2459
A deep image prior based refinement for 3D phase unwrapping in brain MRI1School of EECS, University of Queensland, Brisbane, Australia, 2Central South University, China, Changsha, China
Synopsis
Keywords: Gray Matter, Quantitative Susceptibility mapping
Motivation: MRI signals have phase information from the GRE sequence, which reflects B0 field homogeneities.
Goal(s): Due to acquisition, the phase is converted from complex data, ranging from -π to π and causing visual discontinuities. However, previous learning-based approaches have difficulties processing 3D brain data directly.
Approach: In this study, we introduced an unsupervised refinement based on Deep Image Prior to enhance the performance of the pre-trained networks (PHU-DIP), and the inference were performed on one simulated and one in vivo brain.
Results: The PHU-DIP method corrected the misclassification regions from the pre-trained networks and exhibited the significant time-efficiency compared to conventional method.
Impact: The PHU-DIP provided a refinement scheme that help to improve the performance of a well-trained network. This technique could also be expanded onto other training modes and other pathological conditions.
Introduction
Phase images from the Gradient Echo sequence reflect the homogeneities of the magnetic field. Given the architecture of the MRI acquisition process, phase values are extracted from complex data and subsequently folded within the -π to π. This restricted range formed a series of boundaries, resulting in ambiguities and discontinuities in the phase data. Previous learning-based networks (1, 2) were