2242
A Unified Approach for Synthesizing Multimodal Brain MR Images via Gated Hybrid Fusion1School of Computing, Korea Advanced Institute of Science and Technology, Daejeon, Korea, Republic of, 2Gordon Center for Medical Imaging, Massachusetts General Hospital and Harvard Medical School, Boston, MA, United States, 3Yale School of Medicine, New Haven, CT, United States
Synopsis
Keywords: Analysis/Processing, Brain
Motivation: It is possible that some MR images may not be acquired during a scanning session. Therefore, it is necessary to generate missing modalities for accurate diagnosis and treatment planning.
Goal(s): Our goal is to synthesize missing modalities from the acquired images while minimizing any loss of information.
Approach: We propose a unified framework that employs a gated hybrid fusion approach to synthesize multimodal brain MR images from the acquired images.
Results: In our experiments, carried out on the BraTS 2018 database containing four MR modalities, we observed improved synthesis quality in all metrics, when synthesizing missing modalities from one or three provided modalities.
Impact: Our unified framework for synthesizing missing modalities is versatile enough to handle all scenarios, irrespective of the modalities provided. It can be applied in clinical decision-making and computer-aided diagnosis, where all modalities are essential for processing.
Introduction
Magnetic resonance (MR) Imaging plays a crucial role in clinical diagnosis and treatment. Multimodal MR images yield more reliable results [1]; however, acquiring multimodal MRI can be challenging due to time constraints or the limited availability of imaging equipment. To address this challenge, various medical image synthesis methods have been developed to generate missing MR images. UCD-GAN [2] introduced a disentanglement framework that can translate all one-to-one modality pairs with a single network, while TransMI [3] demonstrated an effective conditioning method employing a transformer for image translation. ResViT [4] introduced a unified synthesis method that can synthesize N-to-one modality configurations from varying numbers of source images, all utilizing a single network.Nevertheless, the approaches mentioned above still face challenges related to information loss: (1) they may not fully utilize all the available information in the images, or even if