2781
Fast Joint MR T1 and T2* Parameter Mapping with Scan Specific Unsupervised Networks1Industrial Engineering and Management Systems, Amirkabir University of Technology (Tehran Polytechnic), Tehran, Iran (Islamic Republic of), 2Hongik University, Seoul, Korea, Republic of, 3Radiology, Harvard Medical School, Boston, MA, United States, 4Boston Children’s Hospital, Boston, MA, United States, 5Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Charlestown, MA, United States
Synopsis
Keywords: Quantitative Imaging, Image Reconstruction
Motivation: Joint MAPLE is an MR parameter mapping technique with improved results which suffers from long processing times.
Goal(s): We propose a fast version of Joint MAPLE as a self-supervised, model-based multi-parameter mapping technique capable of jointly mapping T1, T2*, frequency and proton density in a whole brain volume ~50 times faster than the original version, while retaining its parameter mapping performance.
Approach: A fast whole brain reconstruction, transfer learning and a rapid initialization in optimization is incorporated.
Results: Results show that fast Joint MAPLE retains the mapping performance of the original version and outperforms existing methods.
Impact: Fast Joint MAPLE estimates T1, T2*, frequency and proton density of a volume ~50 times faster than the original version with the same performance. A fast volume reconstruction, transfer learning and a rapid initialization is incorporated for faster mapping.
Introduction
MR parameter mapping can offer detailed information to empower clinical diagnosis and research studies1–3. While the long scan times is a limitation3,4, a range of accelerated reconstruction techniques including parallel imaging5–11, model-based12–20 and deep learning methods21–24 have been developed to address this problem.Enhanced performance can be achieved with a synergistic combination of such approaches. Kim et. al.25 introduced MAPLE as a scan-specific parameter mapping technique with improved results. Recently, an extension of MAPLE called Joint MAPLE26 is introduced to address joint multi-parameter mapping in a multi-echo, multi-flip angle (MEMFA) GRE dataset to enable improved joint reconstruction of T1, T2*, frequency and proton density maps. However, it suffers from a prohibitively long computation time.
In this work, we introduce a fast version of Joint MAPLE which jointly maps T1, T2*, frequency and proton density ~50 times faster while retaining the mapping performance. We name it Fast Transfer Learning Joint MAPLE (FTL-Joint MAPLE) with the capability of whole brain reconstruction and incorporation of transfer learning which enables processing of large volumetric dataset with multi-echo and multi-flip angle setting in ~2 hours reconstruction time.
Data/code: https://github.com/AmirHeydariGit/fast_joint_maple
Theory and Methods
Fig. 1. shows the main steps of the proposed method. In a slice-by-slice manner, the selected sub-sampled MEMFA k-space data of a volume is input to the zero-shot self-supervised learning27 reconstruction (ZS-SSL Recon) to reconstruct MEMFA images. The signal model S generates the synthetic MEMFA images.Loss1 is computed by comparing the reconstructed and synthetic MEMFA images and Loss2 is computed by matching the original sub-sampled k-space data and the output of the forward model A on the synthetic images. LossR is the ZS-SSL loss function. Total Loss function is a scaled summation of these three loss functions. A fast initialization scheme of unknown parameters is designed based on an initial optimization with Loss1.
As shown in Fig.2, ZS-SSL Recon is adapted to rapidly process a volume. At each training epoch, to obviate exhaustive slice-by-slice training, a randomly selected number of slices is input to the network to update the network parameters.
The parameters from the pre-trained prior network with a prior subject goes through a transfer learning step to fine tune the parameters to be adapted with the newly acquired subject volume data. Fine-tuned ZS-SSL Recon can infer the large MEMFA volume data of the new subject rapidly.
Dataset: Two fully sampled in-vivo 3D whole brain datasets from two different subjects were acquired using a Siemens 3T Prisma scanner with a 32-channel head-coil. The slice thickness is 2 mm and there are 72 and 64 partitions in kz direction respectively. Each dataset consists of six different echo times for each of the three flip angles.
Coil sensitivity maps were generated from the central 24x24 ACS using ESPIRiT28 and the geometric-decomposition coil compression29 (GCC) is used as the coil compression technique.