tested on 2D data. In this study, we investigated a refinement scheme that enhanced two 3D U-Net frameworks, using principles of Deep Image Prior (DIP) (3, 4). DIP's loss function modified a physical model and a morphological feature, improving reconstructions from both networks. Our method was tested on one simulation and one in vivo subject and made comparisons to the conventional PRELUDE methods (5).Methodology
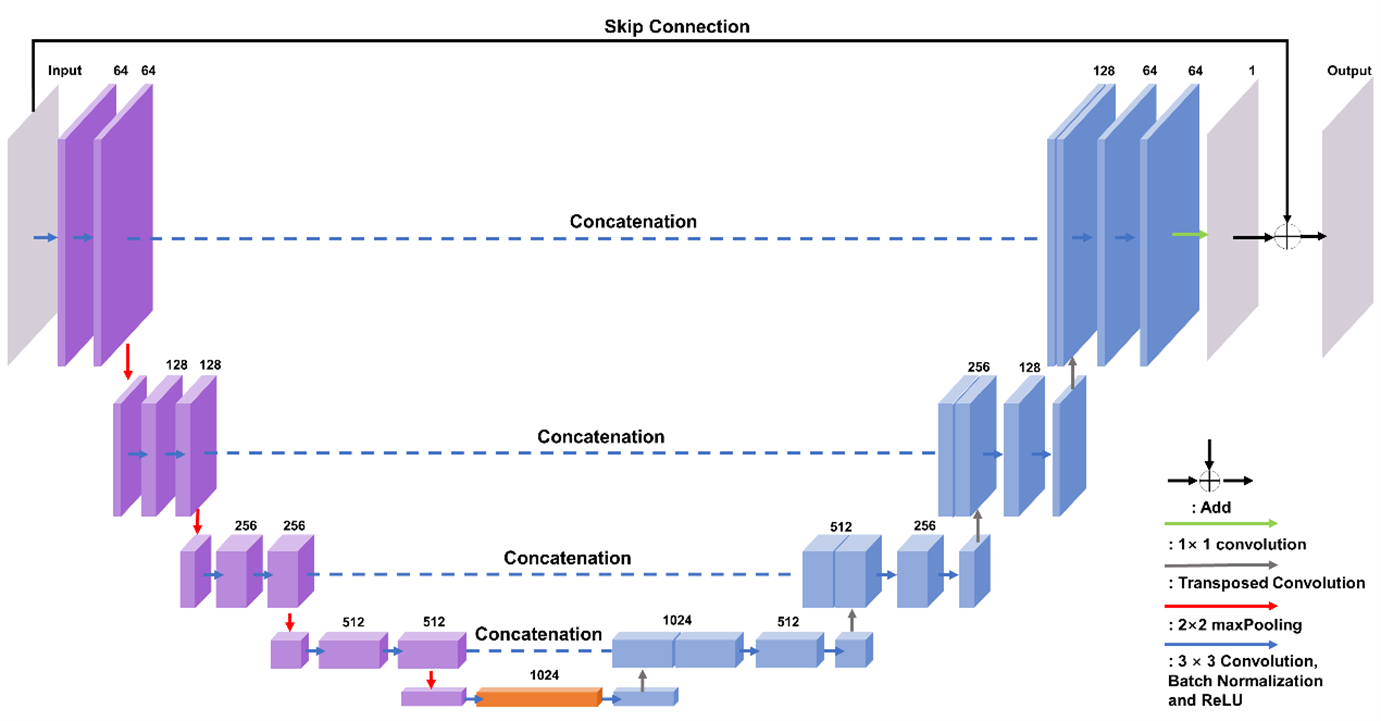
Training-set simulation and U-net frameworkWe build two training networks with the same U-net architecture, namely PHUnet and PhaseNet3D. Network configurations are 18 convolution layers (kernel size: 3×3×3) and 18 batch normalization layers, 4 max-pooling layers (kernel size: 2×2×2), 1 final convolutional layer (kernel size: 1×1×1), and 4 feature concatenations, illustrated in Figure 1. For loss function, PHUnet was trained by CE loss only, while PhaseNet3D added the L1 loss and the residue loss:
\(\text{Loss}_{\text{Res}}=\sqrt{\cfrac{1}{N}\sum\left(|U_{x}^{2}(\psi)-U_{x}^{2}(\varphi)|+|U_{y}^{2}(\psi)-U_{y}^{2}(\varphi)|+|U_{z}^{2}(\psi)-U_{z}^{2}(\varphi)|\right)}\)
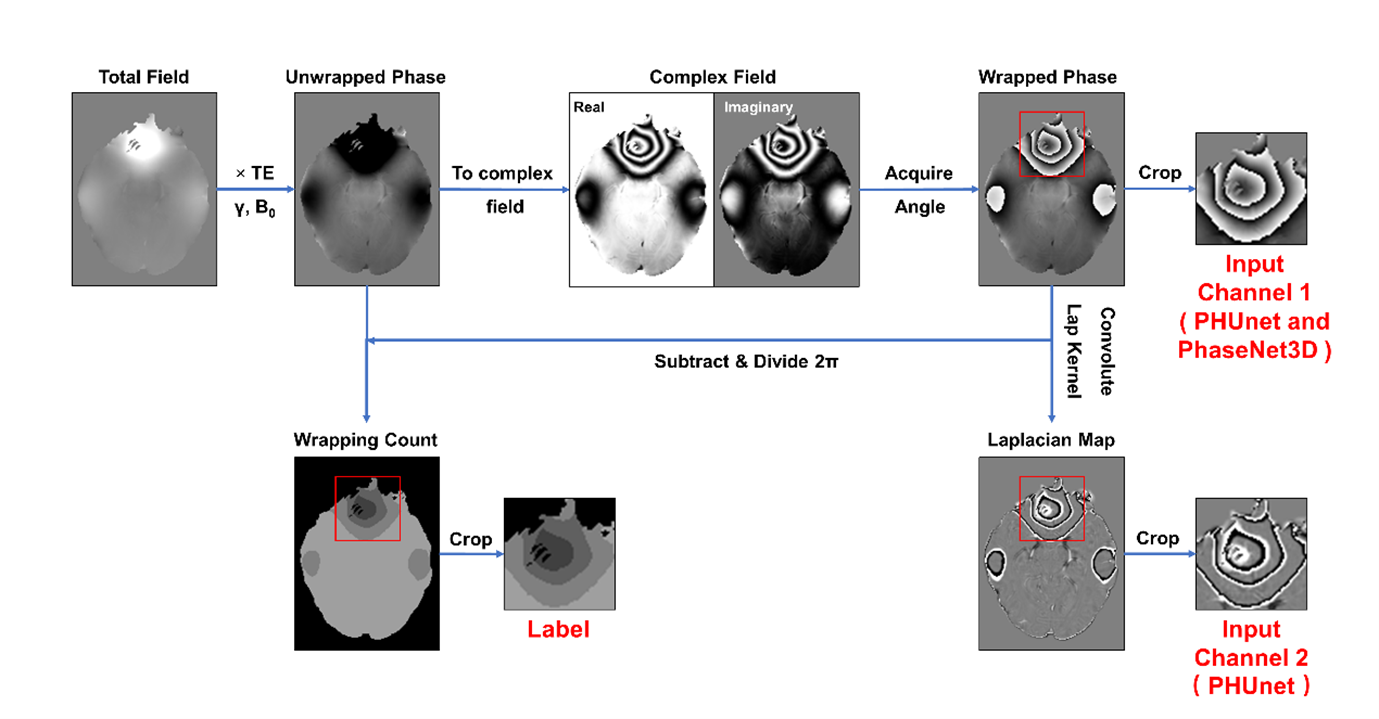
A total of 28,800 small patches (matrix size: 643) of raw phase were cropped from the existing 96 in vivo subjects (1 mm isotropic at 3T, matrix size 144×192×128). The corresponding wrapping counts, regarded as training labels, were calculated from the simulated unwrapped phase. Figure 2 demonstrates the entire pipeline of dataset generation. Typically, the Laplacian map of the raw phase was involved in PHUnet training, as the second input channel.
