2793
Mixed-sequence training for deep subspace learning image reconstruction of T1-T2-T2*-FF CMR Multitasking data1Biomedical Imaging Research Institute, Cedars-Sinai Medical Center, Los Angeles, CA, United States, 2Department of Radiological Sciences, David Geffen School of Medicine at UCLA, Los Angeles, CA, United States, 3Department of Bioengineering, University of California, Los Angeles, Los Angeles, CA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Cardiovascular
Motivation: Multi-parametric mapping using T1-T2-T2*-fat fraction (FF) MR Multitasking is promising but is hindered by lengthy reconstruction times.
Goal(s): To improve T1-T2-T2*-FF Multitasking reconstruction time with deep subspace learning, overcoming challenges in training data scarcity and network scalability to high-dimensional spatial factors.
Approach: A component-by-component (CBC) network structure was evaluated for three training strategies: 1) large T1 data, 2) limited T1-T2-T2*-FF data, and 3) multi-domain, mixed-sequence learning on both T1 and T1-T2-T2*-FF data.
Results: Mixed-domain learning demonstrated superior image reconstruction quality, achieving the lowest normalized root mean squared error, displaying fewer structural artifacts, and narrowing Bland-Altman limits of agreement.
Impact: Component-by-component deep-subspace-learning image reconstruction with mixed-sequence training can dramatically speed up T1-T2-T2*-fat fraction (FF) MR Multitasking image reconstruction by approximately 600 times, potentially overcoming a major barrier to clinical translation.
Introduction
Multi-parametric mapping provides detailed, quantitative analysis of tissue properties for objective diagnosis and treatment monitoring of disease. For example, the recently developed T1-T2-T2*-fat fraction (FF) MR Multitasking sequence1,2 can map several parameters simultaneously in the heart. However, long reconstruction times are still a challenge for clinical adoption. Previous work for the original T1 MR Multitasking pulse sequence has used supervised deep subspace learning (SDSL)3-5 to reduce reconstruction times to clinically viable durations. Unfortunately, SDSL is less effective for the newer T1-T2-T2*-FF sequence due to scant training data and poor scalability of previous network structures to its relatively high-dimensional “spatial factor”. The recently proposed ‘Component-by-Component’ (CBC) network6 offers a potential solution. In principle, it can be trained on the copious existing data from other sequences (e.g., T1) to overcome training data scarcity, and can scale to arbitrary spatial factor dimensions. In this study, we developed CBC image reconstruction for T1-T2-T2*-FF Multitasking and evaluated a mixed-sequence learning strategy in healthy volunteers.Methods
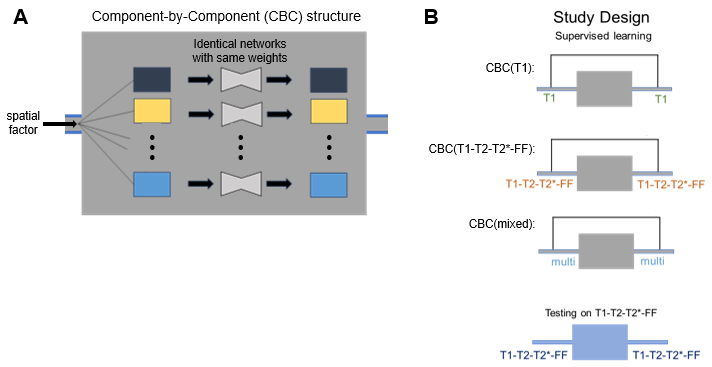
Network Structure:The ‘component-by-component’ (CBC) network applied the same U-Net7 structure to every component of the MR Multitasking spatial factor (i.e., to each eigenimage). The detailed network design is shown in Figure 1.
Data Acquisition:
1. T1 mapping CMR Multitasking data was collected from three 3T Siemens scanners (Verio, Vida, and mMR): 106 cases for training, 12 cases for validation. The imaging parameters included 1.7 mm in-plane spatial resolution, 8 mm slice thickness, 20 cardiac phases, and 6 respiratory phases. The spatial factor had a matrix size of 320×320×32.
2. T1-T2-T2*-FF mapping data was collected on one 3T scanner (Vida): 6 cases for training, 2 cases for validation, and 8 cases for testing. Spatial and temporal resolutions matched the T1 data, but the sequence had additional gradient echoes and T2IR preparations [0,30,40,50,60ms]. The size of the spatial factor is 320×320×528.
