2603
Deep-learning reconstruction of under-sampled readout-segmented echo-planar diffusion-weighted images at multiple b values1Department of Radiology and Nuclear Medicine, St. Olav's University Hospital, Trondheim, Norway, 2The Department of Circulation and Medical Imaging, NTNU - Norwegian University of Science and Technology, Trondheim, Norway
Synopsis
Keywords: IVIM, Diffusion/other diffusion imaging techniques, Readout-segmented EPI; super-resolution
Motivation: Readout-segmented (rs-) EPI typically yields improved DWI image quality compared to single-shot EPI, but it is time-consuming. This presently precludes its clinical use for multiple b-value diffusion modeling like IVIM.
Goal(s): To accelerate rs-EPI image acquisition without compromising quality using convolutional neural networks (CNNs) trained on high-resolution and under-sampled low-resolution images.
Approach: Three CNNs were trained and tested on synthetic and in vivo DWI datasets. The CNNs were tasked with reconstructing high-resolution images at multiple b values, and IVIM parameter maps were estimated for comparison.
Results: The CNNs reconstructed high-resolution DWI images and IVIM parameter maps of comparable quality to the fully-sampled data.
Impact: This approach could substantially reduce the scan times of readout-segmented EPI when used for multiple b-value diffusion modeling. It therefore offers the potential for improved image quality for IVIM imaging, at scan times comparable to conventional single-shot EPI acquisition.
Introduction
Readout-segmented (rs-) EPI1,2 divides image acquisition into multiple segments in the read-out direction, shortening the sampling time and effective TE compared to conventional single-shot EPI. This makes rs-EPI less sensitive to B0-inhomogeneity, susceptibility differences, motion and T2* decay, resulting in less distortion, blurring and ghosting, and overall improved image quality. However, these benefits come at the cost of extended scan time, which makes rs-EPI inaccessible clinically for any diffusion modeling that requires a high number of b values, such as intravoxel incoherent motion (IVIM) modelling.Our proposal involves convolutional neural networks (CNNs) that are trained using three fully-sampled high-resolution (HR) images and ten under-sampled (central rs-EPI pane) low-resolution (LR) images, all at different b values. The objective is for the LR images to contribute contrast information, while the network extracts detailed structural information from the HR images, to facilitate the reconstruction of a complete set of HR images. Hence, our approach attempts to yield the benefits of rs-EPI without extending the scan time. Conceptually, this work is related to super-resolution reconstruction3,4.
Methods
We implemented three CNNs (4 layers; 64-128-128-64 units) trained on three different datasets described below (two synthetic, one in-vivo). The input for each network was a set of 13 DWI images consisting of 3 HR images (b = 0, 140, 900 s/mm2) and 10 LR images (b = 10, 20, 40, 80, 110, 200, 300, 400, 500, 700 s/mm2). In this work, the LR images were generated synthetically from HR images by Fourier transforming, truncating one frequency dimension by a factor of five, and inverse-Fourier transforming, thus approximating the central pane of a five-pane rs-EPI acquisition. The output for each network were 10 reconstructed HR images at b values corresponding to the LR input. A mean-squared error loss between ground-truth HR and reconstructed HR images was used in training, with learning rate 0.0001, batch size = 16/20 (fractal-noise/in-vivo cases; see below), number of batches = 400 per epoch, and 100 epochs.IVIM parameter maps (D: diffusion, Dp: pseudo diffusion, Fp: perfusion fraction, and S0) were estimated by fitting the bi-exponential IVIM model5 to the 13 DWI images using nonlinear least squares.
Three datasets were considered:
- Synthetic fractal-noise data: Ground-truth IVIM parameter maps (240x240) were synthesized using fractal-noise generation (Perlin-based). One fractal-noise map was used to randomly define a mask for three tissue regions: white matter, gray matter and CSF. For each tissue type and IVIM parameter, additional fractal-noise maps were scaled to appropriate parameter values, and then combined with the mask. The IVIM equation was used to generate corresponding DWI images, and Rician noise was added (S0=0:1 equated to SNR=0:100). This approach synthesized spatial correlations similar to real data, but in a randomized fashion.
- Real in-vivo data: Corresponding HR DWI data (ss-EPI) was acquired from a healthy volunteer (20 slices, 12 repetitions) using a 3T Siemens Prisma.
- Synthetic in-vivo data: The IVIM model was fit to the real in-vivo data, and then synthetic data was generated using the IVIM equation and adding Rician noise.
