2105
Deep Learning Based Automated Brain Segmentation from Computed Tomography Scans1School of Electronic and Electrical Engineering, Kyungpook National University, Daegu, Korea, Republic of, 2Department of Radiology, Yonsei University College of Medicine, Seoul, Korea, Republic of
Synopsis
Keywords: Analysis/Processing, Segmentation
Motivation: While computed tomography (CT) imaging has been actively employed in clinical practice, its limited contrast for brain tissues makes it challenging to achieve precise brain segmentation.
Goal(s): In this study, we developed a deep learning (DL)-based method enabling brain tissue segmentation from CT image.
Approach: MRI-derived tissue labels were provided as ground truth to a DL network, where U-Net and VGG16 interact to each other for model optimization by means of a perceptual loss.
Results: Results demonstrate the effectiveness of incorporating the perceptual loss to the model in preserving image details, and in terms of evaluation scores.
Impact: The presented method, upon further validation and optimization, is expected to be a valuable means to a range of brain imaging studies where MRI is somehow not available.
Introduction
Accurate and robust brain segmentation plays a pivotal role in various neuroimaging applications, e.g., analysis of brain atrophy in Alzheimer’s disease1. While CT imaging has been actively employed in clinical practice, its limited contrast for brain tissues makes it extremely challenging to achieve precise brain segmentation. In recent years with the advances of deep learning (DL) technology, methods enabling transformation of CT images to MRI have emerged2,3, suggesting a feasibility of CT-based brain tissue segmentation. In this study, we propose a method integrating a perceptual loss into a DL network to enhance the performance of brain segmentation from CT images.Methods