Deep image prior: the refinement
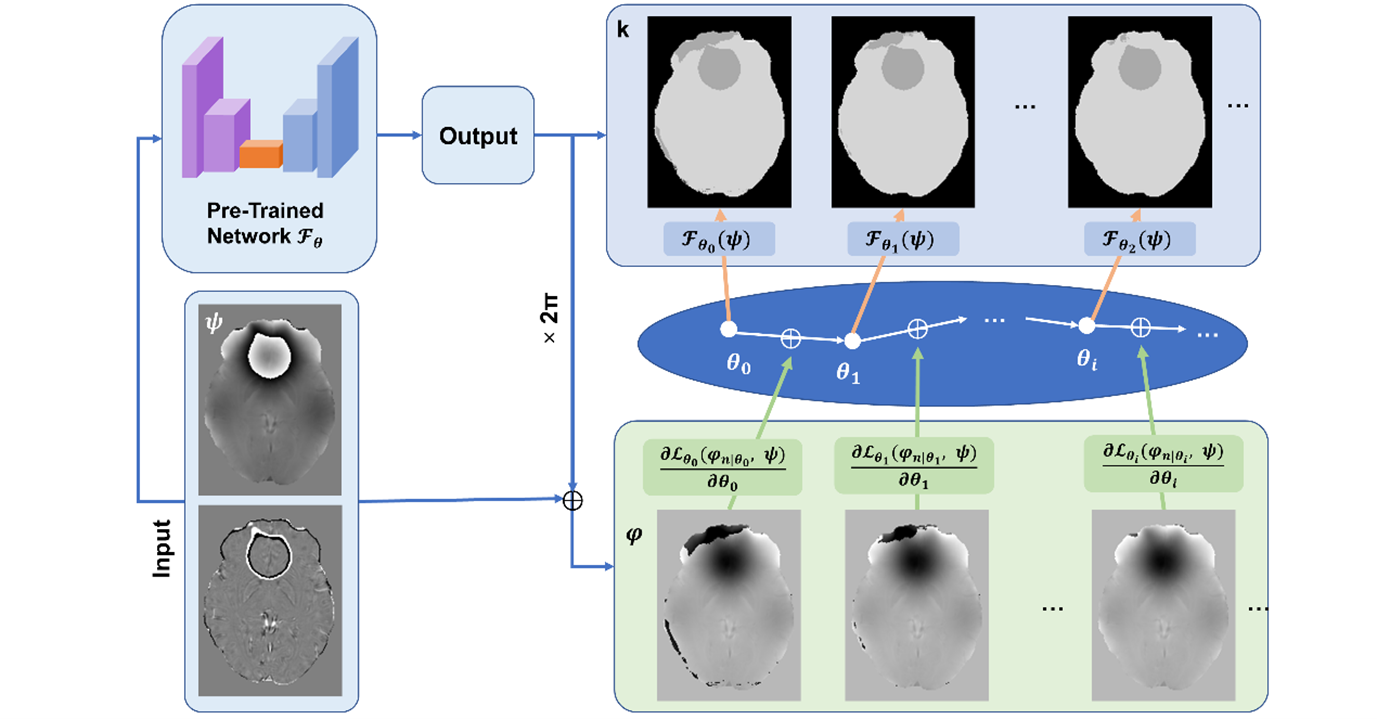
The refinement of the Deep Image Prior (DIP) scheme, shown in Figure 3, was implemented by the combination of two loss functions. The first was designed based on a physical model, which minimized the difference between the Laplacian of the reconstructed-unwrapped phase and the raw (wrapped) phase.