Training strategy comparison:
We compared three training strategies:
a) CBC(T1): Cross-domain learning on the larger set of unmatched T1 training data,
b) CBC(T1-T2-T2*-FF): In-domain learning on the smaller set of T1-T2-T2*-FF training data,
c) CBC(mixed): Mixed-domain learning on the full set of T1 and T1-T2-T2*-FF training data.
All network outputs went through a preconditioned gradient descent data consistency (DC) layer4.
Evaluation metrics:
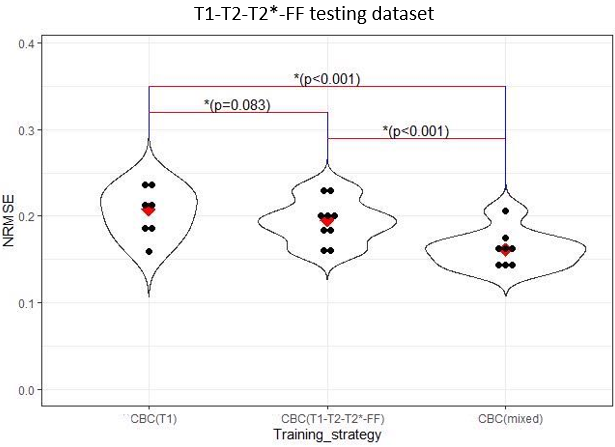
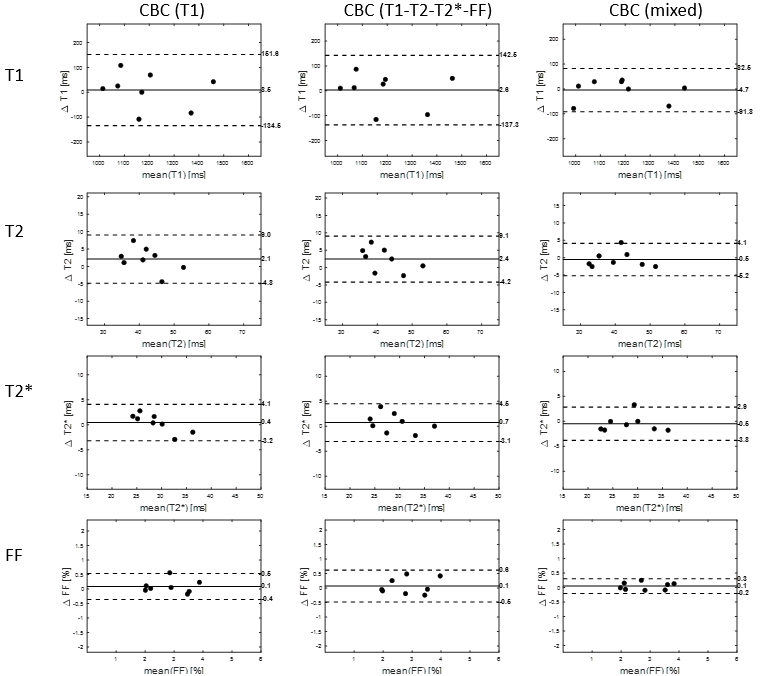
Normalized root mean squared error (NRMSE) for the spatial factor was calculated, which is equivalent to the NRMSE for the entire dynamic image1. The Wilcoxon signed-rank test was used for statistical comparison, regarding p<0.05 as statistically significant. Bland-Altman plots were used to evaluate the accuracy and precision of end-diastolic septal T1, T2, T2*, and FF values versus reference values from iterative reconstruction with regularization of wavelet sparsity.