Datasets: We selected 150 pairs of CT and T1-weighted MRI datasets obtained in patients visiting Gangnam Severance Hospital, Seoul, Korea, but without brain diseases. The volumetric image datasets were divided into 100 and 50 pairs for training (11,658 slices) and test (4,214 slices) of the DL network model, respectively.Data preprocessing: Following the image format conversion to NIfTI, each of volumetric CT images was co-registered to corresponding MRI, and was resliced to the resolution of the latter (voxel-size: 1mm isotropic) using SPM. Both images were then normalized to the intensity range [0,1]. T1-weighted MR images were further processed in SPM, yielding segmentation maps of gray matter (GM), white matter (WM), and cerebrospinal-fluid (CSF), respectively, serving as ground-truth binary masks in the DL network training step.
DL network training: The standard U-net4 architecture was employed as a backbone DL network model. Here, sectional CT images are provided as input, and the network is trained to corresponding target slices of ground-truth masks. The network training was performed individually for each of the three tissues (GM, WM, CSF). The loss function of the DL network model consists of three components as:
$$ loss(y, \hat{y}) = L_{L1}(y, \hat{y}) + L_{L2}(y, \hat{y}) + L_{p}(y, \hat{y}) (1) $$
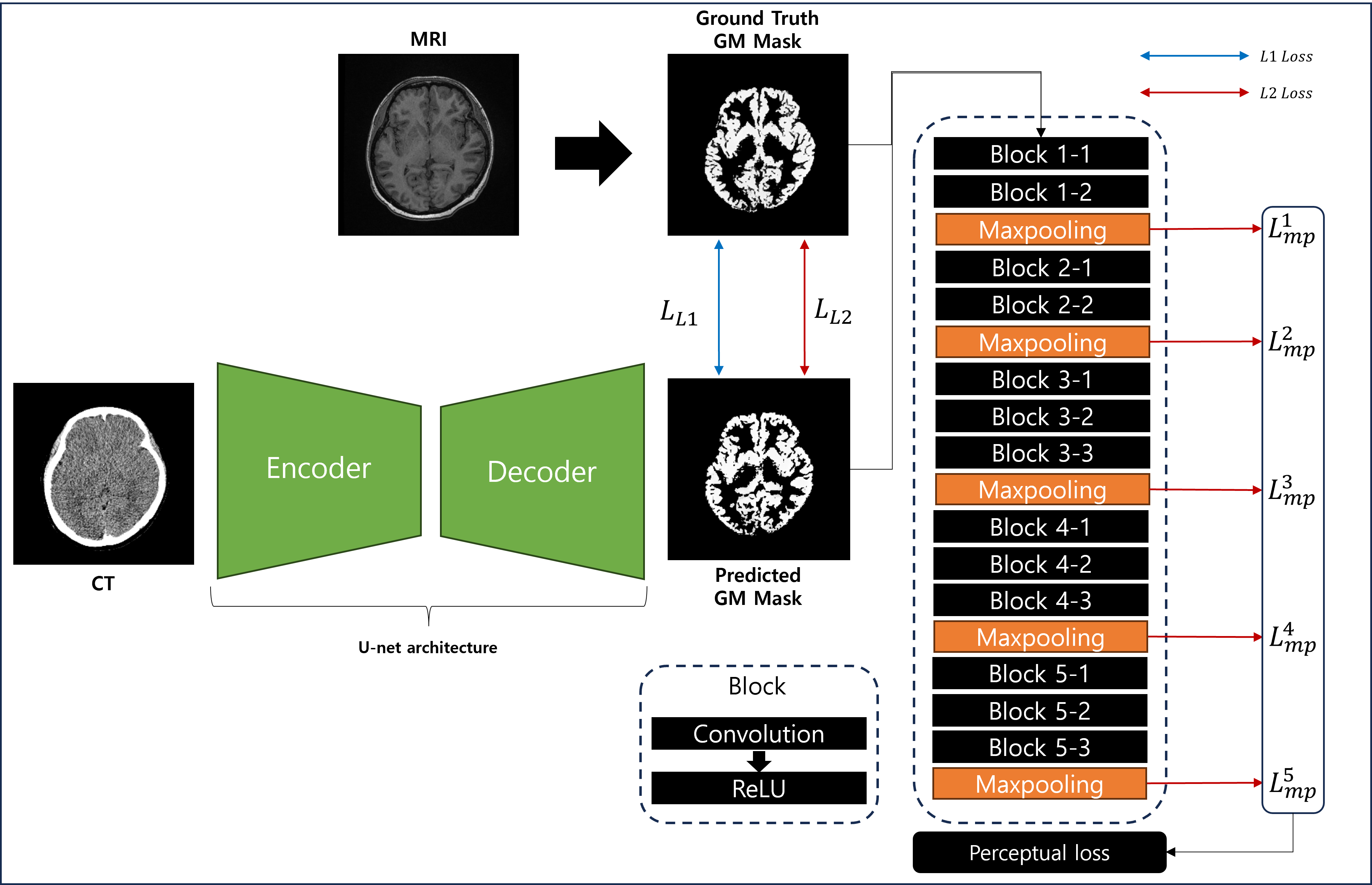
where $$$ y $$$ and $$$ \hat{y} $$$ represent the ground truth and DL-predicted image, respectively, $$$ L_{L1} $$$, $$$ L_{L2} $$$, and $$$ L_{p} $$$ are the L1, L2, and perceptual loss, respectively, comparing network predictions with target values for a given tissue. Here, we conjectured that image details, for example, around GM/WM interfacial regions, may be lost due to L1/L2 losses, but could be potentially preserved by introducing the perceptual loss5. To this end, a VGG16 network6 pretrained on ImageNet was employed separately from the U-Net training model. The perceptual loss computes featural differences (by mean-squared-errors) between ground truth and DL-predicted masks, right after each of the five max-pooling layers of VGG16, and adds them up. The schematic diagram of the proposed DL network is illustrated in Fig. 1. Key hyperparameters include: image size=256 x 256, learning rate=0.0001, batch size=32, training epochs=100, and the Adam optimizer. For computational efficiency, we implemented parallel training across 3 NVIDIA GeForce RTX 3090 Ti GPUs, each equipped with 24GB of memory, leading to 9 hours for the network training.
