2116
An automated end-to-end deep learning reconstruction and quantification workflow for fast quantitative DCE-MRI1Weill Cornell Graduate School of Medical Sciences, New York, NY, United States, 2Department of Medical Physics, Memorial Sloan Kettering Cancer Center, New York, NY, United States, 3Department of Radiology, Memorial Sloan Kettering Cancer Center, New York, NY, United States
Synopsis
Keywords: Analysis/Processing, Perfusion, Machine Learning/Artificial Intelligence, Cancer
Motivation: Despite extensive research and promising initial results, quantitative dynamic contrast-enhanced (DCE) MRI is marginal in clinical practice, due to lack of automation and low reproducibility.
Goal(s): Introduce an end-to-end deep learning approach for an automated and more reproducible DCE-MRI pipeline.
Approach: Two networks, one reconstructing undersampled k-t data via Movienet and the other estimating perfusion and MR parameters, were merged into a unified, automated pipeline. The approach was tested on a volunteer and a patient with cervical cancer.
Results: Automated processing yielded images in under 2 seconds, comparable in quality to GRASP and providing multiparametric mapping of perfusion and MR from one acquisition.
Impact: The proposed fast automated data processing pipeline including deep learning reconstruction and quantification can be an important clinical tool to exploit the information from DCE-MRI to improve tumor diagnosis and treatment response evaluation.
Introduction
Dynamic contrast-enhanced (DCE) MRI is an important tool to evaluate tumor vascularity, including computation of parametric perfusion maps that can be used as quantitative biomarkers for cancer. However, despite extensive research work and promising results, present DCE-MRI techniques is marginal in routine clinical practice, due to a combination of limited acquisition and quantification performance1. The combination of golden-angle radial sampling and compressed sensing (such as GRASP2) enabled DCE-MRI with high spatial and temporal resolution for improved accuracy, but iterative reconstruction is slow2. Moreover, in addition to the pharmacokinetic model, there are many factors affecting quantification of DCE-MRI data including T1, B1, arterial input function (AIF), bolus arrival time (BAT) that reduce reproducibility. The use of deep learning techniques has separately accomplished improved reconstruction (for example GRASPnet3 and Movienet4 for motion-resolved imaging), and quantification (for example DCENet5 which can estimate perfusion parameters along with other variables affecting quantification). This work proposes to integrate deep learning reconstruction and quantification into a single and automated framework for DCE-MRI to enable high spatial and temporal resolution, fast reconstruction, and comprehensive quantification for robust implementation on a clinical setting.Methods
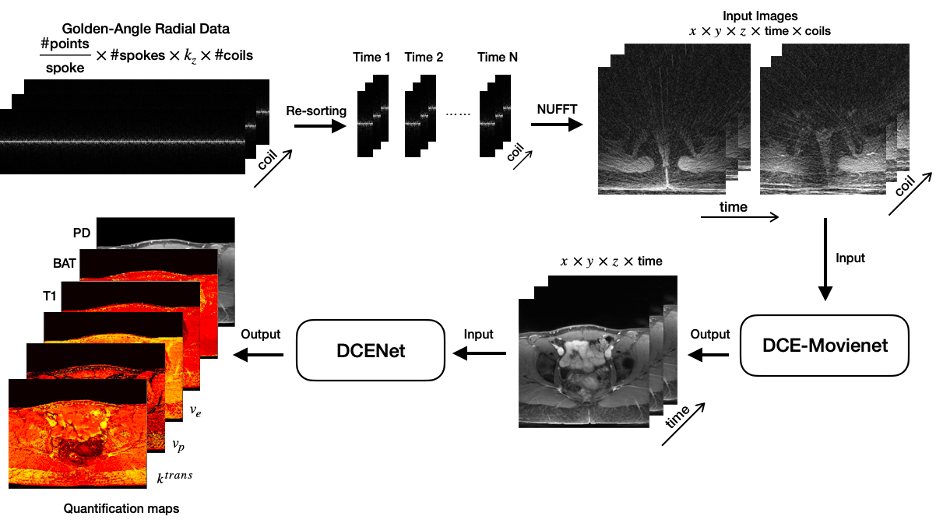
End-to-end deep learning DCE-MRI: The proposed workflow uses two separate networks: a modified version of Movienet (DCE-Movienet) to reconstruct undersampled k-t data and DCENet to compute quantitative perfusion maps and other variables from the output of DCE-Movienet (Fig. 1).Data acquisition: DCE-MRI data were acquired on 10 healthy volunteers and a patient with cervical cancer using a golden-angle stack-of-stars sequence on a 3T Signa Premier (GE Healthcare) with the following acquisition parameters: TR/TE = 3.396/1.572 msec, spatial resolution = 1.5x1.5x4mm3 in-plane matrix size = 256x256, number of slices = 52-58, number of spokes = 1976-2492. A patient with cervical cancer was scanned twice 24 hours apart. k-space data were retrospectively sorted with a temporal resolution of 5 seconds, resulting in 60 temporal frames.
