1994
Masked U-net: Bridging the gap between real and synthetic data for mapping reconstruction in multiple overlapping-echo detachment imaging1Institute of artificial intelligence, Xiamen University, Xiamen, China, 2Department of Electronic Science, Xiamen University, Xiamen, China, 3Clinical & Technical Support, Philips Healthcare, Shenzhen, China
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence
Motivation: The synthetic training data used for mapping reconstruction of deep learning can simulate the required features, but it is difficult to fully simulate the unnecessary characteristics existing in real-world data.
Goal(s): This work aims to enable the model to extract the essential mapping relationships for mapping reconstruction and eliminate the interference of non-ideal factors in real data.
Approach: We propose a mask pre-training method called Masked U-net that allows the model to learn appropriate inductive biases on quantitative images.
Results: The proposed method can better extract relevant features and reduce the interference of irrelevant factors in real data.
Impact: The proposed method bridges the gap between the real data and synthetic data, improves the quality of deep learning reconstruction driven by synthetic training data, and achieves important application in T2/T2* mapping reconstruction of multiple overlapping-echo detachment (MOLED) imaging.
Introduction
Multiple overlapping-echo detachment (MOLED) imaging enable the acquisition for multiple-parameter quantitative mapping in about 100 milliseconds, making quantitative imaging very fast and motion robust.1-3 Deep learning methods driven by synthetic training data are currently used for mapping reconstruction of MOLED because of the unavailability of a large amount of real training data. By considering various non-ideal factors in real-world MRI data, synthetic training data based on Bloch simulation can allow deep neural networks to learn various basic properties in real-world data. However, there are still some non-ideal factors that are difficult to reflect in the synthetic training data, such as noise from various sources, local physiological motion, unusual texture structure, etc. It is more obvious for some lesion cases. Therefore, if the model can focus on the mapping relationship of key features, it can ignore non-critical features and bridge the gap between synthetic and real data. In this work, we propose a pre-training method that allows the model to use masks on quantitative images to learn inductive biases. A model with prior information can more accurately extract the key features required for mapping. Experimental results show that the pre-training method is better than direct training on synthetic data.Methods
The proposed method is shown in Figure 1. We masked 50% of the pixels of the T2 map at random. And each masked patch was 4´4 pixels in size. Then, we input the entire masked T2 map into the network. The random masking process was performed during training. The model predicted the original T2 quantitative image based on the masked image. The loss function calculated the mean absolute error (MAE) between the reconstructed image and the original image in pixel space. Only the loss on the masked patches was calculated.4 By pre-training on masked T2 maps, the model can learn prior information about quantitative maps. Then, we further trained the model on synthetic data using the pre-trained model to better learn the mapping relationship between MOLED images and quantitative maps.U-net was used as the model. T2 maps generated from the public IXI dataset was used for pre-training. The IXI dataset provides T2-weighted and PD-weighted images, which were used to create T2 maps by using the MR T2 signal attenuation formula.5 Synthetic data were generated according to the method proposed by Yang et al.5 The pulse sequences used for collecting synthetic and real data are shown in Figure 2. For T2 reconstruction, single-shot MQMOLED was used.1 For T2* reconstruction, single-shot GRE-MOLED was used.3Results
Figure 3 and Figure 4 show the results of the proposed method and U-net on T2 and T2* mapping reconstruction. There are streaks in the T2 maps of the lesions using the direct U-net training method, whereas the proposed method can reconstruct the lesion region quite well. For T2* map reconstruction, the proposed method can reconstruct more detailed texture.Discussion
The synthetic training data used for mapping reconstruction of deep learning can simulate the required features. But real data contains unnecessary noise that affects the model to grasp the mapping relationship. Besides, the synthetic data do not contain lesion areas with the same mapping relationship as normal areas. Compared with direct training, the pre-trained U-net with prior information can better grasp the mapping relationship between MOLED and parametric maps and exclude the interference of irrelevant noise. When real data is used as input during testing, even if real data has non-ideal interference compared to synthetic data, the model can identify key features and reduce the interference of non-ideal factors to obtain better quantitative mapping reconstruction. The pre-training U-net also can grasp the mapping relationship of the lesion region when the synthetic training dataset does not contain the lesion region.Conclusion
This work introduces a pre-training masked U-net method. This method allows the model to acquire prior information, extract more relevant features during training on synthetic data, reduce the impact of noise on reconstruction results in real data, and achieve better quantitative mapping reconstruction.Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under grant numbers 12375291 and 22161142024, and in part by the National Key R&D Program of China under Grant 2022YFC2402102.References
1. Ma L, Wu J, Yang Q, et al. Single-shot multi-parametric mapping based on multiple overlapping-echo detachment (MOLED) imaging. Neuroimage. 2022, 263: 119645.