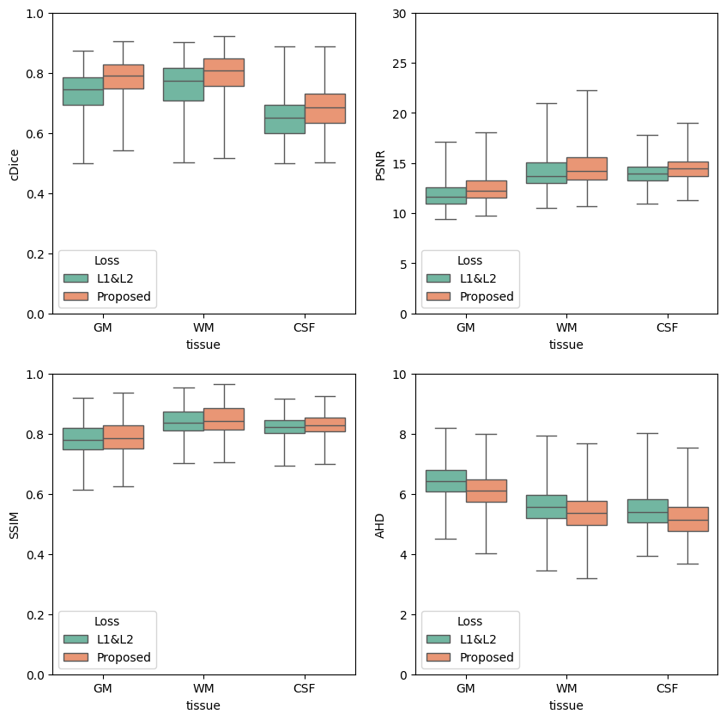
DL network evaluation: The trained network was evaluated in test datasets using the following metrics: continuous dice score (cDice)7, structural similarity index measure (SSIM), peak signal-to-noise ratio (PSNR), forward and reverse Hausdorff distance (FHD and RHD, Hausdorff distance from ground truth to predicted image and vice versa), and Average Hausdorff distance (AHD, mean of FHD and RHD). To assess the effectiveness of perceptual loss in the present network model, model training was carried out with and without $$$ L_{p} $$$ in Eq. (1), and the above metrics were computed for the test images.
Results
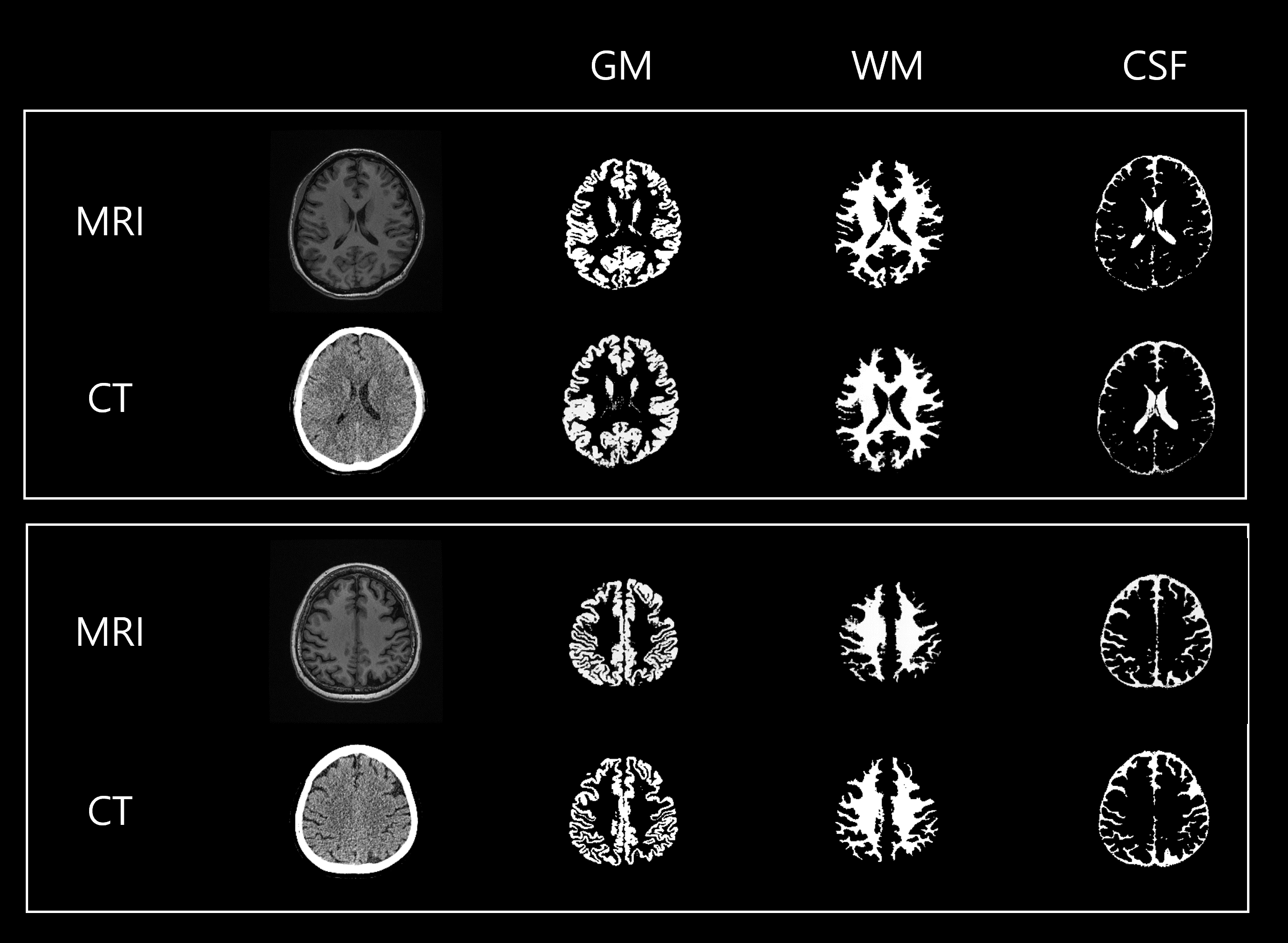
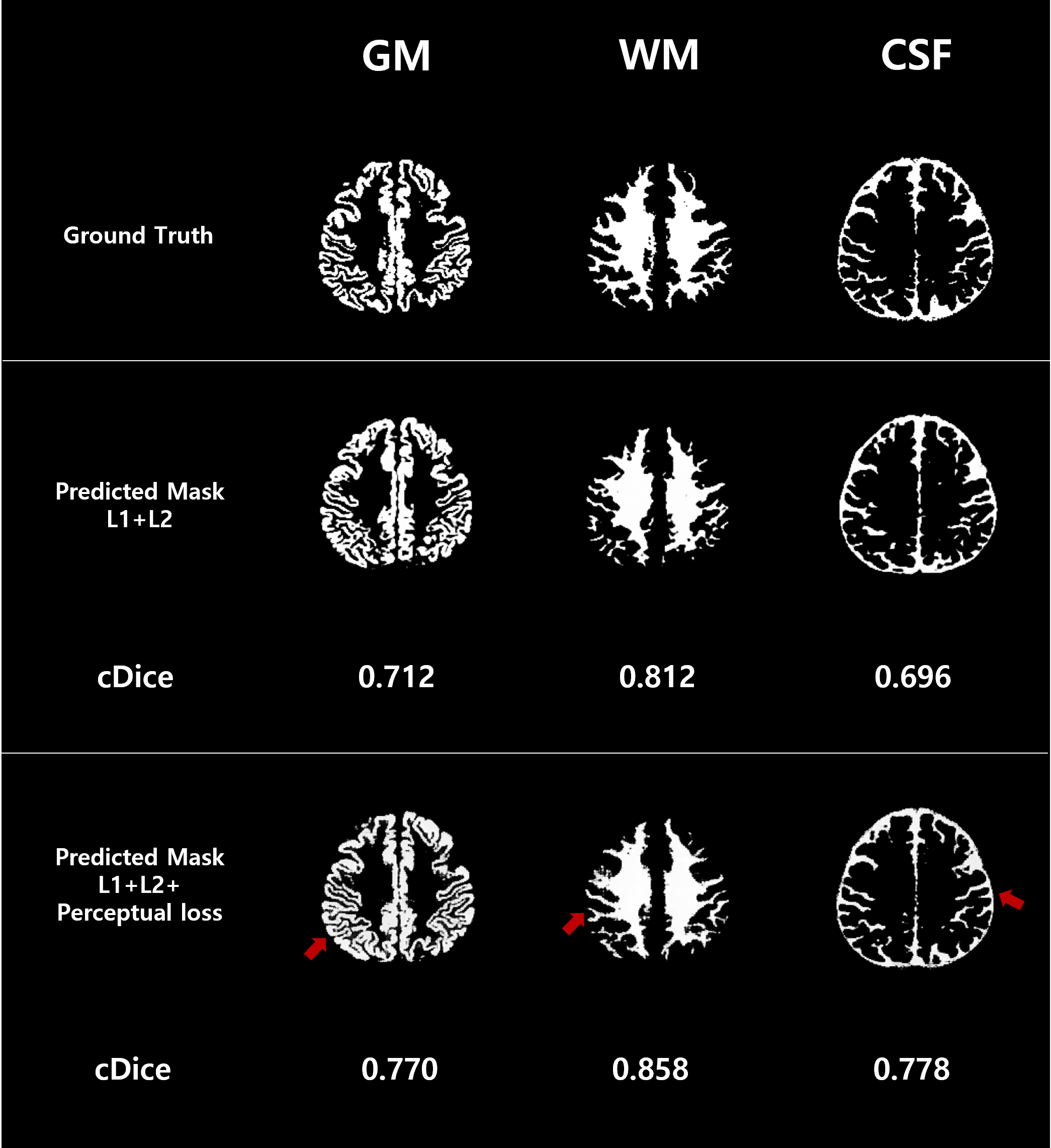
Figure 2 shows two representative test sets of MRI-derived tissue classification maps (ground truth) and DL-predicted counterparts from CT images. Qualitative comparison in Fig. 3 suggests the effectiveness of introducing the perceptual loss to the present DL network model in preserving detailed structures in brain tissues. This is further supported by Fig. 4 displaying box plots of the test evaluation scores (cDice, SSIM, PSNR, and AHD), obtained in 4,214 test CT images using the DL network trained with and without the perceptual loss.Discussion & Conclusion
