5) Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, et al. ESPIRiT-An Eigenvalue Approach to Autocalibrating Parallel MRI: Where SENSE Meets GRAPPA. Magnetic Resonance in Medicine 2014;71(3):990-1001.
Figures