\(\text{Loss}_{\text{Lap}}=\cfrac{1}{N}\sum\left|\nabla^{2}\varphi_{\text{pre}}-\left(\cos(\psi_{\text{raw}})\nabla^{2}\sin(\psi_{\text{raw}})-\sin(\psi_{\text{raw}})\nabla^{2}\cos(\psi_{\text{raw}})\right)\right|\)
The second was the total variation loss with one-voxel-erosion:
\(\text{Loss}_{\text{TV}}=\cfrac{1}{N}\sum|\nabla_{x}(M)\nabla_{x}(\varphi)|+|\nabla_{y}(M)\nabla_{y}(\varphi)|+|\nabla_{z}(M)\nabla_{z}(\varphi)|\)
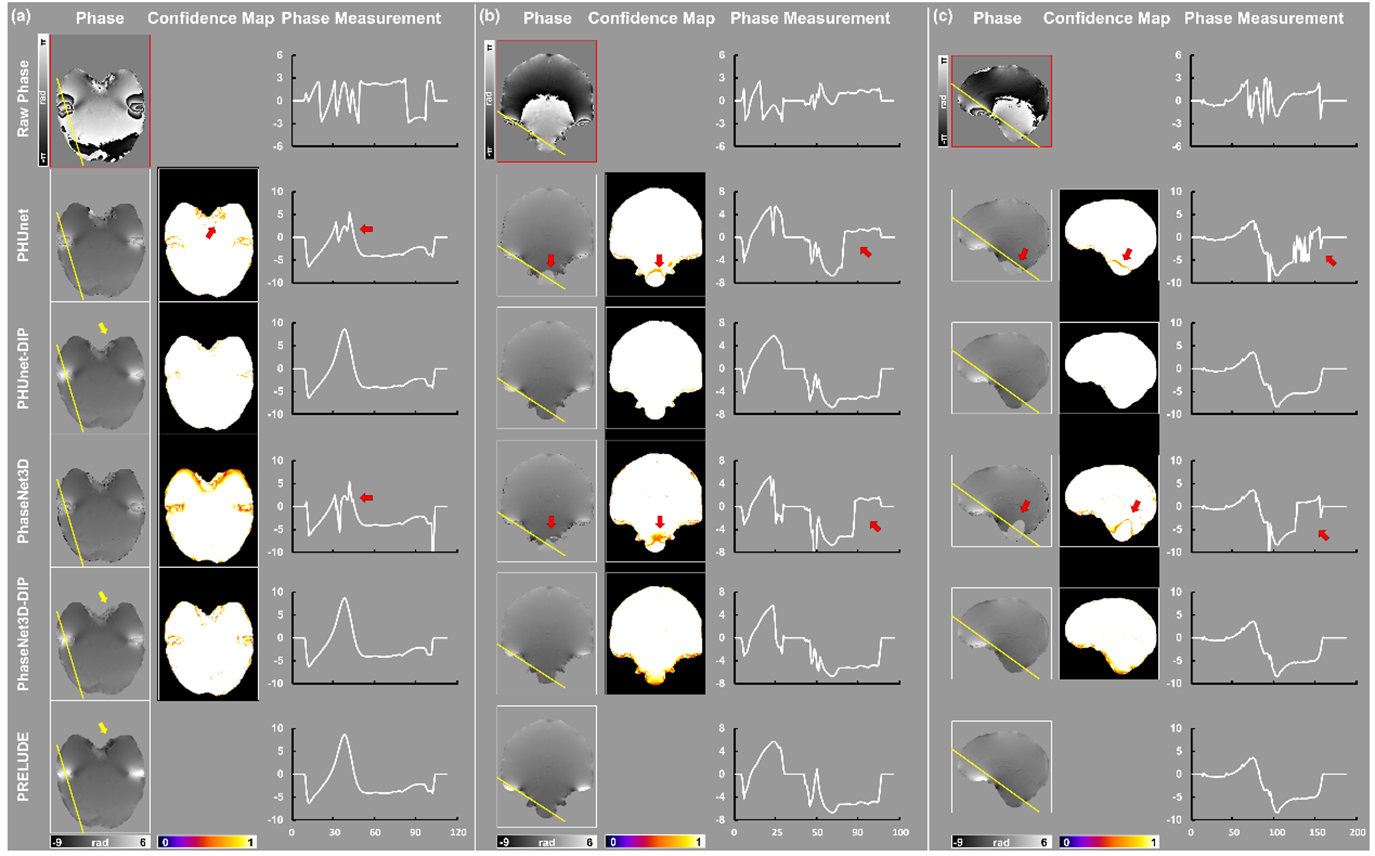
The performance of these two DIP-based approaches was compared not only to their initial results but also to a traditional unwrapping technique PRELUDE, using one simulated and one in vivo brain image. For simulation results, we presented the confidence map from CE loss probabilities. For in vivo experiments, we also plotted the line profile across the densely wrapped regions as sinus and antrum auris.