Results
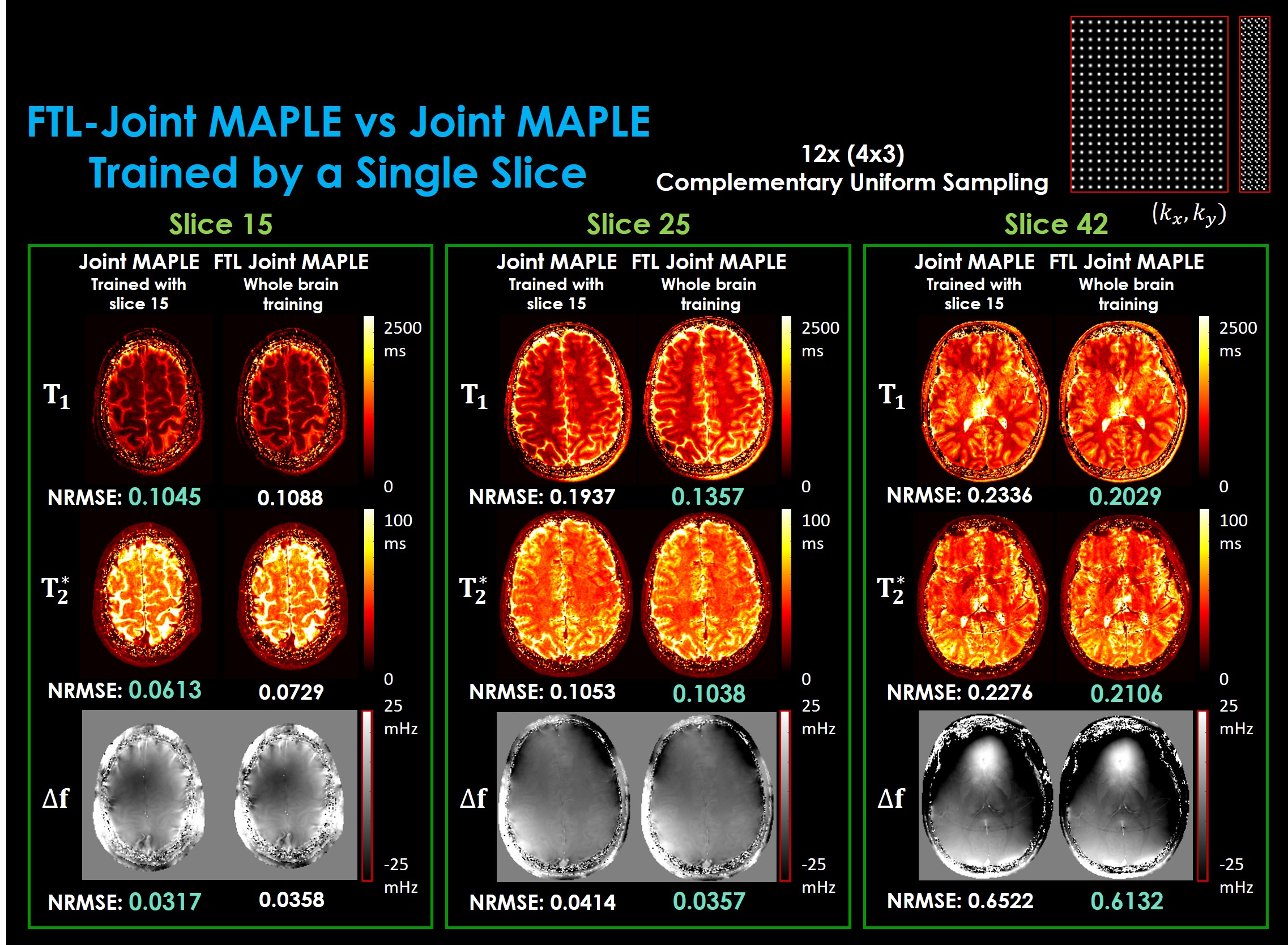
Codes run on an A100 GPU available on Google Collaboratory. Fig. 3 demonstrated the processing time of the proposed FTL-Joint MAPLE in comparison to the original Joint MAPLE while retaining the stability of the mapping performance. The largest part of the reconstruction time stems from the 32-channel head coil Joint MAPLE (part a) where ZS-SSL reconstructs each slice separately. Compressing the coil channels into 16 (part b) helps decrease the processing time in Joint MAPLE. Whole brain Joint MAPLE without the use of transfer learning (part c) converges fast but with worse results in comparison to the proposed FTL-Joint MAPLE (part d).Joint ZS-SSL trained by a single slice is capable of inferring all slices without the need for the extra training. However, its reconstruction performance will be deteriorated for new slices. As shown in Fig. 4, the original Joint MAPLE works well for mapping of the parameters of the trained slice, but in new slices, FTL-Joint MAPLE outperforms its performance in all parameters as it has learnt to reconstruct volumetric data.
