2118
Fast Probabilistic Parameter Estimation for Quantitative MRI using Variational Autoencoders1Centre for Medical Image Computing & Department of Computer Science, University College London, London, United Kingdom
Synopsis
Keywords: Analysis/Processing, Quantitative Imaging
Motivation: Mapping MRI signal into tissue parameters aims to identify robust physiologic-phenotypic associations. However, conventional methods are computationally expensive, limiting their applicability in research or clinical practice.
Goal(s): To develop fast and robust techniques for estimating quantitative tissue parameters under a probabilistic framework using MRI signals.
Approach: Train and evaluate the performance of variational autoencoders and compare its capabilities with state-of-the-art deep learning methods on both synthesized and real MRI data.
Results: Compared to existing autoencoder-based methods, both synthetic and real data experiments show enhanced performance of VAEs on tissue parameter estimation. Parameter maps produced from real data show higher similarity to gold-standard maps.
Impact: We show that variational autoencoders can be trained for fast inference of quantitative parameter estimation MRI data quantification in qMRI.
Introduction
Quantitative MRI aims to non-invasively quantify tissue biophysical properties, with the potential to aid early disease detection and identify physiologic-phenotype associations [1]. To estimate tissue parameters from MRI magnitude data, the conventional method performs maximum likelihood estimation (MLE) using non-linear least squares for each voxel, a process that is slow and prone to local minima. Deep learning autoencoder-based approaches have been recently developed to provide a direct non-probabilistic parametric mapping without estimating the posterior.To address this, we propose a variational autoencoder (VAE) model that maps from MRI signals to the summary parameters of the probabilistic latent space. Using the intra-voxel incoherent (IVIM) motion model as an exemplar, results shows that our approach can map directly to the posterior while demonstrating equal or better performance of parameter estimates than the existing autoencoder approaches. The proposed technique provides a framework to avoid local minima through incorporation of prior knowledge in a Bayesian formulation.Methods
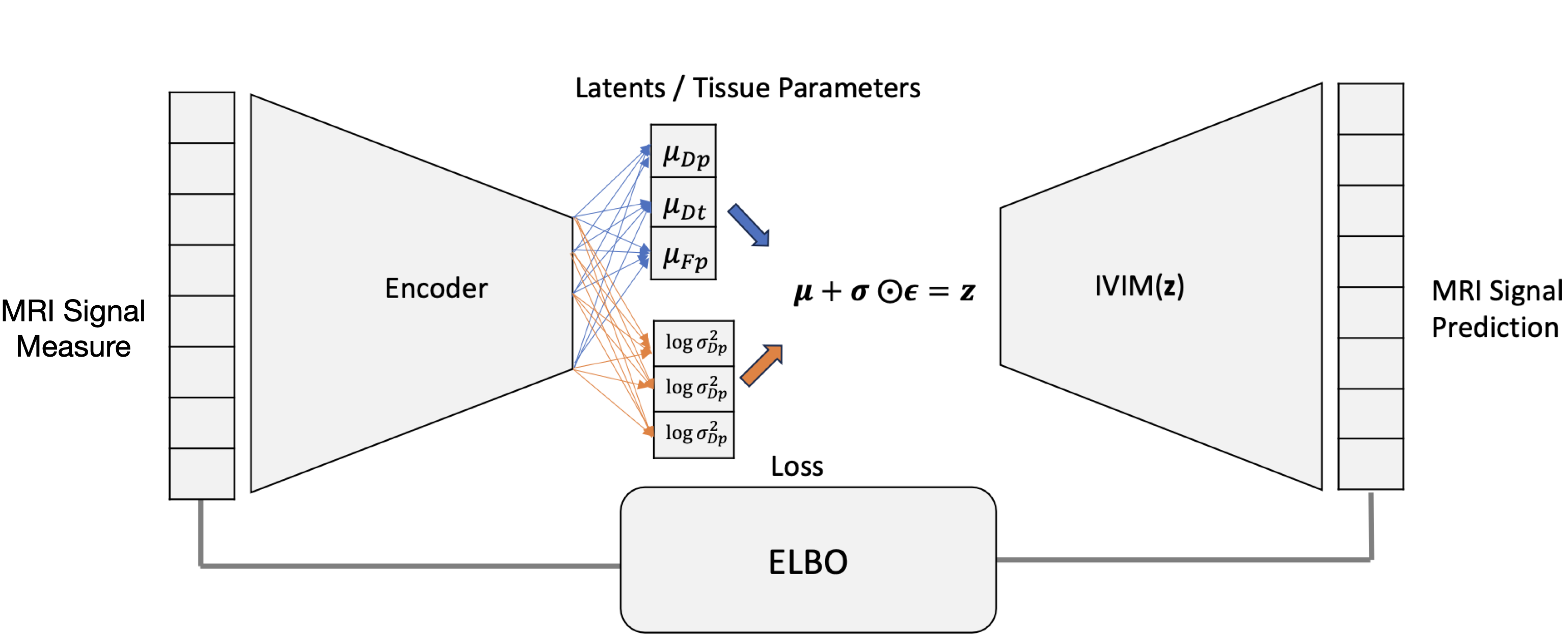