Results
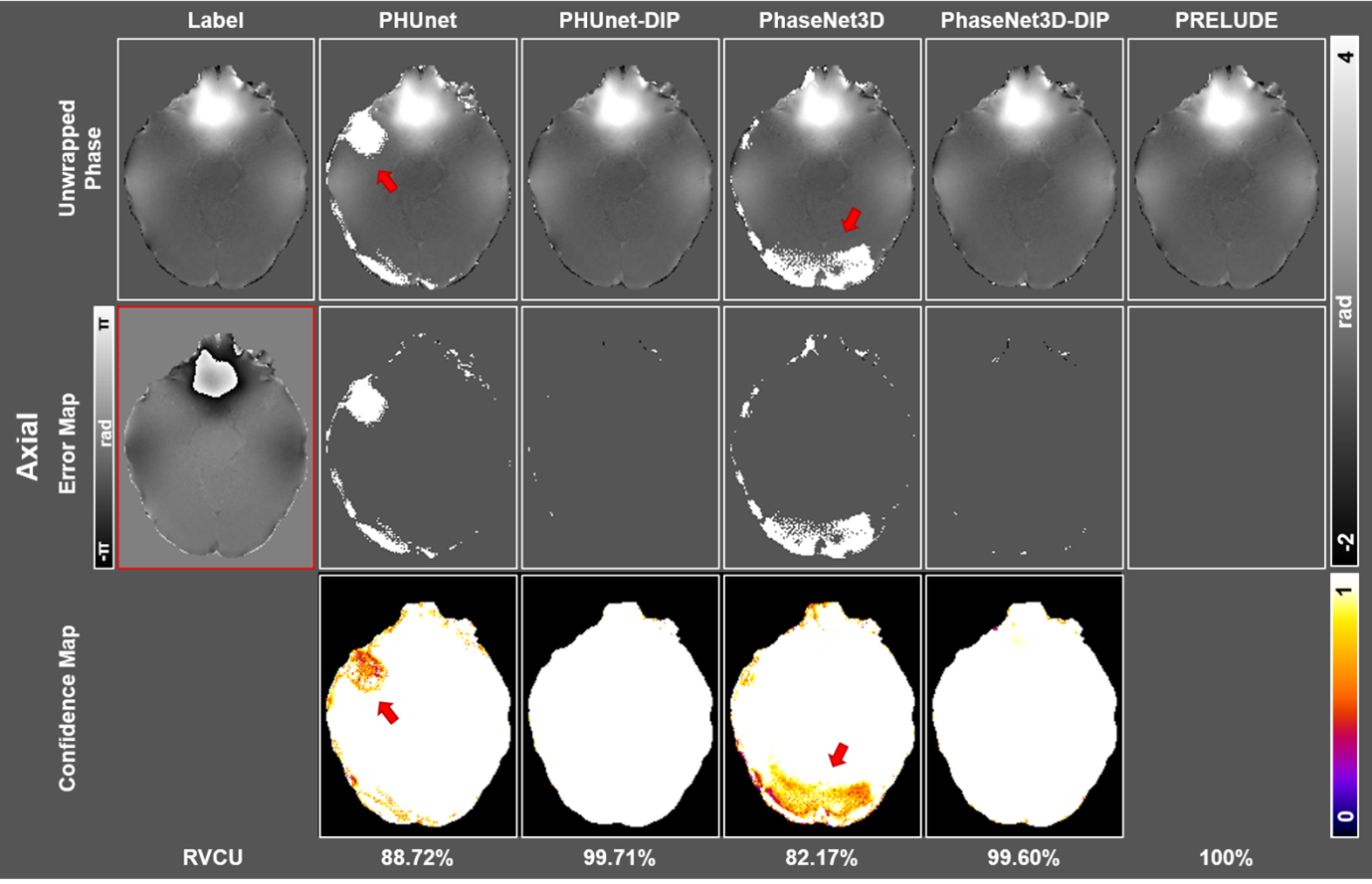
Figure 4 illustrates the comparison of five-phase unwrapping methods on a simulated brain tissue with 3ms TE. Initial unwrapped phases from PHUnet and PhaseNet3D showed visual misclassifications, particularly in the cortex and white matter. Concerning DIP results, both PHUnet-DIP and PhaseNet3D-DIP displayed significant improvements in correcting these areas. The error maps of the two DIP results were visually similar, leaving only a few voxels unwrapped. The results in confidence maps aligned those in the unwrapping phase and error maps, in which the probability of misclassified regions increased to ~1.0. In terms of quantitative metrics, the ratio of voxels that correctly unwrapped (RVCU) values saw a notable rise: PHUnet-DIP reached 99.71% from 88.72%, and PhaseNet3D-DIP achieved 99.60% from 82.17%.Figure 5 demonstrates the results of in vivo experimentation with phase unwrapping methods using a TE of 10.6ms. PHUnet-DIP and PhaseNet3D-DIP showed improved reconstructions with fewer misclassifications compared to their initial counterparts. PHUnet and PhaseNet3D had significant residual wrappings, highlighted by decreased confidence values near misclassified regions. After DIP refinement, the confidence values were increased. Specifically, PHUnet showed an error near the antrum auris, and PhaseNet3D had a shifted value in the cerebellum. Both inaccuracies were corrected during the post-DIP processing.
It was observed that DIP demonstrated temporal efficiency in comparison to the conventional PRELUDE method. Specifically, there was a reduction in processing time by approximately 90% in simulated subjects and 80% in practical real-world applications.
