2740
Enhancing Undersampled MR Reconstruction Performance via Denoising Diffusion Models1Harbin Institute of Technology, Harbin, China
Synopsis
Keywords: Image Reconstruction, Image Reconstruction
Motivation: Diffusion models, the latest generative modeling approach, hold significant promise for MRI reconstruction tasks.
Goal(s): Due to the lengthy and slow diffusion inverse process, diffusion model are challenging to apply directly to MR reconstruction tasks.
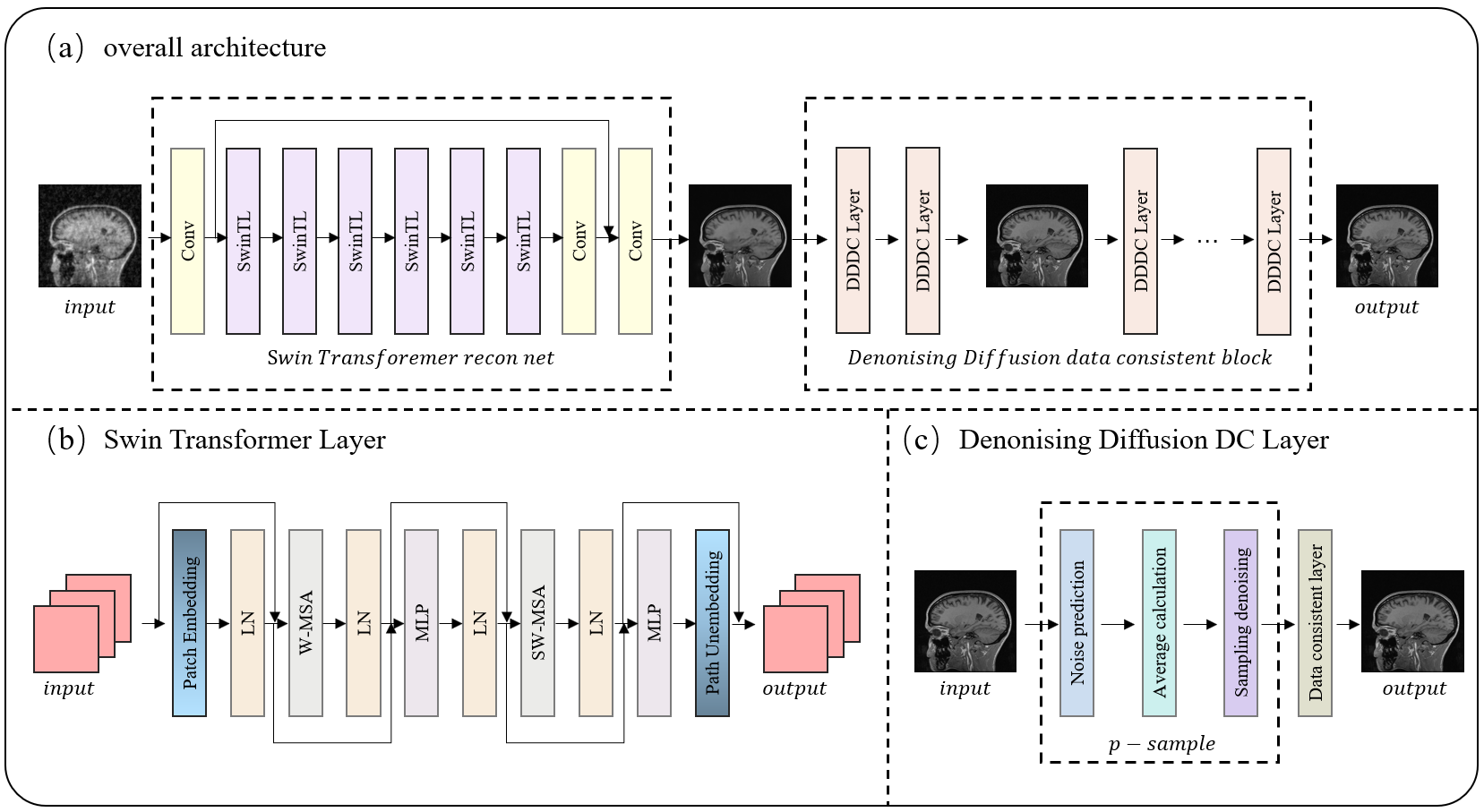
Approach: We employ SwinrnNet for initial reconstruction of undersampled images and introduce the DDDC module to supplement details, obviating the need for a protracted full reverse diffusion process.
