1971
Stacked Deep U-Net with Hybrid Assisted Priors for Through-Plane Super-Resolution in Brain MRI1Yonsei University, Seoul, Korea, Republic of, 2Sejong University, Seoul, Korea, Republic of
Synopsis
Keywords: AI/ML Image Reconstruction, Brain, Super-Resolution
Motivation: The motivation behind this study is to alleviate discomfort during clinical exams by improving through-plane resolution.
Goal(s): Our objective is to develop a deep learning-based super-resolution approach for low-resolution T2 images, reducing patient discomfort and improving diagnosis accuracy.
Approach: We develop a deep learning framework that combines information from T1 and T2 scans, enabling the generation of high-quality images in the through-plane direction.
Results: The proposed approach successfully enhances through-plane super-resolution in brian MRI, resulting in superior image quality. This improvement has the potential to improve diagnostic accuracy and alleviate patient discomfort during clinical exams.
Impact: This study presents a novel deep learning framework that improves through-plane Super-Resolution in brain MRIs, thus enhancing diagnostic accuracy and reducing patient discomfort during routine health checks.
Introduction
The demand for through-plane Super-Resolution (SR) in brain Magnetic Resonance Imaging (MRI) has been emphasized due to potential discomfort during clinical examinations. In typical clinical exams, T2 MR scans with a slice thickness of 2mm to 5mm are commonly performed since multi-slice fast spin-echo is