2246
Improved Deep Learning MR Image Enhancement with Synthetic Images1Subtle Medical Inc, Menlo Park, CA, United States
Synopsis
Keywords: Analysis/Processing, Machine Learning/Artificial Intelligence
Motivation: Deep learning (DL) based image enhancement requires paired data for supervised training. But separately acquired data pairs may encounter spatial mis-alignment that limits the model performance.
Goal(s): Incorporate synthetic data into the training set to address the mis-alignment issue and improve the quality and diversity of the training set.
Approach: Develop and validate the diffusion based image degrader to synthesize low quality images. Compare the performance of DL models trained with/without synthetic data.
Results: DL models trained with synthetic data can achieve similar performance compared to training with acquired pairs. Additional synthetic data can improve DL image enhancement.
Impact: Synthetic data allows building more diverse training sets to achieve multi-task DL models. How much faster the DL model can support and whether it can control the quality of output to meet different clinical preferences is worth further investigation.
Purpose
Deep learning (DL) has been clinically used in image quality restoration for accelerated MR scans. The quality of the training image pairs largely determines the DL model performance. However, the paired high quality (HQ) standard-of-care (SOC) and rapidly scanned low quality (LQ) image may encounter structural mis-alignment and inconsistent artifacts, which reduce the number and diversity of qualified training pairs and adversely affect the model performance. This work investigated the feasibility of incorporating synthetic data to address these issues.Methods
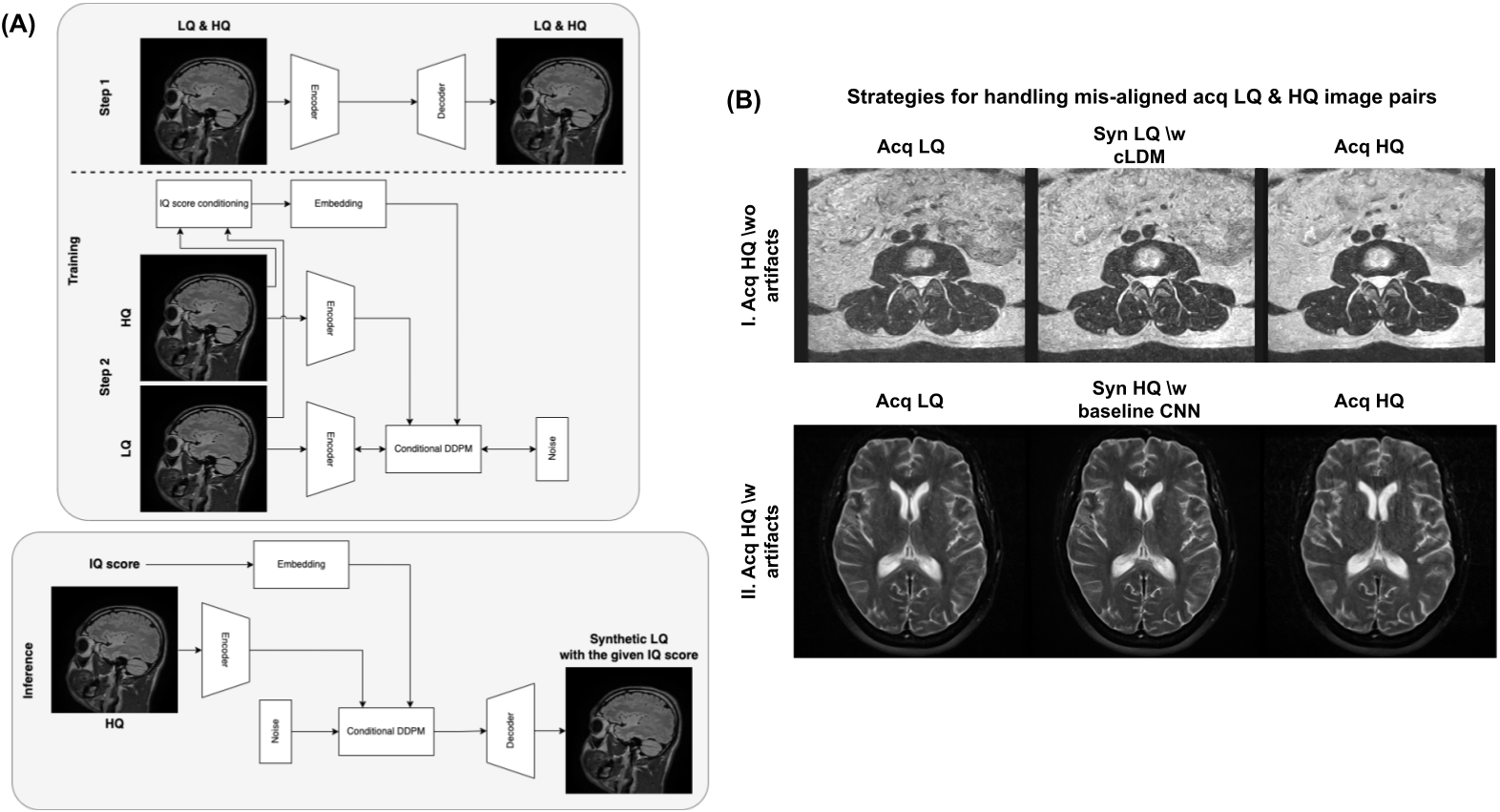
Synthesized LQ and HQ training pairsWith 20,170 acquired low quality (LQ) and high quality (HQ) 2D MR images, two conditional latent diffusion models (cLDMs) [1] were trained to synthesize the noisy/blurry MR images given the acquired HQ image and degradation level (figure 1A). Another two baseline convolutional neural networks (CNNs) [2] were trained to restore the image quality given the noisy/blurry MR image. Both cLDMs and baseline CNNs can produce well-aligned synthetic image pairs, and the synthetic images were used when misalignment occurs between acquired LQ and HQ image pairs (figure 1B). This enables larger-sized and more diverse data pairs for training.
Evaluation of synthetic data for model training
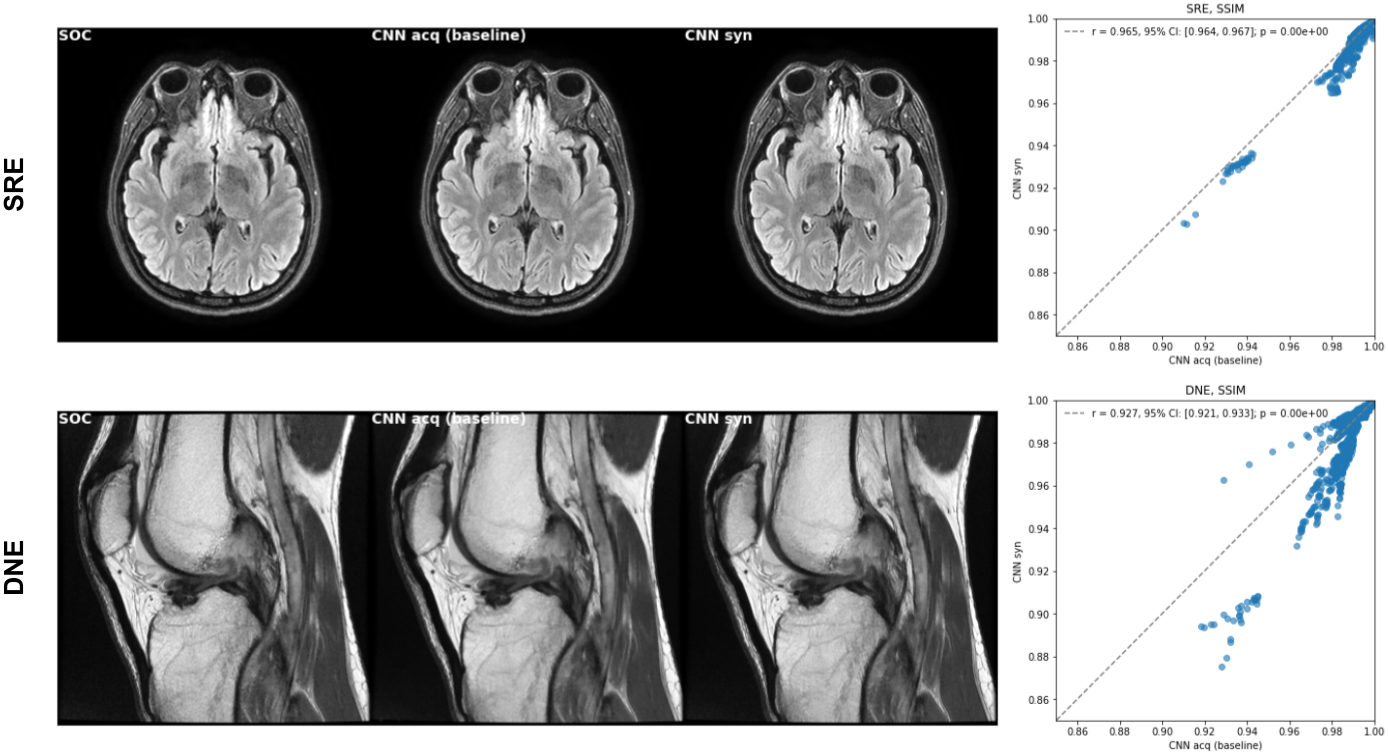