2. Zhang J, Wu J, Chen S, et al. Robust single-shot T2 mapping via multiple overlapping-echo acquisition and deep neural network. IEEE Trans Med Imaging. 2019, 38(8): 1801-1811.
3. Yang Q, Ma L, Zhou Z, et al. Rapid high‐fidelity T2* mapping using single‐shot overlapping‐echo acquisition and deep learning reconstruction. Magn Reson Med. 2023, 89(6): 2157-2170.
4. He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 16000-16009.
5. Yang Q, Lin Y, Wang J, et al. Model-based synthetic data-driven learning (MOST-DL): Application in single-shot T2 mapping with severe head motion using overlapping-echo acquisition. IEEE Trans. Med Imaging. 2022; 41(11): 3167-3181.
Figures
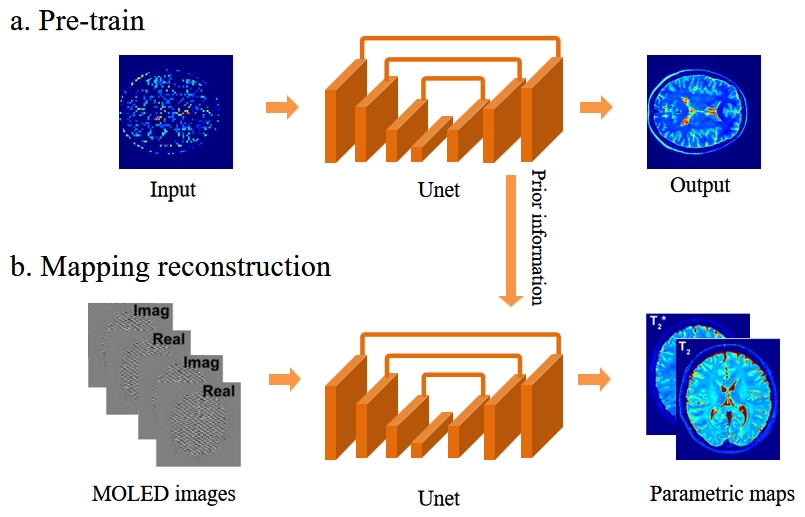
Figure 1. The structure of the proposed method
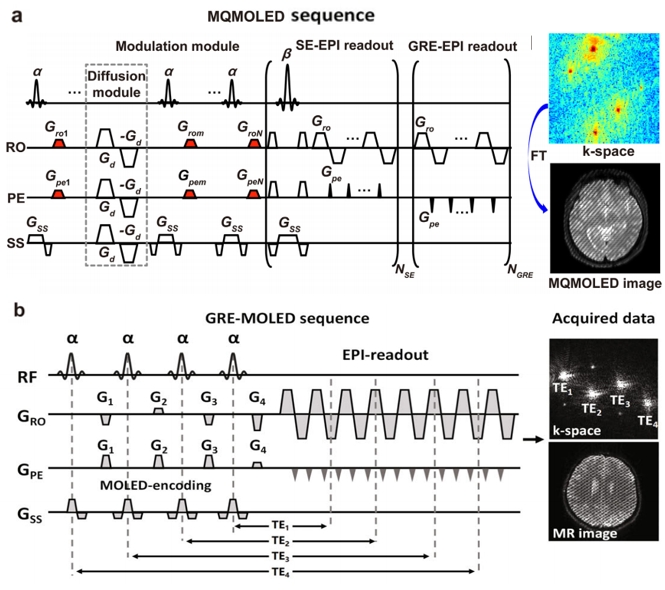
Figure 2. (a) Single-shot MQMOLED pulse sequence. (b) Single-shot GRE-MOLED sequence.