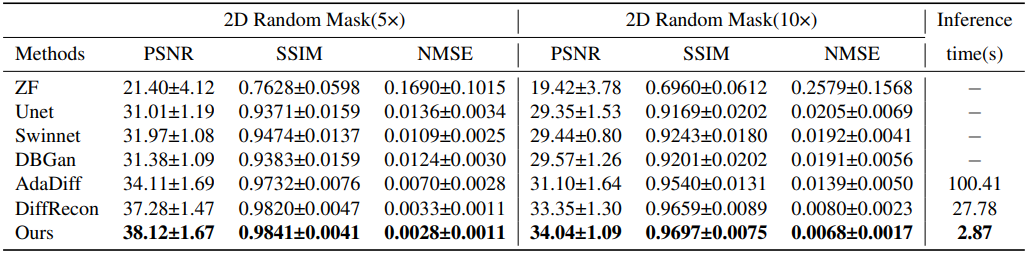
Results: Our method achieves high-quality reconstructions within 3 seconds, outperforming SOTA approaches in quantitative metrics. It exhibits superior reconstruction speed compared to other diffusion model methods, with a remarkable PSNR of 38.28 dB in the case of 5x acceleration.
Impact: The DDDC module we propose effectively enhances reconstruction quality and can be applied extensively to any reconstruction model proposed by other researchers. With only a minimal time investment, it significantly improves image quality.
Introduction
Reconstructing images from undersampled k-space data is a pivotal strategy for accelerating MR imaging. Currently, deep learning methods stand as the gold standard for MR undersampled reconstruction. Nevertheless, end-to-end network models often struggle to restore fine details, resulting in blurry reconstructions. Recently, diffusion models have demonstrated impressive performance in various computer vision tasks, showcasing substantial potential in MRI reconstruction tasks. However, the slow sampling process makes it challenging to directly apply diffusion models to MR reconstruction.In this paper, we propose a novel framework for undersampled MR reconstruction by integrating deep learning and diffusion model techniques. Our framework initiates undersampled image reconstruction using deep learning networks, followed by fine detail enhancement through denoising diffusion data consistency layers. Our method exhibits superior detail reconstruction performance in highly undersampled scenarios, significantly alleviating the detail blurring often associated with direct network model reconstructions, thereby enhancing reconstruction quality.Moreover, our approach achieves better reconstruction quality in seconds compared to other diffusion model methods, outperforming in terms of speed. Experimental results on the CC-359 dataset indicate our method's superior performance and remarkable efficiency under various undersampling masks and acceleration factors, achieving outstanding results in various quantitative metrics.Architecture
Mainstream diffusion model methods often start from Gaussian noise and undergo over a thousand reverse diffusion steps to generate images. The reverse diffusion process in diffusion models can be divided into two parts: the early phase of inference primarily focuses on generating basic image structure features, while the latter part concentrates on fine-tuning and denoising image details. For the MR reconstruction problem, end-to-end deep learning networks are highly capable of eliminating aliasing artifacts in undersampled images, generating excellent coarse reconstruction samples. As a result, there is no need to spend substantial time inferring coarse samples step by step from Gaussian noise. In this context, we rapidly generate coarse reconstruction samples from undersampled images using SwinrnNet. For the latter part of the reverse diffusion process, known for its remarkable denoising, sharpening, and detail generation capabilities, we propose a denoising diffusion data consistency module. Given its denoising and sharpening characteristics, combined with data consistency correction, this module enables fine-tuning of image details. The denoising diffusion data consistency module performs denoising diffusion steps alternated with data consistency correction, enriching sample details.SwinrnNet
