2094
CPU-based real time cardiac MRI segmentation using lightweight neural network and knowledge distillation1Computer Science, Vrije University Amsterdam, Amsterdam, Netherlands, 2Biomedical Engineering, University of Virginia, Charlottesville, VA, United States
Synopsis
Keywords: Analysis/Processing, Segmentation
Motivation: Cardiac MRI plays an important role in diagnosis and prognosis of cardiovascular disease. Ideally, clinicians wants to get real-time segmentation using the existing CPU device but is challenging due to high computation burden of current neural networks.
Goal(s): We aim to develop a lightweight network to accelerate cardiac MRI segmentation on a CPU device while maintaining the accuracy.
Approach: We used layer-wish knowledge distillation to improve the accuracy of the lightweight network.
Results: Our results showed that the accuracy of the lightweight model can satisfy the real-time segmentation on CPU devices and achieve the same level of accuracy as the complex model.
Impact: This research provides a way to significantly reduce the running time of neural network on CPU device while maintaining accuracy using knowledge distillation. It facilitates the deployment of neural network in clinical practice by eliminating the need for additional hardware.
Introduction
Cardiovascular disease is one of the leading causes of mortality worldwide. Magnetic ResonanceImaging (MRI) is crucial in diagnosis and prognosis of these diseases using various sequences such as real-time cine, perfusion, and late gadolinium enhancement imaging [1]. These scans, while informative, often require or significantly benefit from quantitative analysis including ejection fraction calculation. However, this requires accurate segmentation of regions of interest (ROIs),which can be time-consuming and subjective. Recently, numerous neural network architectures have demonstrated commendable performance in automatic medical image segmentation tasks, as noted in various studies [2]. However, one limitation of these high-performance segmentation models is the requirement of high-end GPU rather than CPU devices which are more widely available in clinical environments as otherwise the computation time will be extremely slow. Ideally clinicians want to get the real-time segmentation and quantitative parameters right after the MRI acquisition with the existing CPU device, but it is challenging with the traditional neural networks. In this study we aim to develop a very lightweight network [3] and use knowledge distillation[4] to satisfy the real-time segmentation on CPU devices while maintaining the accuracy of the complex networks.Methods and Experiments
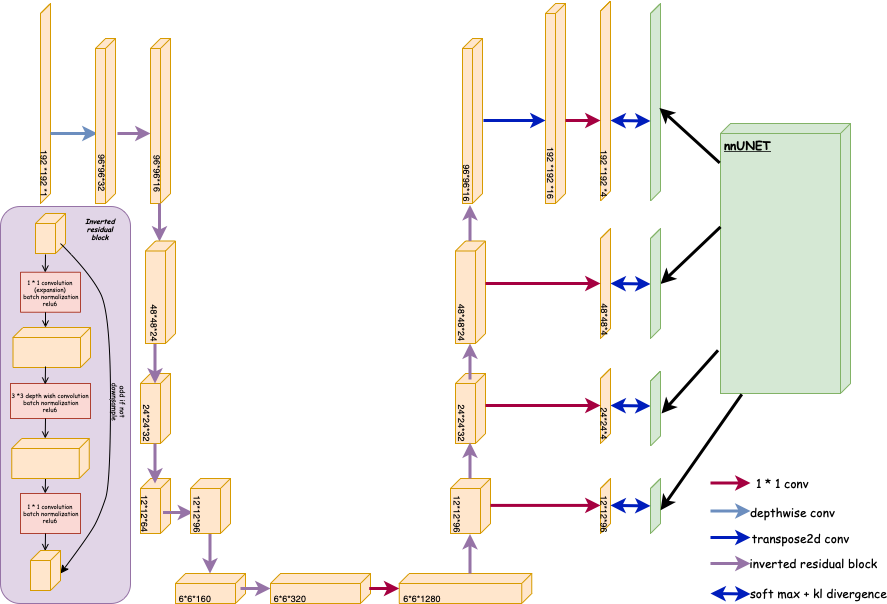
Knowledge distillation, introduced in [4], is a method for transferring insights from a complex "teacher" neural network to a simpler "student" model. The teacher, due to its larger size and accuracy, produces a rich output probability distribution that the student model can’t learn directly from data alone. This output offers deeper insights into data characteristics, beyond mere class identification. A crucial element in this process is the "distillation temperature", a hyper-parameter that adjusts the teacher model's output distribution. This adjustment helps the student model understand and learn finer details more effectively. The teacher's logits are moderated by the distillation temperature and then processed through a softmax function to generate this tailored distribution. By training on this modified distribution, the student model learns to recognize complex patterns, achieving accuracy close to the teacher model. This efficiency makes it well-suited for real-time applications like cardiovascular MRI scan segmentation.We use the nnUNet [5] as the teacher model for knowledge distillation as it showed superior accuracy and generalizability in various segmentation tasks of medical images. For the training of teacher model, data augmentation includes random translation, rotation, flipping and contrast changes are used; for the inference, test augmentation including rotation and mirroring are used.