VAE model structure and theoriesWe constructed VAEs to provide a fast and direct mapping from MRI signals to the approximate posterior distribution of their quantitative model parameters. With the objective of the minimisation of the evidence lower bound (ELBO), VAE can be trained to summarise the information of posterior location of the tissue parameters. The locations of estimated tissue parameters: $$$\boldsymbol{\mu_z}=(\mu_{Dp},\mu_{Dt}, \mu_{Fp})$$$ and their posterior noise level $$$\boldsymbol{\sigma_z}=(\sigma_{Dp},\sigma_{Dt}, \sigma_{Fp})$$$ are mapped to the latent space. $$$\mathbf{z}=(D_p, D_t, F_p) $$$ is then sampled using the reparameterisation trick. The decoder reconstructs MRI signals from this latent space via the IVIM model.
VAE model structure and theories
The VAE encoder was built upon previous autoencoders [2,3]. $$$\boldsymbol{\mu_z}$$$ and $$$\log\boldsymbol{\sigma_z^2}$$$ share a single encoder but branch at an additional final linear layer. The processing of the data illustrated in figure 1, is described by:
$$\text{Encoder: } \boldsymbol{\mu_z} = f_{\boldsymbol{\phi_\text{enc}}}(\mathbf{x}; \boldsymbol{\phi_{\text{enc}}}) \quad\boldsymbol{\sigma_z} = f_{\boldsymbol{\phi_\text{enc}}}(\mathbf{x}; \boldsymbol{\phi_{\text{enc}}})$$
$$\text{Reparameterisation step: } \boldsymbol{z} = \boldsymbol{\mu_z + \sigma_z\odot \epsilon}$$
$$\text{Decoder: } \mathbf{\hat{x}} = IVIM(\mathbf{z}; \mathbf{b})$$
The VAE uses evidence lower bound(ELBO) as the loss function, with negative loRician likelihood as reconstruction loss and the $$$D_{KL}$$$ term formulated with a Standardised Gaussian prior modified with a term that add a large constant penalising the model once it tends to estimate the parameters outside the prior range. The optimisation objective function is defined as:
$$\underset{\phi}{\operatorname{arg\,min}} \quad L(\phi_{\text{encoder}}) = \text{- log Rician Likelihood Loss} + D_{KL}$$
VAE training and evaluation
The VAE was firstly trained using synthetic IVIM data for 200,000 voxels, with a uniform distribution of ground truth parameters $$$D_p \sim U[0.01 ,0.1 ]$$$ $$${mm^2/s}$$$, $$$D_t \sim U[0.0005 , 0.002]$$$ $$${mm^2/s}$$$, and $$$F_p \sim U[0.1, 0.4]$$$ $$${mm^2/s}$$$, and 8 b-values: 0, 10, 20, 60, 150, 300, 500, 1000 $$$ms/\mu m^2$$$ [2]. Rician noise was added with $$$\sigma = 0.02$$$. For comparison, state-of-the-art autoencoders were also trained with Rician log-likelihood loss [2] or mean squared error loss [3]. Estimated parameters was validated on 1,000 unseen synthetic test voxels in terms of RMSE to the ground truth parameters.