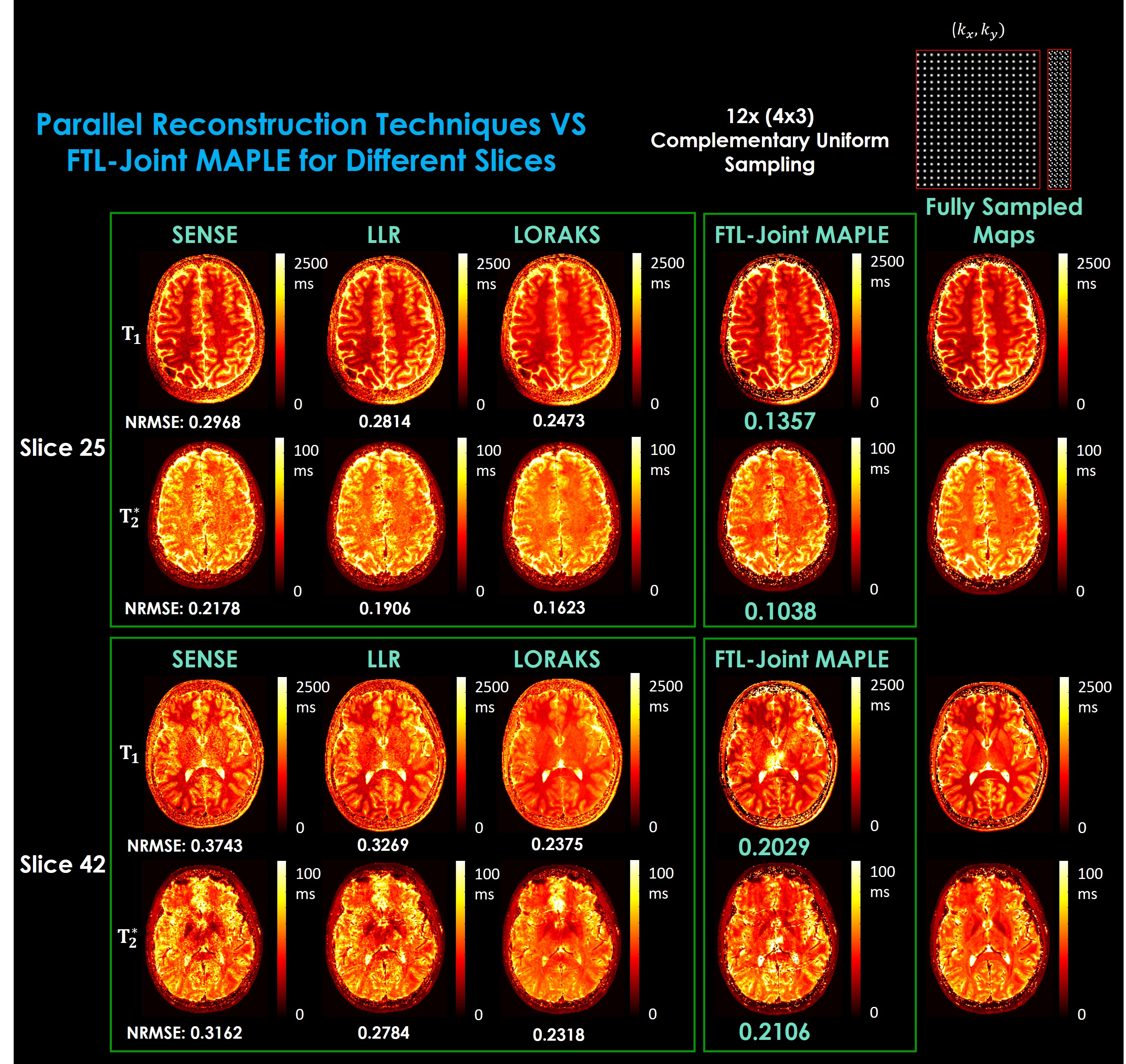
Fig. 5 shows that faster reconstruction of FTL-Joint MAPLE keeps the parameter mapping performance and it outperforms SENSE30, Locally Low Rank (LLR)11 and LORAKS31,32 reconstruction techniques.