DCE-Movienet architecture and training: Similar encoder-decoder architecture with residual blocks as the original Movienet was employed, but the 8 coils and 60 time points were concatenated to efficiently exploit spatial-time-coil correlations. DCE-Movienet was trained on the first 9 volunteer datasets using iterative GRASP results as a reference. The two patient scans and the last volunteer scan were used as testing cases.
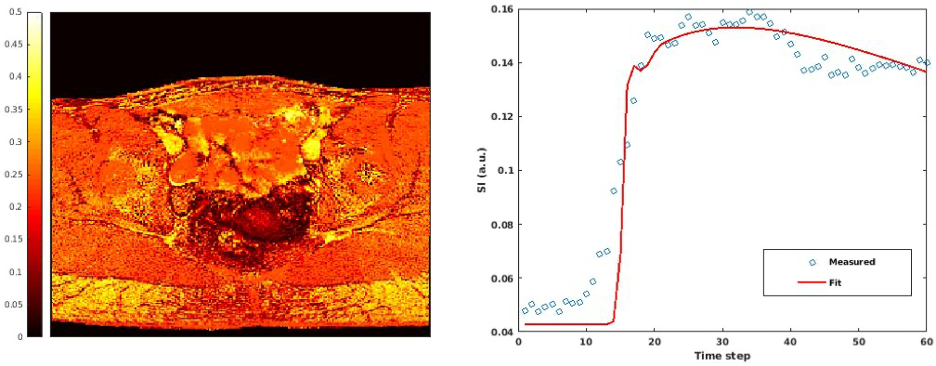
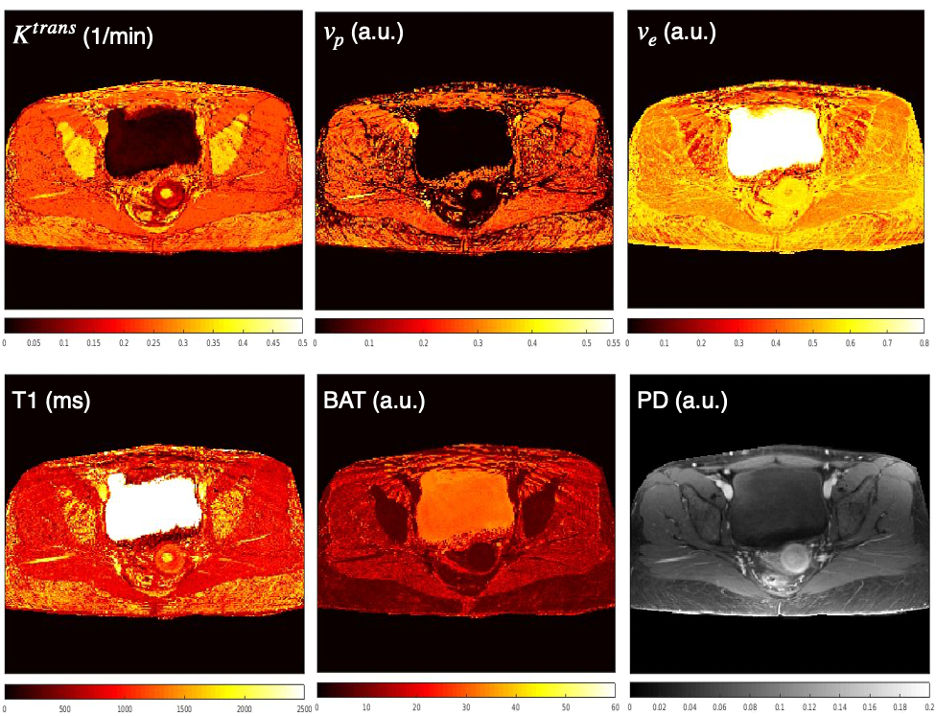
DCENet architecture and training: A 7-layer network was defined and trained on simulated DCE-MRI signals derived from the parameters of the Extended Tofts model, gradient-echo MR signal and population-based AIF. DCENet simulatenously computed the perfusion parameters (Ktrans, vp, ve), T1 relaxation, proton density and BAT.
