2243
MR Contrast-Invariant Deep Learning Method for Synthetic CT Generation1GE HealthCare, Munich, Germany, 2University of Zurich, Zurich, Switzerland, 3Newcastle University and Northern Centre for Cancer Care, Newcastle upon Tyne, United Kingdom, 4Newcastle University, Newcastle upon Tyne, United Kingdom
Synopsis
Keywords: Analysis/Processing, Radiotherapy, synthetic CT, PET/MR, image synthesis
Motivation: Deep learning models are sensitive to image contrast variations. We explore the feasibility of training a single model to process multiple MR contrasts.
Goal(s): To generate synthetic CT images from different MR image contrasts using a image contrast agnostic model.
Approach: A multi-task deep convolutional neural network has been trained using a variety of MR image contrasts.
Results: We demonstrate generation of synthetic CT images from multiple MR images with superior qualitative accuracy and encouraging quantitative accuracy.
Impact: The ability to generate synthetic CT from a variety of MR contrasts brings flexibility of choice of MR sequence in MR guided radiation therapy clinical setup. It improves the model robustness to scan parameter variations leading to a consistent outcome.
Introduction
Generation of synthetic CT (sCT [HU]) from MRI is of interest for applications like MR-only radiation therapy (RT) planning and PET/MR attenuation-correction (AC). Different methods proposed which use various image contrasts [1,2,3,4]. The deep learning models are inherently sensitive to image contrast variations and a model trained on images of one kind of MR contrast performs poorly to image inputs of varied contrast. In this work, we explore the feasibility of generating sCT from a single model trained on multiple MR contrast images including - Zero TE (ZTE), fast spin echo (CUBE), and fast spoiled gradient echo with Dixon-type fat-water separation (LAVA-Flex), using a multi-task deep learning (DL) model. We analyze the qualitative and quantitative accuracy of the generated sCT image from each input and highlight the changes in model behavior according to the input data variations.Methods and Materials
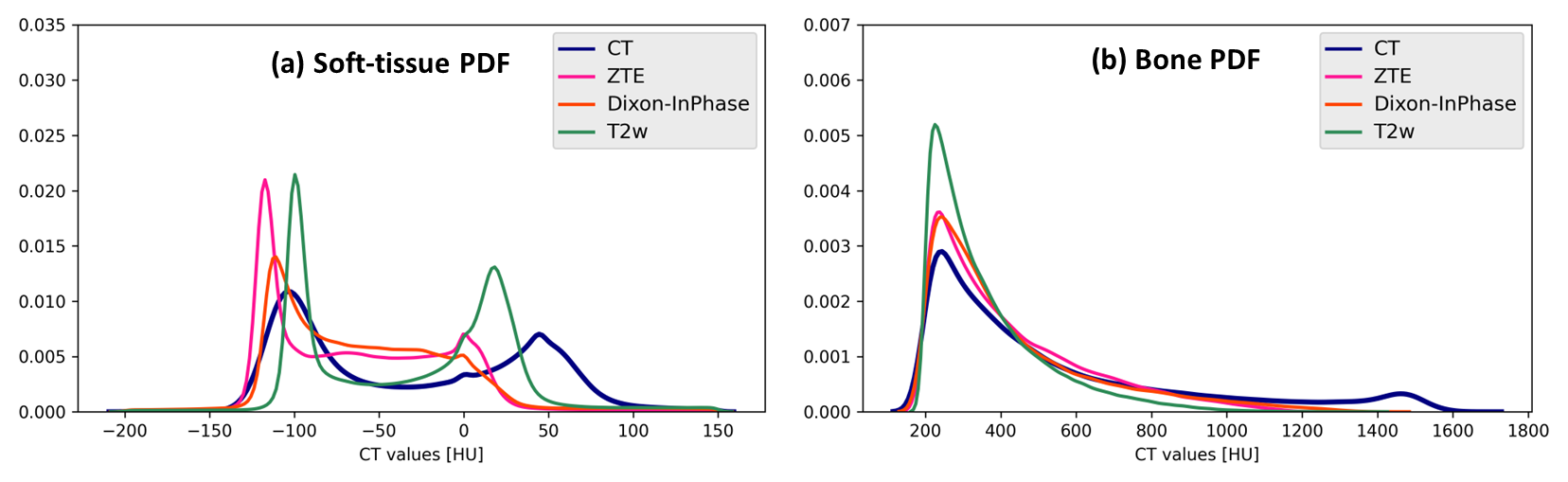
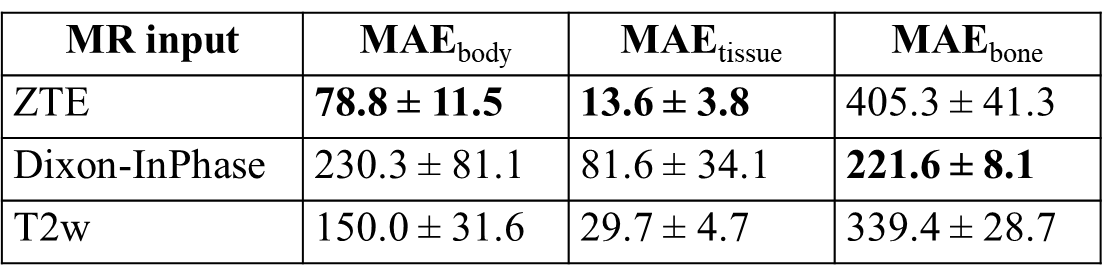
