2787
Novel deep learning approach combining image reconstruction and diagnostic segmentation1Computational Imaging Lab, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany, 2IDEA Lab, Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen, Germany
Synopsis
Keywords: Image Reconstruction, Image Reconstruction
Motivation: Deep-learning-based image reconstruction methods for accelerated magnetic resonance imaging are optimized for global image quality metrics, but lack focus on diagnostically relevant features during training and reconstruction.
Goal(s): A novel approach combining reconstruction and segmentation during training is investigated, incorporating feedback on clinically relevant features for reconstruction.
Approach: Pretrained reconstruction (E2E-VN) and segmentation models (nnUNet) are connected. The reconstruction model is trained with a weighted combination of reconstruction and segmentation loss. Training and evaluation are performed on fastMRI+ data.
Results: The proposed method resulted in improved image quality of reconstructed images at 8x acceleration compared to baseline E2E-VN, along-with improved downstream segmentation.
Impact: Training deep-learning-based image reconstruction methods for accelerated MRI with additional feedback on diagnostic content improves image quality in the overall image and the region of interest, and subsequently the diagnostic utility of reconstructed images.
Introduction
Accelerated magnetic resonance imaging (MRI) methods are crucial in making MRI more accessible and feasible for wider clinical usage. Current deep-learning-based image reconstruction methods are trained and optimized for objective but global image quality metrics (IQMs). This ensures fidelity of reconstructions compared