the preferred imaging protocol resulting in a coarser resolution in the though-plane domain (We denote this as low resolution (LR) T2).1 Existing deep learning SR networks primarily focus on in-plane SR2,3, overlooking the specific clinical needs for through-plane enhancement. We propose a SR routine in the through-plane based on a deep learning framework that utilizes information from relatively high-resolution (HR) 3D T1 data obtained during health examinations. This approach can potentially alleviate discomfort during health checks while enhancing diagnostic accuracy.Methods
[Dataset]In this study, we utilized T1 and T2 weighted images from the IXI dataset (http://brain-development.org/ixi-dataset/), consisting of 50 subjects without major artifacts, with a split of 40 for training and 10 for testing. To enhance registration accuracy, we performed an affine transformation using Elastix4. Specifically, the T1 weighted images were registered to the T2 weighted images using 100 sagittal images containing brain tissue per subject. The registered images have a volume size of 256x256x128, a resolution of 0.9375x0.9375x1.2mm3 and a Field of View (FOV) of 240x240x154mm3. In this work, we improved the LR T2 volume sizes for different slice thicknesses (2mm: 240x240x76, 3mm: 240x240x51, 4mm: 240x240x38, and 5mm: 240x240x30) to match the original volume size and FOV utilizing the proposed framework.
[Proposed Framework]
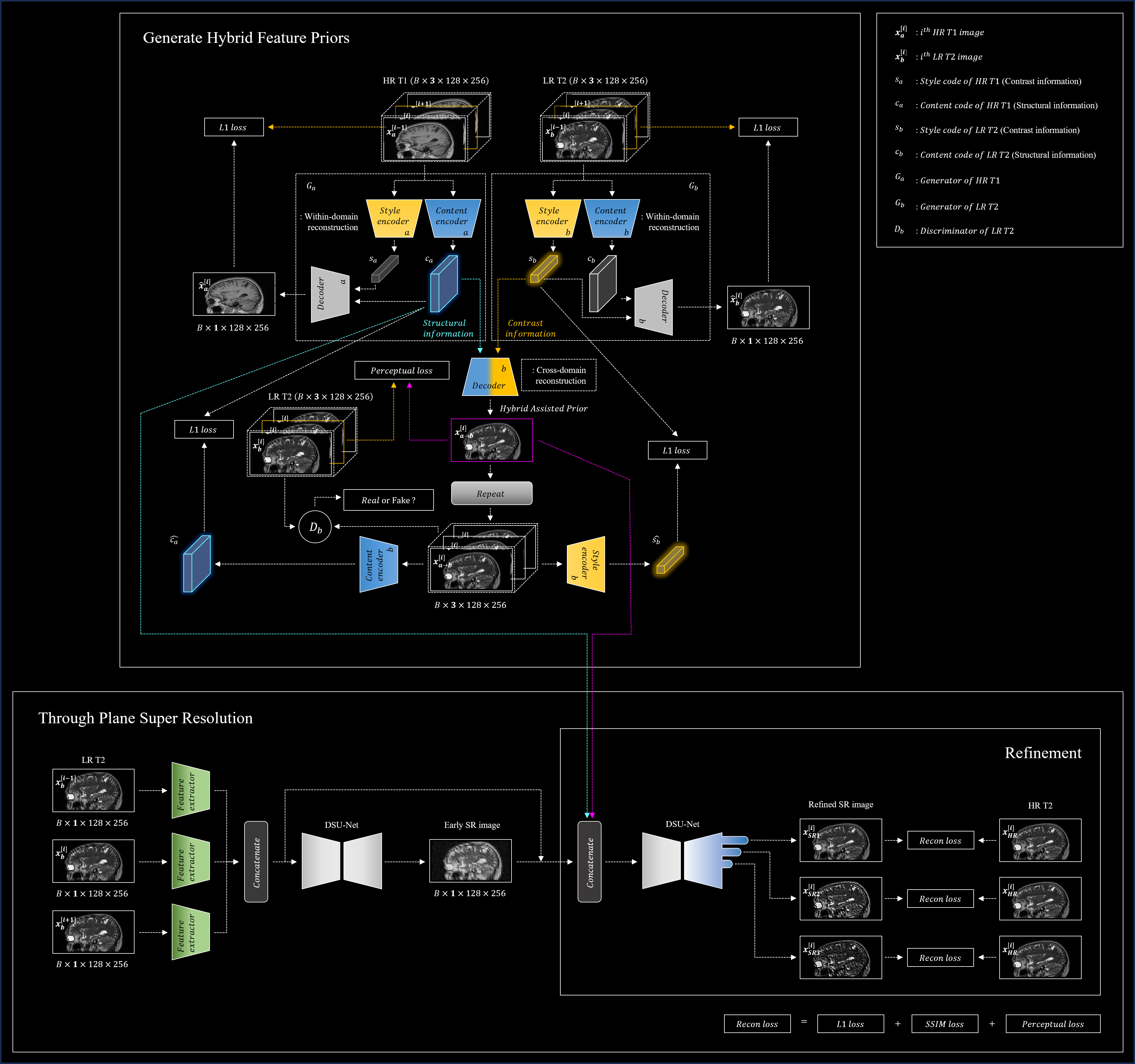
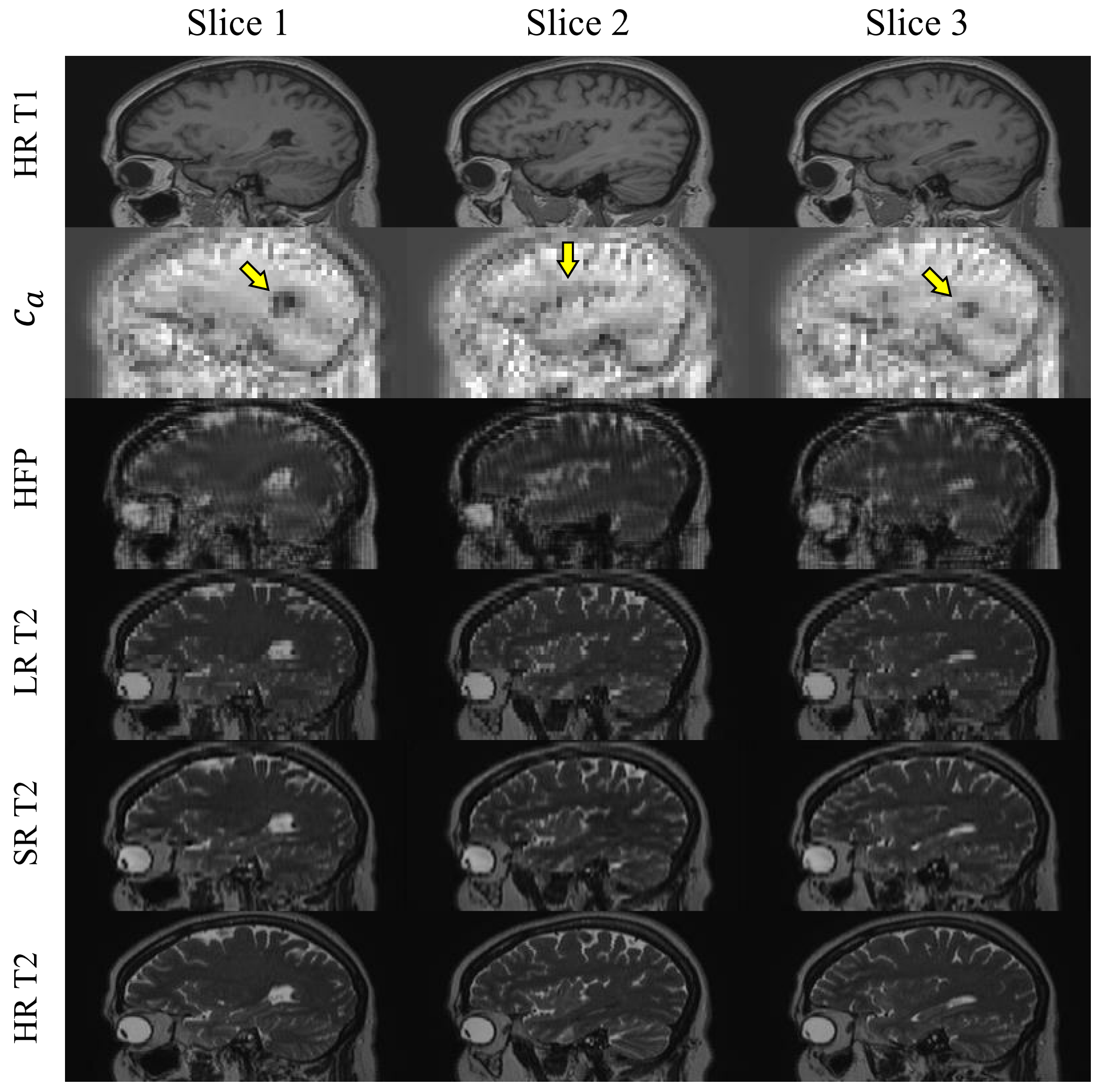
Our proposed deep learning framework aims to improve the resolution of T2 weighted images in the through-plane direction. This is achieved by utilizing contrast features from thicker-slice T2 images and structural information from HR T1 weighted images. The framework consists of a sub-module that generates Hybrid Assisted Priors (HAP) and a main-module that performs through-plane SR based on these priors using a Stacked DSU-Net (see Figure 1). Inspired by the concept that images possess content and style spaces5, we extract structural information (ca) from HR T1-weighted images and contrast information (sb) from LR T2-weighted images. We use 3-channel inputs by joining adjacent slices to tackle single-channel medical image constraints and to capture detailed anatomical features. This approach compensates for any lost contrast features in degraded T2-weighted images. The integration of the extracted codes (ca and sb) allows us to decode the Hybrid Feature Prior (HFP), combining the strengths of both content and contrast information. We employ feature extractors to capture attributes from three consecutive LR T2 images, which serves as input for the initial DSU-Net. This process conserves crucial details from the image priors. The next stage involves refinement through the second DSU-Net, which merges the early SR output, extracted features, and the codes (ca and HFP). The application of deep supervision techniques in the final stages of the second DSU-Net bolsters training efficiency by preserving the gradient of the preliminary stage6.