Evaluation: Reconstruction and quantification performance were evaluated against GRASP results. Reproducibility was evaluated between the two patient scans separated by 24 hours.
Results
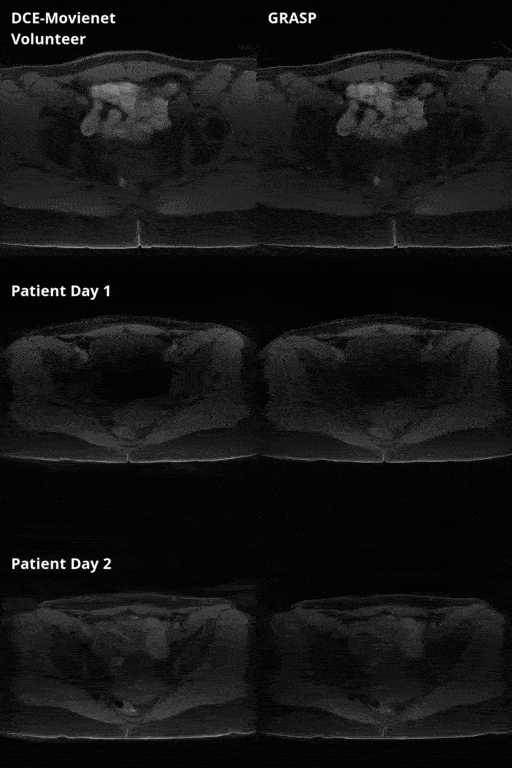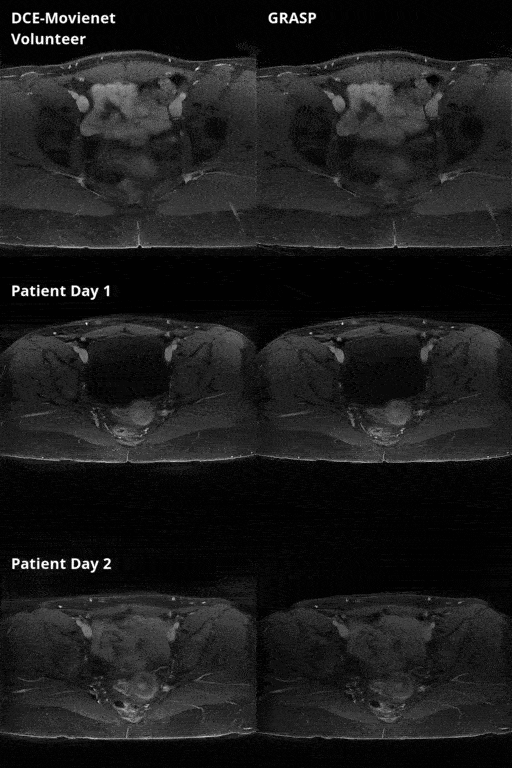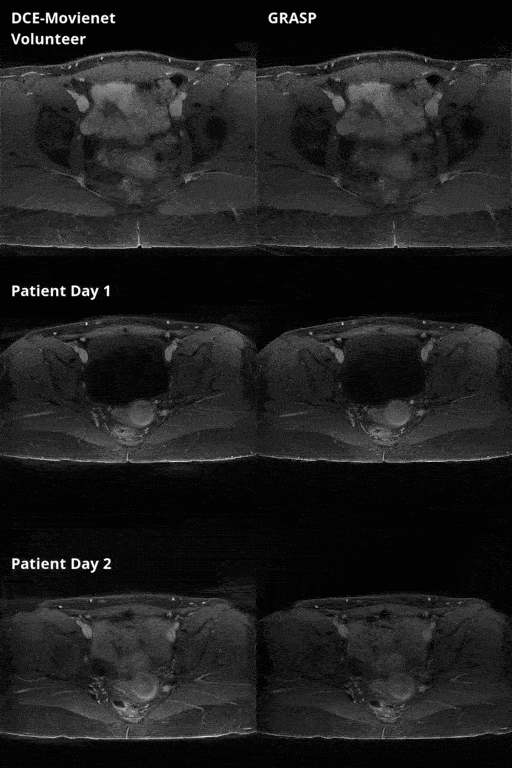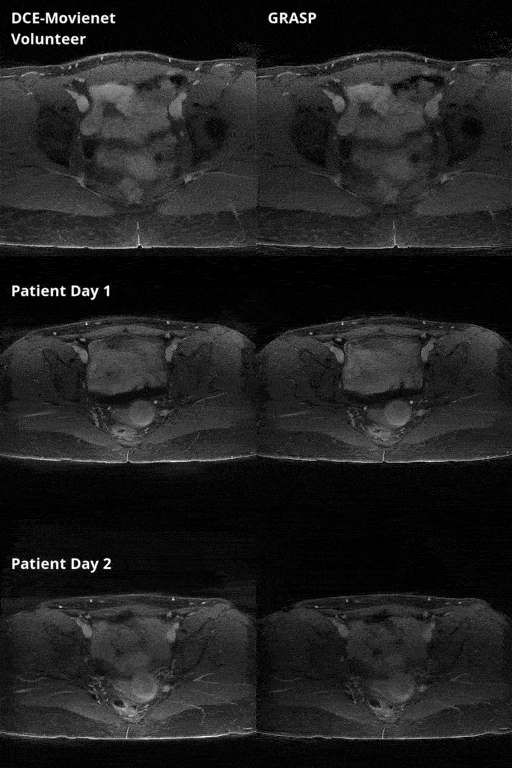
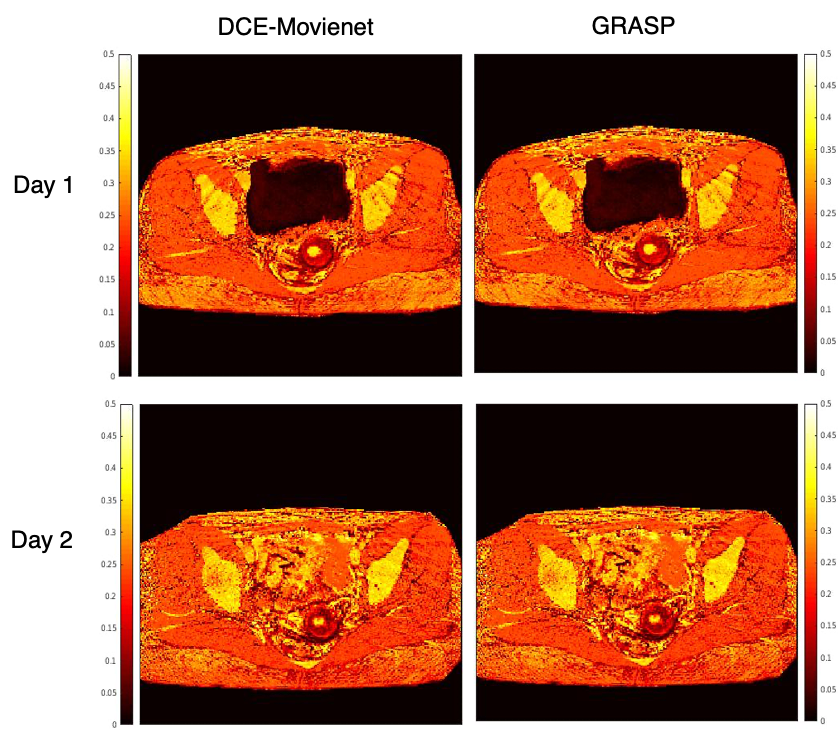
DCE-Movienet reconstruction time was about 0.66 seconds and DCENet quantification was about 1 second, resulting in 1.66 seconds for the complete reconstruction and quantification process. Reconstruction of 0.66 seconds is a significant improvement compared to GRASP reconstructions, which may require on the order of 10 minutes6. DCE-Movienet presented similar reconstruction quality (Fig. 2) and quantification performance (Fig. 4) compared to GRASP despite the significant reduction in reconstruction time. The fitted signal from DCENet was very close to the output from DCE-Movienet (Fig. 3). Ktrans in the tumor region was reproducible between the scans performed on the patient with mean difference lower than 1%. The end-of-end deep learning approach enabled automatic mapping of perfusion parameters and MR parameters such as T1 and PD from a single acquisition (Fig. 5).Discussion