One of the primary computational bottlenecks in neural network-based image analysis is the convolution layers. Addressing this inefficiency, our student model uses the mobilenet structure [3] as the backbone of feature extraction by replacing the convolution layer with the inverted residual block, which can significantly increase the computational speed. For the training process, same data augmentation as training teacher model was used. In the inference process, no test augmentation was used. The loss function takes the following form
$$L = \sum_{i=1}^{4} w_i \left( (1-W)\cdot L_{\text{hard}}^{(i)} + W\cdot D_{\text{KL}}\left(\frac{P^{(i)}}{T}, \frac{Q^{(i)}}{T}\right) \right)$$
where $$$ L_{{hard}}^{(i)} $$$ is the hard loss (same as teacher model) at layer $$$i$$$. $$$ D_{{KL}}\left(\frac{P^{(i)}}{T}, \frac{Q^{(i)}}{T}\right) $$$ is the KL divergence between the softened probability of the teacher model $$$ P^{(i)} $$$ and student model $$$ Q^{(i)} $$$ at layer $$$ i $$$, with distillation temperature $$$ T $$$ . $$$w_i$$$ is the layer weight.
Figure 1 shows the architecture of how the student model distillated from the teacher model.
In our experiment, we compared the performance of the teacher and student models in the context of cine MRI segmentation. The open source data from two challenges [6-7] was combined and the task was to segment LV cavity, LV myocardium and RV cavity. 591 frames were used for training and 249 frames were used for testing.
Results
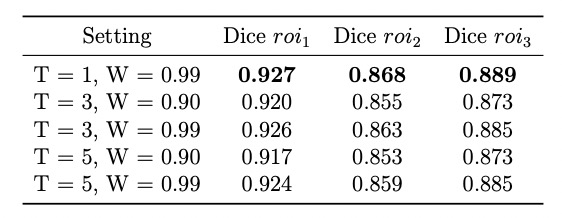
The key metrics for comparison were deployment speed and segmentation accuracy. Table 1 shows that the Mobilenet structure has a much faster deployment speed compared to nnUNet and can satisfy the real-time segmentation on CPU device which needs speed up to 10 images per second.We selected the Mobilenet with expansion ratio 8 of inverted residual block as the student model to test the performance improvement after distillation from nnUNet. Table 2 shows that when using the knowledge distillation, the accuracy of the student model improved and is close to the accuracy of the teacher model.
Discussion
Our study showed that knowledge distillation from a more accurate neural network can improve the accuracy of a lightweight model deployed on CPU devices. The distillation temperature can affect the accuracy and a lower temperature can improve the accuracy. We will perform further clinical validation in the future.Acknowledgements
No acknowledgement found.References
[1] Constantine G, Shan K, Flamm SD, Sivananthan MU. Role of MRI in clinical cardiology. Lancet. 2004 Jun 26;363(9427):2162-71. doi: 10.1016/S0140-6736(04)16509-4. PMID: 15220041.
[2] Asgari Taghanaki S, Abhishek K, Cohen J P, et al. Deep semantic segmentation of natural and medical images: a review. Artificial Intelligence Review, 2021, 54: 137-178.
[3] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[4] Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
[5] Isensee F, Petersen J, Klein A, et al. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv preprint arXiv:1809.10486, 2018.
[6] https://www.creatis.insa-lyon.fr/Challenge/acdc/#challenges
[7] https://www.ub.edu/mnms/
Figures