Results
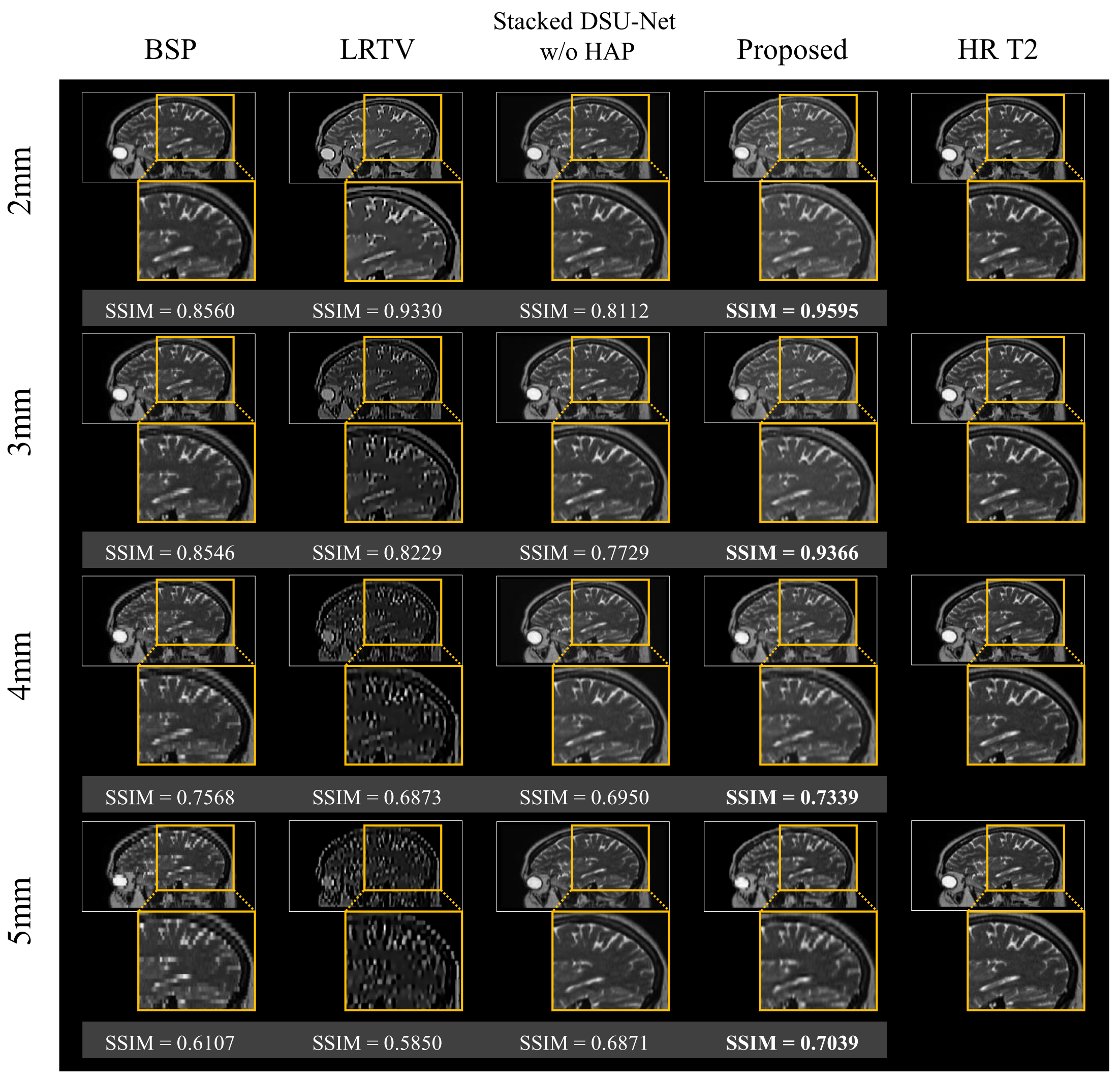
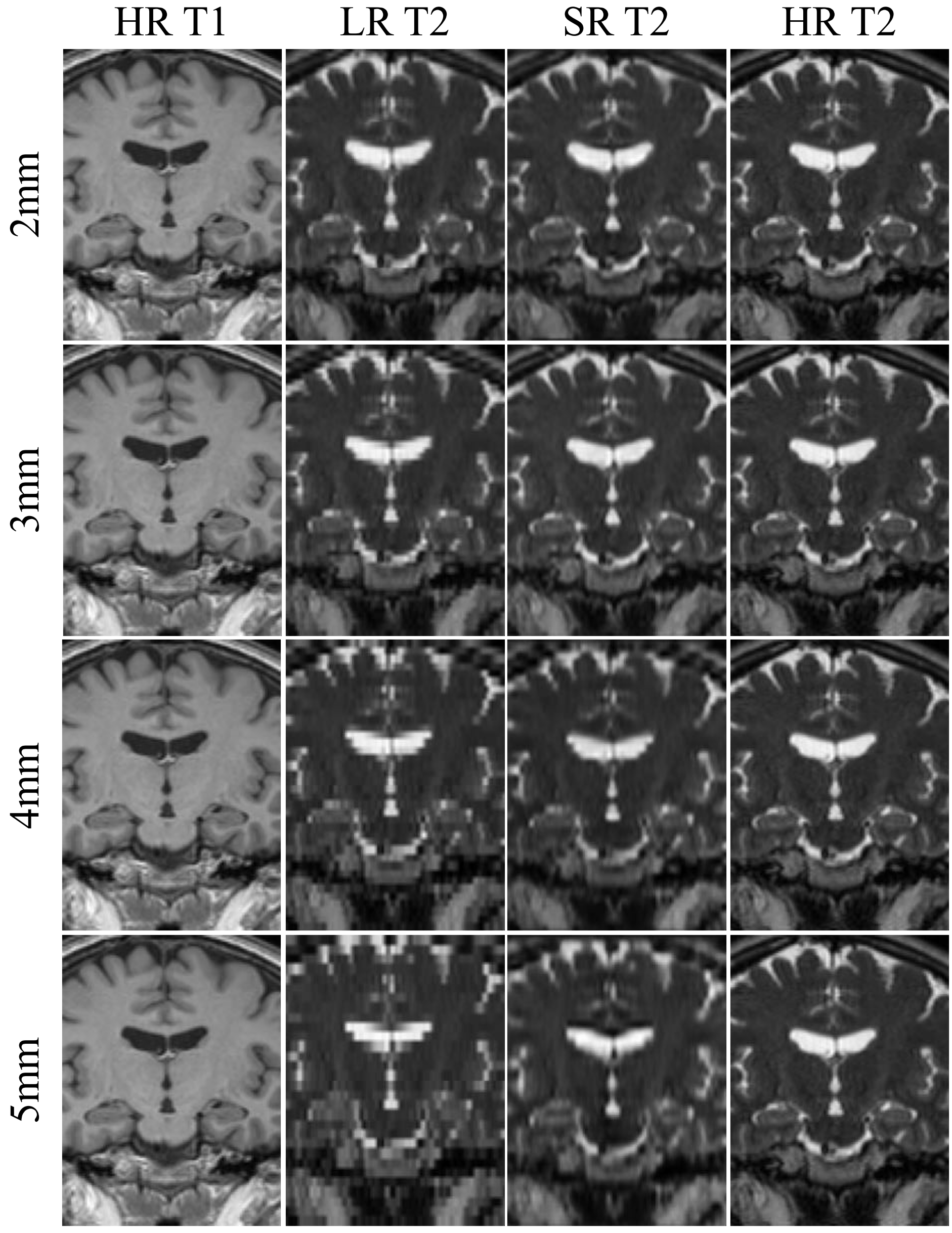
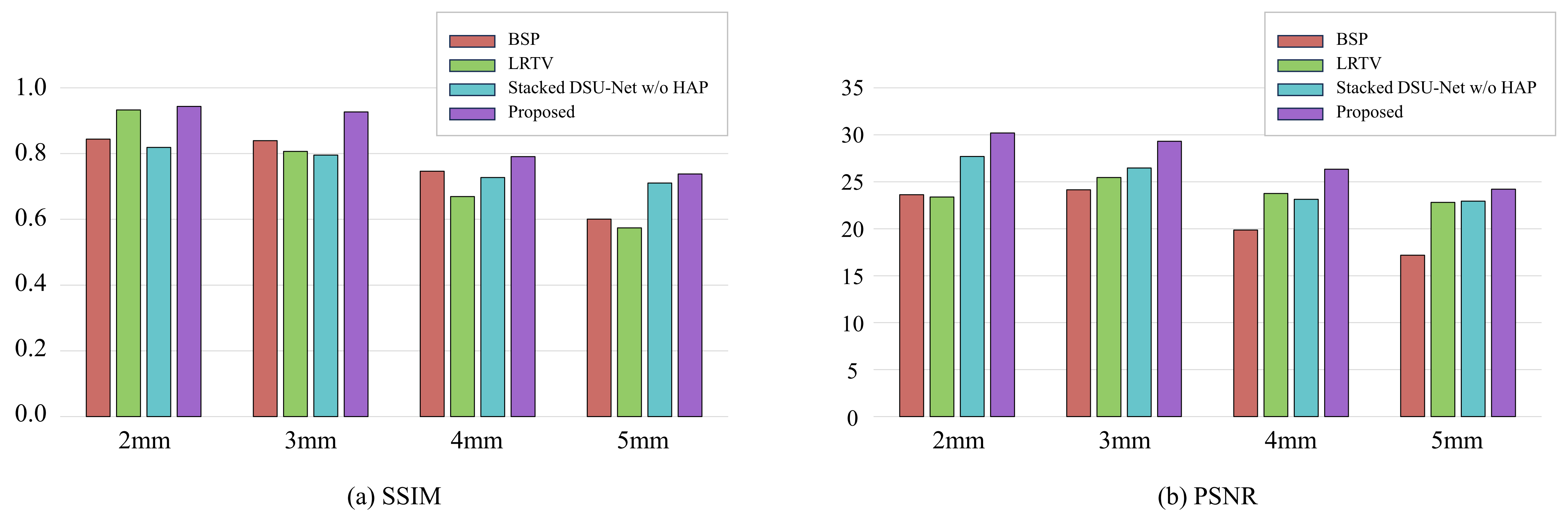
Figure 2 presents the qualitative results of comparative experiments with the proposed method, the commonly used B-spline interpolation (BSP) in super-resolution, the total variation method LRTV7 and Stacked DSU-Net without HAP, according to the slice thickness. The proposed network shows relatively effective preservation of both contrast information and structural details, even as the slice thickness increases. In contrast, LRTV exhibits a significant degradation of not only the contrast features but also the structural characteristics as the slice thickness exceeds 3mm. The results from Stacked DSU-Net without HAP presented that as the slice thickness increased to 5mm, the structural features began to smooth out and were not preserved as effectively as in the proposed model. Furthermore, proposed network demonstrates a notable improvement of approximately 16% in SSIM value when HAP is utilized with a slice thickness of 3mm. Figure 3 