The proposed workflow offers an automated and fast solution for DCE MRI reconstruction and quantification for robust implementation in a clinical setting. Initial reproducibility analysis using two datasets separated by 24 hours shows high concordance between parametric maps. Future work will study reproducibility in a large cohort of patients. The combination of two networks that were separately trained on images and simulated data from mathematical models illustrates initial feasibility of an end-to-end deep learning processing. Future work will attempt to unify the training. Training in a self-supervised fashion can also potentially improve reconstruction results as the network may find a solution space that surpasses GRASP quality.Conclusion
This work presented initial feasibility of an end-to-end deep learning solution for efficient reconstruction and quantification of DCE-MRI data with a total processing time of less than 2 second and similar performance to state-of-the-art compressed sensing reconstruction. The end-to-end deep learning workflow can enable automated and potentially reproducible DCE-MRI in a clinical setting.Acknowledgements
This work was supported by NIH grant R01-244532.References
1. Kim H. Variability in Quantitative DCE-MRI: Sources and Solutions. J Nat Sci. 2018;4(1):e484. PMID: 29527572; PMCID: PMC5841165.
2. Feng L, Grimm R, Block KT, et al. Golden-angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI. Magn Reson Med. 2014;72(3):707-717. doi:10.1002/mrm.24980
3. Jafari R, Do RKG, LaGratta MD, et al. GRASPNET: Fast spatiotemporal deep learning reconstruction of golden-angle radial data for free-breathing dynamic contrast-enhanced magnetic resonance imaging. NMR Biomed. 2023;36(3):e4861. doi:10.1002/nbm.4861
4. Murray V, Siddiq S, Crane C, et al. Movienet: Deep space-time-coil reconstruction network without k-space data consistency for fast motion-resolved 4D MRI [published online ahead of print, 2023 Oct 17]. Magn Reson Med. 2023;10.1002/mrm.29892. doi:10.1002/mrm.29892
5. Cohen, Ouri et al. DCENet: Deep Network Quantification of Dynamic Contrast Enhanced (DCE) MRI. [Manuscript submitted for publication]
6. Feng L, Wen Q, Huang C, Tong A, Liu F, Chandarana H. GRASP-Pro: imProving GRASP DCE-MRI through self-calibrating subspace-modeling and contrast phase automation. Magn Reson Med. 2020;83(1):94-108. doi:10.1002/mrm.27903
Figures