Discussion and Conclusion
FTL-Joint MAPLE is a fast version of Joint-MAPLE and capable of joint T1, T2*, frequency and proton density mapping more than 50 times faster while it retains the parameter mapping performance. It incorporates a fast whole brain reconstruction, transfer learning and a fast initialization technique taking ~2 hours for mapping of a large whole brain multi-echo and multi-flip angles dataset. Transfer learning improves the fast results with no significant effect on the total time.Acknowledgements
This work was supported by research grants NIH R01 EB028797, U01 EB025162, P41 EB030006, U01 EB026996, R03 EB031175, R01 EB032378, UG3 EB034875, NVidia Corporation for computing support and National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No.2022R1F1A1074786).References
1. Feng L, Ma D, Liu F. Rapid MR relaxometry using deep learning: An overview of current techniques and emerging trends. NMR Biomed. 2022;35(4):e4416.
2. Deoni SCL. Quantitative relaxometry of the brain. Top Magn Reson imaging. 2010;21(2):101-113.
3. Berg RC, Leutritz T, Weiskopf N, Preibisch C. Multi‐parameter quantitative mapping of R1, R2*, PD, and MTsat is reproducible when accelerated with Compressed SENSE. Neuroimage. 2022;253:119092.
4. Jansen JFA, Kooi ME, Kessels AGH, Nicolay K, Backes WH. Reproducibility of quantitative cerebral T2 relaxometry, diffusion tensor imaging, and 1H magnetic resonance spectroscopy at 3.0 Tesla. Invest Radiol. 2007;42(6):327-337.
5. Feng L, Otazo R, Jung H, et al. Accelerated cardiac T2 mapping using breath‐hold multiecho fast spin‐echo pulse sequence with k‐t FOCUSS. Magn Reson Med. 2011;65(6):1661-1669.
6. Zhao B, Lu W, Hitchens TK, Lam F, Ho C, Liang Z. Accelerated MR parameter mapping with low‐rank and sparsity constraints. Magn Reson Med. 2015;74(2):489-498.
7. Velikina J V, Alexander AL, Samsonov A. Accelerating MR parameter mapping using sparsity‐promoting regularization in parametric dimension. Magn Reson Med. 2013;70(5):1263-1273.
8. Wang L, Schweitzer ME, Padua A, Regatte RR. Rapid 3D‐T1 mapping of cartilage with variable flip angle and parallel imaging at 3.0 T. J Magn Reson Imaging An Off J Int Soc Magn Reson Med. 2008;27(1):154-161.
9. Doneva M, Börnert P, Eggers H, Stehning C, Sénégas J, Mertins A. Compressed sensing reconstruction for magnetic resonance parameter mapping. Magn Reson Med. 2010;64(4):1114-1120.
10. Huang C, Graff CG, Clarkson EW, Bilgin A, Altbach MI. T2 mapping from highly undersampled data by reconstruction of principal component coefficient maps using compressed sensing. Magn Reson Med. 2012;67(5):1355-1366.
11. Zhang T, Pauly JM, Levesque IR. Accelerating parameter mapping with a locally low rank constraint. Magn Reson Med. 2015;73(2):655-661.
12. Sumpf TJ, Uecker M, Boretius S, Frahm J. Model‐based nonlinear inverse reconstruction for T2 mapping using highly undersampled spin‐echo MRI. J Magn Reson Imaging. 2011;34(2):420-428.