SwinrnNet's basic unit is the Swin Transformer Layer, with Conv2D layers added at the beginning and end. The Swin Transformer Layer, compared to the original Transformer Layer, features window-based multi-head self-attention layers (W-MSA) and shifted window multi-head self-attention layers (SW-MSA). By partitioning feature maps into windows and limiting attention calculations to within each window, it significantly reduces computational requirements. The shifted window operation allows information exchange between different windows, and patch embedding downsamples gradually to increase the receptive field, capturing both local and global features.Denoising Diffusion Data Consistency Module
The denoising diffusion data consistency module consists of multiple DDDC layers, each containing one denoising diffusion step and data consistency correction.The strength of denoising prior can be adjusted by setting the hyperparameter t. In traditional diffusion models, the reverse process must correspond to the forward noise-adding process, and the denoising hyperparameter t follows a decreasing sequence from T to 0. However, in the DDDC layer, our main objective is to enrich sample details through alternate denoising diffusion and data consistency correction.Hence, strict adherence to a stepwise decreasing pattern is not required, and t for each layer can be set according to specific needs. Since SwinrnNet effectively removes noise artifacts, extensive denoising is unnecessary. Here, we achieve fine detail supplementation using 20 layers of DDDC with t set to 1.Experiments
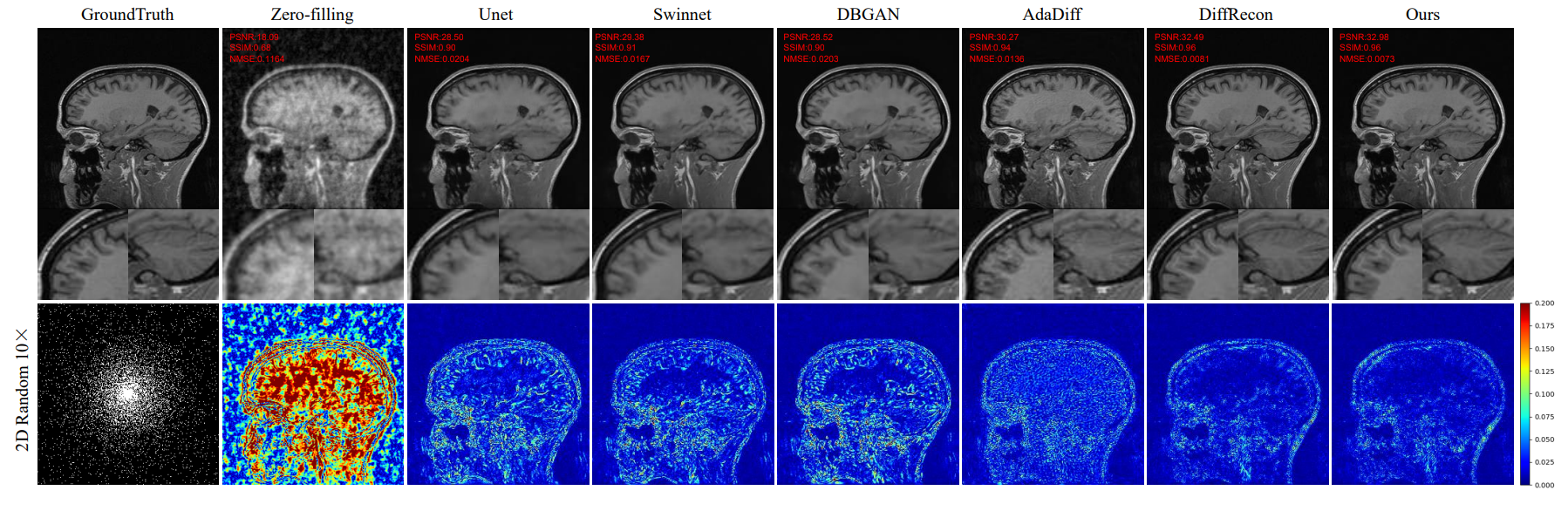
Among all methods, our approach achieved the best reconstruction performance. With a 5x acceleration, our method reached a PSNR of 38.12 dB and an SSIM of 0.9841. Furthermore, in comparison to two state-of-the-art diffusion model methods, AdaDiff and DiffRecon, our method not only excelled in terms of reconstruction metrics but also reduced the inference time to 2.87 seconds. Compared to DiffRecon, our method exhibited nearly a tenfold improvement in inference efficiency, while compared to AdaDiff, it demonstrated a nearly 35-fold enhancement in inference efficiency.Acknowledgements
This work is supported by Natural Science Foundation of Heilongjiang YQ2021F005 and China NSFC 62371167.References
[1] Katherine A. Rodby, Sergey Y Turin, R. J. Jacobs, Janet F Cruz, V. Hassid, A. Kolokythas, and A. Antony, “Advances in oncologic head and neck reconstruction: systematic review and future considerations of virtual surgical planning and computer aided design/computer aided modeling.,” Journal of plastic, reconstructive & aesthetic surgery : JPRAS, vol. 67 9, pp. 1171–85, 2014.
[2] Yang He, Yi Zhang, J. An, Xianyu Gong, Zhi qiang Feng, and Chuan-Bin Guo, “Zygomatic surface markerassisted surgical navigation: a new computer-assisted navigation method for accurate treatment of delayed zygomatic fractures.,” Journal of oral and maxillofacial surgery : official journal of the American Association of Oral and Maxillofacial Surgeons, vol. 71 12, pp. 210114, 2013.
[3] Bimeng Jie, B. Yao, R Li, Jin gang An, Yawei Zhang, and Y. He, “Post-traumatic maxillofacial reconstruction with vascularized flaps and digital techniques: 10-year experience.,” International journal of oral and maxillofacial surgery, 2020.