Results and discussion
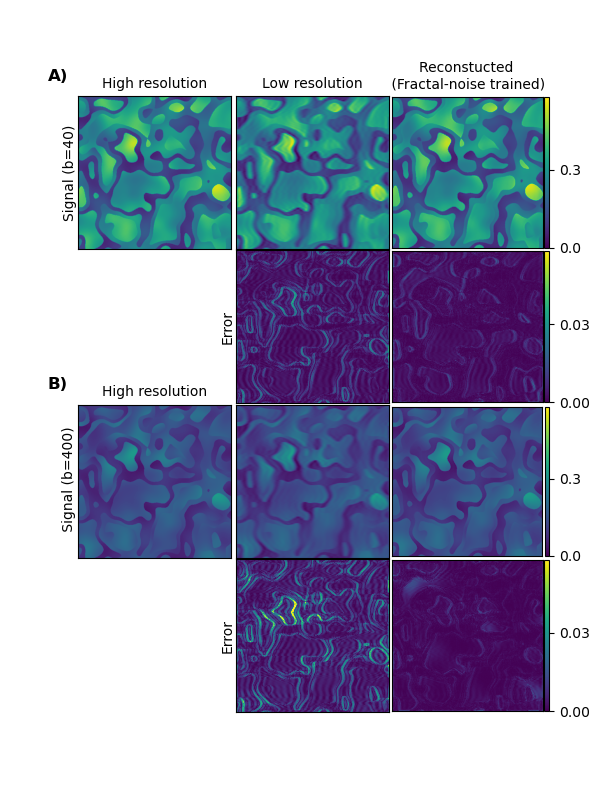
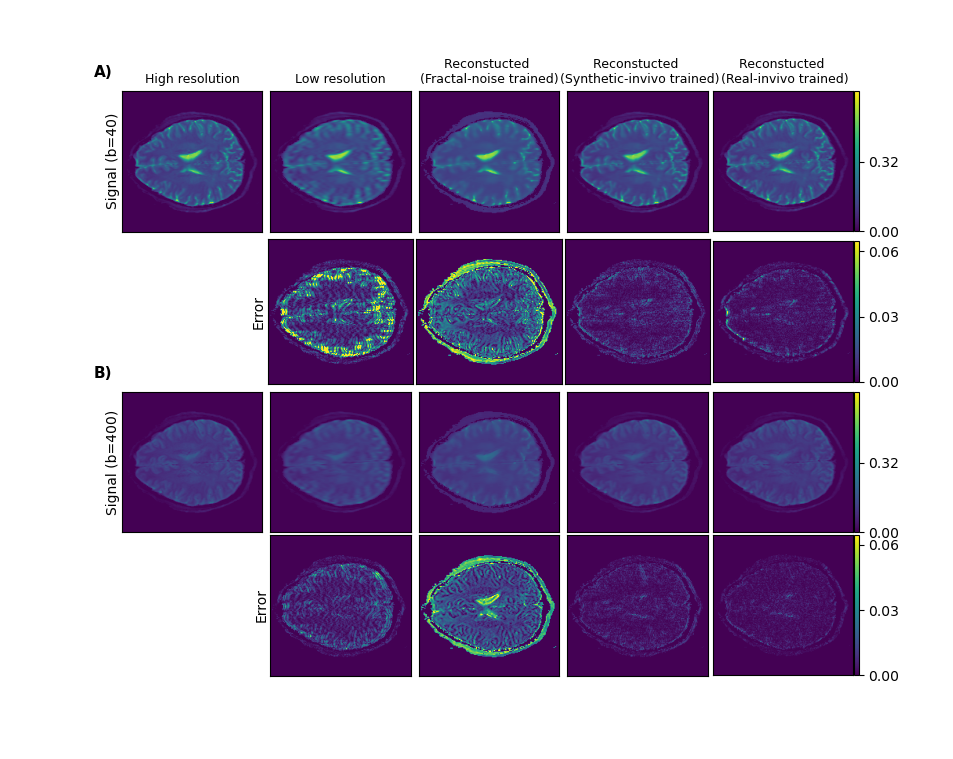
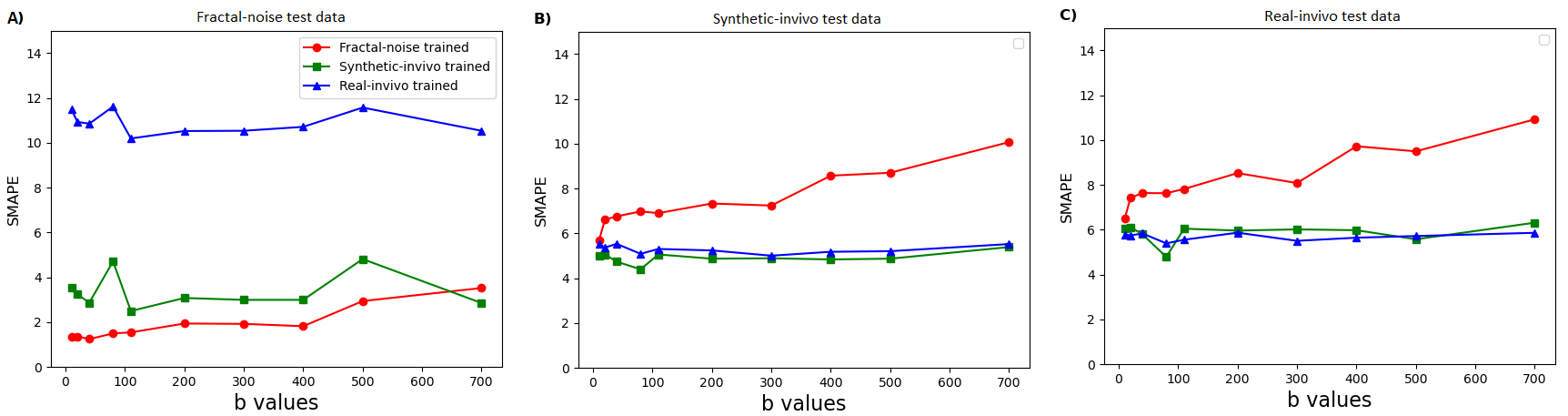
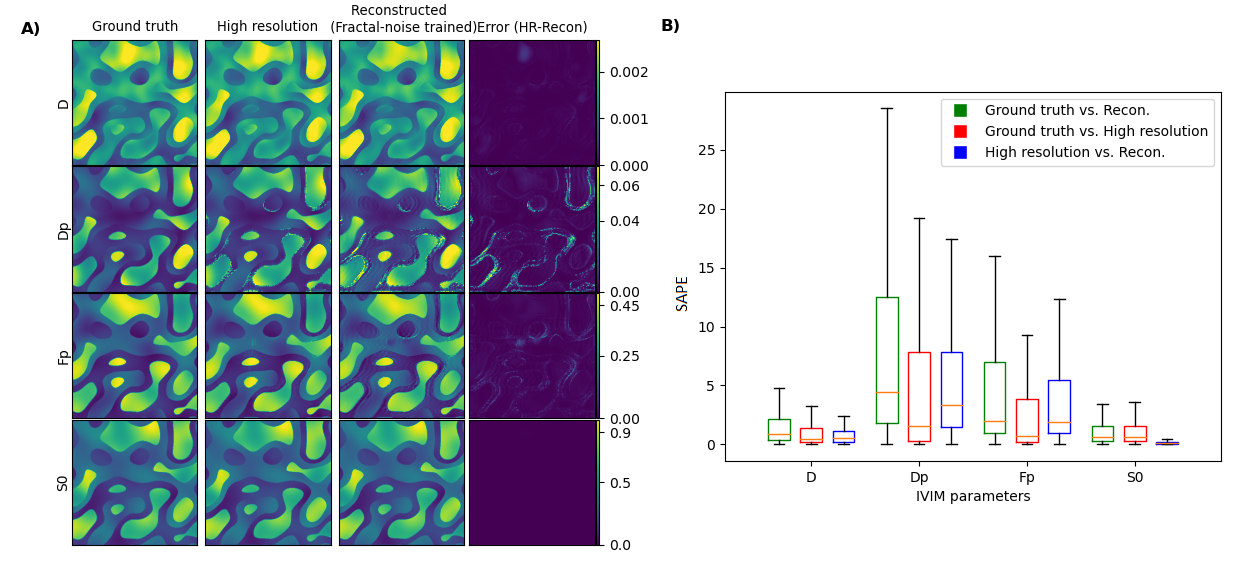
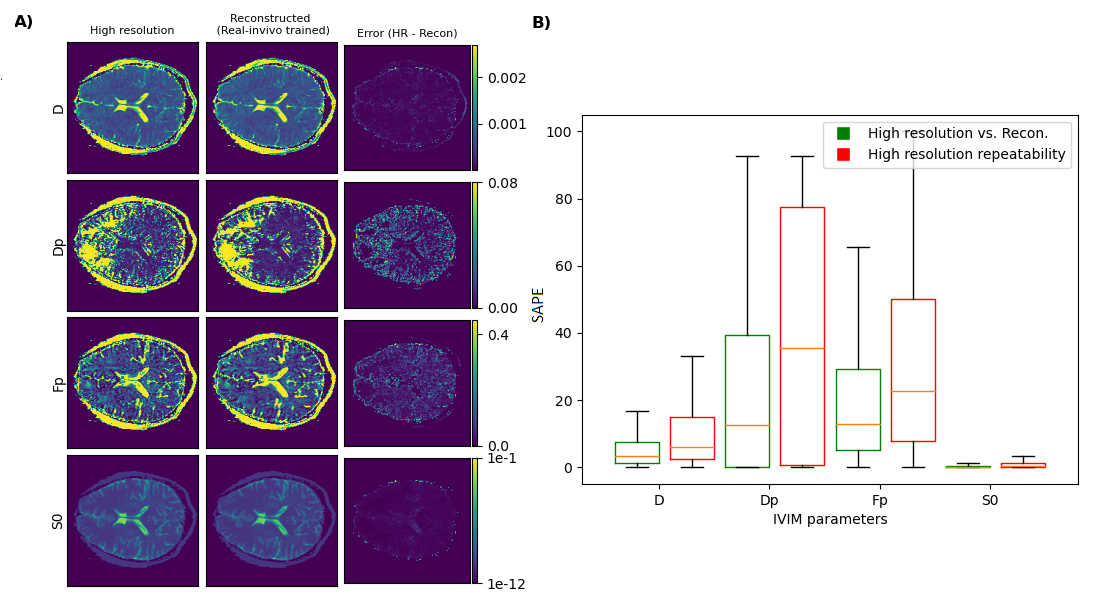
Fig. 1 shows example results for the fractal-noise-trained CNN applied to the fractal-noise test set. The reconstructed images display closer correspondence to the HR ground truth compared to the up-scaled LR counterparts. Fig. 2 displays example results for all three CNNs applied to the real in-vivo test set. We observe a substantial reduction in error for the networks trained on either synthetic or real in-vivo data. Fig. 3 compares the performance of the three CNNs when applied to representative data from each test set, for all b values. As expected, lower errors are observed when there is closer correspondence between the training and test data. However, the CNN trained on synthetic in-vivo data performs comparatively well on the real in-vivo test data, which may greatly simplify clinical