13. Sumpf TJ, Petrovic A, Uecker M, Knoll F, Frahm J. Fast T2 mapping with improved accuracy using undersampled spin-echo MRI and model-based reconstructions with a generating function. IEEE Trans Med Imaging. 2014;33(12):2213-2222.
14. Zhao B, Lam F, Liang Z-P. Model-based MR parameter mapping with sparsity constraints: parameter estimation and performance bounds. IEEE Trans Med Imaging. 2014;33(9):1832-1844.
15. Roeloffs V, Wang X, Sumpf TJ, Untenberger M, Voit D, Frahm J. Model‐based reconstruction for T1 mapping using single‐shot inversion‐recovery radial FLASH. Int J Imaging Syst Technol. 2016;26(4):254-263.
16. Wang X, Kohler F, Unterberg-Buchwald C, Lotz J, Frahm J, Uecker M. Model-based myocardial T1 mapping with sparsity constraints using single-shot inversion-recovery radial FLASH cardiovascular magnetic resonance. J Cardiovasc Magn Reson. 2019;21:1-11.
17. Hilbert T, Sumpf TJ, Weiland E, et al. Accelerated T2 mapping combining parallel MRI and model‐based reconstruction: GRAPPATINI. J Magn Reson Imaging. 2018;48(2):359-368.
18. Maier O, Schoormans J, Schloegl M, et al. Rapid T1 quantification from high resolution 3D data with model‐based reconstruction. Magn Reson Med. 2019;81(3):2072-2089.
19. Bilgic B, Kim TH, Liao C, et al. Improving parallel imaging by jointly reconstructing multi‐contrast data. Magn Reson Med. 2018;80(2):619-632.
20. Wang X, Cho J, Jun Y, Gagoski B, Bilgic B. Model-Based Phase-Difference Reconstruction for Accelerated Phase-Based T2 Mapping.
21. Cai C, Wang C, Zeng Y, et al. Single‐shot T2 mapping using overlapping‐echo detachment planar imaging and a deep convolutional neural network. Magn Reson Med. 2018;80(5):2202-2214.
22. Li H, Yang M, Kim J, et al. Ultra-fast simultaneous T1rho and T2 mapping using deep learning In Proceedings of the 28th Annual Meeting of ISMRM, Virtual Conference and Exhibition, 2020, vol. 2669.
23. Hamilton JI, Seiberlich N. Machine learning for rapid magnetic resonance fingerprinting tissue property quantification. Proc IEEE. 2019;108(1):69-85.
24. Virtue P, Stella XY, Lustig M. Better than real: Complex-valued neural nets for MRI fingerprinting. In: 2017 IEEE International Conference on Image Processing (ICIP). IEEE; 2017:3953-3957.
25. Kim TH, Cho J, Zhao B, Bilgic B. Accelerated MR Parameter Mapping with Scan-specific Unsupervised Networks. In Proceedings of the Annual Meeting of ISMRM, London, 2022. p. 4402.
26. Heydari A, Kim TH, Ahmadi A, Bilgic B. Joint MR T1 and T2* Parameter Mapping with Scan Specific Unsupervised Networks. In Proceedings of the Annual Meeting of ISMRM, Toronto, 2023. p. 7158.
27. Yaman B, Hosseini SAH, Akçakaya M. Zero-shot self-supervised learning for MRI reconstruction. arXiv Prepr arXiv210207737. Published online 2021.
28. Uecker M, Lai P, Murphy MJ, et al. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med. 2014;71(3):990-1001.
29. Zhang T, Pauly JM, Vasanawala SS, Lustig M. Coil compression for accelerated imaging with Cartesian sampling. Magn Reson Med. 2013;69(2):571-582.
30. Pruessmann KP, Weiger M, Scheidegger MB, Boesiger P. SENSE: sensitivity encoding for fast MRI. Magn Reson Med An Off J Int Soc Magn Reson Med. 1999;42(5):952-962.
31. Haldar JP. Low-rank modeling of local $ k $-space neighborhoods (LORAKS) for constrained MRI. IEEE Trans Med Imaging. 2013;33(3):668-681.