Performance was also evaluated on real-world data acquired at 3T from the pelvis of an adult male [4]. Gold standard parameter values were obtained from conventional fitting to the super-sampled dataset and one of 16 repetitions were used for testing.
Results and Discussion
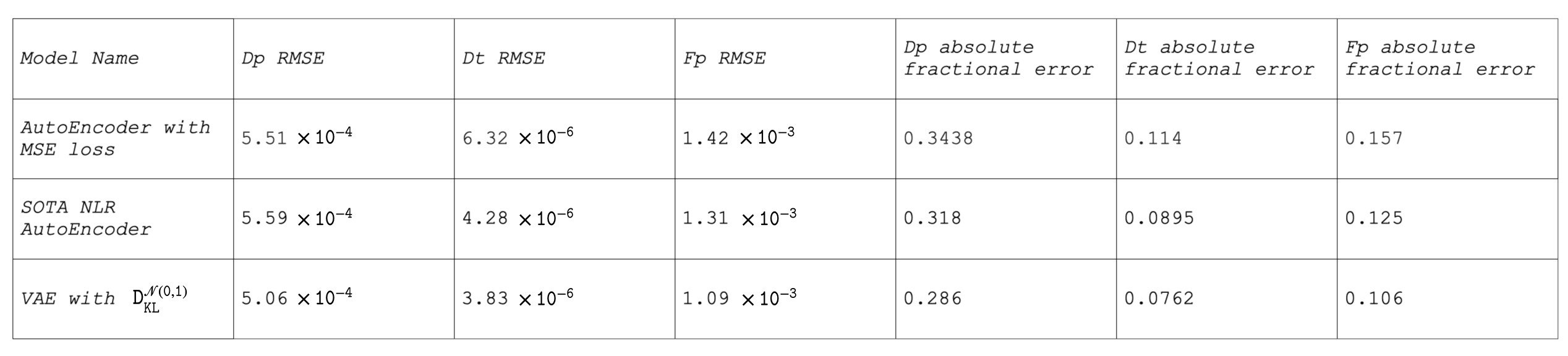
Synthetic DataPerformance of the VAE for parameter estimation is compared against existing state-of-the-art autoencoder techniques and summarised in table 2. The root-mean squared error (RMSE) suggests that VAE more accurately predicts parameters compared to the non-probabilistic autoencoder models.
Real data
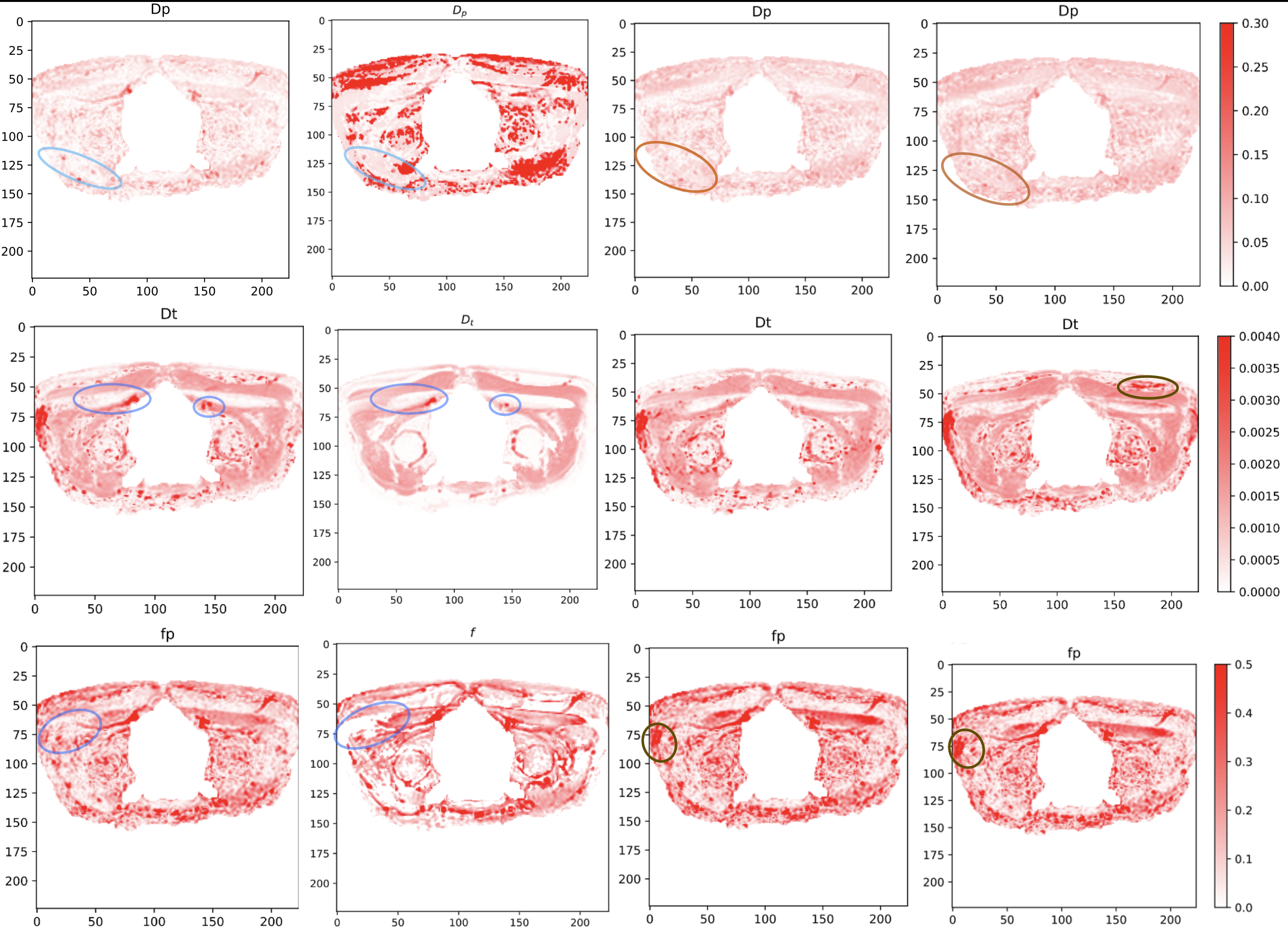
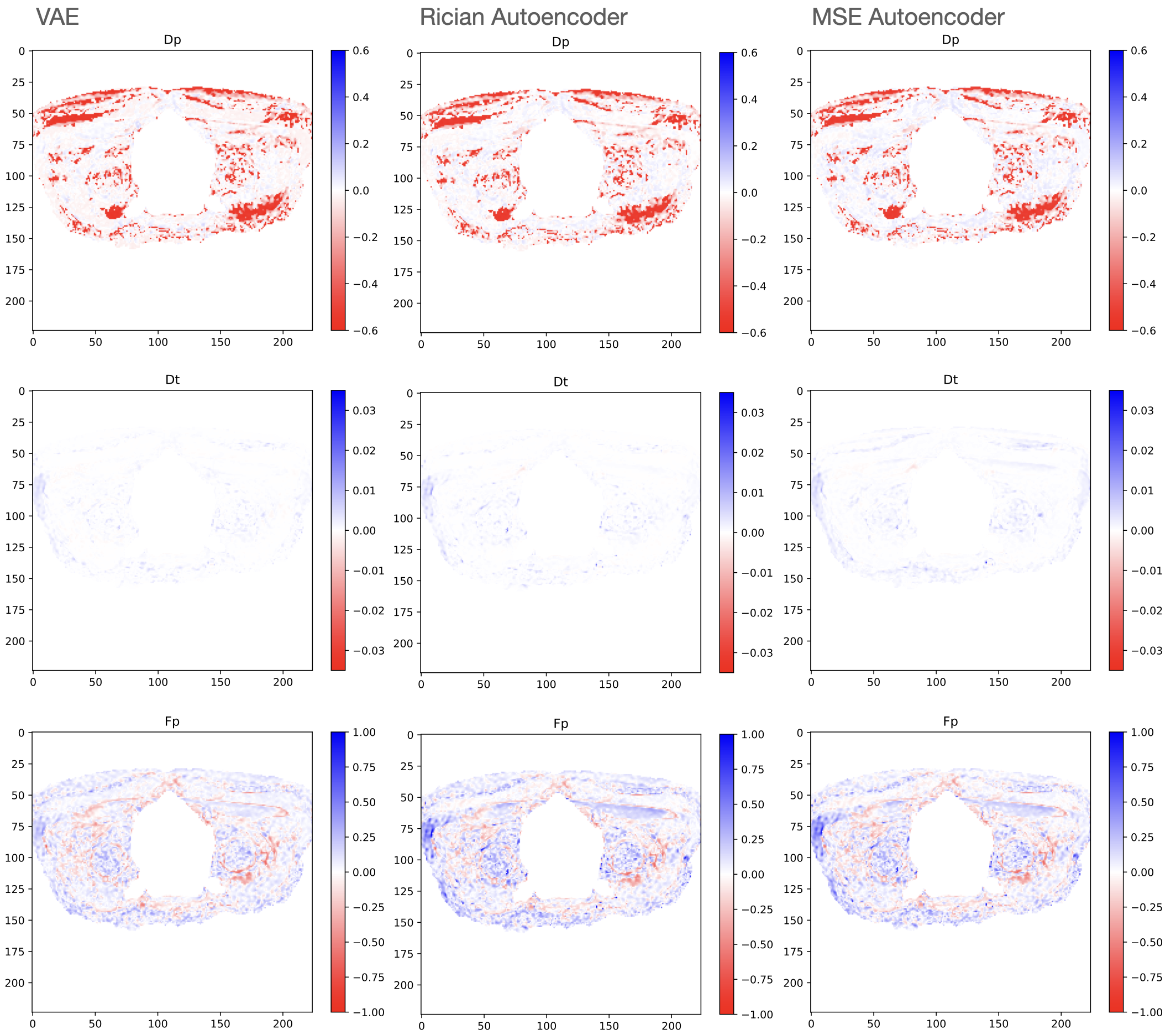
Figure 3 shows the qMRI map produced by VAE, the gold standard and autoencoder methods for each IVIM parameter. It can be seen from the circled areas that