2125
Efficient Multi-modality MRI Fusion Based on Superpixel Method for Semi-supervised Brain Tumor Segmentation1State Key Laboratory of Magnetic Resonance and Atomic and Molecular Physics, National Center for Magnetic Resonance in Wuhan, Wuhan Institute of Physics and Mathematics, Innovation Academy for Precision Measurement Science and Technology, Chinese Academy of Sciences, Wuhan National Laboratory for Optoelectronics, Wuhan,China, China
Synopsis
Keywords: Segmentation, Brain
Motivation: The multi-modal images can provide complementary information to improve automatic MRI segmentation performance. However, most multi-modal methods require long training times due to the complex network structures and the large amounts of multi-modal images involved. Furthermore, obtaining numerous labeled data is time-consuming and laborious.
Goal(s): To achieve efficient and high-quality segmentation using only a few labeled data.
Approach: We propose an efficient training-free multi-modal fusion strategy based on superpixel method for semi-supervised brain tumor segmentation.
Results: The experiments on BraTS18 dataset show that our method results in superior overall performance, and can greatly reduce the time costs of doctors.
Impact: The strategy of using superpixel method to accelerate the network training process can assist in the timely diagnosis and treatment of diseases in the clinic, and provides a new idea to simplify multi-modal information fusion.
Purpose
Automated brain tumor segmentation is significant for aiding brain disease diagnosis.1 Currently, magnetic resonance imaging (MRI) is routinely used in the field of brain tumor segmentation due to its non-invasive character and powerful tissue contrast.2 Brain tumors can appear in different locations with arbitrary shapes that are difficult to detect and segment. Therefore, it is hard to achieve accurate segmentation just using single-modal images. In recent years, many multi-modal MRI segmentation methods have been proposed to solve this problem.3 However, they require the large amounts of memory and time to train complex networks for fusing multi-modal features. In this work, we propose an efficient multi-modal fusion method based on superpixel segmentation that can achieve fast fusion without training and eliminate redundancy. Meanwhile, to alleviate the problem of sparse labeled data in clinic, we propose a novel dual-branch semi-supervised network for segmentation. Compared with the single-modal method and the state-of-the-art multi-modal method, our method achieves superior overall performance with less training time.Methods
Network architectureWe propose an efficient multi-modal semi-supervise segmentation framework, which consists of two modules, the fusion module and the segmentation module, as shown in Fig. 1. In the fusion module, the simple linear iterative clustering (SLIC) algorithm is used to segment the corresponding multi-modal images, and a pre-trained VGG19 network is adopted to extract the feature maps. Afterward, these feature maps are compared to generate fusion weights that guide the fusion process. In the segmentation module, two segmentation networks F(·) and G(·) are defined with the same encoder and different decoders, and they output probability PA and PB. The supervised loss can be written as
$${L_{seg}} = Dice\left( {{P_A},Y} \right) + Dice\left( {{P_B},Y} \right) $$
Where Dice represents the Dice loss, and Y is the ground truth, Lseg is only calculated from labeled data. To fully utilize the unlabeled data, a dual-branch registration network is adopted to generate pseudo-labels to supervise the network training crossly. The pseudo-labels can be written as:
$$P{S_A} = {P_B} \circ {\varphi _{BA}},P{S_B} = {P_A} \circ {\varphi _{AB}}$$
Where PSA and PSB are the pseudo-labels of PA and PB. φAB denote the forward deformation field, and φBA denotes the inverse deformation field. P○φ represents P warped by φ. The final prediction of the network F(·) is the result we need. The unsupervised loss can be written as
$${L_{\csc }} = {L_2}\left( {{P_A},P{S_B}} \right) + {L_2}\left( {{P_B},P{S_A}} \right)$$
Where L2 is the MSE loss, Lcsc is calculated from all training data.The total loss can be written as
$$loss = Dice\left( {{P_A},Y} \right) + Dice\left( {{P_B},Y} \right) + \lambda \left( {{L_2}\left( {{P_A},P{S_B}} \right) + {L_2}\left( {{P_B},P{S_A}} \right)} \right)$$
Where λ is a weight to balance Lseg and Lcsc.
Experiments
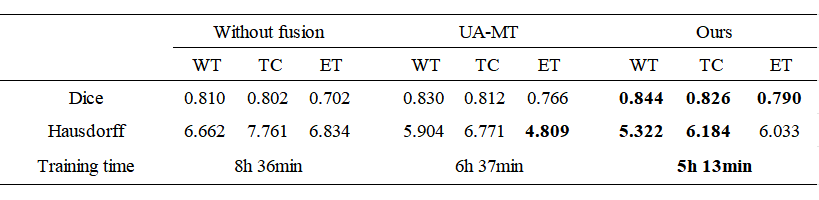
To evaluate the effectiveness of the model, 100 MRI T1 scans, 100 MRI T2 scans and 100 FLAIR scans were collected from the BraTS18 dataset. They were randomly divided into two parts: 80% of the image volumes were used as the training set, and the other 20% were used as the test set. Each volume was normalized to zero mean and unit variance, slices were center-cropped to the size of 160 × 192. The evaluation was performed for the enhancing tumor, the core, and the complete tumor. In this work, the Dice value and Hausdorff distance were used to evaluate the segmentation quality, and training time was recorded to assess the network efficiency.