32. Kim TH, Setsompop K, Haldar JP. LORAKS makes better SENSE: phase‐constrained partial fourier SENSE reconstruction without phase calibration. Magn Reson Med. 2017;77(3):1021-1035.
33. Jenkinson M, Bannister P, Brady M, Smith S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. Neuroimage. 2002;17(2):825-841.
Figures
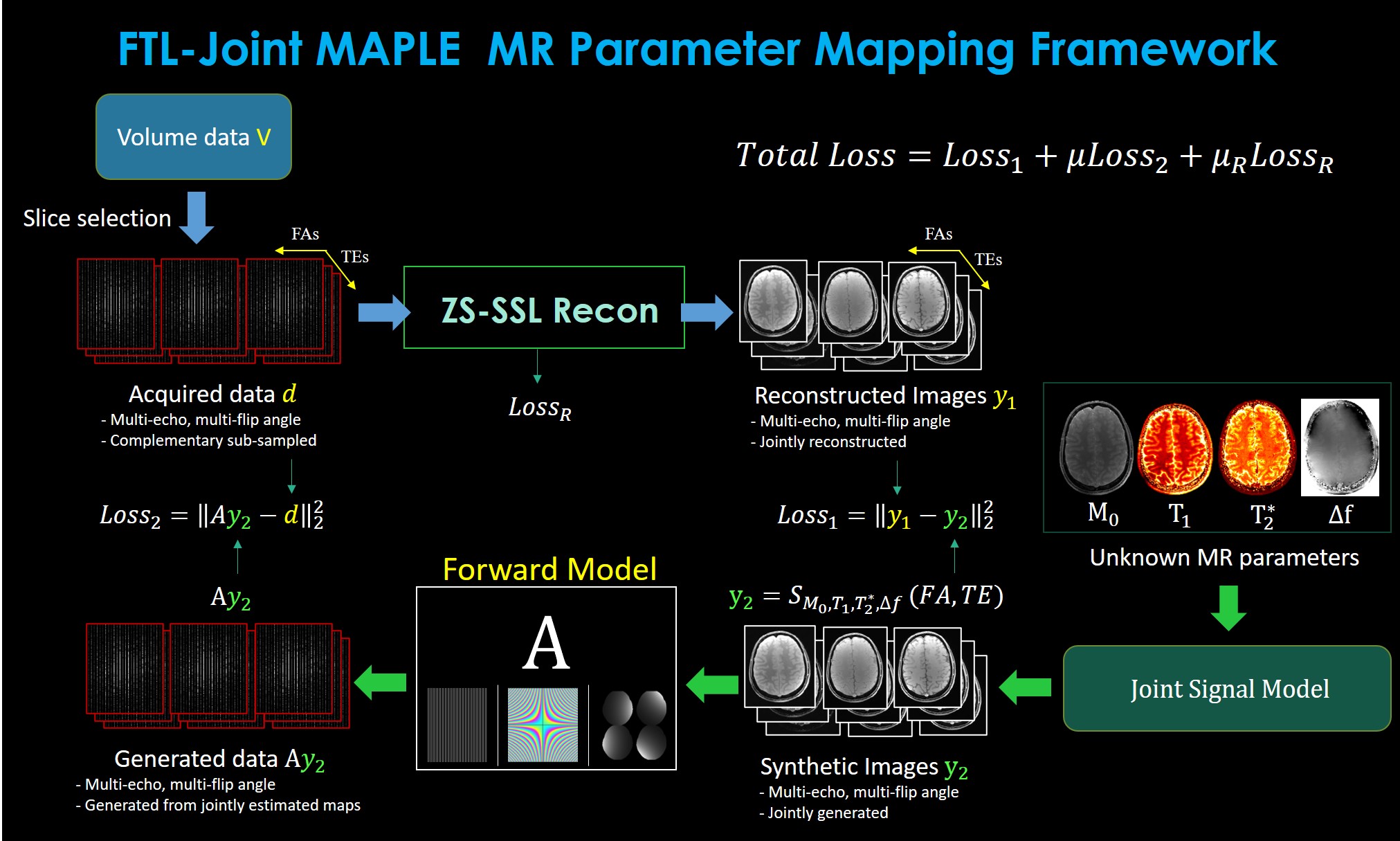
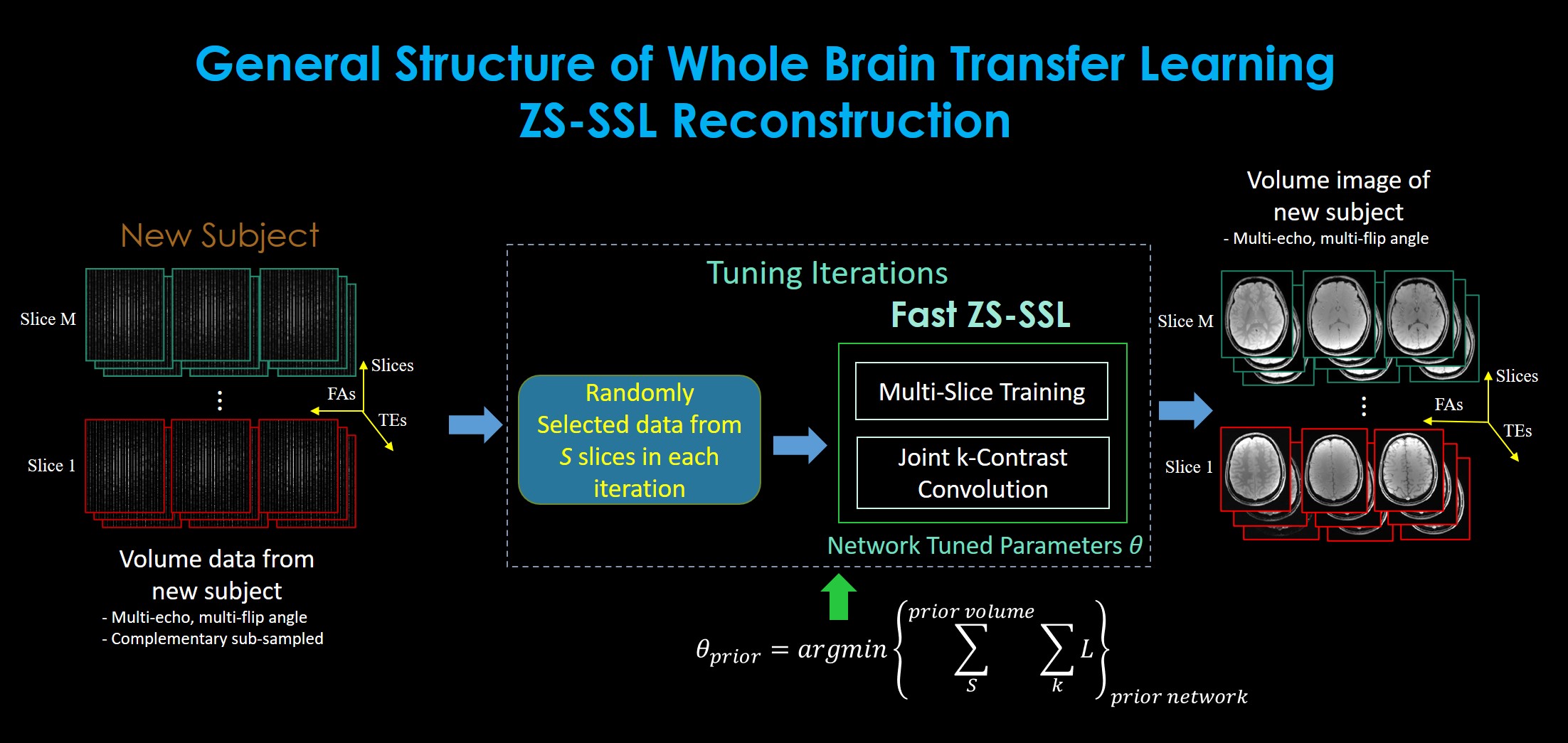
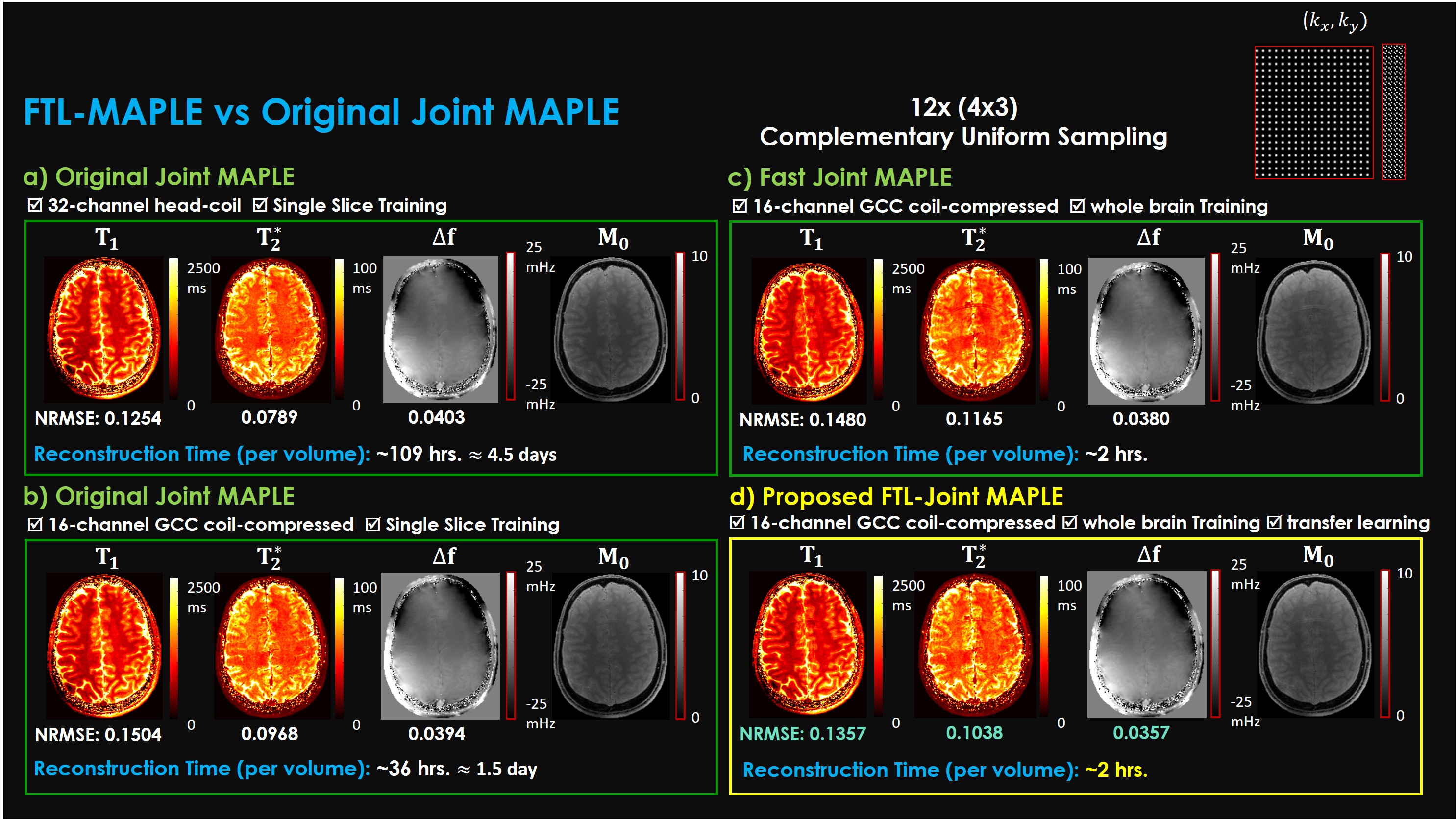
Fig. 3. Parameter mapping time and performance of FTL-Joint MAPLE vs Joint MAPLE. Data were retrospectively sub-sampled using uniform complementary33 sampling with 12x (4x3) acceleration factor. Normalized RMSE is used as the validation measurement. a) Original Joint MAPLE training the ZS-SSL specific to each slice and uses 32-channel head-coil dataset where in b) coil channels are compressed into 16 using GCC29, c) fast Joint MAPLE using whole brain training of ZS-SSL, and d) FTL-Joint MAPLE with whole brain training and transfer learning offering ~50x faster reconstruction.