plots the outputs at each stage of our proposed framework, including the extraction of the structural feature (ca) from the HR T1 image using Ga. Figure 4 indicates the qualitative results of our framework with coronal view across each slice thickness. Figure 5 provides quantitative results, presenting average SSIM and PSNR values for all methods across different slice thicknesses.Discussion and Conclusion
The proposed method successfully restored structural details from LR T2 weighted images, especially with thin slice thicknesses. We speculate that our framework operates as intended because T1 and T2 weighted images, despite differing contrasts, share the common structural information that describes brain anatomy. Additionally, we considered that while the structural features in LR T2 weighted images may deteriorate with increasing slice thickness, the contrast information can be relatively preserved.Acknowledgements
This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. NRF-2022R1A4A1030579).References
1. Kim, E. A new healthcare policy in Korea part 1: expanded reimbursement coverage of brain MRI, brain/neck MRA, and head and neck MRI by National Health Insurance. Taehan Yongsang Uihakhoe chi 81, 1053-1068 (2020).
2. Wang, J., Chen, Y., Wu, Y., Shi, J. & Gee, J. in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3627-3636.
3. Chen, Y. et al. in 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018). 739-742 (IEEE).
4. Klein, S., Staring, M., Murphy, K., Viergever, M. A. & Pluim, J. P. Elastix: a toolbox for intensity-based medical image registration. IEEE transactions on medical imaging 29, 196-205 (2009).
5. Huang, X., Liu, M.-Y., Belongie, S. & Kautz, J. in Proceedings of the European conference on computer vision (ECCV). 172-189.
6. Choi, Y. et al. A Single Stage Knowledge Distillation Network for Brain Tumor Segmentation on Limited MR Image Modalities. Computer Methods and Programs in Biomedicine, 107644 (2023).
7. Shi, F., Cheng, J., Wang, L., Yap, P.-T. & Shen, D. LRTV: MR image super-resolution with low-rank and total variation regularizations. IEEE transactions on medical imaging 34, 2459-2466 (2015).
Figures