A synthetic training set was built by replacing the LQ image with the cLDMs' outputs. The performance of CNN trained with synthetic data was compared against the baseline CNN. Pearson correlation and Bland-Altman bias analysis were performed on the SSIM measurements.
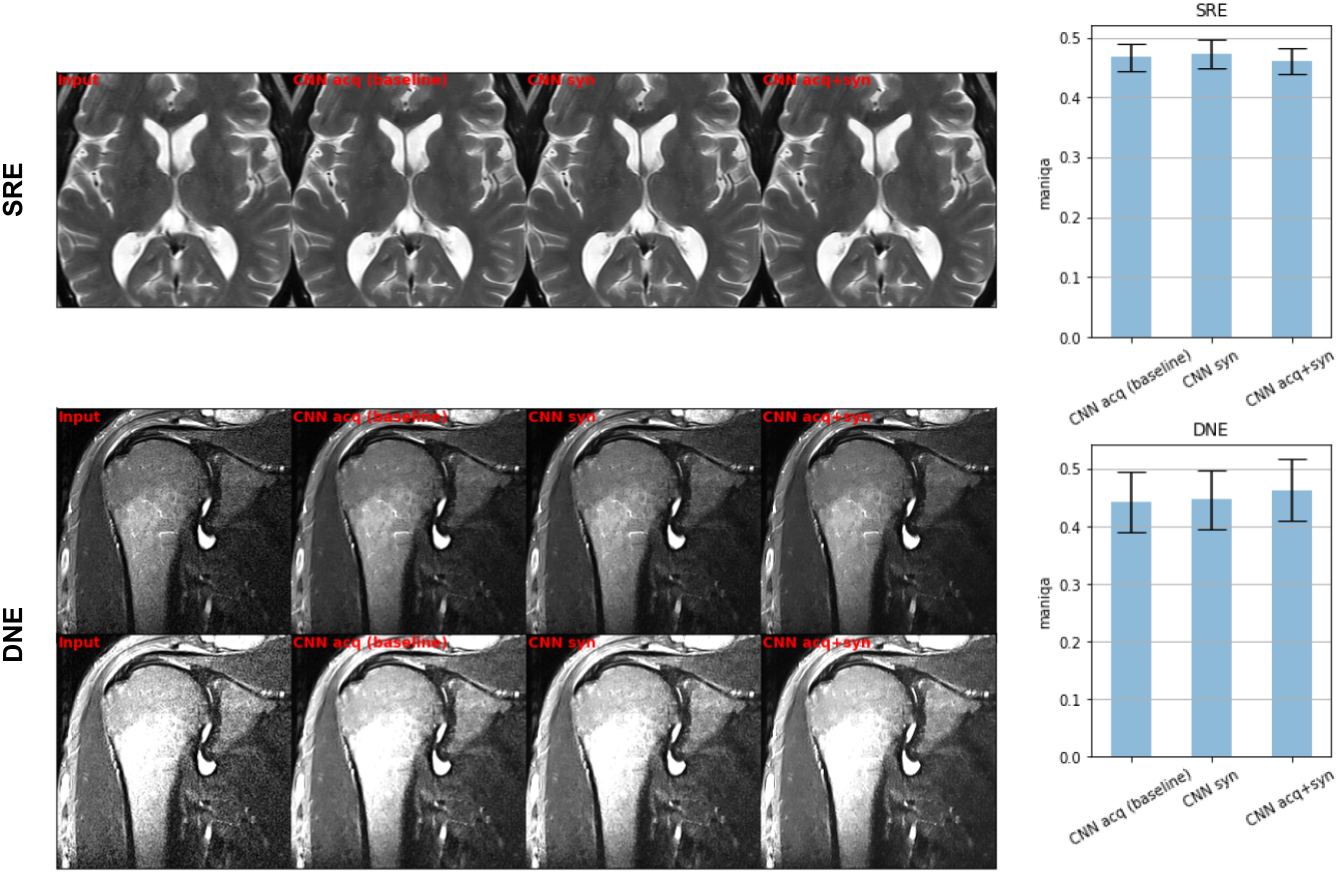
Another larger training set was created by incorporating additional 6,725 synthetic pairs with the pre-trained cLDMs. Also, soft targets were generated with the baseline CNN for knowledge distillation (KD) loss. This CNN trained with combined data pairs was compared against the two baseline CNNs in terms of MANIQA image quality score [3] using T-test.
Results
Compared to baseline CNN, CNN trained on synthetic data achieved consistent model performance in both denoising (DNE) and super-resolution (SRE) tasks with high correlation coefficient and no significant bias in terms of SSIM scores (figure 2 and table 1). Qualitatively, CNN trained with synthetic pairs can better preserve the detail structures in both DNE and SRE tasks.After adding more synthetic training data, significant MANIQA improvement was found in the DNE task (median MANIQA of CNN w/wo additional synthetic data: 0.473285/0.453578, p < 0.01), but not for SRE task. On the other hand, CNN trained with synthetic SRE data alone performed better than the other two CNNs (median MANIQA of CNN with synthetic/acquired data: 0.472702/0.465445, p < 0.01). This result also aligns with the qualitative review.
Discussion and Conclusion
DL models trained with synthetic images can achieve similar performance compared to training with acquired pairs, particularly benefiting small structure enhancement due to better aligned training pairs. Combining acquired and synthetic data can improve the training data diversity that potentially enables a single DL model for both DNE and SRE tasks. Compared to the task specific model, the single model allows more adaptive image enhancement for faster scans with different acceleration approaches.Acknowledgements
We'd like to acknowledge the funding support from NIH SBIR grant (1R44MH135725-01).References
1. Rombach R, Blattmann A, Lorenz D, Esser P, and Ommer B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2022, pp. 10684-10695.
2. Zhou Z, Chamberlain R, Gulaka P, Gong E, Zaharchuk G, Shankaranarayanan A. Adaptive Deep Learning MR Image Enhancement with Property Constrained Unrolled Network. In Proceedings of the ISMRM 2023, p4031.
3. Yang S, Wu T, Shi S, Lao S, Gong Y, Cao M, Wang J and Yang Y. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, pp. 1191-1200.
Figures