The results demonstrate the benefit of incorporating the perceptual loss, as it effectively captures local and complex image features that are missed when using the norm-based losses only. The performance of the present DL network model may be further enhanced by a weighted combination of the terms in the loss function. Although model optimizations along with validation with externally acquired datasets are yet to be performed, the method is expected to be a valuable means to a range of brain imaging studies where MRI is somehow not available.Acknowledgements
This work was supported by the Korean Society of Magnetic Resonance in Medicine (KSMRM) research grant (KRF-23-005001).References
1. Claudia Plant, Stefan J. Teipel, Annahita Oswald, Christian Böhm, Thomas Meindl, Janaina Mourao-Miranda, Arun W. Bokde, Harald Hampel, Michael Ewers, Automated detection of brain atrophy patterns based on MRI for the prediction of Alzheimer's disease, NeuroImage, Volume 50, Issue 1, 2010, Pages 162-174, ISSN 1053-8119, https://doi.org/10.1016/j.neuroimage.2009.11.046.
2. Li W, Li Y, Qin W, Liang X, Xu J, Xiong J, Xie Y. Magnetic resonance image (MRI) synthesis from brain computed tomography (CT) images based on deep learning methods for magnetic resonance (MR)-guided radiotherapy. Quant Imaging Med Surg 2020;10(6):1223-1236. doi: 10.21037/qims-19-885
3. Meera Srikrishna, Joana B. Pereira, Rolf A. Heckemann, Giovanni Volpe, Danielle van Westen, Anna Zettergren, Silke Kern, Lars-Olof Wahlund, Eric Westman, Ingmar Skoog, Michael Schöll, Deep learning from MRI-derived labels enables automatic brain tissue classification on human brain CT, NeuroImage, Volume 244, 2021, 118606, ISSN 1053-8119, https://doi.org/10.1016/j.neuroimage.2021.118606.
4. Ronneberger, O., Fischer, P., and Brox, T. (2015). U- Net: Convolutional Networks for Biomedical Image Segmentation. arXiv:1505.04597
5. Johnson, J., Alahi, A., & Fei-Fei, L. (2016). Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14 (pp. 694-711). Springer International Publishing.
6. Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
7. Shamir, R.R. , Duchin, Y. , Kim, J. , Sapiro, G. , Harel, N. , 2019. Continuous dice coefficient: a method for evaluating probabilistic segmentations. arXiv preprint arXiv:1906.11031 .
Figures