[4] Wen bo Zhang, Yao Yu, Y. Wang, C. Mao, Xiao jing Liu, Chuan-Bin Guo, Guang yan Yu, and Xin Peng, “Improving the accuracy of mandibular reconstruction with vascularized iliac crest flap: Role of computer-assisted techniques.,” Journal of cranio-maxillo-facial surgery : official publication of the European Association for Cranio-Maxillo-Facial Surgery, vol. 44 11, pp. 18191827, 2016.
[5] B. Yao, Y. He, B. Jie, J. Wang, J. An, Chuanbin Guo, and Y. Zhang, “Reconstruction of bilateral post-traumatic midfacial defects assisted by three-dimensional craniomaxillofacial data in normal chinese people-a preliminary study.,” Journal of oral and maxillofacial surgery : official journal of the American Association of Oral and Maxillofacial Surgeons, 2019.
[6] W. Zhang, Y. Wang, X. Liu, C. Mao, C. B. Guo, G. Yu, and X. Peng, “Reconstruction of maxillary defects with free fibula flap assisted by computer techniques.,” Journal of cranio-maxillo-facial surgery : official publication of the European Association for Cranio-MaxilloFacial Surgery, vol. 43 5, pp. 630–6, 2015.
[7] Stefan Zachow, Hans Lamecker, Barbara Elsholtz, and Michael Stiller, “Reconstruction of mandibular dysplasia using a statistical 3d shape model,” 2005.
[8] Wiebke Semper-Hogg, Marc Anton Fuessinger, Steffen Schwarz, Edward Ellis, Carl-Peter Cornelius, Florian Andreas Probst, Marc Christian Metzger, and Stefan Schlager, “Virtual reconstruction of midface defects using statistical shape models.,” Journal of craniomaxillo-facial surgery : official publication of the European Association for Cranio-Maxillo-Facial Surgery, vol. 45 4, pp. 461–466, 2017.
[9] Fuessinger Marc Anton, Schwarz Steffen, Neubauer Joerg, Cornelius Carl-Peter, Gass Mathieu, Poxleitner Philipp, Zimmerer Ruediger, Metzger Marc Christian, and Schlager Stefan, “Virtual reconstruction of bilateral midfacial defects by using statistical shape modeling.,” Journal of cranio-maxillo-facial surgery : official publication of the European Association for Cranio-MaxilloFacial Surgery, vol. 47 7, pp. 1054–1059, 2019.
[10] Deqiang Xiao, Chunfeng Lian, Li lian Wang, Hannah H. Deng, Hung-Ying Lin, Kim-Han Thung, Jihua Zhu, Peng Yuan, Leonel Perez, Jaime Gateno, Steve GuoFang Shen, Pew-Thian Yap, James J. Xia, and Dinggang Shen, “Estimating reference shape model for personalized surgical reconstruction of craniomaxillofacial defects,” IEEE Transactions on Biomedical Engineering, vol. 68, pp. 362–373, 2021.
[11] N. Gellrich, A. Schramm, B. Hammer, S. Rojas, D. Cufi, W. Lagr` eze, and R. Schmelzeisen, “Computer-assisted secondary reconstruction of unilateral posttraumatic orbital deformity,” Plastic and Reconstructive Surgery, vol. 110, pp. 1417C1429, 2002.
12] Zuoyong Li, Le An, Jun Zhang, Li Wang, James J. Xia, and Dinggang Shen, “Craniomaxillofacial deformity correction via sparse representation in coherent space,” in MLMI, 2015.
[13] Li Wang, Yi Ren, Yaozong Gao, Zhen Tang, Ken Chung Chen, Jianfu Li, Steve Guo-Fang Shen, Jin Yan, Philip K. M. Lee, Ben Chow, James J. Xia, and Dinggang Shen, “Estimating patient-specific and anatomically correct reference model for craniomaxillofacial deformity via sparse representation.,” Medical physics, vol. 42 10, pp. 5809–16, 2015.
[14] ̈ Ozg ̈ un C ̧ ic ̧ek, Ahmed Abdulkadir, Soeren S Lienkamp, Thomas Brox, and Olaf Ronneberger, “3d u-net: learning dense volumetric segmentation from sparse annotation,” in Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., 2016, pp. 424–432.
[15] Guha Balakrishnan, Amy Zhao, Mert R Sabuncu, John Guttag, and Adrian V Dalca, “An unsupervised learning model for deformable medical image registration,” in IEEE CVPR, 2018, pp. 9252–9260.
Figures