they do, (2) the employed structure might result in suboptimal performance. In this work, we aim to reduce information loss by employing a gated hybrid fusion approach. Our framework can process various combinations of MR images as input to generate missing MR images.
Methods
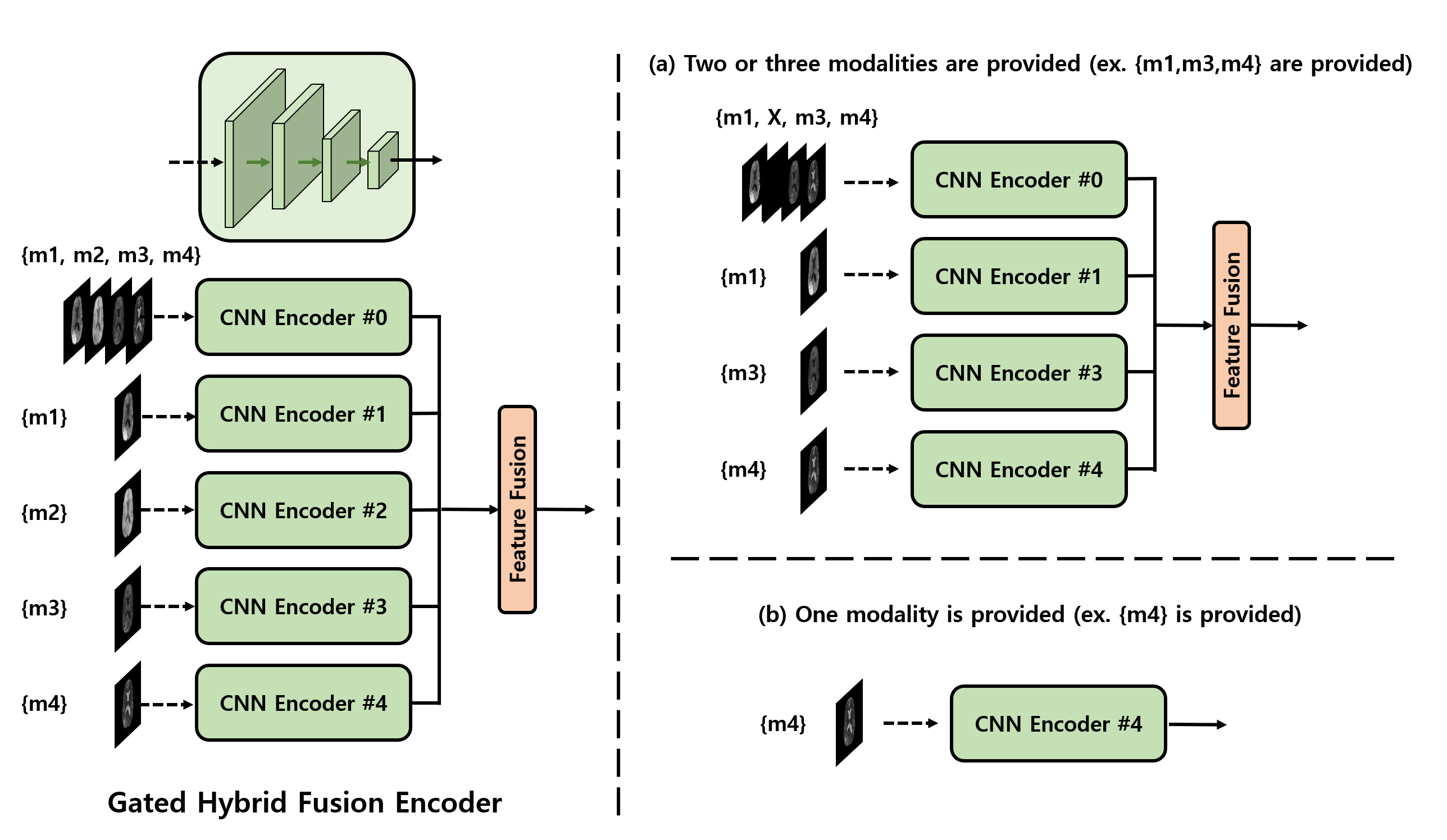
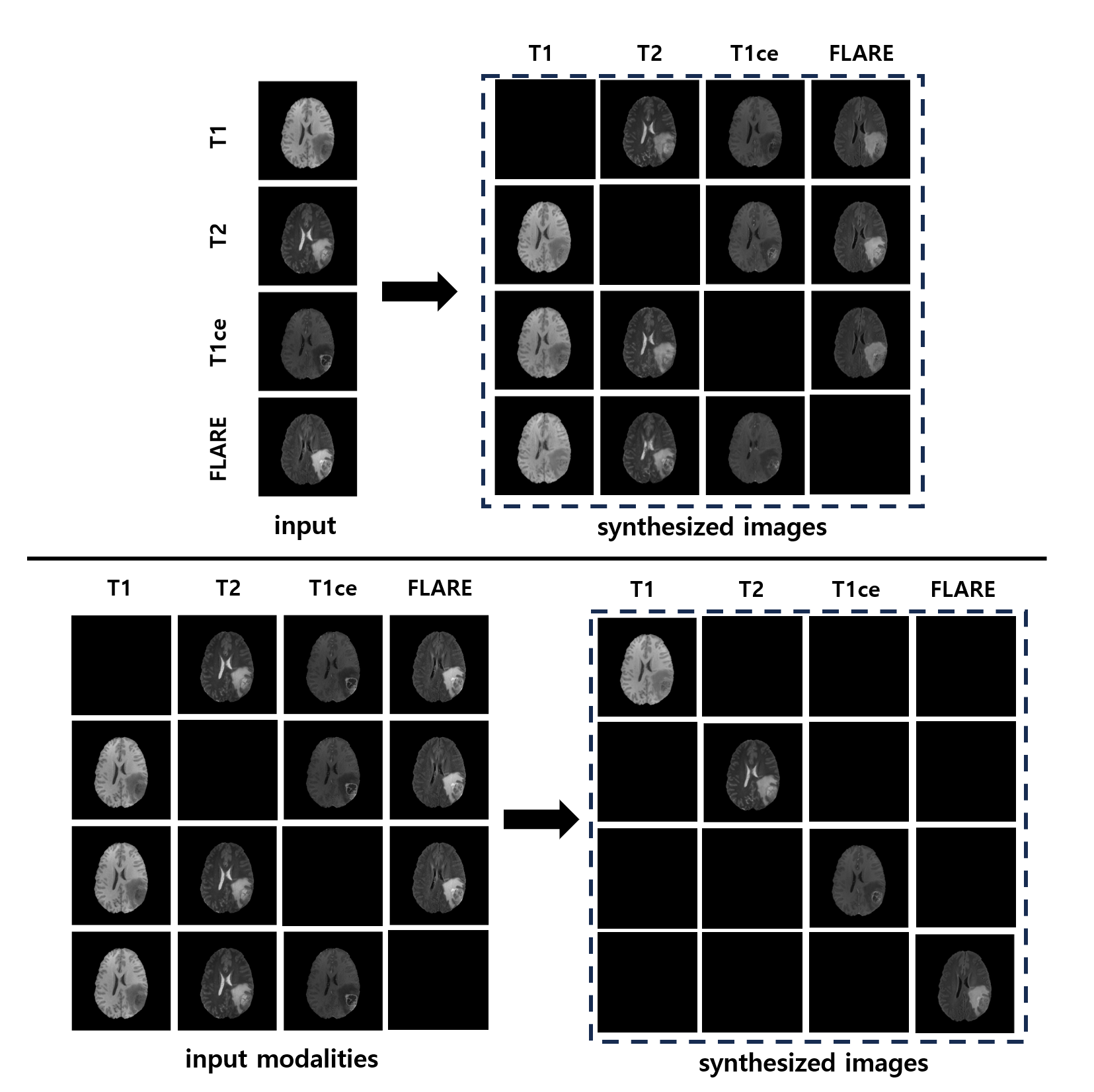
To achieve the synthesis of all modality pairs using a single network, our unified framework is comprised of three key modules, including (1) gated encoders, which minimize the information loss through the hybrid fusion approach [5], (2) a transformer-based modality infuser and a CNN decoder, facilitating the synthesis of the target modality as in [3], and (3) a discriminator for adversarial training, coupled with auxiliary modality classification [6].During the training phase, we randomly select the target and sources from scenarios where the target modality is missing or not provided. Concatenating these modalities as a multi-channel input can be detrimental, especially when there are limitations in the provided modalities [4]. Therefore, we also individually process each modality to extract their respective features. Then, we