to a reference image. However, often these metrics differ from the subjective image quality assessment by radiologists, who focus on diagnostically relevant features [1, 2].This work investigates the impact of combining feedback from diagnostic feature representations using a deep-learning-based segmentation model with objective IQMs during training of the reconstruction model. The performance is assessed on the fastMRI+ dataset (https://fastmri.med.nyu.edu).
Methods
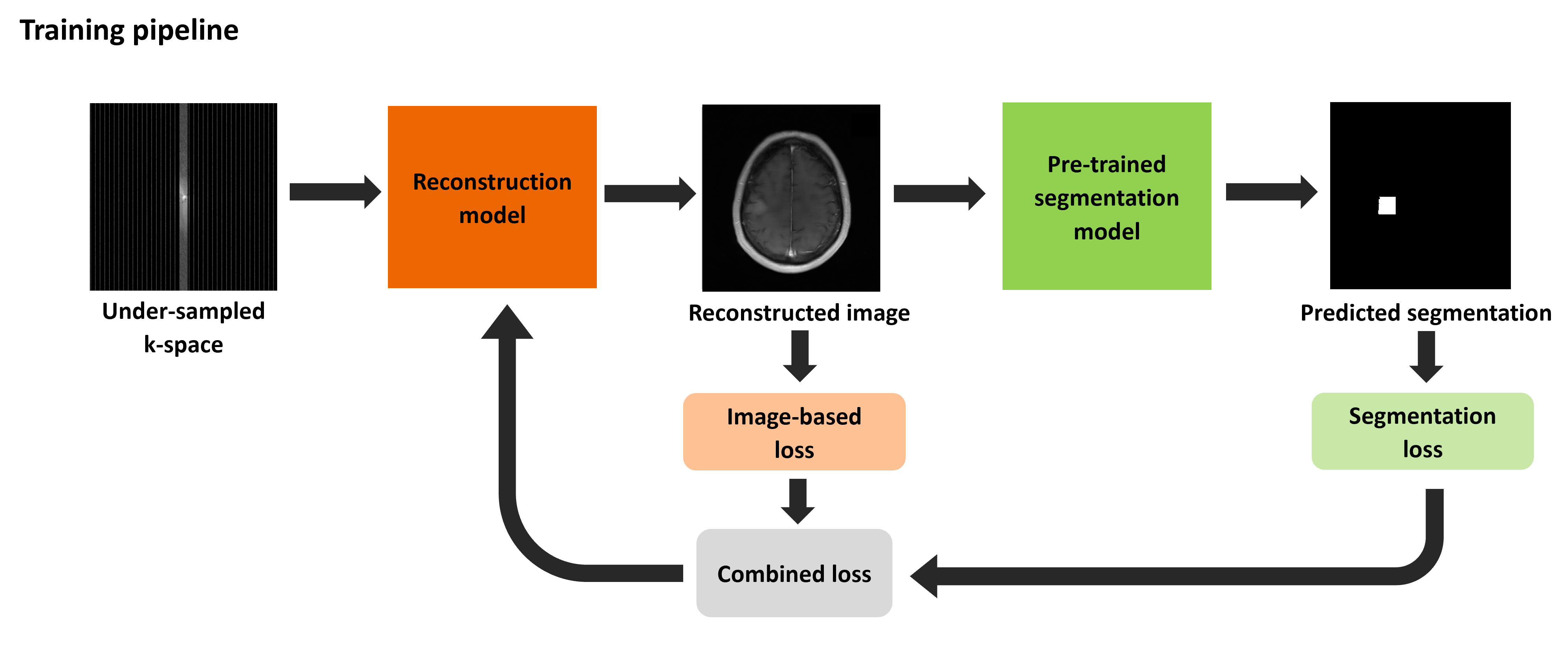
A reconstruction and a segmentation model are connected end-to-end. During training, a weighted combination of reconstruction and segmentation loss is back-propagated to the reconstruction model (Fig. 1).The brain fastMRI+ data consisting of fully sampled multi-coil raw k-space data and slice-wise bounding-box-annotations is selected as exemplar for this work. The bounding-box-annotations are used to generate weak segmentation masks [3] for the ground truth image. The dataset is limited to studies with pathology-label “Mass” resulting in 46 studies (40 training, 4 validation and 2 test samples). The studies’ k-space data are under-sampled, simulating an acceleration rate of 8 by sampling every 8th k-space line, and retaining 4% of the center of k-space [4].
The variational network (E2E-VN) [5], with 8 cascades and approximately 20M trainable parameters, is used as the image reconstruction model. A baseline model is trained for 50 epochs with SSIM loss ($$$L_{SSIM}$$$), and a learning rate of 0.001, which decays after the 40th epoch at a rate of 0.1.
The nnUNet segmentation model [6] is trained to provide a latent representation of diagnostically relevant features. The nnUNet pipeline is used for training the segmentation model on fully sampled ground truth images. A weighted combination of Dice and cross-entropy loss ($$$L_{s}$$$), is optimized for training [6].