Patient data: MR scans were performed using a 3T, time-of-flight (TOF) Signa PET/MR scanner (GE Healthcare, Chicago, IL, USA). 52 pelvis radiation oncology patients were scanned with three different MR sequences including 3D PDw ZTE, 3D T2w CUBE, and PDw LAVA-Flex (Table-1). For all patients, accompanying CT scans were available from earlier examinations. All patient studies were approved by respective Institutional Review Boards, including signed informed consent. CT to MR registration: Each MR contrast was registered separately to the patient’s CT image using a combination of rigid and diffeomorphic dense registration algorithms developed in ITK [5]. All MR images were co-registered to the CT image for comparison of each sCT in a normalized geometric space. Deep learning based sCT computation: A 2D supervised CNN UNet like architecture adapted to multi-task learning as described in [6] was employed to generate sCT. The DL model was trained with an input cohort consisting of ZTE, T2w, and LAVA-Flex images. Of the available data, 47 cases were divided 80:20 for training and validation cohort. The remaining 5 cases were set apart for performance testing. The data was augmented with random flips, rotations, and arbitrary multiplicative bias to simulate MR inhomogeneity. Training was performed on 52845 slices from a total of 634 image volumes and each epoch was validated on 13397 slices from 160 image volumes. Predicted slices were reconstituted to form the whole sCT volume. sCT evaluation: We computed MAE in different tissue regions between sCT and real CT as a measure of HU value prediction accuracy. Dice similarity coefficient between CT bone region and DL predicted bone region as a measure of bone classification accuracy. The similarity of tissue and bone value probability distribution provides a qualitative impression of the overall HU value accuracy in different regions in a qualitative manner.Results & Discussions
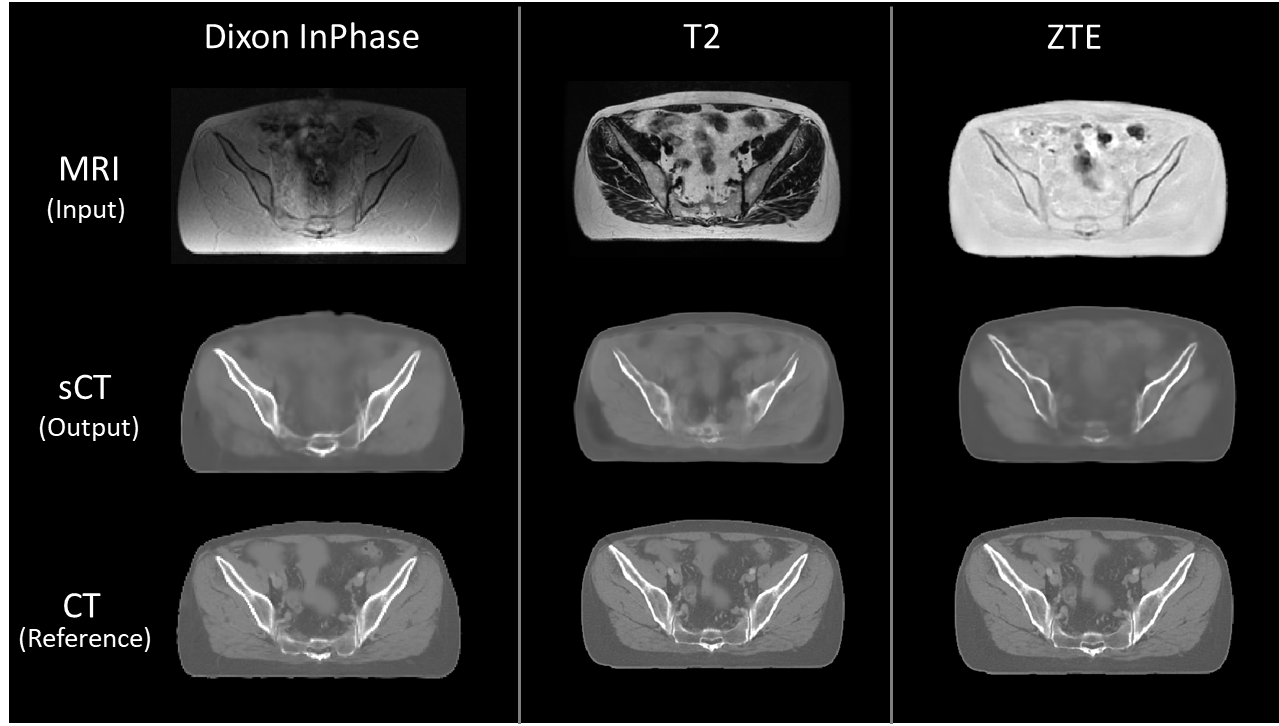