leverage the full spatial correlations between modalities using our hybrid fusion approach [5]. In cases where only one modality is provided, three-quarters of the concatenated modalities lack any information, potentially leading to the extraction of detrimental features that can adversely impact synthesis quality. Therefore, we exclusively use the features from the given modality during that instance. The architecture and gating scheme of our gated hybrid encoder are illustrated in Fig. 1.
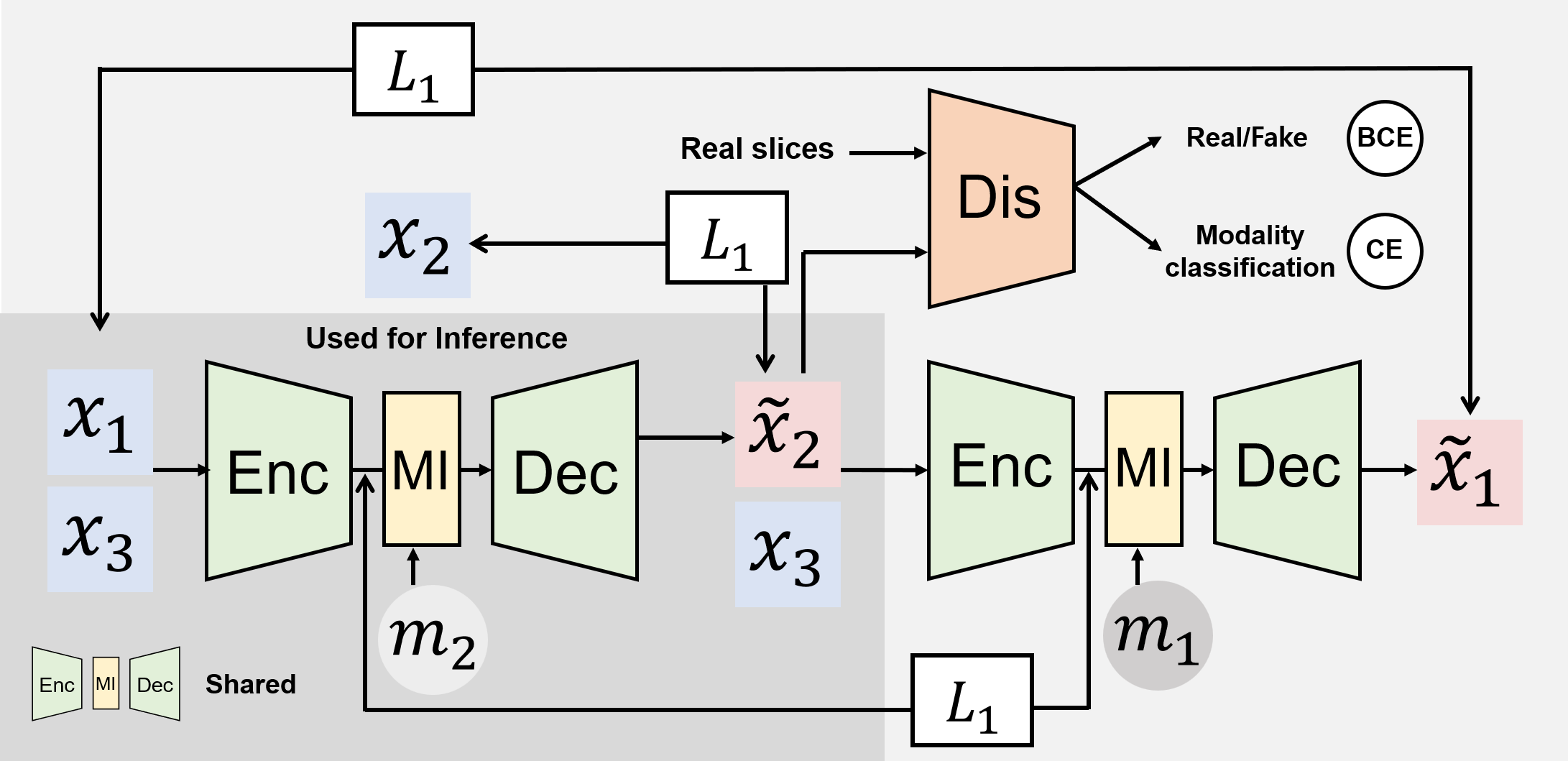
The fused features are transformed into modality-specific features by the modality infuser [3], and modality-conditioned features are used to generate the target modality by the CNN decoder. The generated image is compared with the target ground truth using the L1 loss. For adversarial training, a discriminator tries to distinguish whether generated images are real or not, while also identifying their respective modalities. In addition, we employ synthesized images as input, and one of the source images is generated as the final output to better preserve shape structures [7]. An overview of the proposed training framework is shown in Fig. 2.