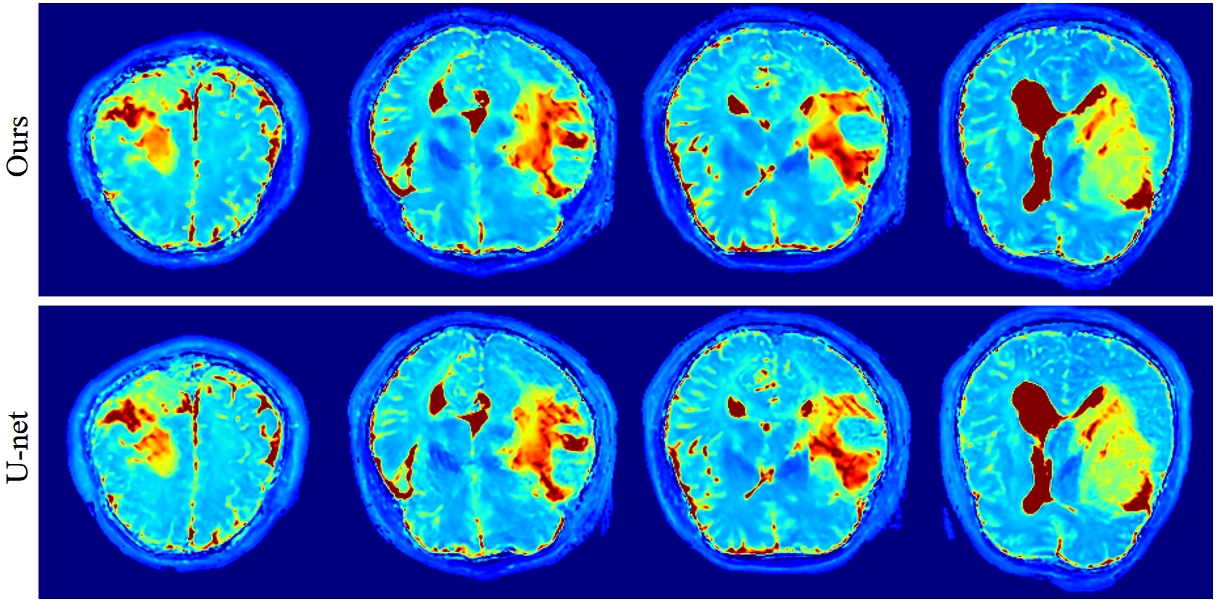
Figure 3. Comparison of the reconstruction results of the proposed method and U-net for T2 maps containing lesions.
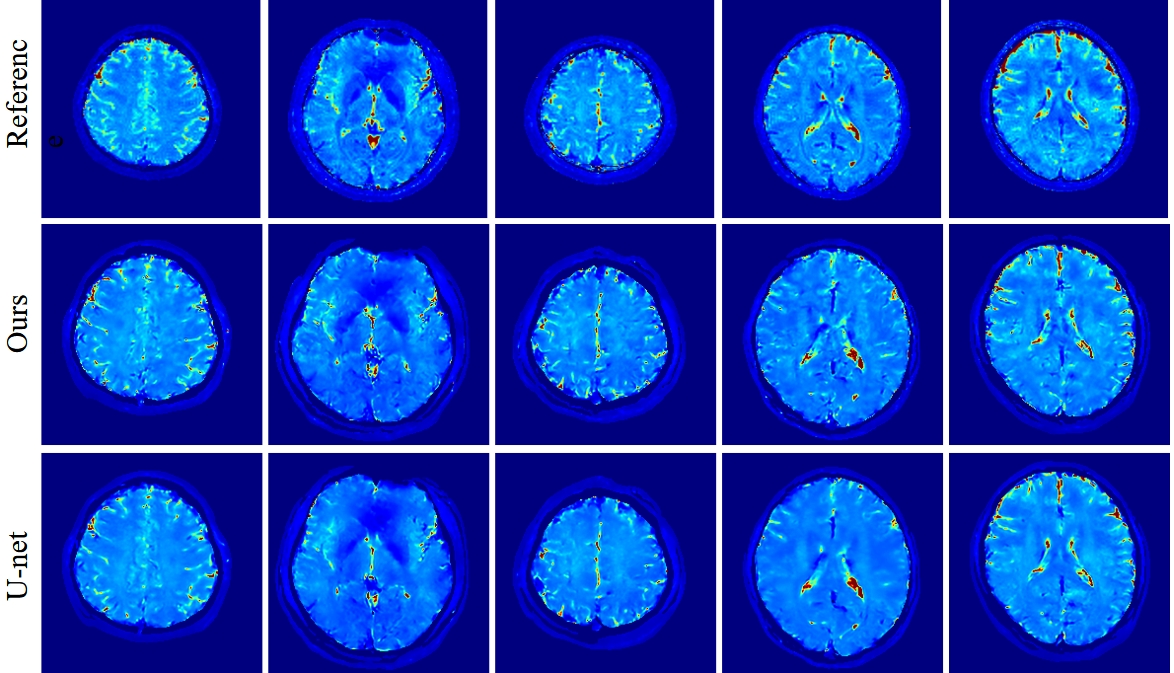
Figure 4: Comparison of the reconstruction results of T2* maps using the proposed method and U-net.