Visual comparison of generated sCT images with corresponding real CT shows varying details of bone depiction in sCT output depending on the input MR contrast (Fig.1). Bone depicted in Dixon-InPhase is better than the other two MR inputs and the soft-tissue details are depicted best with T2 input followed by InPhase and ZTE. Fig.2 shows the comparison of HU value distribution in soft-tissue and bone regions between real CT and sCT from different inputs. The quantitative metrics in Table-2 show the MAE in different regions in the test cases. The qualitative metrics and visual appearance of the generated images indicate the ability of the model to learn depiction of visual details independent of image contrast when trained with data of varying contrasts. However, the quantitative accuracy of the combined model is not as superior as models trained separately on homogeneous cohort of data as show in [7]. This indicates that learning the quantitative aspects needs either a better ability to resolve data complexity or a better conditioning of the data to homogenize varying image characteristics since it impacts the ability of the model to map MR image values to CT HU values.Conclusion
Deep learning models are known to be sensitive to image contrast variations and this work demonstrates the ability of a model to be contrast agnostic. We have presented a method to generate sCT images from a single model trained to process three different MR contrasts. sCT generated from each MR input has comparable visual characteristics to the real CT. This makes an encouraging step towards being able to harness complementary information from different image contrasts to train the model for improved robustness and broader applicability. What currently appears to be a trade-off in performance for learning a broader distribution of data would be an interesting next step to address towards achieving higher quantitative performance on a variety of image contrasts within the same model.Acknowledgements
No acknowledgement found.References
[1]. H.A Massa, et al, Phys. Med. Biol. 2020, Vol.65 23NT03
[2]. MF Spadea, et al, Medical Physics 2021; Vol.48 Issue.11, Pages 6537-6566
[3]. Y Li, et al, BioMed Research International, vol. 2020, Article ID 5193707, 9 pages, 2020
[4]. E Persson, et al, International Journal of Radiation Oncology, Biology, Physics, Volume 99, Issue 3, 692 - 700
[5]. B.B Avants, et al, Penn Image Computing and Science Laboratory, 2009
[6]. S Kaushik, et al, Physics in Medicine and Biology, Aug. 2023
[7]. S Kaushik, et al, ISMRM 2023
Figures