Results
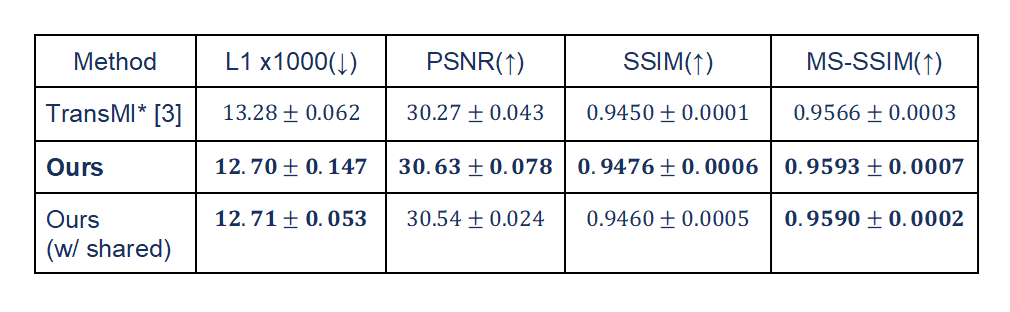
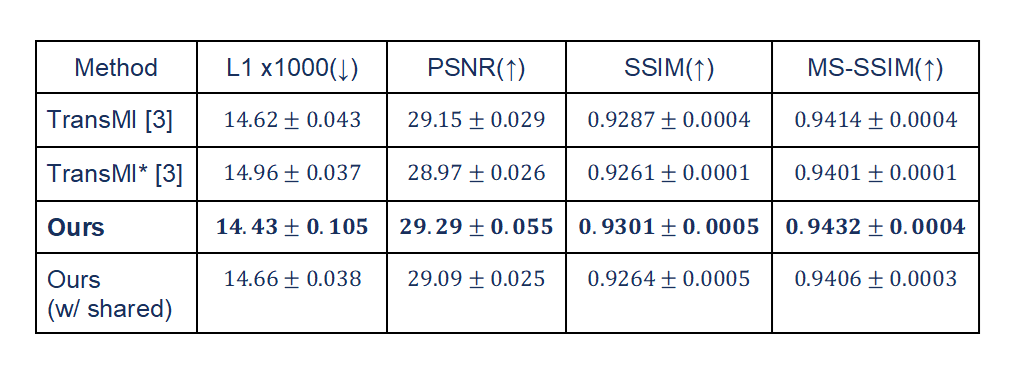
We experimented with the BraTS 2018 dataset, which consists of four MR modalities: T1-, T2-, post-contrast T1-weighted (T1ce), and T2-FLAIR (FLARE) MRI. We follow the experimental configuration used in [3]. Specifically, we used a total of 80 subjects for training, 20 subjects for validation, and 100 subjects for testing. For training and testing, we used 2D axial slices. For the comparison, we extended the previous method [3] to be able to handle all of the modality-missing scenarios using multichannel inputs as in [4]. We evaluated two types of scenarios, (1) 12 cases for providing one modality and (2) four cases for providing three modalities, using four metrics including mean absolute error (L1), peak signal-to-noise ratio (PSNR), structural similarity measure (SSIM), and multi-scale SSIM (MS-SSIM).Our framework consistently outperformed the previous method across all metrics, as in Figs. 3 and 4. Notably, our approach demonstrated superior performance in synthesizing target images when using three input images, demonstrating its ability to capture inter-modality relationships. In cases where only one modality was provided as input, the use of multi-channel inputs initially yielded suboptimal results compared with a one-to-one translation model. However, our proposed approach yielded improved results as shown in Fig. 5, due to its gated structure, which effectively minimizes information loss.
Discussion and Conclusion
This work presented a synthesis framework for generating MR images using varying numbers of modalities. In particular, we developed a gated hybrid fusion structure that facilitates informative feature extraction while minimizing information loss. Promising synthesis results were obtained, demonstrating the potential of our framework to be used for data imputation tasks.Acknowledgements
No acknowledgement found.References
[1] Cho, J. and Park, J., 2023. Multi-modal transformer for brain tumor segmentation. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries (pp. 138-148).
[2] Liu, X., Xing, F., El Fakhri, G., and Woo, J., 2021. A unified conditional disentanglement framework for multimodal brain mr image translation. In 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), (pp. 10-14).
[3] Cho, J., Liu, X., Xing, F., Ouyang, J., El Fakhri, G., Park, J., and Woo, J., 2023. Disentangled Multimodal Brain MR Image Translation via Transformer-based Modality Infuser. To appear in Medical Imaging 2024: Image Processing.
[4] Dalmaz, O., Yurt, M., & Çukur, T., 2022. ResViT: Residual vision transformers for multimodal medical image synthesis. In IEEE Transactions on Medical Imaging, 41(10) (pp. 2598-2614).
[5] Cho, J. and Park, J., (in press). Hybrid-fusion transformer for multisequence mri. In Proceedings of 2022 International Conference on Medical Imaging and Computer-Aided Diagnosis (MICAD 2022).
[6] Odena, A., Olah, C., & Shlens, J., 2017, July. Conditional image synthesis with auxiliary classifier gans. In International conference on machine learning (pp. 2642-2651).
[7] hu, J.-Y., Park, T., Isola, P., and Efros, A. A., 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, (pp.2223–2232)
Figures