Finally, the pre-trained reconstruction and segmentation models are connected (Fig. 1) and trained for 10 epochs. Weights of the segmentation model are frozen during training. Output from the reconstruction model is provided as input to the segmentation model after z-score normalization. A weighted combined loss ($$$L_{c}$$$), combining the reconstruction ($$$L_{SSIM}$$$) and segmentation loss ($$$L_{s}$$$) with weights $$$w_r$$$ and $$$w_s$$$ respectively, is back-propagated to the reconstruction model during training. $$$L_{SSIM}$$$ is computed on the reconstructed image $$$\hat{f}$$$ and the fully sampled ground truth image $$$f$$$. $$$L_{s}$$$ is computed on predicted segmentation $$$\hat{y}$$$ and ground truth segmentation $$$y$$$. $$$L_{c}$$$ is computed as
$$L_{c}=w_{r} * L_{SSIM}(\hat{f}, f) + w_{s} * L_{s}(\hat{y}, y).$$
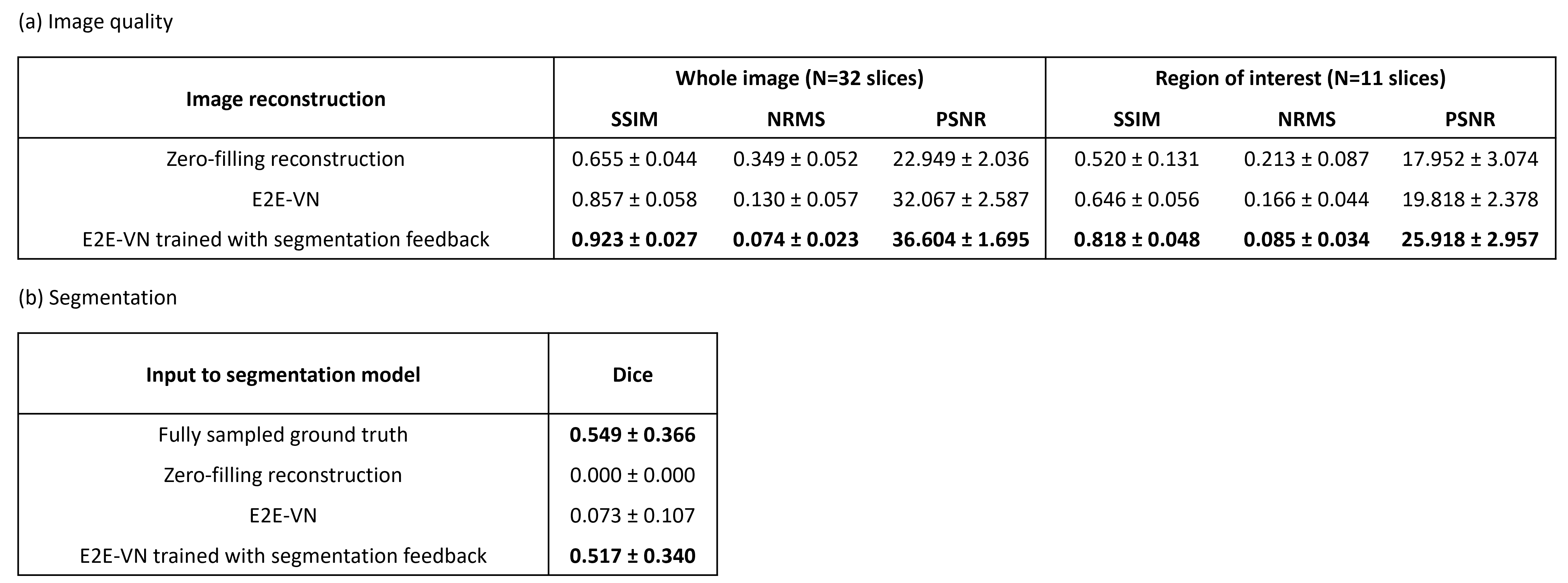
Optimal learning rate, $$$w_r$$$ and $$$w_s$$$ are selected through grid search. The proposed approach is compared to the baseline E2E-VN model and to zero-filled image reconstructions on the 8x accelerated test dataset. IQMs SSIM, NRMS and PSNR are compared. The segmentation model’s performance on reconstructed images is evaluated using the Dice score.
Results
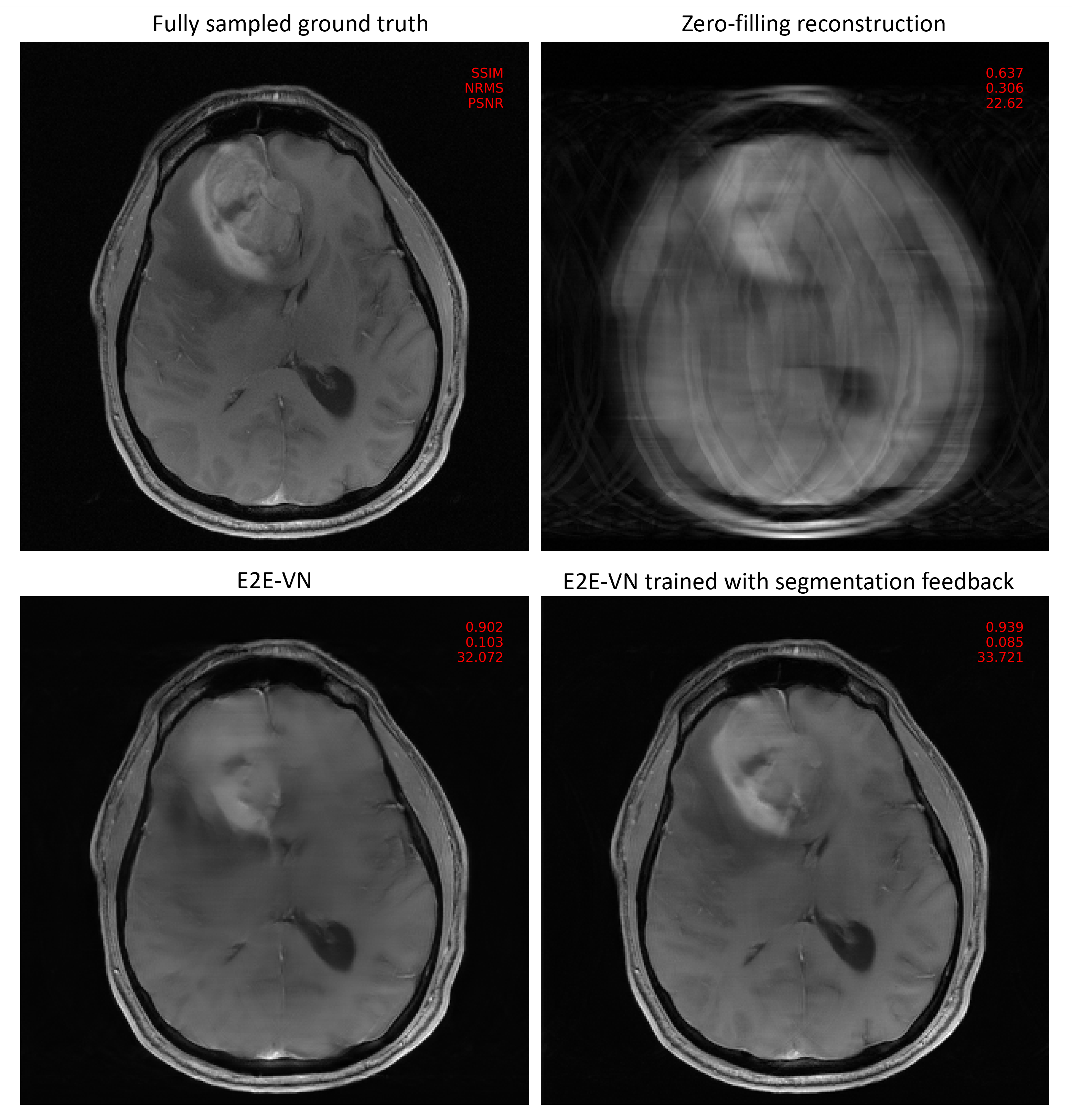
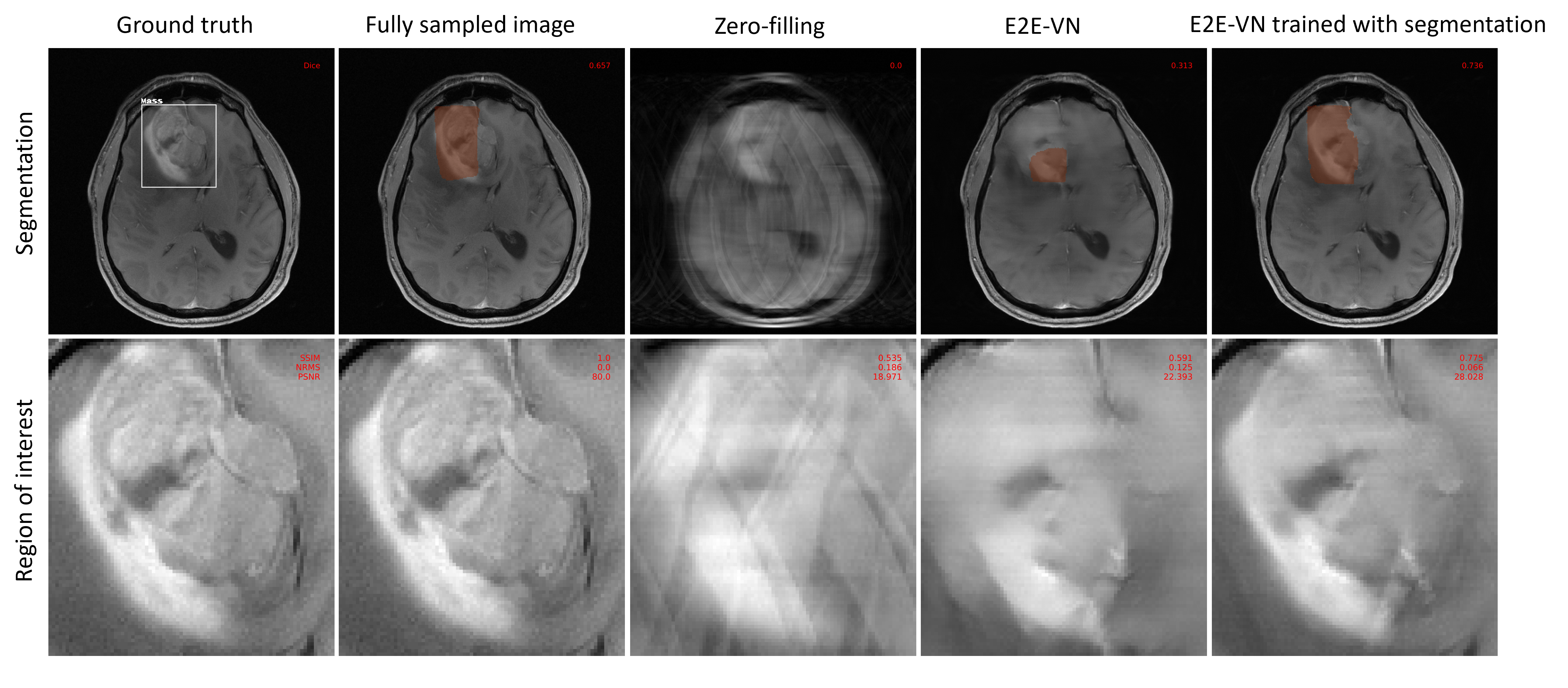
The proposed method resulted in higher SSIM and PSNR, and low NRMS of the entire image and regions of interest, as shown in Fig. 2. The downstream segmentation performance on reconstructed images with the proposed method are higher than the baseline E2E-VN, and slightly lower than the performance on fully sampled images. Visual assessment of Fig. 3 and Fig. 4 shows that the proposed method preserves boundaries of pathologies and internal structures better than the reconstruction that was trained only on a global image-based loss metric.Discussion