implementation.Fig. 4 compares IVIM parameter maps estimated from reconstructed images and from (noisy) HR images corresponding to the fractal-noise test set. Slightly reduced yet comparable parameter accuracy is achieved from the reconstructed images. Fig. 5 displays a similar comparison for the real in-vivo data. There is good correspondence between the parameter maps estimated from the reconstructed HR images and those from the acquired HR images, where the error is actually less than that observed between repeated HR acquisitions.
In this preliminary study, we have used truncated single-shot EPI data. Future work will explore in vivo application more thoroughly with rs-EPI data.
Conclusion
The presented approach shows promise for enabling diffusion modelling using under-sampled rs-EPI DWI data acquired at multiple b values, at clinically relevant acquisition times.Acknowledgements
This work was supported by the Research Council of Norway (FRIPRO Researcher Project 302624).References
- Zhang H, Huang H, Zhang Y, Tu Z, Xiao Z, Chen J, Cao D. Diffusion-weighted MRI to assess sacroiliitis: improved image quality and diagnostic performance of readout-segmented echo-planar imaging (EPI) over conventional single-shot EPI. Am. J. Roentgenol. 2021;217(2):450-459.
- Yeom KW, Holdsworth SJ, Van AT, Iv M, Skare S, Lober RM, Bammer R. Comparison of readout-segmented echo-planar imaging (EPI) and single-shot EPI in clinical application of diffusion-weighted imaging of the pediatric brain. Am. J. Roentgenol. 2013:W437-443.
- Van Reeth E, Tham IWK, Tan CH, Poh CL. Super-resolution in magnetic resonance imaging: a review. Concepts Magn. Reson. A 2012;40A:306–325.
- Luo S, Zhou J, Yang Z, Wei H, Fu Y. Diffusion MRI super-resolution reconstruction via sub-pixel convolution generative adversarial network. Magn. Reson. Imaging 2022;88:101-107.
- Le Bihan D, Breton E, Lallemand D, Grenier P, Cabanis E, Laval-Jeantet M. MR imaging of intravoxel incoherent motions: application to diffusion and perfusion in neurologic disorders. Radiology 1986;161(2):401–407.
Figures