there are certain distinct similarities with gold standard can only be detected by VAE, while some dissimilarities are quite common for the autoencoder methods. VAE shows the same accuracy than the existing autoencoders on estimating Dp and lower errors on Dt and Fp. The RMSE across all voxels on real data for dp, dt, and Fp is (0.20, 0.00079, 0.12) for VAE, (0.20, 0.00096, 0.14) for autoencoder with Rician loss and (0.19, 0.00120, 0.14) for autoencoder with MSE loss. Figure 4 shows difference maps of the models by subtracting the ground truth from the predicted values. The VAE map is clearly lighter than other models on average, meaning that the location of the posterior distribution produced by VAE is very close to the gold standard, compared to other methods’ approximation.
Acknowledgements
CSP and HZ are supported by the Medical ResearchCouncil (MR/T046473/1)References
[1] Seiberlich, N., Gulani, V., Campbell-Washburn, A., Sourbron, S., Doneva, M.I., Calamante, F. and Hu, H.H. eds., 2020. Quantitative magnetic resonance imaging. Academic Press.
[2] C. S. Parker, A. Schroder, S. C. Epstein, J. Cole, D. C. Alexander, and H. Zhang. Rician likelihood loss for quantitative mri using self-supervised deep learning. arXiv preprint, 2023. doi: 10.48550/arXiv.2307.07072.
[3] S. Barbieri, O. J. Gurney-Champion, R. Klaassen, and H. C. Thoeny. Deep learning how to fit an intravoxel incoherent motion model to diffusion-weighted mri. Magnetic Resonance in Medicine, 2019. doi: 10.1002/mrm.27910.
[4] Epstein, S.C., Bray, T.J., Hall-Craggs, M. and Zhang, H., 2022. Choice of training label matters: how to best use deep learning for quantitative MRI parameter estimation. arXiv preprint arXiv:2205.05587.
Figures