This work presents a first proof of concept, that training reconstruction models with feedback on diagnostic content results in improved image quality over baseline E2E-VN. Feedback from the segmentation model enables the reconstruction model to learn anatomically relevant features, crucial in detecting pathologies and improving the overall image quality.Reconstructed images with the proposed method are diagnostically usable by the downstream segmentation model. At 8x acceleration, it demonstrates a performance close to the performance on fully sampled images, thus, gaining a major benefit.
One drawback of the current method are the crude bounding box annotations as ground truth labels for training the segmentation model, resulting in sub-optimal segmentation performance. These annotations could be refined, further improving the performance of the model.
Conclusion
Training reconstruction models with additional feedback on diagnostic content notably improves the image quality and hence, diagnostic utility of the obtained images, compared to the other options presented.Further work will be done on additional methods for incorporating pathology-related feedback, such as attention masks or end-to-end training. Furthermore, the proposed method is planned to be modified and tested on more test data, different pathologies and anatomies.
Acknowledgements
This work was supported by Deutsche Forschungsgemeinschaft (DFG) – Project Number 513220538 and 512819079. In addition, we gratefully acknowledge the scientific support by ERC MIA-NORMAL (101083647) and HPC resources provided by the Erlangen National High Performance Computing Center (NHR@FAU) of Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) under the NHR project b143dc. NHR funding is provided by federal and Bavarian state authorities. NHR@FAU hardware is partially funded by the German Research Foundation (DFG) – 440719683.References
[1] Zhou Wang et al. “Image Quality Assessment: From Error Visibility to Structural Similarity”. In: IEEE Transactions on Image Processing 13 (4 Apr. 2004), pp. 600–612. issn: 10577149. doi: 10.1109/TIP.2003.819861.
[2] Sergey Kastryulin et al. “Image Quality Assessment for Magnetic Resonance Imaging”. In: IEEE Access 11 (Feb. 2023), pp. 14154–14168. issn: 2169-3536. doi: 10.1109/ACCESS. 2023.3243466.
[3] Martin Rajchl et al. “Deepcut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks”. In: IEEE Transactions on Medical Imaging 36.2 (2016), pp. 674–683.
[4] Florian Knoll et al. “Advancing Machine Learning for MR Image Reconstruction with an Open Competition: Overview of the 2019 fastMRI Challenge”. In: Magnetic Resonance in Medicine 84 (6 Dec. 2020), pp. 3054–3070. issn: 1522-2594. doi: 10.1002/MRM.28338. url: https://pubmed.ncbi.nlm.nih.gov/32506658/.
[5] Sriram, Anuroop et al. “End-to-End Variational Networks for Accelerated MRI Reconstruction". In: Martel, A.L., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2020. MICCAI 2020. Lecture Notes in Computer Science, vol 12262. Springer, Cham. https://doi.org/10.1007/978-3-030-59713-9_7
[6] Fabian Isensee et al. “nnU-Net: A Self-configuring Method for Deep Learning-Based Biomedical Image Segmentation”. In: Nature Methods 18 (Feb. 2021), pp. 1–9. doi: 10.1038/s41592-020-01008-z.5
Figures