Results
As shown in Table 1, the proposed method had better Mean Dice compared to the state-of-the-art method, and the increases were about 2.18% (WT: 1.69%, ET: 1.72%, TC: 3.13%). Compared to the methods only segment single-modal images, our method resulted in superior overall performance. As shown in Figure 2, the result of our method was more accurate visually. In addition, the training time of our method was less than that of other methods at only 5 hours and 13 minutes.Conclusions
In this work, we present an efficient multi-modal MRI fusion method for brain tumor segmentation. The superpixel segmentation algorithm is creatively used to accelerate fusion process, and a pre-trained VGG19 network is used to achieve efficient fusion without training. Then a dual-branch network is employed to achieve accurate semi-supervised segmentation by cross pseudo supervision. Experiments on the BraTs18 dataset demonstrate the effectiveness of our method, where it outperforms a state-of-the-art multi-modal segmentation method and a single-modal based semi-supervised segmentation method. Additionally, the fusion strategy significantly reduces the memory consumption and computation time of our method. Therefore, our method is easy to be used in clinical practices and will greatly reduce the burden on doctors.Acknowledgements
This work was supported by National key Research and Development Project of China (2018YFA0704000), National Natural Science Foundation of China (82127802, 21921004, 82001915), Key Research Program of Frontier Sciences (ZDBS-Y-JS004), Hubei Provincial Key Technology Foundation of China (2021ACA013). Xin Zhou acknowledges the support from the Tencent Foundation through the XPLORER PRIZE.References
1.Yang H, Zhou T, Zhou Y, et al. Flexible Fusion Network for Multi-Modal Brain Tumor Segmentation. IEEE Journal of Biomedical and Health Informatics. 2023;29:3349-3359.
2. Hu J, Gu X, et al. Mutual ensemble learning for brain tumor segmentation. Neurocomputing. 2022;504:68-81.
3. Gao H, Miao Q, Ma D, et al. Deep mutual learning for brain tumor segmentation with the fusion network. Neurocomputing. 2023;521:213-220.
Figures

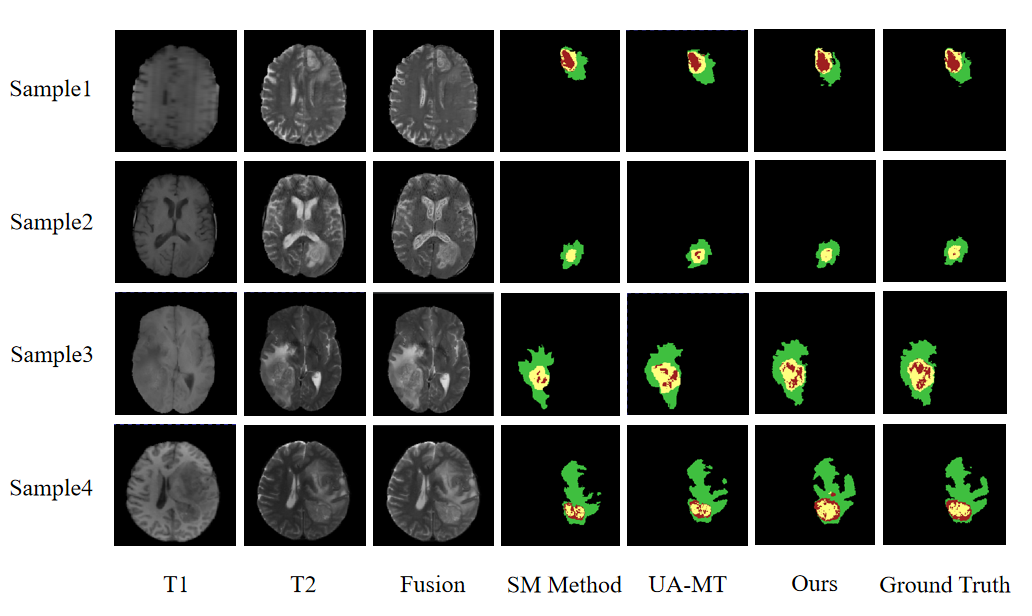
Figure 2. Segmentation results of the proposed network and the compared method. The SM method only uses single-modal images. Green labels represent the area of the peritumoral edema (ED), yellow labels represent the enhancing tumor (ET), and red labels represent the non-enhancing tumor (NET). Our method shows a higher rate of lesion area overlap and fewer false positives than the other method.