Discussion
This study has demonstrated that an unsupervised refinement method of 3D brain phase unwrapping (Phase-DIP) significantly improved the accuracy of pre-rained network results from data sets in both simulated and in vivo subjects, compared with conventional algorithms (i.e., PRELUDE). The origin of the improvement from the well-designed loss function in DIP, which followed the constraint of a physical model and morphological feature. The DIP was time-efficient during the refinement and exhibited a solid capability for misclassification corrections. Such performance could be generalized to both training models. The scheme of hyper-parameter tuning, like the investigation of early stopping, will be further studied.Acknowledgements
HS acknowledges support from the Australian Research Council (DE210101297, DP230101628).References
1. Zhou H, Cheng C, Peng H, Liang D, Liu X, Zheng H, et al. The PHU‐NET: A robust phase unwrapping method for MRI based on deep learning. Magnetic Resonance in Medicine. 2021;86(6):3321-33.
2. Spoorthi G, Gorthi S, Gorthi RKSS. PhaseNet: A deep convolutional neural network for two-dimensional phase unwrapping. IEEE Signal Processing Letters. 2018;26(1):54-8.
3. Ulyanov D, Vedaldi A, Lempitsky V, editors. Deep image prior. Proceedings of the IEEE conference on computer vision and pattern recognition; 2018.
4. Yang F, Pham T-A, Brandenberg N, Lütolf MP, Ma J, Unser M. Robust phase unwrapping via deep image prior for quantitative phase imaging. IEEE Transactions on Image Processing. 2021;30:7025-37.
5. Jenkinson M. Fast, automated, N‐dimensional phase‐unwrapping algorithm. Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine. 2003;49(1):193-7.
Figures