Results
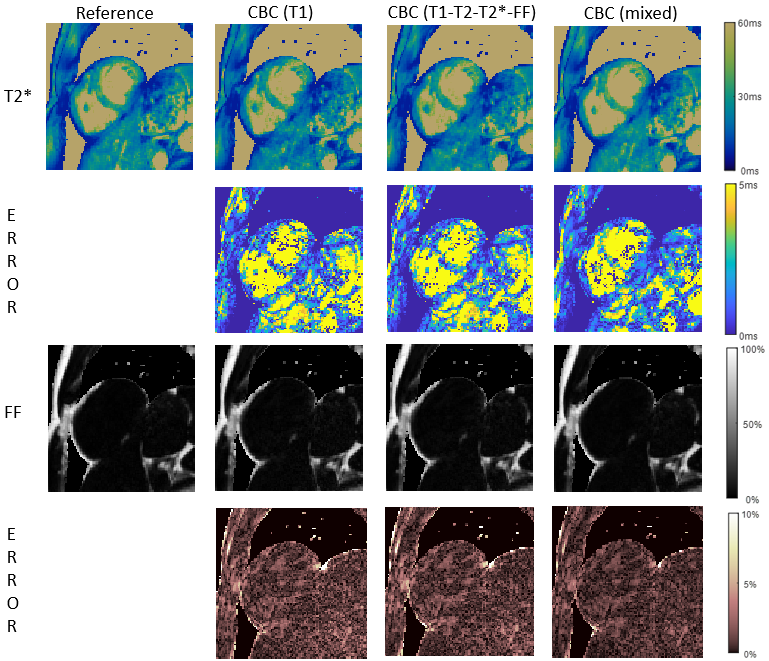
Average reconstruction times were 3.5 hrs for iterative reconstruction and 20 sec for CBC+DC inference. As shown in Figure 2, in-domain learning with CBC(T1-T2-T2*-FF) was better than cross-domain learning CBC(T1), but the mixed-domain CBC(mixed) produced the lowest NRMSE values of all. Figure 3 and 4 shows example maps from all approaches; fewer structural features are seen in the error maps from mixed-domain training, especially in the T2 and FF maps. In Bland-Altman analyses (Figure 5), CBC(mixed) produced the tightest limits of agreement for all 4 quantitative maps.Discussions
The CBC network structure for SDSL appears to be generalizable enough to support a mixed-domain learning strategy. The combination of large but out-of-domain T1 data with limited but domain-specific T1-T2-T2*-FF data achieved the lowest error in reconstructed images and the highest agreement in parameter maps. Previous work6 suggested that the “spatial-only” structure of the CBC network promotes generalizable contrast-invariant feature learning, for which this study provides further evidence. The study's limitations include a dataset confined to healthy volunteers and testing on a single 3T scanner model, so future work should investigate whether this generalizability extends to pathology, vendors, and field-strength. Network improvements such as unrolled end-to-end training may further improve reconstruction performance.Conclusions
Mixed-domain learning leveraging multiple pulse sequences is feasible with CBC deep subspace learning, reducing image error and improving quantitative T1-T2-T2*-FF precision relative to other training strategies and reducing reconstruction time relative to iterative reconstruction.Acknowledgements
This work was partially supported by NIH R01 EB028146 and NIH R01 HL156818.References
[1] Christodoulou AG, Shaw JL, Nguyen C, et al. Magnetic Resonance Multitasking for Motion-Resolved Quantitative Cardiovascular Imaging. Nature Biomedical Engineering. 2018;2(4):215-226.
[2] Cao T, Wang N, Kwan AC, et al. Free-breathing, non-ECG, simultaneous myocardial T(1) , T(2) , T(2) *, and fat-fraction mapping with motion-resolved cardiovascular MR multitasking. Magn Reson Med 2022;88(4):1748-1763.
[3] Chen Y, Shaw JL, Xie Y, et al. Deep learning within a priori temporal feature spaces for large-scale dynamic MR image reconstruction: Application to 5-D cardiac MR Multitasking. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; 2019: Springer; pp. 495-504.
[4] Chen Z, Chen Y, Xie Y, Li D, Christodoulou AG. Data-Consistent non-Cartesian deep subspace learning for efficient dynamic MR image reconstruction. Proc IEEE Int Symp Biomed Imaging 2022;2022.
[5] Sandino CM, Lai P, Vasanawala SS, Cheng JY. Accelerating cardiac cine MRI using a deep learning-based ESPIRiT reconstruction. Magn Reson Med 2021;85(1):152-167.
[6] Hu Z, Chen Z, Lee H-L, Xie Y, Li D, Christodoulou AG. Universal sequence-invariant deep learning image reconstruction for cardiovascular MR Multitasking. Proc Int Soc Magn Reson Med, 2023
[7] O. Ronneberger, P. Fischer, and T. Brox, "U-net: Convolutional networks for biomedical image segmentation," Med Image Comput Comput Assist Interv, pp. 234-241, 2015.
Figures